Doporučování se zaměřením na kulturní portály PDF Free Download
1 / 57/57
100%

DIPLOMOVÁ PRÁCE
Bc. Zuzana Vytisková
Doporučování se zaměřením na kulturní portály
Katedra softwarového inženýrství
Vedoucí diplomové práce: Mgr. Ladislav Peška, Ph.D.
Studijní program: Informatika
Studijní obor: Softwarové systémy
Praha 2017

[Vzor: Vevázaný list – kopie podepsaného „Zadání diplomové práce“. Toto zadání NENÍ
součástí elektronické verze práce. NESKENOVAT.]
Na tomto místě bych chtěla poděkovat vedoucímu diplomové práce, Mgr. Ladislavu
Peškovi, Ph.D. za užitečné rady i za trpělivost. Vojtěchu Knyttlovi děkuji za možnost
pracovat s historickými daty webu goout.cz. V neposlední řadě patří poděkování i mé
rodině a partnerovi za podporu během psaní této práce.
Prohlašuji, že jsem tuto diplomovou práci vypracovala samostatně a výhradně
s použitím citovaných pramenů, literatury a dalších odborných zdrojů.
Beru na vědomí, že se na moji práci vztahují práva a povinnosti vyplývající
ze zákona č. 121/2000 Sb., autorského zákona v platném znění, zejména skutečnost,
že Univerzita Karlova má právo na uzavření licenční smlouvy o užití této práce jako
školního díla podle § 60 odst. 1 autorského zákona.
V …...... dne............ podpis
Název práce: Doporučování se zaměřením na kulturní portály
Autor: Zuzana Vytisková
Katedra / Ústav: Katedra softwarového inženýrství
Vedoucí diplomové práce: Mgr. Ladislav Peška, Ph.D., Katedra softwarového
inženýrství
Abstrakt: Diplomová práce se zabývá tématem doporučování v kultuře. V teoretické
části srovnává doporučování digitálně dostupných děl s doporučováním akcí, což
slouží jako východisko pro popis doporučování na kulturním portálu. Dále práce
zkoumá model domény jako několika různých, vzájemně provázaných typů objektů.
Využití těchto vazeb pro obohacování datových sad umožňuje překonat nízkou
hustotu dat a zlepšit výsledky doporučování.
Práce dále zkoumá dvě běžné situace praktického doporučování,
doporučování obecnému uživateli s minimálním profilem a doporučování
registrovanému uživateli se známou historií. Pro účely jejich řešení byly
implementovány hybridní algoritmy založené na zapojení obsahových informací
do již existujících metod kolaborativního filtrování.
Výsledky jsou ověřeny v offline testech na datových sadách výzkumného
i reálného charakteru. Subjektivní kvalita výsledných doporučení byla zkoumána
prostřednictvím uživatelské studie.
Klíčová slova: doporučovací systémy, uživatelské preference, kulturní portály,
multimedia
Title: Recommender systems for culture events
Author: Zuzana Vytisková
Department: Department of Software Engineering
Supervisor: Mgr. Ladislav Peška, Ph.D., Department of Software Engineering
Abstract: The diploma thesis deals with the topic of recommendation in culture.
In the theoretical part, it compares the recommendation of digitally available works
with event recommendations, which serves as the basis for describing
recommendations on the cultural portal. Further, the thesis examines the domain
model as several different interconnected types of objects. Using these relations to
enrich data sets allows overcoming the low data density and improving the
recommendations.
The paper examines two common situations of practical recommendation,
general user recommendation with minimal profile and recommendation to registered
users with known history. As a part of the solution, hybrid algorithms have been
implemented based on the introducing content information into existing collaborative
filtering methods.
The results are verified in offline tests on data sets consisting of both research
and real-world data. The subjective quality of the resulting recommendations was
examined through a user study.
Keywords: recommender systems, user preference, culture portals, multimedia

Obsah
Úvod ............................................................................................................................. 1
Navigace ................................................................................................................... 2
1. Doporučovací systémy ......................................................................................... 3
1.1. Koncepty doporučování ................................................................................ 3
1.1.1. Základní pojmy ...................................................................................... 3
1.1.2. Podobnost ............................................................................................... 4
1.1.3. Zpětná vazba .......................................................................................... 5
1.2. Úlohy a principy doporučování ..................................................................... 5
1.2.1. Metody založené na obsahu ................................................................... 6
1.2.2. Metody založené na hodnocení ostatních uživatelů ............................... 7
1.2.3. Rozšiřující metody ................................................................................. 7
1.2.4. Skládání a hybridizace ........................................................................... 8
1.3. Metody a metriky hodnocení doporučování .................................................. 8
1.3.1. Metody hodnocení kvality doporučovacího systému ............................. 9
1.3.2. Metriky hodnocení kvality doporučování ............................................ 10
2. Doporučování v oblasti kultury .......................................................................... 13
2.1. Doporučování digitálně distribuovaných děl .............................................. 13
2.1.1. Zpětná vazba u doporučování děl ........................................................ 13
2.2. Doporučování událostí ................................................................................ 15
2.2.1. Zpětná vazba u doporučování akcí ....................................................... 15
2.3. Kulturní portál ............................................................................................. 16
2.3.1. Doména ................................................................................................ 16
2.3.2. Podobnost a převody v doméně ........................................................... 17
2.3.3. Zpětná vazba na kulturním portálu ...................................................... 17
2.3.4. Obsahová data pro kulturní akce .......................................................... 17
2.3.5. Příklady doporučování na českých kulturních webech ........................ 18
2.3.6. Společná volba skupiny........................................................................ 19
3. Datové sady a offline testy ................................................................................. 20
3.1. Datové sady ................................................................................................. 20
3.1.1. Knihy .................................................................................................... 20
3.1.2. Filmy .................................................................................................... 21
3.1.3. Portál .................................................................................................... 22
3.2. Použité metody ............................................................................................ 24
3.2.1. Biased MF ............................................................................................ 24
3.2.2. BPR ...................................................................................................... 25
3.2.3. Hybridní metody .................................................................................. 25
3.2.4. CBMF ................................................................................................... 26
3.2.5. CBBPR ................................................................................................. 26
3.3. Implementace řešení v LibRec .................................................................... 26
3.3.1. Nové metody přidané do LibRec ......................................................... 27
3.3.2. Další úpravy v LibRec ......................................................................... 28
3.4. Výsledky offline testů ................................................................................. 29
3.4.1. Knihy .................................................................................................... 29
3.4.2. Filmy .................................................................................................... 29
3.4.3. Portál .................................................................................................... 30
4. Praktické úlohy a návrh jejich řešení ................................................................. 34
4.1. Úloha obecného uživatele............................................................................ 34
4.2. Úloha registrovaného uživatele ................................................................... 35
5. Uživatelská studie .............................................................................................. 36
5.1. Úloha obecného uživatele............................................................................ 36
5.2. Úloha registrovaného uživatele ................................................................... 36
5.3. Základní otázka studie ................................................................................. 37
5.4. Realizace ..................................................................................................... 37
5.5. Vyhodnocení ............................................................................................... 38
5.5.1. Vyhodnocení textových otázek ............................................................ 40
5.6. Interpretace a další poznatky ....................................................................... 41
5.6.1. Znám a nezajímá mě ............................................................................ 41
5.6.2. Neformální zpětná vazba...................................................................... 41
Závěr .......................................................................................................................... 43
Seznam použité literatury ........................................................................................... 45
Seznam obrázků a tabulek .......................................................................................... 48
Přílohy ........................................................................................................................ 49
Obsah CD ............................................................................................................... 49
Úvod
Dlouhou dobu bylo cílem webových stránek a vyhledávačů především
shromažďovat a zpřístupňovat informace. S rostoucím množstvím dostupného
obsahu roste potřeba nabízet uživatelům i prostředky k co nejsnazšímu nalezení
předmětu jejich zájmu. Některé používané metody vycházejí z možnosti přímého
zadávání vyhledávacích kritérií, jiné jsou založené na strojovém odhadu zájmu
uživatelů podle jejich předchozího chování. Doporučovací systémy jsou zástupcem
druhého z uvedených přístupů.
Informace o událostech v kultuře jsou příkladem domény, kdy prosté
shromáždění zvyšuje užitečnost dat jen částečně; události se uskutečněním stávají
neaktuálními, zdrojová data o nich nemají standardizovanou formu a k dispozici je
málo objektivních vyhledávacích parametrů. Dlouhou dobu zastával funkci hlavního
informačního zdroje v oblasti pražského kulturního dění tištěný Pražský přehled
kulturních pořadů. V každém vydání přinášel souhrn událostí s datem konání
v příštím měsíci. Akce byly řazeny podle hrubého tématu, v rámci něj podle
pořadatele a jednotlivé události pak podle data konání. Možnosti vyhledávání byly
omezeny na hledání tematicky orientované, orientaci komplikovalo i rozdělování
akcí jednoho pořadatele do více částí podle tématu události.
Internetové katalogy kulturních akcí jsou přímým pokračovatelem takového
kulturního přehledu. Shromažďují informace o konaných akcích a organizují je
v podobně rozložených rubrikách. Prakticky všechny nabízejí navíc oproti tištěným
variantám alespoň zobrazení událostí probíhajících v některý konkrétní den nebo
fulltextové prohledávání. Umožňují tedy najít cokoliv, o čem uživatel ví, že to hledá.
Zapojení online doporučovacích systémů může uživatelům dále usnadnit
orientaci v nabídce a zpříjemnit rozhodování. Na rozdíl od vyhledávačů mohou
doporučovací systémy nabídnout i položku, o které uživatel netušil, že existuje, ale
s vysokou pravděpodobností ho zaujme.
Diplomová práce se zabývá doporučovacími systémy a možnostmi jejich
využití pro oblast kulturních portálů, přičemž vychází ze srovnání doporučování akcí
s častěji řešenou úlohou doporučování digitálně dostupných děl. V teoretické části
práce je navržen model domény a metriky podobnosti. Dále jsou popsány možnosti
obohacování dat pomocí vztahů mezi různými objekty, což umožňuje
předzpracováním zvýšit hustotu dat použitých pro doporučování. V praktické části
2
práce byly v offline testu porovnány algoritmy maticové faktorizace s příbuznými
hybridnímy algoritmy na datech z oblasti kultury. Pro tento účel byla do frameworku
LibRec implementována podpora pro práci s obsahovými atributy a dvojice
hybridních doporučovacích algoritmů. Dále byla provedena uživatelská studie
ověřující řešení navržené pro dvojici reálně motivovaných úloh.
Navigace
Úvodní část shrnuje téma práce a rozložení ostatních částí textu.
První kapitola stručně uvádí doporučování, představuje jeho základní pojmy
společně se základními úlohami a postupy oboru. Kapitola druhá zužuje
doporučování na oblast kultury, konkrétně srovnává doporučování kulturních akcí
s doporučováním digitálně distribuovaných děl a popisuje doporučování v prostředí
kulturních portálů. Součástí této kapitoly je model zkoumané domény a
z něj vyplývající možnosti vzájemného obohacování dat.
Třetí kapitolou začíná praktická část práce, jsou představeny tři datové sady a
jejich základní charakteristiky. Dále jsou popsány vybrané metody pro offline testy
včetně výsledků získaných jejich aplikací na jednotlivé sady. Kapitola čtvrtá se
zaměřuje na dvě prakticky motivované úlohy a návrh jejich řešení. Uživatelská
studie, realizovaná v rámci této práce, a její výsledky jsou obsahem páté kapitoly.
Závěrečná část shrnuje výsledky práce. V přílohách se nachází popis
použitých nástrojů a poznámky o metodách vytvořených nebo upravených pro účely
této práce v systému LibRec. Zdrojové kódy a dokumentace nově vytvořených
metod jsou součástí přiloženého CD.

3
1. Doporučovací systémy
Doporučovací systémy (Recomender Systems) jsou skupinou postupů,
algoritmů a softwarových nástrojů. Obecným cílem doporučování na webu je vybrat
z množiny všech dostupných objektů takové, které pro konkrétního uživatele budou
relevantní, což v důsledku směřuje uživatele k jednání v souladu s cíli provozovatele
systému, například uživatel provede další nákup nebo zvýší svou loajalitu k danému
webu. Pro tento účel se využívají znalosti o uživatelích v podobě dříve získané
zpětné vazby, informace o objektech v nabídce, znalost vazeb uživatele na další
osoby v systému nebo kontext aktuálního hledání. S doporučováním se v nějaké
podobě setkáváme v různých prostředích, od internetových obchodů po zpravodajské
weby.
1.1. Koncepty doporučování
Tato sekce představuje základní pojmy, myšlenky a přístupy používané v celé
práci. V závorkách jsou uvedeny anglické, případně další v literatuře používané
názvy.
1.1.1. Základní pojmy
Uživatel (user) je osoba, která přistupuje ke službě. Pro účely
personalizovaného doporučování preferujeme osobu individuálně identifikovanou,
ať už jako registrovaný uživatel nebo pomocí cookies. Služba může ke každému
uživateli registrovat sadu atributů jako jsou věk, pohlaví, používaný jazyk, profesi
nebo region; často ale rozsah i přesnost poskytnutých informací závisí na rozhodnutí
uživatele. Dále služba může ukládat jeho historii interakcí, tedy navštívené stránky
v rámci webu, případně přímo vyjádřené preference.
Objekt (item) je konkrétní obsah, který služba může doporučit uživateli, tedy
zboží v případě internetových obchodů nebo konkrétní stránka obsahu
u informačních webů. I objekty mohou být spojeny se sadou atributů; atributy
objektů bývají dostupné častěji a úplněji než atributy uživatelů, protože jsou často
známy v momentě vkládání objektů do systému a bývají plně ve správě
provozovatele.
4
Zatímco slovo objekt je vyhrazeno pro to, co je doporučováno, výrazy prvek
a entita jsou v tomto textu používány jako synonyma v situacích, kdy nezáleží
na rozdělení uživatelů a objektů.
Pojmem preference označujeme vztah uživatele k jednotlivým objektům.
Typická reprezentace je formou uživatelského hodnocení. Jako tabulku preferencí
označujeme matici uživatel x objekt, jejímiž prvky jsou hodnocení objektů uživateli.
1.1.2. Podobnost
Jednou ze základních myšlenek doporučování je, že objekty, které uživatel
hodnotí kladně, jsou si v nějakém smyslu podobné. Stejně tak uživatelé, kteří jsou si
podobní, budou vyhledávat podobnou skupinu objektů. Na základě předchozího
výběru uživatele tedy můžeme odhadovat, co dalšího bude hodnotit pozitivně.
S podobností je možné pracovat dvěma základními způsoby.
Podobnost založená na obsahu (content) vychází z hledání věcné
podobnosti mezi entitami. Obecné vlastnosti uživatelů i objektů se vyjádří atributy.
Primárně formulujeme vzájemnou podobnost mezi uživateli, případně podobnost
objektů mezi sebou. Některé metody doporučování pracují s objektovým profilem
uživatele, tedy odvozují z dostupných informací, jaké atributy objektů uživatel
preferuje, což umožňuje hledat podobnost mezi uživatelem a objekty.
S atributy se v metodách tohoto typu často pracuje ve formě binarizovaných
vektorů, podobnost je pak určena jednoduchou metrikou, jako jsou cosinová
podobnost nebo Pearsonova korelace vektorů. V pokročilejších obsahově
orientovaných metodách se používají i atributy složitější, například numerické nebo
kategorické. Zdrojem obsahových dat může být i delší text, například doprovodný
popis produktu, ve kterém je možné identifikovat časté výrazy nebo jiná klíčová
slova.
Podobnost podle uživatelských hodnocení (colaborative, kolaborativní)
využívá toho, že pokud skupina uživatelů hodnotila některé objekty podobně, je
zvýšená pravděpodobnost, že se budou shodovat i jejich další hodnocení. Tento
přístup zpracovává tabulku preferencí; hodnocení v ní chybějící jsou odhadována
z hodnocení známých. Podobnost v takovém případě chápeme jako podobnost
známých hodnot v tabulce preferencí.
5
1.1.3. Zpětná vazba
Zpětná vazba, tedy preference uživatele vyjádřené chováním uživatele
v systému, je vstupem pro stavbu modelu i pro vlastní doporučování. Podle způsobu
vzniku ji dělíme na implicitní a explicitní.
Explicitní zpětnou vazbou rozumíme uživatelem vědomě vyjádřené
hodnocení. Může mít podobu napsání recenze, přidělení hvězdiček nebo procent
na stanovené škále, případně jednoduchého hodnocení typu "líbí se mi". V praxi
se lze setkat se zpětnou vazbou vyjadřovanou po seznámení s objektem (hodnocení
shlédnutého filmu) i s hodnocením vyjádřeným předem jako odhad vlastního zájmu
o objekt, dříve než je možné hodnotit skutečnou spokojenost (vyjádření typu mám
zájem o koncert). Na webech více provázaných s doporučovacím systémem uživatel
může hodnotit nejen objekty, ale přímo jednotlivá doporučení. Informace
o preferencích uživatele může být získávána z příslušného webového projektu nebo
být obohacena z dalších zdrojů, zejména pomocí profilů a chování uživatelů
na sociálních sítích.
Za implicitní zpětnou vazbu považujeme informace získané pozorováním
chování uživatele, jako jsou informace o navštívení stránky, provedení nákupu,
zobrazení detailu objektu nebo opakování návštěvy. V některých systémech je možné
sledovat i podrobnější údaje jako pohyb myši, scrollování nebo čas strávený
na stránce. Ve většině systémů mohou být implicitní informace dostupné v řádově
větším množství, ale jejich vyhodnocení je obtížnější.
Zatímco explicitní zpětná vazba v každém jednotlivém hodnocení přímo
vyjadřuje nějakou preferenci uživatele, v případě implicitních dat je jednotlivý
záznam méně jasný ukazatel, který získává větší význam opakovanou interakcí
uživatele s daným objektem. Implicitními daty v doporučování se zabývá práce
Hu&al (2008).
1.2. Úlohy a principy doporučování
Úlohu uživatelských preferencí lze nahlédnout dvěma způsoby, jako odhad
hodnocení (Rating prediction), tedy jak by uživatel hodnotil jednotlivé dosud
nehodnocené objekty, a jako odhad pořadí (Ranking, odhad relativního hodnocení),
tedy které objekty by hodnotil lépe než ostatní.
6
Řešení uvedených úloh vychází z několika základních konceptů. V literatuře i
praxi převažují algoritmy vycházející z první dvojice, doporučování založeného
na obsahu a kolaborativním přístupu, a proto je jim v tomto přehledu věnována větší
pozornost. Vybrané další postupy, které lze aplikovat na úlohy doporučování, jsou
shrnuty ve společné podkapitole.
Přestože se nejedná o samostatnou úlohu nebo metodu, uvedeme na tomto
místě ještě jeden v doporučování důležitý pojem. Pomalý start (cold start) se nazývá
situace, kdy nejsou k dispozici dostatečná data pro využití některé doporučovací
metody. Typicky nastává při přidání nového prvku do systému. Náchylnost
na problém pomalého startu je jedním z relevantních parametrů při hodnocení
jednotlivých algoritmů.
1.2.1. Metody založené na obsahu
Metody založené na obsahu (Content-based) doporučují podle vlastností
uživatelů a objektů. Základní zpracování se skládá z analýzy a předzpracování
obsahových dat, tvorby profilů a samotného doporučování. Pro tvorbu doporučení je
rozhodující kvalita profilů; typicky je snadné přidání nového objektu, protože
informace bývají dostupné, zatímco při přidávání nového uživatele je potřeba jeho
součinnost při vytváření profilu a většinou se profil vyvíjí postupně.
Příkladem analytického modulu obsahových metod jsou systémy práce
s klíčovými slovy jako zdrojem pro vektorovou podobnost. Klíčová slova mohou být
získávána z metod pracujících s váhou termínů v textu (TD-IDF), nebo pomocí
složitějších systémů založených na ontologiích. Obecně jsou používány metody
strojového získávání informací (information retrieval).
Tvorba profilu vychází z metod strojového učení. Podle zaměření systému
se používají pravděpodobnostní, zejména bayesovské metody. Samotné
doporučování je typicky realizováno na základě vektorové podobnosti, případně
pomocí rozhodovacích stromů. Přehled principů využívaných v doporučování
založeném na obsahu zpracovali Lops&al (2010).
7
1.2.2. Metody založené na hodnocení ostatních uživatelů
Metody založené na hodnocení ostatních uživatelů zpracovávají tabulku
preferencí a z dostupných hodnot odhadují hodnoty chybějící. Existují dva základní
typy.
Metoda nejbližších sousedů (K Nearest Neighbours, KNN) je původem
klasifikační metoda. Při doporučování jsou hledány nejpodobnější objekty
porovnáním vektorů z tabulky preferencí. Konkrétní neznámý odhad hodnocení
objektu uživatelem je dopočten z toho, jak tento objekt hodnotí danému uživateli
nejpodobnější uživatelé, bráno podle celé tabulky preferencí.
Faktorizace matic (matrix Factorization, Matrix Decomposition) je
matematická metoda rozkladu tabulky preferencí, tedy velké matice Uživatelé x
Objekty na dvojici řádově menších matic. Společný rozměr nových matic se nazývá
Faktory a zpětným vynásobením matic UxF a FxI získáváme matici, jejíž hodnoty se
od známých hodnot z původní matice preferencí liší co nejméně. Nově získané
hodnoty se pak použijí jako odhad hodnocení.
Rozklad na faktory není pouze matematickou operací. V doporučování se
předpokládá, že touto metodou je možné postihnout hlubší společné vlastnosti entit.
Takzvané Latentní faktory jsou vlastnosti, které se v datech nacházejí přirozeně, i
když zrovna k faktorizaci nedochází. Základní prací metod založených na faktorizaci
matic je Koren (2008).
1.2.3. Rozšiřující metody
Při řešení úloh doporučování jsou často využívány poznatky z oborů řešících
příbuzné otázky.
Zohlednění kontextu (Context aware) doporučování vychází z myšlenky,
že uživatel má v různých situacích různé potřeby a preference. Uživatele může
zajímat objekt, například restaurace, která se v daném momentě nachází poblíž.
V oblasti filmu může zvolit jiný žánr v neděli dopoledne, kdy se dívá s celou
rodinou, a jiný žánr večer, kdy sledují jen dospělí členové domácnosti. Podobně
pro sledování na displeji mobilního telefonu může být vhodnější sitcom, zatímco
prostředí domácího kina je vhodné i pro velký výpravný snímek.
Znalostní systémy (Knowledge-based) komplexněji využívají obsahové
informace. Uživatel nějakou formou vyjádří své přání nebo požadavek.
8
Doporučovací systém je vybaven znalostmi o vlivu jednotlivých atributů objektu
na vlastnost požadovanou uživatelem. Tento přístup umožňuje uživateli vyjádřit
preferenci v pojmech jako pohodlný, designový, vhodný i pro vozíčkáře, městský
nebo herní, a obdržet relevantní doporučení.
Analýza sociálních sítí vychází ze situace, kdy jsou známy vazby uživatele
k dalším uživatelům, a lze předpokládat, že ho zajímají objekty, které získávají
oblibu v jeho komunitě. Přístup je v základu podobný kolaborativnímu filtrování,
odlišuje ale neznámého podobného uživatele od uživatele, se kterým je aktuální
uživatel v přímém kontaktu. Studium vztahů na sociálních sítích je samostatně
se rozvíjejícím oborem, v poslední době je ale v doporučování čím dál běžnější
obohacování dat o informace z tohoto typu zdrojů.
1.2.4. Skládání a hybridizace
Není překvapivé, že každý z uvedených základních přístupů je vhodný
pro doporučování v jiné situaci; vyšší hustota známých hodnocení svědčí spíše
kolaborativním přístupům, zatímco nový prvek s dosud neexistujícím hodnocením je
snáze uchopitelný pro přístup založený na obsahu. Takto odlišné situace mohou
nastávat i v rámci jednoho reálného doporučovacího systému. Proto často dochází
ke kombinaci více přístupů.
Využití metod různého typu v doporučovacím systému je možné realizovat
více způsoby. Lze vybrat doporučovací metodu podle charakteristik aktuální situace,
určit více způsoby dílčí doporučení a zkombinovat je do jednoho výsledku nebo
použít doporučovací algoritmus, který prvky více přístupů kombinuje přímo v sobě.
Řešení posledního uvedeného typu označujeme jako hybridní algoritmy.
1.3. Metody a metriky hodnocení doporučování
Při práci s doporučovacími systémy je důležité mít možnost jednotlivé
systémy, algoritmy nebo parametry porovnat. Tato sekce uvádí základní metody a
metriky hodnocení.
9
1.3.1. Metody hodnocení kvality doporučovacího systému
Offline test
Offline test je přístup k testování založený na použití dříve zaznamenaných
dat. Umožňuje základní ověření chování algoritmů na konkrétních datových sadách a
jejich srovnání.
Typická realizace obsahuje rozdělení dat na trénovací a testovací část,
v některých případech je oddělena ještě část validační. Trénovací data představují
známou historii a slouží pro přípravu modelu doporučovacího algoritmu. Testovací
část dat je doporučovacímu systému skryta, systém je dotázán na odhad příslušné
hodnoty a výsledek je porovnán s hodnotou skutečnou. Validační část dat slouží jako
testovací data při ladění parametrů a nejlepší výsledek této fáze je použit
s testovacími daty.
Hlavní výhodou offline testů je rychlost a nízké náklady, protože nepotřebuje
skutečné uživatele. Je možné jeho provedení mnohokrát opakovat, což je výhodné
při hledání vhodného nastavení parametrů algoritmů.
Nevýhodou je nejasná míra přenositelnosti výsledků, protože se testování
často odehrává na malé části dat, u které není zaručeno, že dobře reprezentuje
potenciální celá data. Podle Stecka&al (2013) rozložení dostupných a chybějících
hodnot není náhodné a už samotný fakt, že uživatel něco ohodnotil, hodnocené prvky
odlišuje od ostatních. I přes zmíněné omezení se jedná o efektivní metodu
pro základní testování a zúžení seznamu kandidátů pro náročnější, ale lépe
vypovídající testy.
Uživatelská studie
Formou uživatelské studie (User study) lze testovat a porovnávat dílčí
algoritmy, doporučovací systémy i celé weby využívající doporučování. Není vhodná
pro zjišťování parametrů, ale umožňuje zjistit vlastnosti přesahující rámec offline
testu.
V uživatelské studii je subjekt testování předložen skupině uživatelů, kteří
plní několik úloh podle zaměření studie. Mohou být zaznamenávány konkrétní
výsledky i pozorována celková interakce se systémem. Tímto způsobem je možno
získat odpovědi na kvalitativně orientované otázky. Tématem uživatelské studie
se podrobně zabývá Dooms&al(2011).
10
AB testování
Při AB testování jsou srovnávány dvě varianty doporučovacího systému
v reálné nebo realitě co nejbližší situaci. Uživatelé jsou po nějakou dobu bez jejich
vědomí náhodně přiřazeni k verzi A nebo B (samozřejmě jich může být i více) a
provádějí běžnou interakci s webem. Při logování jejich akcí je zaznamenávána
zobrazená varianta.
Mezi hlavní výhody takového postupu testování patří, že oproti situaci, kdy
by algoritmy byly testovány jeden po druhém, odpadá vliv mimořádných událostí,
sezónnosti nebo běžného růstu návštěvnosti. Navíc tento přístup umožňuje porovnat
vliv testovaných variant doporučování v cílových metrikách celého systému,
což mohou být nejen prokliky a explicitní hodnocení objektů, ale i objem
uskutečněných prodejů. Nevýhodami jsou malý počet testovatelných variant za daný
čas a riziko, že použití špatné metody může poškodit vztah uživatele ke službě nebo
výsledky systému v době testování.
AB testování je často využíváno pro zjištění přínosu jinými metodami
vybrané nejnadějnější varianty na zlepšení doporučování oproti stávajícímu řešení.
V takovém případě jsou někteří uživatelé systému po stanovenou dobu obsluhováni
stabilní a jiní experimentální verzí.
1.3.2. Metriky hodnocení kvality doporučování
Při hodnocení kvality doporučování můžeme sledovat různé parametry.
Některé lze vyhodnocovat strojově, jiné jsou založeny na dojmu a spokojenosti
uživatele.
Statistické metriky hodnocení kvality doporučovacího systému
Úloha odhadu hodnocení je vyhodnocována jako normovaný rozdíl
odhadovaného hodnocení oproti hodnocení skutečnému. Rozšířené jsou metriky
Mean Absolute Error a Roor Mean Squere Error.
Při vyhodnocování úlohy odhadu pořadí je zajímavé především pořadí na
prvních místech. Metriky typu přesnost/úplnost (precision/recall) vyjadřují překryv
doporučené skupiny a relevantních objektů. Přesnost hodnotí, v jaké míře jsou
v doporučené n-členné skupině přítomny objekty, jejichž relevance je
11
potvrzena. Úplnost měří, jaká část objektů, které jsou relevantní, je přítomna
v doporučené skupině.
Při vyhodnocování úlohy pořadí může být kromě vybrané skupiny důležité
i přesné seřazení prvků. Rozšířeným zástupcem tohoto směru je metrika NDCG
(Normalized Discounted Cumulative Gain), která je definována jako poměr
kumulativní relevance řešení a ideální kumulativní relevance, která by byla
dosažena, kdyby všechny objekty byly seřazeny správně. Technicky je kumulativní
relevance definována tak, že relevance každého prvku je dělena dvojkovým
logaritmem jeho pořadí. Metriky tohoto typu se dříve používaly primárně v úlohách
vyhledávačů a získávání informací z dokumentů.
Metrika různost (Diversity) slouží jako jednoduché matematické vyjádření
odlišnosti objektů. Pro doporučenou skupinu kontroluje, jak vzdálené jsou od sebe
jednotlivé dvojice objektů v prostoru tabulky hodnocení, preferována je odlišnost
vyšší. Tato metrika odpovídá myšlence, že sice chceme doporučovat objekty blízké
známým pozitivním hodnocením uživatele, na druhou stranu však chceme, aby
doporučení bylo zajímavé a pestré a mělo tak větší šanci uživatele skutečně
zaujmout.
Uživatelské hodnocení kvality doporučení
Uživatelé většinou vědomě nehodnotí doporučovací systém jako celek.
Vnímají však jim zobrazené konkrétní doporučení a subjektivní uživatelská
spokojenost patří k rozhodujícím faktorům úspěšnosti doporučovacího systému,
respektive webového projektu jako celku.
Pu&al (2010) formulovali třináct otázek pro zjišťování parametrů uživatelské
spokojenosti s doporučením a Dooms&al (2011) ukázali vztahy mezi některými
z nich.

12
Uživatelé hodnotí pozitivně, když považují za srozumitelné (transparency),
proč je jim předloženo dané konkrétní doporučení. Porozumění doporučení je pro ně
relevantní při posuzování celkové důvěryhodnosti (trust) doporučovače. Některé
systémy proto svá doporučení přímo vysvětlují, například služba Last.fm uživateli
nejdříve doporučuje obecné populární objekty, a hned po získání prvních hodnocení,
většinou implicitních, začne doporučení uživateli personalizovat a vysvětlovat
(Obrázek 1).
Obrázek 1: Vysvětlená doporučení Last.fm
Druhou zajímavou skupinu subjektivních parametrů tvoří známost
(familiarity), respektive novost (novelty) doporučených objektů, společně
s uživatelem vnímanou růzností (diversity) celého doporučení. Z pohledu uživatele
je žádoucí přiměřená novost a rozmanitost, která vede k objevování objektů, které by
sám nehledal. Doporučování, které vede k objevení nečekaného zajímavého objektu,
je v literatuře označováno také jako serendipity.
Kombinace těchto parametrů společně přispívá k uživatelskému vnímání
užitečnosti (usefulnes) a celkové spokojenosti (satisfaction) uživatele
s doporučením.
13
2. Doporučování v oblasti kultury
Tato kapitola zužuje otázku doporučování na téma doporučování v oblasti
kultury. V první části se zabývá doporučováním digitálně distribuovaných děl
ve srovnání s doporučováním kulturních akcí, což slouží jako východisko
pro analýzu doporučování kulturním portálem. Druhá část této kapitoly popisuje
model domény a vztahy mezi různými typy objektů, které lze použít pro zahušťování
dat.
Objekty doporučování v kultuře se nachází mezi dvěma extrémy, které
reprezentují digitálně distribuovaná díla a jednorázové akce. Speciální případy,
například živý přenos opery z New Yorku v kinech, pak představují určitou
kombinaci jejich parametrů. Příklady datasetů obou typů jsou analyzovány
v následující kapitole.
2.1. Doporučování digitálně distribuovaných děl
Mezi digitálně distribuovaná díla řadíme filmy, knihy, zvukové nahrávky,
případně některá grafická díla. V zájmu přehlednosti bude v dalším textu používána
filmová terminologie, ale předmětem této kapitoly jsou společné vlastnosti digitálně
distribuovaných děl.
Digitálně distribuovaná díla spojuje široká dostupnost ve smyslu časovém,
geografickém i v počtu uživatelů, kteří mohou zároveň sledovat stejné dílo. Typické
prostředí doporučování je internetový obchod nabízející díla po menších celcích
(například prodej jednotlivých písniček) nebo online půjčovna s obchodním
modelem založeným na předplatném. Cílem provozovatele je získání a udržení
co největšího počtu zákazníků, kteří opakovaně platí malé částky.
Z pohledu uživatele jsou v každém konkrétním případě dostupná všechna díla
v systému a všechny nezvolené objekty ve výběru zůstávají pro další příležitost.
Mezi díly je tedy velká konkurence. Náklady špatné volby pro uživatele nejsou příliš
vysoké, protože uživatel může kdykoliv ukončit sledování jednoho filmu a pustit si
jiný, což snižuje rizika experimentování.
2.1.1. Zpětná vazba u doporučování děl
Standardem oboru byla dlouhou dobu hvězdičková nebo procentuální
vyjádření spokojenosti, v poslední době jsou nahrazována jednoduššími formami,

14
například online půjčovna filmů Netflix v současné době pracuje s hodnocením typu
palec nahoru, palec dolů. Uživatelé systémů doporučujících distribuovaná díla a
sbírajících explicitní zpětnou vazbu hodnotí typicky po zhlédnutí, takže provedená
hodnocení jsou skutečným vyjádřením uživatelovy spokojenosti s objektem.
Uživatel v praxi nikdy nehodnotí náhodný vzorek. Hodnotí jenom takové
objekty, u kterých už předem odhadoval, že by ho mohly zajímat (podle vlastního
uvážení nebo důvěry v návrh doporučovacího systému), a proto si je vybral
ke sledování a dal jim tak příležitost být hodnocené. Proto udělená hodnocení
nebývají rozdělena rovnoměrně.
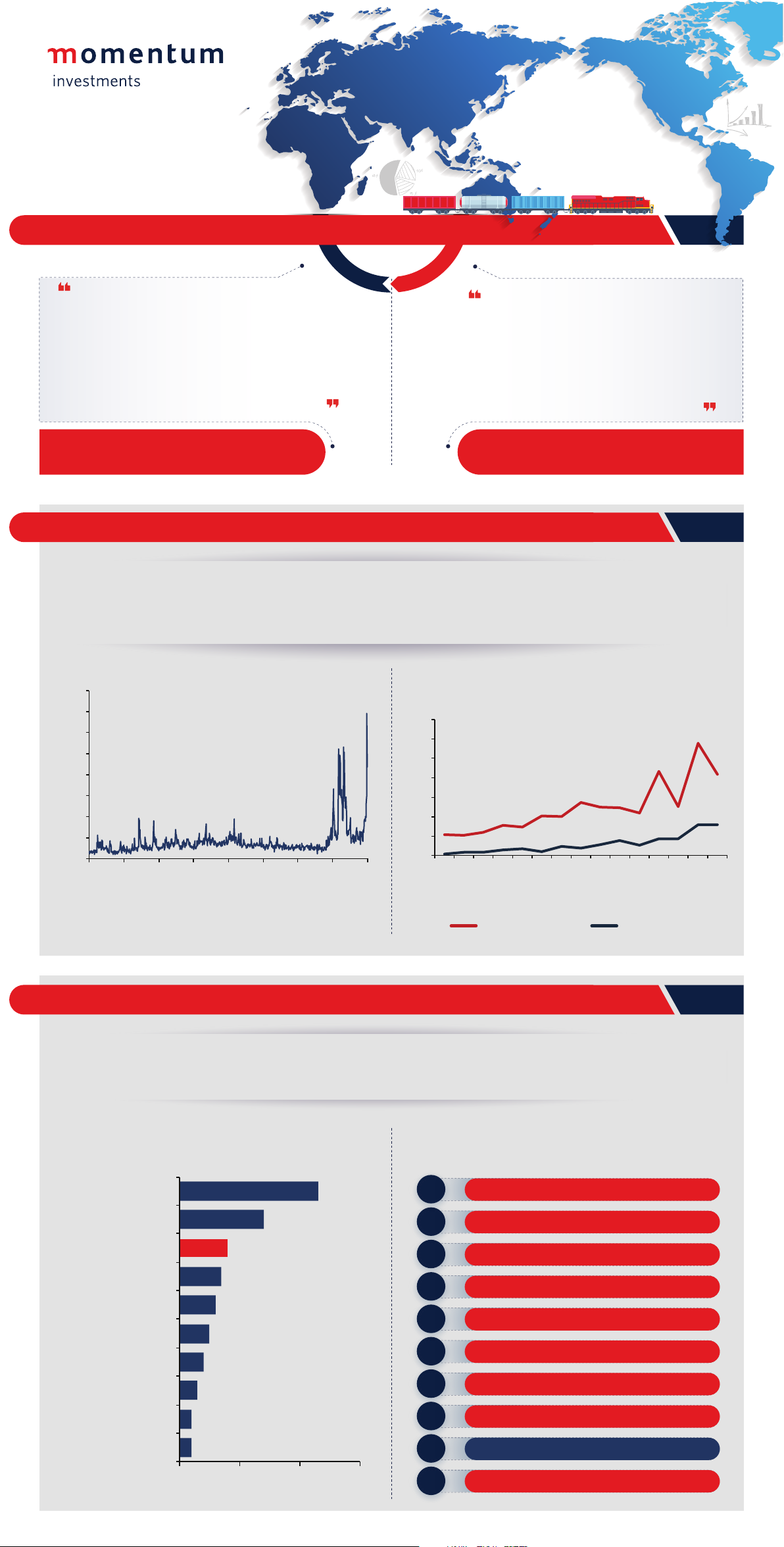
Například v datech ze sady knihy DBpedia je na škále 1-5 hvězdiček
průměrné hodnocení 3,9 a nejčetnější udělené hodnocení 4 (Obrázek 2). Tomu
odpovídá i rozložení uživatelů podle jejich průměrného hodnocení, kdy dvě třetiny
uživatelů udělily hodnocení s průměrem mezi 3,5 a 4,5 (Obrázek 3).
Obrázek 2: Histogram hodnocení sady Knihy

15
Obrázek 3: Histogram průměrných hodnocení
Úloha doporučování digitálně distribuovaných děl je zkoumaná poměrně
často. Mezi nejslavnější případy patří Netflix Challenge.
2.2. Doporučování událostí
Události (event, one-and-only-item, akce) typicky probíhají v daném čase
na konkrétním místě, často pro omezený počet uživatelů. Typickým příkladem jsou
koncerty, jejichž terminologie bude používána v této kapitole.
Z pohledu uživatele si události probíhající v podobném čase navzájem
konkurují a nevybraná akce nezůstává v nabídce automaticky. Často ale existují další
akce s podobnými parametry (divadelní představení má větší množství repríz,
koncerty se mohou opakovat několik dnů po sobě v případě turné, nebo naopak
v pravidelném intervalu).
Návštěva událostí znamená pro uživatele často vyšší náklady než zhlédnutí
digitálního obsahu, ať už finanční (vstupné, doprava, náklady konzumace v místě
akce), časové (přesný čas začátku, doprava) nebo společenské (obtížnější odchod
z akce v průběhu), uživatel jich proto navštíví ve srovnání s digitálně
distribuovanými díly méně, a může být ve výběru obezřetnější.
2.2.1. Zpětná vazba u doporučování akcí
V případě doporučování akcí je sbírání zpětné vazby po skončení akce
možné, ale méně časté. Některé datové sady proto pracují s předem vyjádřeným

16
zájmem, který odpovídá uživatelovu odhadu jeho budoucího hodnocení. Vzhledem
k tomu, že uživatel nemůže porovnat více akcí ze stejného data, ani z explicitního
hodnocení provedeného po návštěvě akce by nebylo možné s jistotou vyhodnotit,
jestli jeho vlastní intuitivní odhad hodnocení/pořadí priorit byl správný.
Na druhou stranu, pokud by si uživatelé vybírali akce alespoň stejně dobře
jako knihy, a tedy si většinově vybírali události, se kterými budou spokojeni, je
možné předpokládat, že takto vzniklá chyba v hodnoceních není příliš velká.
Množství uživatelských hodnocení je u akcí, jakožto objektu omezeného
malým množstvím příležitostí být uživatelem zvolen, typicky řidší než u digitálně
distribuovaných děl. Navíc pokud bychom brali v úvahu jen samotné akce, ocitli
bychom se prakticky ve stavu permanentního studeného startu.
Tématu doporučování akcí se věnuje například Dooms&al (2011). V roce
2013 bylo doporučování akcí v mezinárodním prostředí tématem soutěže webu
Kaggle.com. Data ze soutěže nebyla uvolněna pro výzkumné využití. Vzhledem
k mezinárodní datové sadě není překvapivé, že účastníci často zdůrazňovali práci
s regionem a úlohu odhadu regionu z dat
1
.
2.3. Kulturní portál
Kulturním portálem je pro účely této práce myšlena webová služba
poskytující agregované informace o kulturních událostech, jako jsou koncerty nebo
divadelní představení, v kalendářní formě. Weby tohoto typu často nabízejí i vlastní
profily umělců.
2.3.1. Doména
Nejběžnější akce na kulturních portálech je typu koncert, proto bude použit
jazyk koncertů pro popis celé domény.
Objekty ve světě kulturního webu jsou umělci (kapely, soubory, zpěváci),
akce (události, koncerty, představení) a místa (kluby, divadla). Zatímco umělci a
místa existují dlouhodobě a můžeme je tedy označit jako objekty trvalé, akce jsou
typicky kombinací jednoho či více umělců, místa a času a vzhledem k tomu, že už
v momentě jejich vzniku v systému je známo i datum, ke kterému ztratí platnost, je
možno je označit za objekty dočasné.
1
http://www.rouli.net/2013/02/five-lessons-from-kaggles-event.html
17
Pro účely doporučování je vztah uživatele k akcím možné modelovat pomocí
trvalých objektů a úlohu doporučování událostí transformovat na doporučení
vhodného stabilního objektu, která má právě aktivní vhodnou vazbu dočasného typu.
2.3.2. Podobnost a převody v doméně
Podobnost v doméně kulturních portálů lze vnímat standardními způsoby,
tedy jako podobnost uživatelských profilů nebo podobnost vektoru hodnocení.
Vzhledem k provázanosti různých objektů je podobnost možné definovat i
dalšími způsoby. Pokud bychom každý prvek v systému považovali za uzel v grafu a
provedená pozitivní hodnocení jako hrany, bylo by možné v rámci podobnosti
posuzovat například délku cesty mezi dvěma entitami.
Znalost vztahů mezi objekty lze využít i k převádění informací a zahušťování
konkrétních datových sad. Pokud známe hodnocení uživatele pro umělce, můžeme
ho použít k odhadu hodnocení akce, na které vystupuje. Podobně pokud uživatel
opakovaně navštěvuje akce na nějakém místě, je možné dočasné informace o vztahu
k proběhlým akcím využít jako informaci o vztahu k danému místu konání.
2.3.3. Zpětná vazba na kulturním portálu
Uživatelé mohou vyjadřovat vztah ke všem typům objektů. U hodnocení
umělců a míst lze předpokládat, že uživatel hodnotí jemu známé věci. Zájem
o události většinou vyjadřuje ještě před konáním akce, tedy se jedná o odhad
budoucího hodnocení uživatelem, který ale nezaručuje, že uživatel byl s hodnocenou
událostí skutečně spokojen.
Z pohledu použití jako vstupu pro trénování doporučovacího systému tak
vzniká určitý paradox, kdy zájem o profil umělce je jako zpětná vazba spolehlivější,
zatímco zájem o akci, případně přímo nákup vstupenky, je hodnotnější z pohledu
provozovatele systému.
2.3.4. Obsahová data pro kulturní akce
Při práci s doporučováním kulturních akcí jsou často dostupné některé typy
obsahových dat.
18
Textové profily
Textové profily kapel mohou obsahovat objektivně popsatelnou složku
vystoupení konkrétního umělce, jak je nástrojové obsazení. Dále v nich bývají
specifická klíčová slova typu žánr.
Na druhou stranu tyto faktické informace samy o sobě nestačí k doporučení,
například „nejlepší houslista“ může být označení pro Vanessu Mae, Pavla Šporcla i
sólistu místní základní umělecké školy.
Po návštěvníka akce jsou důležité i subjektivní parametry typu kvalita nebo
zábavnost, které popisují spíše show než uměleckou část projevu, a které se snáze
než z marketingového textu zjišťují z reakcí ostatních uživatelů, tedy kolaborativními
metodami.
Žánr
Rozlišování žánrů je příkladem lidské snahy zorientovat se v nabídce a
vyjádřit určitou podobnost. Na straně druhé mnoho umělců žánry odmítá jakožto
příliš zjednodušující a mnozí mají tendenci pro svou hudbu definovat žánry vlastní,
nebo alespoň speciální kombinace žánrů vlastních. Pro strojové zpracování dat je
práce s žánry výhodná, protože na nich lze definovat taxonomii, což umožňuje
snadno změnit úroveň podrobnosti pro zpracování. Přínos hierarchického vnímání
žánrů ukázali Li a Ogihara (2005).
2.3.5. Příklady doporučování na českých kulturních webech
Na českých kulturních webech není zatím algoritmické doporučování příliš
rozšířené. V této sekci je představena dvojice větších kulturních webů, které nějakým
způsobem pracují s doporučováním.
Bandzone.cz
Pravděpodobně největší český web zaměřený na oblast populární hudby
v širším slova smyslu je www.bandzone.cz. Většinu jeho obsahu tvoří profily kapel a
informace o koncertech vyplňovaných přímo umělci. Umožňuje vyhledávání akcí
podle data a žánru.
Profily umělců nabízí dvě sady prokliků. Takzvané kapely spřízněné jsou
definovány přímo umělci. Kapely podobné jsou stanoveny na základě počtu
19
společných fanoušků. Takto stanovená podobnost vede k výraznému preferování
umělců známých do role podobných kapel. Čím populárnější je kapela, tím spíše se
najde větší množství jejích fanoušků mezi uživateli, kteří sledují nějakého
konkrétního umělce.
V červnu 2017 bylo registrováno 41 48 skupin a 205 619 uživatelů. Na tomto
místě je třeba poznamenat, že profil umělce je vždy spravován z profilu
uživatelského typu.
Mezi zdroje příjmů patří reklama, včetně té zadané kapelami. Dále Bandzone
spolupracuje na prodeji vstupenek se systémem SMSticket.cz.
Goout.cz
Goout.cz je rychle rostoucí projekt zaměřený na vyhledávání kulturních akcí.
Profily umělců a míst, spravované projektem Goout obsahují i zvukové materiály
nebo videa. Ačkoliv je web zaměřen na prodej vstupenek, prodejní je pouze malá
část návštěv a doporučování událostí je jen dílčí cíl, velká část interakcí směřuje
spíše k budování vztahu, tedy například získání a udržení oprávnění pro zasílání
newsletteru.
Web doporučuje svým návštěvníkům aktuálně populární události různých
typů jako je koncert nebo divadlo. Při návštěvě profilu některého umělce doporučuje
umělce podobného druhu, například další písničkáře.
2.3.6. Společná volba skupiny
Zatímco knihu často čte jednotlivec sám, už u domácího sledování filmů
vzrůstá průměrný počet společně sledujících. Návštěva kulturní akce je také často
záležitostí páru, rodiny nebo skupiny přátel. Z účastníků uživatelské studie (Kapitola
5) jen čtvrtina běžně vyráží na kulturní akce samostatně.
V praxi není příliš časté, že by webový doporučovací systém měl informace
o složení skupiny plánující navštívit nějakou akci společně dříve, než dojde k jejímu
vytvoření. Přirozeným prostředím pro práci s informacemi o skupině jsou sociální
sítě. Doporučováním v této oblasti se zabývá Zhang&al (2013).

20
3. Datové sady a offline testy
V této kapitole jsou představeny datové sady, vybrané algoritmy a framework
pro jejich běh. Cílem bylo vyzkoušet, jak na daných sadách fungují vybrané
algoritmy, a získat tak konkrétnější představu před řešením úloh popsaných v další
kapitole. Kapitola obsahuje i výsledky provedených offline testů.
3.1. Datové sady
Pro první fázi experimentů byly použity tři sady dat, dvě veřejně dostupné
sady obsahující hodnocení knih, respektive filmů, a anonymizovaná sada z českého
kulturního portálu.
Datasety byly obohaceny o obsahová data. Pro účely použití v hybridních
algoritmech byly atributové záznamy binarizovány a zpracovány do formy matice
vztahů Objekt x Atribut.
3.1.1. Knihy
Sada uživatelských hodnocení knih, která byla zveřejněna pro účely soutěže
The Linked Open Data-enabled Recommender Systems Challenge při konferenci
ESWC 2014
2
.
Základní charakteristiky shrnuje Tabulka 1.
Tabulka 1: Charakteristika sady Knihy
Počet uživatelů
6181
Počet hodnocených objektů
6166
Počet hodnocení
75897
Hodnoticí škála
0-5, pět nejlepší.
Hustota hodnocení
0,2%
Max. počet hodnocení od 1 uživatele
24
Max. počet hodnocení 1 objektu
1047
Průměrné hodnocení
3.87
Medián hodnocení
4
Standardní odchylka
0,98
2
http://challenges.2014.eswc-conferences.org/index.php/RecSys#DBbook_dataset

21
Kromě numerických uživatelských hodnocení jsou pro objekty dostupné i
další informace přes systém DBPedia (Lehmann&al, 2015). DBPedia je otevřený
projekt zpřístupňující data z uživateli rozšiřované online encyklopedie Wikipedia
ve strukturované formě propojené odkazy (Linked Online Data). Data jsou dostupná
k dotazování přes rozhraní jazyka SPARQL.
Obrázek 4: DBpedia ukázka
Z atributů dostupných pro knižní data v projektu DBpedia je část pro účely
doporučování nepříliš vhodná (ISBN), část potenciálně použitelná (autoři nebo země
původu). Pro prvotní ověření vlivu byl zvolen atribut žánr, který má nejpříznivější
vlastnosti: pro knihy jich je použito méně než 200, každému objektu je přiřazen
alespoň jeden, sady žánrů se mezi různými objekty různě překrývají.
3.1.2. Filmy
Druhou použitou veřejně dostupnou sadou dat je Movielens 1000k
Harper&al (2015). Jedná se o sadu uživatelských hodnocení filmů se základními
charakteristikami (Tabulka 2) podobnými sadě Knihy.

22
Tabulka 2: Charakteristika sady Filmy
Počet uživatelů
6040
Počet hodnocených filmů
3706
Počet hodnocení
1000522
Hodnoticí škála
0-5, 5 nejlepší
Hustota hodnocení
4.4%
Max. počet hodnocení od 1 uživatele
2314
Max. počet hodnocení 1 objektu
2991
Průměrné hodnocení
3.58
Medián hodnocení
4
Standardní odchylka
1,13
3.1.3. Portál
Jako třetí sada byla analyzována anonymizovaná data z několika měsíců
provozu českého serveru goout.cz v roce 2014. Data mají formu několika
provázaných tabulek se zpětnou vazbou typu „líbí se mi“ nebo „stránka navštívena“,
tedy pouze pozitivního typu. Počáteční stav dat zachycujících vztah uživatelů a
umělců shrnuje Tabulka 3.
Tabulka 3: Charakteristika dat Portál
Počet uživatelů
1449 (s alespoň jedním hodnocením)
Počet objektů
13655 typu Umělec
Počet hodnocení
52400
Hodnoticí škála
1
Hustota hodnocení
0,2%
Max. počet hodnocení od 1 uživatele
25
Max. počet hodnocení 1 objektu
2991
Průměrné hodnocení
nemá význam
Medián hodnocení
nemá význam
Standardní odchylka
nemá význam
Kromě tabulky pro vztah uživatel, umělec obsahují data podobné tabulky
zachycující vztah uživatelů k místům a akcím.
Dále jsou dostupná data tvořená záznamy o všech otevřených stránkách
za sledované období, které obsahuje i údaje o prohlížení neregistrovaných uživatelů.

23
Tabulka 4: Další data v sadě Portál
Počet hodnot
3 000 000
Počet unikátních sessions
791 928
Počet zobrazení stránek bez přehledových
1873369
Počet zobrazení stránek typu umělec
262 251
Počet různých zobrazených stránek typu umělec
7 957
Je zřejmé, že tato sada dat se velice liší od první dvojice. Jedná se sice z větší
části o data získaná jako explicitní hodnocení, ale nebyla sbírána ve formě
hvězdičkového, nebo jiného škálového, hodnocení, ale pouze formou „líbí se mi“.
Tato situace se někdy označuje jako positive-only feedback (jen pozitivní zpětná
vazba). Doporučováním v těchto podmínkách se zabývá například Vinagre (2014).
Další rozdíl oproti předchozím datovým sadám spočívá v tom, že uživatelé
mohli vyjádřit pozitivní vztah k objektům více typů (událost, interpret, místo).
Hustota každé samostatné sady je poměrně nízká a existují uživatelé i objekty
s nulou hodnocení. V tomto bodě se nejedná o odlišnost na úrovni zdrojových dat,
ale první dvojice datových sad byla pro účely výzkumného použití předzpracována a
položky s počtem hodnocení pod stanovenou hranici nebyly zahrnuty.
Pro další zpracování vznikly tři varianty dat.
Sada 1 je tvořena původními daty uživatel, umělec.
Druhá sada je obohacena o vztahy uživatel, umělec získané převedením
vztahů uživatel, akce na jednotlivé interprety.
Třetí sada vznikla spojením explicitního hodnocení umělců
registrovanými uživateli a implicitního hodnocení, tedy zobrazení profilů
umělců uživateli neregistrovanými. Při tomto obohacování byly zahrnuty
jen sessions s alespoň třemi navštívenými profily kapel. Vyřazeny byly i
záznamy, kdy návštěvník navštívil některý objekt jako jediný a tedy by
pro kolaborativní algoritmy neměl velký přínos.
Prohlížení uživateli registrovanými, tam kde bylo identifikováno,
zahrnuto nebylo, protože v tomto případě se oni zjevně rozhodovali, které
prvky označit jako oblíbené a které ne. Výsledné datové sady popisuje
Tabulka 5.

24
Tabulka 5: Nové sady Portál
Sada
Počet umělců
Počet hodnocení
Uživatel_umělec_1
1584
5771
Uživatel_umělec_2
2211
9253
Uživatel_umělec_3
3829
32888
Implicitní data použitá k obohacení vztahu Uživatel x Umělec ve třetí datové
sadě je zajímavá i tím, že seznam nejpopulárnějších umělců podle implicitních dat se
se seznamem nejpopulárnějších umělců podle registrovaných uživatelů překrývá jen
z malé části.
Obsahová data
Sada portál obsahová data typu žánr obsahuje v sobě. Jedná se tedy
o odlišnou sadu žánrových kategorií, než v případě knih. Žánrová data jsou z velké
části založena na sebehodnocení umělců
Některé typy vazeb z modelu, které se nehodí k obohacování základní tabulky
hodnocení, lze považovat za další zdroj podobnosti obsahového typu, například
vyjádřené vztahy k místům.
Při práci s obsahovými atributy různého typu, tedy s odlišnou hustotou a
odlišnou distribucí atributů mezi objekty, může být problematické nastavení
požadované podobnosti tak, aby všechny skupiny atributů měly přiměřený vliv
na výsledek.
3.2. Použité metody
Jedním z cílů práce bylo více se seznámit s různými typy doporučovacích
algoritmů. Pro praktickou část práce byly proto postupně vybrány čtyři metody.
3.2.1. Biased MF
Jako první byl zvolen základní zástupce moderní oblasti doporučování,
kolaborativního filtrování, pro škálou hodnocené datové sady Biased Matrix
Factorization v implementaci LibRec podle Koren (2008). Jedná se o algoritmus
určený primárně pro odhad hodnocení.
25
Matice hodnocení je rozkládána na Uživatel x Faktor a Faktor x Objekt
matice plus matice uživatelského i objektového posunu (bias) oproti společnému
základnímu rozkladu celé datové sady.
3.2.2. BPR
Datová sada Portál obsahuje data s pouze pozitivním typem hodnocení.
Druhá zvolená metoda je proto Bayesian Personalized Ranking from Implicit
Feedback v implementaci LibRec podle Rendle et al. (2009). Jedná se o metodu
faktorizace původně určenou pro práci s implicitními daty na úlohách typu
doporučení top k. Faktorizace je založena na oddalování náhodně vybraných dvojic
objektů, z nichž jeden patří do výběru uživatele a druhý nikoliv, v prostoru faktorů.
3.2.3. Hybridní metody
Protože kolaborativní metody, tedy i faktorizace matic, jsou náchylné na cold
start a řídkost dat, ale zároveň dostupná data nevedla k použití klasických na obsahu
založených algoritmů, byla jako druhá zvolena hybridní metoda doplňující základní
faktorizaci o obsahovou podobnost objektů.
Východiskem byla práce Nguyenové a Zhu (2013) zkoumající možnost
zapojení obsahové podobnosti do gradientních metod jako dalšího regularizačního
členu. V článku popsaná metoda pracuje se sousedy objektů identifikovanými
na základě obsahové podobnosti a podporuje podobnost jejich faktorů.
V rámci této práce byly do systému LibRec implementovány dvě takové
varianty metod faktorizace s přihlédnutím k obsahové podobnosti, Content Boosted
Matrix Factorization (jako český název by bylo možné použít Obsahem posílená
faktorizace matic) rozšiřující základní faktorizaci pro úlohu hodnocení a Content
Boosted BPR pro úlohu pořadí. Vstupem pro Obsahem posílené hybridní metody je
soubor obsahující pro každý objekt jeho blízké sousedy z prostoru atributů. Pomocná
třída vytváří tento seznam sousedů, tedy prvků, jejichž vektory jsou si v cosinové
metrice podobnější než stanovený treshold, zpracováním obsahových dat
ze vstupního formátu seznam dvojic objekt-atribut.
Technický popis obou metod a jejich parametrů je uveden v kapitole 3.3.
Zdrojový kód a javadoc dokumentace se nacházejí v příloze práce.
26
3.2.4. CBMF
Content Boosted Matrix Factorization je tedy základní maticová faktorizace
gradientní metodou doplněná o obsahové sousedy. Offline testy ukázaly, že
podporuje metriky top K typu, ale ve srovnání s BiasedMF nemusí obsah úspěšně
nahradit složky uživatelského a objektového posunu.
3.2.5. CBBPR
Content Boosted Bayesian Personalized Ranking je původní algoritmus BPR
rozšířený o práci se seznamem sousedů. V průběhu implementace byla testována
varianta jednostranná (přídavná regularizace se uplatňuje pouze pro "pozitivní"
prvek) i oboustranná (přídavná regularizace probíhá pro oba zpracovávané prvky).
Experimentální nastavení parametrů této metody použité v offline testech je popsáno
v kapitole 3.4.2.
3.3. Implementace řešení v LibRec
Framework LibRec, Guo et al. (2015) je aktivně se rozvíjející projekt
pro práci s doporučovacími systémy. Framework obsahuje několik desítek variant
doporučovacích algoritmů, zejména z oblastí baseline a kolaborativního filtrování.
Dále obsahuje vlastní implementace některých datových struktur, sadu
vyhodnocovacích metrik a pomocné metody, vše optimalizované pro efektivní výkon
při doporučování. Jedná se o otevřený, plně rozšiřitelný projekt implementovaný
v jazyce Java.
Systém LibRec je poměrně rozsáhlý a umožňuje realizaci mnoha konkrétních
scénářů, ale je obtížné se v něm zorientovat. Užitečný je tedy zejména pro poučené
uživatele, kteří dané postupy a algoritmy znají. Pro LibRec ve verzi 1.3 je na webu
projektu k dispozici tutoriál, který obsahuje srozumitelnější přehled připravených
algoritmů i konfiguračních parametrů, než javadoc dokumentace, která je jediným
vodítkem pro ostatní verze.
V této práci byl použit LibRec ve verzi 1.3. Web projektu sídlí
na http://www.librec.net, github se zdrojovými kódy projektu je umístěn
na https://github.com/guoguibing/librec.

27
3.3.1. Nové metody přidané do LibRec
Do systému LibRec byly dopsány dva doporučovací algoritmy a několik
pomocných metod.
Tabulka 6: Vlastní třídy v LibRec
CBMF.java
Metoda přijímá dva nové
konfigurační parametry:
Implementace CBMF algoritmu. Používá
standardní LibRec parametr reg -b pro nastavení
regulačního parametru.
atribute.paths -item [path]
Pro cestu k souboru Item x Atribut.
similarity.threshold -thresh [float]
pro nastavení hodnoty cosinové podobnosti
CBBPR.java
Metoda přijímá dva nové
konfigurační parametry:
Implementace CBBPR algoritmu. Používá
standardní LibRec parametr reg -b pro nastavení
regulačního parametru.
atribute.paths -item [path]
Pro cestu k souboru Item x Atribut.
similarity.threshold –thresh [float]
pro nastavení hodnoty cosinové podobnosti
Att.java
Pomocná metoda pro vytvoření tabulky Uživatel
x Atribut, která je vstupem pro content boosted
algoritmy.
IndexedDenseMatrix.java
Pomocná datová struktura pro načítání a
vypisování dat typu objekt atribut, zachovává
mapování na původní identifikátory a zároveň
umožňuje pracovat s načtenými daty jako
s běžnou tabulkou.
Výpočetní náročnost přípravy obsahových dat z tabulky objektů a atributů je
při velkém počtu objektů výrazně vyšší než samotná faktorizace. V očekávaném
případě nové objekty přibývají v dávkách, například po dnech, takže to není
překážka. Navíc příprava tabulky sousedů může probíhat zcela odděleně od
samotného běhu výpočtu doporučování. Velikost výsledné tabulky sousedů se

28
v testovaných případech různí, ale je v ní, v ideálním případě, uložena pouze
informace přímo použitá ve faktorizaci.
Výsledná velikost tabulky je ovlivněna dvěma způsoby. Parametr požadované
podobnosti (v konfiguraci thresh), stanovuje minimální hodnotu cosinové míry pro
označení objektů za obsahově podobné a tím v důsledku i počet sousedů v tabulce
sousedů.
Výpočetní náročnost doporučování se zapojením obsahových dat je také
o něco větší, ale mimo práci s tabulkou podobností už rozdíl není příliš významný.
3.3.2. Další úpravy v LibRec
Mimo přidání nových metod bylo třeba provést několik změn v původním
kódu. Na přiloženém CD jsou všechny třídy, které byly pro tuto práci upraveny
oproti základní verzi LibRec 1.3.
Tabulka 7: Přehled úprav provedených v LibRec
Librec.java
Byly přidány nové doporučovací algoritmy do seznamu dostupných
a bylo přidáno nastavení locale. Framework počítá s anglickým
jazykovým nastavením, zejména s desetinnou tečkou. Při běhu
se systémovou češtinou není možné načítat desetinná čísla
z konfiguračního souboru, protože čárka je interpretována na úrovni
LibRec jako oddělovač více hodnot a tečka není s českým
nastavením vnímána jako platný oddělovač desetinných míst
standardní Javou.
MetricCollection.java
Byly provedeny změny formátování výstupu a oprava chyby
v metodě getDiversityMetricNames.
DataSplitter.java
Byla přidána možnost nastavení počáteční hodnoty (seed)
pro náhodný generátor používaný pro rozdělení dat, což umožňuje
přesněji reprodukovat konkrétní běh.
MetricDict.java
Změněno formátování výstupu.
IrankingMetric.java
Opravena chyba ve výpisu metriky.
DataDao.java
Doplněna bezpečná verze metody getItemId

29
3.4. Výsledky offline testů
Na vybraných datasetech byla provedena sada offline testů za účelem ověření
aplikovatelnosti jednotlivých metod před návrhem řešení konkrétních úloh. Získané
výsledky testů lze tedy do určité míry vnímat i jako další vlastnosti uvedených
datových sad.
3.4.1. Knihy
Na sadě dat Knihy byly porovnány algoritmy Biased MF a CBMF. Potvrdilo
se, že zapojení i jednoduché obsahové informace zlepšuje výsledky faktorizačního
algoritmu oproti základní faktorizaci.
Pro obě metody bylo použito shodné nastavení parametrů:
learning rate 0,1
regularizační koeficient 0,1
100 iterací
10 faktorů.
Tabulka 8: Offline test Knihy
MAE
RMSE
Precision10
Recall10
Čas běhu
Biased MF
0,738
0,951
0,000464
0,00156
00:08
CB MF
0,945
1,26
0,00117
0,00442
10:46
Metriky MAE a RMSE, tedy průměrná chyba, se změnou algoritmu zvýšily,
což odpovídá tomu, že Biased MF pracuje se specifickým doladěním odhadu
pro uživatele i objekty nad rámec faktorizace.
Pro metriky úspěšnosti doporučení K prvků, Precision a Recall, vyšší hodnoty
dosažené novým algoritmem znamenají zlepšení.
Celkově zapojení obsahu do procesu doporučování výrazně zvýšilo časovou
náročnost a zhoršilo výsledky v ratingových metrikách, avšak zlepšilo výsledky
v top K metrikách, což může znamenat, že při učení dochází k lepší generalizaci.
3.4.2. Filmy
Pro datovou sadu Filmy byly, i díky jejím bohatým doprovodným datům,
provedeny testy všech čtyř algoritmů (Tabulka 9). Jako obsahová složka byly opět
použity žánry. Bylo potvrzeno, že metoda BiasedMF je z testované čtveřice

30
nejvhodnější na úlohy odhadu hodnocení, což je její původní specializace, zatímco
metody založené na BPR jsou úspěšnější v top k hodnoceních.
Tabulka 9: Offline test Filmy
Metrics:
MAE
RMSE
NDCG
Precision10
Recall10
Čas běhu
BPR
2,453260
2,689560
0,463843
0,241463
0,156869
00:51
CBBPR
2,471675
2,708046
0,471651
0,241676
0,156679
09:00
BiasedMF
0,764262
0,974086
0,017454
0,008696
0,004304
00:00
CBMF
0,906648
1,139491
0,079894
0,030965
0,013061
04:18
3.4.3. Portál
Datová sada Portál pracuje se zpětnou vazbou s jedinou hodnotou. Proto
pro ni byla zvolena dvojice algoritmů BPR a CBBPR. Vzhledem k tomu, že všechna
hodnocení v datové sadě mají stejnou hodnotu, metriky MAE a RMSE neposkytují
užitečnou informaci (chyba je vždy rovna nule), a pro porovnání tedy byly použity
pouze metriky Precision a Recall.
Nastavení parametrů
Nejdříve byl v sadě testů postupně ověřen vliv parametrů na výsledné
metriky.
Hodnota regularizačního parametru byla stanovena experimentálně (Tabulka
10, Obrázek 5). K tomu byla použita základní sada dat uživatel x umělec.
Tabulka 10: Regularizační koeficient
Regularizační koeficient
Precision
Recall
0,003
0,0585
0,173
0,007
0,0594
0,179
0,008
0,0604
0,186
0,009
0,0601
0,185
0,01
0,0597
0,185
0,05
0,0572
0,171
0,1
0,0502
0,142

31
Obrázek 5: Regularizační koeficient
Pro oba algoritmy byl experimentálně ověřen vliv počtu faktorů na výsledek.
Ukázalo se, že mezi výsledky nejsou velké rozdíly, pro BPR nebyl mezi počty
faktorů jasný vítěz (Tabulka 11), pro CBBPR (Tabulka 12) vyšel nejlépe výchozí
počet deseti faktorů.
Tabulka 11: BPR - počet faktorů
Počet faktorů
Precision
Recall
Čas běhu
5
0,046965
0,138089
00:08
10
0,056869
0,167587
00:14
15
0,059105
0,176845
00:08
20
0,059744
0,176793
00:08
30
0,060064
0,166258
00:10
Tabulka 12: CBBPR - Počet faktorů
Počet faktorů
Precision
Recall
Čas běhu
5
0,048882
0,148928
14:15
10
0,061022
0,192915
14:48
15
0,060383
0,186454
14:56
20
0,059425
0,181608
15:03
30
0,060703
0,177188
15:50

32
Protože výpočet CBBPR je výrazně časově náročnější, byl pro BPR otestován
i běh s větším počtem iterací. Cílem bylo ověřit, zda prosté zvýšení počtu iterací, a
tedy využití většího množství času, nezlepší výsledky více než zapojení obsahové
informace. Tato hypotéza se nepotvrdila (Tabulka 13, Obrázek 6), výrazné zvýšení
počtu iterací nevedlo k lepším výsledkům BPR algoritmu.
Tabulka 13: Počet iterací
Algoritmus, počet iterací
Precision
Recall
BPR100
0,056869
0,167587
BPR200
0,057508
0,177410
BPR500
0,058786
0,172306
BPR1000
0,052396
0,157336
CABPR100
0,061022
0,192915
Obrázek 6: Počet iterací BPR
Offline test na variantách datové sady
CBBPR s parametry nastavenými podle předchozích testů byl spuštěn
na třech verzích datové sady, jak byly popsány v kapitole 3.1. Pro srovnání jsou
uvedeny i výsledky BPR na stejných datech.
Ukázalo se, že druhá verze dat, zahuštěná o vztahy uživatelů k umělcům
projevené prostřednictvím událostí, má kromě nejvyšší relativní hustoty dat i nejlepší

33
výsledky v offline testu. Zároveň se projevilo, že přínos zapojení obsahové
podobnosti klesá s hustotou dat (Tabulka 14).
Tabulka 14: Tři verze datové sady
Algoritmus, data
Precision
Recall
CBBPR_1
0,061
0,193
BPR_1
0,059
0,177
CBBPR_2
0,149
0,397
BPR_2
0,149
0,393
CBBPR_3
0,055
0,179
BPR_3
0,0535
0,172

34
4. Praktické úlohy a návrh jejich řešení
V této kapitole jsou popsány dvě úlohy motivované praxí a je navrženo jejich
řešení vycházející z provedených offline experimentů. Ověření postupů v uživatelské
studii je obsahem kapitoly následující.
4.1. Úloha obecného uživatele
Neregistrovaný návštěvník vstoupil na stránku některého objektu na portálu.
Doporučovací systém má stanovit, které další objekty mu mají být nabídnuty.
Žádoucí stav by byl, aby uživatel pokračoval na další stránky portálu a zvýšila se tak
šance, že si vybere nějakou akci k navštívení a pořídí vstupenku, případně pošle
odkaz svým známým. Z důvodu omezeného výpočetního výkonu bude všem
neregistrovaným návštěvníkům téhož objektu po nějakou dobu nabízena stejná
skupina dalších objektů.
Cílem je tedy pro každý objekt O vybrat N dalších objektů tak, aby co
největší část uživatelů s tímto společným vstupním objektem O byla zaujata alespoň
jedním z doporučených prvků. Doporučení by dále mělo preferovat takové objekty,
které jsou relevantní z pohledu provozovatele portálu.
Pro účely této úlohy definujeme platnost prvku jako míru jeho vhodnosti
k doporučení. Platnost prvků je externí hodnota, která je dalším vstupem pro
doporučovací systém. Obecně objekty s budoucí událostí mají vyšší platnost než
objekty, které mají jen zajímavý obsah. Nulovou platnost mají objekty s velmi málo
informacemi nebo jinak neaktivní. Nejvyšší platnost může být vyhrazena pro objekty
odpovídající cílům provozovatele systému, například takové, na které přímo prodává
vstupenky.
Návrh řešení
Situaci obecného uživatele na stránce konkrétního objektu budeme simulovat
umělým uživatelem s právě jedním hodnocením. Pomocí metody CBBPR, která
pro zpracovávaná data uspěla v offline testu, pro něj vygenerujeme doporučení
většího počtu objektů, než má být zobrazeno. Z doporučené skupiny vybereme
konkrétních N objektů k doporučení jako funkci pořadí objektu v doporučení a
hodnoty Platnosti.
35
4.2. Úloha registrovaného uživatele
Uživatel se přihlásil ke svému profilu, ze kterého již dříve označil, že se mu
líbí některé objekty. Doporučovací systém má uživateli nabídnout N dalších objektů,
které by mohl prohlédnout a případně označit jako oblíbené.
Návrh řešení
Tato úloha odpovídá jedné ze základních úloh doporučování, úloze pořadí,
takže je možné ji řešit libovolným algoritmem pro doporučení tohoto typu, který je
vhodný pro data s pouze pozitivní zpětnou vazbou. V tomto případě bude použit
algoritmus CBBPR.
Hodnota parametru platnost může být pro tuto úlohu také personalizována,
například pro umělce s blížícím se koncertem v konkrétním klubu zapojením
naučeného vztahu uživatele k danému místu konání.
36
5. Uživatelská studie
Postupy navržené v předchozí kapitole byly ověřeny pomocí online studie
s reálnými uživateli. Studie porovnává vybraný doporučovací algoritmus se
základním algoritmem, a to z pohledu úspěšnosti doporučení i v rovině subjektivního
hodnocení uživatelů. Jako baseline byl zvolen výběr z nejpopulárnějších objektů.
Před první částí studie zaměřenou na doporučování odpovídali respondenti
ještě na trojici otázek vycházejících z teoretické části práce, které se týkaly jejich
zvyklostí v souvislosti s návštěvami kulturních akcí.
5.1. Úloha obecného uživatele
Uživatel si z připravené nabídky volí tři umělce jako své, z dané skupiny
nejpravděpodobnější, vstupní body do systému. Z pohledu systému se jedná
o situaci, kdy uživatel přijde na stránku například z vyhledávání. Pro první vybraný
vstupní bod jsou uživateli zobrazeny dvě pětice prvků doporučených porovnávanými
algoritmy. Uživatel označí, které z doporučených objektů by si vybral jako
pokračování, které z nabídnutých prvků zná, a zda mu taková doporučení pro jeho
vstupní bod dávají smysl. Pro druhý a třetí vstupní bod pak hodnotí pro každý jednu
pětici.
Technicky je počet vstupních bodů v nabídce omezen v zájmu přehlednosti
na dvacet. Vstupní body byly vybrány z dat za pomoci kritérií popularita a různost.
Pro každý vstupní bod je připraveno jedno cílené doporučení, top 5 podle CBBPR
s vyřazením zahraničních interpretů, kteří z principu mají malou platnost z pohledu
původní úlohy. Kromě toho je uživatelům předložena konstantně vybraná nabídka
z nejpopulárnějších kapel podle zdrojových dat, která je použita pro porovnání.
5.2. Úloha registrovaného uživatele
Druhá část, úloha registrovaného uživatele, vyžaduje existenci uživatelské
historie. Data zaznamenaná při průchodu uživatele první částí studie, tedy jedno až
dvacet tři jeho pozitivních hodnocení, tvoří uživatelský profil podobný záznamům
o uživatelích registrovaných v původním systému. Uživateli je algoritmem CBBPR
připraveno individuální doporučení, které ohodnotí stejně jako doporučení z první
fáze.
37
5.3. Základní otázka studie
Základní otázkou studie je porovnání úspěšnosti doporučení ve třech
situacích.
První situací je baseline doporučení typu most popular, druhou situací je
doporučení pro uživatele s jediným známým hodnocením. Třetí situací je hodnocení
personalizovaného doporučení vytvořeného na základě dat z předchozí fáze.
Ověřovaným předpokladem bylo, že míra spokojenosti, známosti a smyslu
bude s postupující mírou personalizace narůstat.
5.4. Realizace
Studie byla provedena online, prostřednictvím pro tento účel vytvořené
webové stránky.
Pro realizaci studie byla použita největší verze datové sady z offline testu.
Použitá metoda sice měla nejlepší výsledky metrik na sadě prostřední, ale potenciální
kvalitnější doporučení by pokrývalo výrazně užší oblast hudby, takže by hrozila
výrazně nižší shoda s oblastmi hudby preferovanými účastníky studie.
Z technických důvodů byly obě části studie provedeny postupně. Uživatel
tedy prošel první úlohou a později mu přišel odkaz na připravenou personalizovanou
část. Vzhledem k tomu, že se v první části studie všichni účastníci vyjadřovali
k výběru jen z několika desítek společných položek, mohlo by přidání všech
hodnocení provedených účastníky studie v první části zároveň způsobit výraznou
umělou preferenci těchto objektů v doporučení pro druhou část. Ta byla proto
připravována na původní datové sadě doplněné vždy jen o několik málo uživatelů
ze studie, pro které bylo v daném běhu právě vytvářeno doporučení.
Konkrétní vytvářená doporučení pro personalizované uživatele nebyla stabilní
mezi jednotlivými běhy doporučovacího systému a záležela na přesném složení
trénovacích dat. Nestabilita se projevovala různě rozsáhlými odlišnostmi na úrovni
jednotlivých doporučení, ale kvalita těchto různých doporučení, posouzeno
expertním odhadem, byla zhruba srovnatelná. Změny by mohly být vysvětleny tím,
že samotný BPR je algoritmus využívající velké množství náhodných výběrů, takže i
při přidání nebo odebrání byť malého množství hodnocení do datové sady dochází
ke stejnému efektu jako při změně seedu generátoru náhodných čísel.

38
5.5. Vyhodnocení
Studie se zúčastnilo přes 80 unikátních osob, 72 z nich dokončilo celou první
část. Druhou fázi zodpovědělo 38 uživatelů. Uživatelé netvořili homogenní skupinu,
byly zastoupeni náctiletí i padesátníci, stejně jako pravidelní i příležitostní
návštěvníci kulturních akcí a několik aktivních umělců.
Výsledky studie ve všech sledovaných parametrech jsou zachyceny
v následujících grafech. U první a třetí metody uživatelé hodnotili přesně pět
položek, u metody druhé provedli vždy patnáct hodnocení. Na vodorovné ose je
zanesen poměr počtu pozitivních vyjádření k danému základu. Protože třetí
doporučení ohodnotila přibližně polovina účastníků studie, nejsou na svislé ose
zobrazeny absolutní počty, ale výsledky byly normalizovány na procentuální podíl
uživatelů odpovídajících danému hodnocení.
V otázce spokojenosti s doporučenými prvky, neboli na kolik z nich by
uživatel klikl, (Obrázek 7) se výrazně zvýšila průměrná spokojenost již při prvním
zkonkrétnění doporučení. Personalizace přinesla zvýšení poměru uživatelů, kteří byli
s hodnocením velmi spokojení, a vyhovovaly by jim čtyři z pěti nabídnutých prvků.
Na druhou stranu se v ní lehce zvýšil i poměr zcela nespokojených. Možné
vysvětlení souvisí s efektem „znám, nezajímá mě“ popsaným v další části.
Obrázek 7: Uživatelská studie – spokojenost

39
Změna ve známosti prvků odpovídá situaci, kdy první doporučení bylo
vybráno z nejpopulárnějších prvků původní datové sady, takže i většina respondentů
znala většinu doporučených objektů (Obrázek 8). V první konkretizaci doporučení
míra známosti mírně poklesla. Doporučení založené na celé získané historii vedlo
k tomu, že třetina respondentů znala všechny objekty personalizovaného doporučení.
Výsledek u těchto uživatelů nedává prostor pro objevení něčeho nového,
pro konkrétní závěry by ale bylo potřeba přesněji rozlišit, jak moc doporučený objekt
znají, pokud někteří za „znám“ považovali i „znám tak trochu“, může to být naopak
pozitivní výsledek.
Obrázek 8: Uživatelská studie – známost
Otázku smyslu doporučení (Obrázek 9) typu most popular uživatelé hodnotili
ve vztahu k první kapele podle svého výběru na začátku studie. Výsledek, kdy 40
procent z nich považuje populární pětici za zcela nesmyslné doporučení, tedy není
překvapivý. S rostoucí mírou konkretizace hodnotili uživatelé doporučení jako více
odpovídající.

40
Obrázek 9: Uživatelská studie – smysl
Souhrnně je tedy možno konstatovat, že narůstající personalizace se projevuje
tím, že uživatelé v doporučení vidí větší smysl a roste i jejich spokojenost
s doporučením.
Plná data zaznamenaná v průběhu realizace studie, s výjimkou kontaktních
informací účastníků, jsou k dispozici na přiloženém CD.
5.5.1. Vyhodnocení textových otázek
Textové otázky položené účastníkům studie byly motivovány dvěma důvody.
Prvním bylo ověření několika tvrzení, či spíše konstatování z teoretické části práce,
která by bylo možné považovat za obecně známá fakta, ale provedení studia byla
dobrá příležitost k jejich ověření. V tomto směru se potvrdilo, že mírná většina
uživatelů výrazně preferuje koncerty jim dobře známých umělců. Jen malá část,
zhruba pět procent výrazně preferuje využití návštěv kulturní akce k poznávání
něčeho výrazně nového. Zbývající část střídá obě varianty.
Polovina respondentů se účastní nějaké kulturní akce v průměru jednou
za měsíc až dva. Pětina se účastní více než patnácti akcí ročně, zbývající část naopak
nejvýše pěti.
V odpovědi na otázku, s kým se běžně událostí účastní, mohli účastníci
vybrat více možností najednou, průměrný počet zvolených variant jsou dvě. Podle
výsledků dvě třetiny vyrážejí s přáteli, polovina v páru a polovina s rodinou.
Pro zhruba třetinu respondentů je běžné vyrazit na akci i samostatně.
41
Druhým, neméně důležitým cílem využití textových otázek, bylo začít studii
způsobem co nejpodobnějším běžným dotazníkům a zjednodušit tak uživatelům
začátek odpovídání.
5.6. Interpretace a další poznatky
Kromě numerických hodnocení bylo možné pozorovat i další zajímavé
výsledky.
5.6.1. Znám a nezajímá mě
Mnozí uživatelé dobře rozlišovali mezi otázkami „zajímá mě“, „znám“ a
„dává smysl“, takže není vzácný případ, kdy uživatel doporučenou položku zná, má
dojem, že dává smysl, že je mu doporučena, ale nemá o ni zájem. To ukazuje
na slabé místo původního návrhu systému, tedy chybějící koncept negativního
hodnocení, ať už vyjádřeného přímo jako "nelíbí se mi" nebo nepřímo, ignorováním
několikrát nabídnuté položky.
Objekt, který je podle algoritmu dobrým doporučením, ale dotyčnému
uživateli se nelíbí, je tak uživateli vnucován opakovaně, což by v dlouhodobém
měřítku mohlo vést k absurdní situaci opakovaného doporučování nejvhodnějších
z uživatelem nepreferovaných doporučení.
V praxi je tento problém pro registrovaného uživatele snadno řešitelný
zavedením seznamu registrovaným uživatelem nepreferovaných položek, které
budou z doporučení odebírány. Uživatel by mohl takové položky označovat přímo,
ale mohly by do něj být, například dočasně, odkládány i objekty, které viděl a
nevybral.
Alternativně by mohly být negativní hodnocení zahrnuta i do procesu výpočtu
doporučení, avšak při malém množství negativních hodnocení by to nebylo
praktické. Navíc by mohlo být potřeba rozlišovat „nezajímá mě tento objekt
specificky“ od „nezajímá mě tento typ objektů“.
5.6.2. Neformální zpětná vazba
Studie nesbírala formální zpětnou vazbu účastníků ve vztahu ke studii
samotné. Z neformálních reakcí účastníků vyplynulo, že pro respondenty, kteří se
považují za hudby znalé nebo hudební profesionály, bylo obtížnější přijmout fakt, že
42
neznají všechny kapely, které jim byly předloženy k výběru. I u hudebníků, které
znali, pro ně bylo složitější odpovědět na otázku, zda jim konkrétní doporučení dává
smysl.
43
Závěr
Jedním z cílů práce bylo získat přehled v oblasti webových uživatelských
preferencí se zaměřením na doménu kulturních portálů. V teoretické části této práce
byly shrnuty základní pojmy a myšlenky doporučování, stejně jako typy a příklady
pro doporučování používaných přístupů a algoritmů. Pozornost byla věnována i
metodám a metrikám hodnocení kvality doporučování.
Druhá polovina teoretické části představila témata doporučování digitálně
distribuovaných děl a doporučování akcí, která jsou východiskem pro doporučování
na kulturním portálu. Dále práce prozkoumala model domény jako několika různých,
vzájemně provázaných typů objektů. Využití těchto vazeb pro obohacování datových
sad umožnilo překonat nízkou hustotu dat a zlepšit výsledky doporučování.
V praktické části práce byly analyzovány tři datové sady s ohledem
na specifika kulturních preferencí. Dále byly implementovány dvě hybridní varianty
doporučovacích algoritmů společně s podporou pro práci s atributovými daty
do frameworku LibRec. Provedené offline testy ukázaly stabilní zlepšení
doporučování nově implementovanými hybridními algoritmy oproti základní
faktorizaci.
Výsledky offline testů byly dále využity při návrhu řešení dvou praktických
úloh, doporučování obecnému uživateli s minimálním profilem a doporučování
registrovanému uživateli se známou historií.
Úspěšnosti i subjektivní kvalita výsledných doporučení byla zkoumána
prostřednictvím uživatelské studie, ve které několik desítek osob srovnávalo
doporučení v situacích odpovídajících definovaným úlohám.
Při práci s reálnou datovou sadou se projevila důležitost předzpracování a
interpretace základních dat, i skutečnost, že začínající kulturní portál měl z vlastních
zdrojů relativně málo dat. Tato situace bude v praxi poměrně častá, což zvyšuje
význam metod, které alespoň částečně řeší tento problém, ať už pomocí zapojení
obsahových informací nebo obohacováním na základě jiných typů vazeb.
Další práce by mohla směřovat k důkladnějšímu využití obsahových dat,
například za pomoci ontologií a vztahů mezi obsahovými atributy. Pozornost si
zaslouží i podrobnější porovnání významu obsahových informací v různých fázích
webového projektu používajícího doporučování, například srovnání výsledků
44
na malých datech z počátečního období a na datech dostupných po několika letech
provozu.

45
Seznam použité literatury
DOOMS, Simon; DE PESSEMIER, Toon; MARTENS, Luc, 2011. A user-centric
evaluation of recommender algorithms for an event recommendation system. In:
FELFERNIG, Alexander; CHEN, Li; MADL, Monika; WILLEMSEN, Martijn;
BOLLEN, Dirk; EKSTRAND, Michael (ed.). Proceedings of the RecSys 2011 :
Workshop on Human Decision Making in Recommender Systems
(Decisions@RecSys’11) and User-Centric Evaluation of Recommender Systems and
Their Interfaces - 2 (UCERSTI 2) affiliated with the 5th ACM Conference on
Recommender Systems (RecSys 2011). Chicago, IL, USA: Ghent University,
Department of Information technology, s. 67–73.
GUO, Guibong; ZHANG, Jie; SUN, Zhu; YORKE-SMITH, Niel, 2015. LibRec: A
Java Library for Recommender Systems. In: UMAP 2015 Extended Proceedings:
Posters, Demos, Late-breaking Results and Workshop Proceedings of the 23rd
Conference on User Modeling, Adaptation, and Personalization (UMAP 2015),
Dublin, Ireland, June 29 - July 3, 2015. CEUR-WS, s. 73–105. CEUR workshop
proceedings. Dostupné z https://books.google.cz/books?id=95YQjwEACAAJ.
HARPER, F. Maxwell; KONSTAN, Joseph A., 2015. The MovieLens Datasets:
History and Context. ACM Trans. Interact. Intell. Syst. Roč. 5, č. 4, s. 19:1–19:19.
ISSN 2160-6455. Dostupné z: DOI: 10.1145/2827872.
HU, Yifan; KOREN, Yehuda; VOLINSKY, Chris, 2008. Collaborative Filtering for
Implicit Feedback Datasets. In: Collaborative Filtering for Implicit Feedback
Datasets. Proceedings of the 2008 Eighth IEEE International Conference on Data
Mining. Washington, DC, USA: IEEE Computer Society, s. 263–272. ICDM ’08.
ISBN 978-0-7695-3502-9. Dostupné z DOI: 10.1109/
ICDM.2008.22.
KOREN, Yehuda, 2008. Factorization Meets the Neighborhood: A Multifaceted
Collaborative Filtering Model. In: Factorization Meets the Neighborhood: A
Multifaceted Collaborative Filtering Model. Proceedings of the 14th ACM SIGKDD
International Conference on Knowledge Discovery and Data Mining. Las Vegas,
46
Nevada, USA: ACM, s. 426–434. KDD ’08. ISBN 978-1-60558-193- 4. Dostupné
z DOI: 10.1145/1401890.1401944.
LEHMANN, Jens et al., 2015. DBpedia–a large-scale, multilingual knowledge base
extracted from Wikipedia. Semantic Web. Roč. 6, č. 2, s. 167–195.
LI, Tao; OGIHARA, M., 2005. Music genre classification with taxonomy. In: Music
genre classification with taxonomy. Proceedings. (ICASSP ’05). IEEE International
Conference on Acoustics, Speech, and Signal Processing, 2005. Sv. 5, v/197–v/200
Vol. 5. ISSN 1520-6149. Dostupné z DOI: 10 . 1109 / ICASSP.2005.1416274.
LOPS,Pasquale; GEMMIS, Marco de; SEMERARO, Giovanni, 2011. Content-based
Recommender Systems: State of the Art and Trends. In: Recommender Systems
Handbook. Ed. RICCI, Francesco; ROKACH, Lior; SHAPIRA, Bracha; KANTOR,
Paul B. Boston, MA: Springer US. ISBN 978-0-387-85820-3. Dostupné z DOI:
10.1007/978-0-387-85820-3_3.
NGUYEN, Jennifer; ZHU, Mu, 2013. Content-boosted matrix factorization tech-
niques for recommender systems. Statistical Analysis and Data Mining. Roč. 6,
č. 4, s. 286–301. ISSN 1932-1872. Dostupné z DOI: 10.1002/sam.11184.
PU, Pearl; CHEN, Li; HU, Rong, 2011. A User-centric Evaluation Framework for
Recommender Systems. In: A User-centric Evaluation Framework for Recommender
Systems. Proceedings of the Fifth ACM Conference on Recommender Systems.
Chicago, Illinois, USA: ACM, s. 157–164. RecSys ’11. ISBN 978-1-4503-0683-6.
Dostupné z DOI: 10.1145/2043932.2043962.
NOIA, TOMMASO DI; CANTADOR IVÁN; OSTUNI VITO CLAUDIO, 2014.
Linked Open Data-Enabled Recommender Systems: ESWC 2014 Challenge on Book
Recommendation.” In: Semantic Web Evaluation Challenge. Proceedings of ESWC
2014. Anissaras, Crete, Greece. Cham: Springer International Publishing. ISBN 978-
3-319-12023-2. Dostupné z DOI: 10.1007/978-3-319-12024-9
47
RENDLE, S.; FREUDENTHALER, C.; GANTNER, Z.; SCHMIDT-THIEME, L.,
2012. BPR: Bayesian Personalized Ranking from Implicit Feedback. ArXiv e-prints.
Dostupné z arXiv: 1205.2618 [cs.IR].
RICCI, Francesco; ROKACH, Lior; SHAPIRA, Bracha; KANTOR, Paul B., 2010.
Recommender Systems Handbook. 1st. New York, NY, USA: Springer-Verlag New
York, Inc. ISBN 0387858199, 9780387858197.
STECK, Harald, 2013. Evaluation of Recommendations: Rating-prediction and
Ranking. In: Evaluation of Recommendations: Rating-prediction and Ranking.
Proceedings of the 7th ACM Conference on Recommender Systems. Hong Kong,
China: ACM, s. 213–220. RecSys ’13. ISBN 978-1-4503-2409-0. Dostupné z DOI:
10.1145/2507157.2507160.
VINAGRE, Joao; JORGE, Alípio Mário; GAMA, Joao, 2014. Fast Incremental
Matrix Factorization for Recommendation with Positive-Only Feedback. In: User
Modeling, Adaptation, and Personalization: 22nd International Conference, UMAP
2014, Aalborg, Denmark, July 7-11, 2014. Proceedings. Ed. DIMITROVA, Vania;
KUFLIK, Tsvi; CHIN, David; RICCI, Francesco; DOLOG, Peter; HOUBEN, Geert-
Jan. Cham: Springer International Publishing, s. 459–470. ISBN 978-3-319-08786-3.
Dostupné z DOI: 10.1007/978-3-319-08786-3_41.
ZHANG, Yinuo; WU, Hao; SORATHIA, Vikram; PRASANNA, Viktor K., 2013.
Event Recommendation in Social Networks with Linked Data Enablement. In: Event
Recommendation in Social Networks with Linked Data Enablement. Proceedings of
the 15th International Conference on Enterprise Information Systems - Volume 2:
ICEIS, ScitePress, s. 371–379. ISBN 978-989-8565-60-0. Dostupné z DOI:
10.5220/0004443903710379.
48
Seznam obrázků a tabulek
Obrázek 1: Vysvětlená doporučení Last.fm ............................................................... 12
Obrázek 2: Histogram hodnocení sady Knihy ........................................................... 14
Obrázek 3: Histogram průměrných hodnocení .......................................................... 15
Obrázek 4: DBpedia ukázka....................................................................................... 21
Obrázek 5: Regularizační koeficient .......................................................................... 31
Obrázek 6: Počet iterací BPR ..................................................................................... 32
Obrázek 7: Uživatelská studie – spokojenost............................................................. 38
Obrázek 8: Uživatelská studie – známost .................................................................. 39
Obrázek 9: Uživatelská studie – smysl ...................................................................... 40
Tabulka 1: Charakteristika sady Knihy ...................................................................... 20
Tabulka 2: Charakteristika sady Filmy ...................................................................... 22
Tabulka 3: Charakteristika dat Portál ......................................................................... 22
Tabulka 4: Další data v sadě Portál ............................................................................ 23
Tabulka 5: Nové sady Portál ...................................................................................... 24
Tabulka 6: Vlastní třídy v LibRec .............................................................................. 27
Tabulka 7: Přehled úprav provedených v LibRec ...................................................... 28
Tabulka 8: Offline test Knihy .................................................................................... 29
Tabulka 9: Offline test Filmy ..................................................................................... 30
Tabulka 10: Regularizační koeficient ........................................................................ 30
Tabulka 11: BPR - počet faktorů ............................................................................... 31
Tabulka 12: CBBPR - Počet faktorů ........................................................................ 31
Tabulka 13: Počet iterací ............................................................................................ 32
Tabulka 14: Tři verze datové sady ............................................................................. 33
49
Přílohy
Obsah CD
Elektronická verze práce ve formátu PDF
Zdrojové kódy nově implementovaných algoritmů a všech částí
systému LibRec upravených pro účely této práce
Dokumentace nově implementovaných algoritmů ve formátu
JavaDoc
Plná data z realizace uživatelské studie
Obsahová data z DBPedia použitá v offline testu pro datovou sadu
Knihy