ISSCC 2025 PRESS KIT PDF Free Download
1 / 152/152
100%

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
2025
PRESS KIT
DRAFT 2-1-2025

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
ISSCC Press Kit Disclaimer
The material presented here is preliminary.
As of November 5, 2024, there is not enough information to guarantee its correctness.
Thus, it must be used with some caution.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
ISSCC 2025
VISION STATEMENT
The International Solid-State Circuits Conference is the foremost global forum for presentation
of advances in solid-state circuits and systems-on-a-chip. The Conference offers a unique
opportunity for engineers working at the cutting edge of IC design and use to maintain
technical currency, and to network with leading experts.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Table of Contents
Table of Contents ............................................................................................................................................ 4
Preamble .......................................................................................................................................................... 7
FAQ on ISSCC ...................................................................................................................................................................................... 7
Plenary Session (Session 1) ............................................................................................................................................................. 10
Plenary Session — Invited Papers ............................................................................................................... 12
Plenary Session — Invited Papers ............................................................................................................... 13
Evening Events (EE) ...................................................................................................................................... 15
Bingo Networking Event ................................................................................................................................................................... 15
EE1: Student Research Preview ....................................................................................................................................................... 15
EE2: Quantum Computing: Whose Qubit is Better? ....................................................................................................................... 15
EE3: Future of Analog Design: Still Magical or Mostly Digital? .................................................................................................... 16
EE4: The Next Decade of AI – Barriers, Opportunities, & Directions ............................................................................................ 16
Session Overviews and Highlights .............................................................................................................. 17
Conditions of Publication ............................................................................................................................. 18
PREAMBLE ......................................................................................................................................................................................... 18
FOOTNOTE ......................................................................................................................................................................................... 18
Session 2 Overview: Processors ................................................................................................................. 19
Session 2 Highlights: Processors ................................................................................................................ 20
Session 3 Overview: Amplifiers and Analog Front-Ends............................................................................ 22
Session 3 Highlights: Amplifiers and Analog Front-Ends .......................................................................... 23
Session 4 Overview: Analog Techniques .................................................................................................... 24
Session 4 Highlights: Analog Techniques ................................................................................................... 25
Session 5 Overview: Front-End Circuits for High-Performance Transceivers ......................................... 26
Session 5 Highlights: Front-End Circuits for High-Performance Transceivers ....................................... 27
Session 6 Overview: Imagers and Displays ................................................................................................ 28
Session 6 Highlights: Imagers and Displays ............................................................................................... 29
Session 7 Overview: Ultra-High-Speed Wireline ......................................................................................... 31
Session 7 Highlights: Ultra-High-Speed Wireline ........................................................................................ 32
Session 8 Overview: Digital Techniques for System Adaptation, Power Management and Clocking ..... 34
Session 8 Highlights: Digital Techniques for System Adaptation, Power Management and Clocking ... 35
Session 9 Overview: Ubiquitous Power Delivery ........................................................................................ 36
Session 9 Highlights: Ubiquitous Power Delivery ...................................................................................... 37
Session 10 Overview: Transceiver Chipsets for Communication and Radar ............................................ 38
Session 10 Highlights: Transceiver Chipsets for Communication and Radar .......................................... 39
Session 11 Overview: RF and mm-Wave Wireless Receivers ................................................................... 40
Session 11 Highlights: RF and mm-Wave Wireless Receivers ................................................................. 41
Session 12 Overview: Innovations from Outside the (ISSCC) Box ........................................................... 42

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 12 Highlights: .................................................................................................................................. 42
Session 13 Overview: Cool Computation Circuits ...................................................................................... 44
Session 13 Highlights: Cool Computation Circuits..................................................................................... 45
Session 14 Overview: Compute-In-Memory ................................................................................................ 47
Session 14 Highlights: Compute-in-Memory ............................................................................................... 48
Session 15 Overview: Neural Interfaces and Edge Intelligence for Medical Devices ............................... 50
Session 15 Highlights: Precision neural and cardiac chips ....................................................................... 51
Session 16 Overview: Highlighted Chip Releases: Digital and Machine Learning Processors .............. 53
Session 16 Highlights: Highlighted Chip Releases: Digital and Machine Learning Processors ............ 54
Session 16 Highlights: Highlighted Chip Releases: Digital and Machine Learning Processors ............ 55
Session 16 Highlights: Highlighted Chip Releases: Digital and Machine Learning Processors ............ 56
Session 16 Highlights: Highlighted Chip Releases: Digital and Machine Learning Processors ............ 57
Session 17 Overview: Hardware Security .................................................................................................... 58
Session 17 Highlights: Hardware Security .................................................................................................. 59
Session 18 Overview: Noise-Shaping and SAR-Based ADCs ................................................................... 60
Session 18 Highlights: Noise-Shaping and SAR-Based ADCs ................................................................. 61
Session 19 Overview: Frequency Synthesizers and Series-Resonance VCOs ........................................ 62
Session 19 Highlights: Frequency Synthesizers and Series-Resonance VCOs ...................................... 63
Session 20 Overview: Sensors and Actuators for Health and Autonomy ................................................ 64
Session 20 Highlights: Sensors and Actuators for Health and Autonomy............................................... 65
Session 21 Overview: Compute & USB Power ............................................................................................ 66
Session 21 Highlights: Compute & USB Power .......................................................................................... 67
Session 22 Overview: Memory Interface ...................................................................................................... 68
Session 22 Highlights: Memory Interface .................................................................................................... 69
Session 23 Overview: AI Accelerators ......................................................................................................... 70
Session 23 Highlights: AI Accelerators ....................................................................................................... 71
Session 24 Overview: High-Frequency ADCs ............................................................................................. 73
Session 24 Highlights: High-Frequency ADCs ............................................................................................ 74
Session 25 Overview: High Concepts at High Frequencies ....................................................................... 75
Session 25 Highlights: High Concepts at High Frequencies ...................................................................... 76
Session 26 Overview: Wireless Transmitters and Front-Ends .................................................................. 77
Session 26 Highlights: Wireless Transmitters and Front-Ends ................................................................ 78
Session 27 Overview: Sensor Interfaces ..................................................................................................... 79
Session 27 Highlights: Scalable Sensor Interface ...................................................................................... 80
Session 28 Overview: Capacitive Sensor Readout ..................................................................................... 81
Session 28 Highlights: Capacitive Displacement Sensor ........................................................................... 82
Session 29 Overview: SRAM ........................................................................................................................ 83
Session 29 Highlights: SRAM ....................................................................................................................... 84
Session 30 Overview: Nonvolatile Memory and DRAM .............................................................................. 85
Session 30 Highlights: Nonvolatile Memory and DRAM ............................................................................. 86
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 31 Overview: Energy Harvesting and IoT Power .......................................................................... 88
Session 31 Highlights: Energy Harvesting and IoT Power ......................................................................... 89
Session 32 Overview: Isolated Power and Gate Drivers ............................................................................. 90
Session 32 Highlights: Isolated Power and Gate Drivers ........................................................................... 91
Session 33 Overview: Components for Beyond 100GHz ............................................................................ 92
Session 33 Highlights: Components for Beyond 100GHz .......................................................................... 93
Session 34 Overview: Digital PLLs and Waveform-Shaping VCOs .......................................................... 94
Session 34 Highlights: Digital PLLs and Waveform-Shaping VCOs ......................................................... 95
Session 35 Overview: Implantable and Wearable Biomedical Devices ..................................................... 96
Session 35 Highlights: Photoacoustic/Implant RXs.................................................................................... 97
Session 36 Overview: Ultra-High-Density D2D and High-Performance Optical Transceivers ................ 98
Session 36 Highlights: Ultra-High-Density D2D and High-Performance Optical Transceivers ............... 99
Session 37 Overview: Design-Technology Optimization and Digital Accelerators ................................ 101
Session 37 Highlights: Design-Technology Optimization and Digital Accelerators ............................... 101
Trends .......................................................................................................................................................... 103
Conditions of Publication ........................................................................................................................... 104
PREAMBLE ....................................................................................................................................................................................... 104
FOOTNOTE ....................................................................................................................................................................................... 104
Analog – 2025 Trends.................................................................................................................................. 106
Power Management – 2025 Trends ............................................................................................................ 108
Data Converters – 2025 Trends .................................................................................................................. 110
RF – 2025 Trends ......................................................................................................................................... 115
Wireless – 2025 Trends ............................................................................................................................... 118
Wireline – 2025 Trends ................................................................................................................................ 121
Digital Architectures & Systems (DAS) – 2025 Trends ............................................................................. 127
Digital Circuits – 2025 Trends ..................................................................................................................... 131
Memory – 2025 Trends ................................................................................................................................ 133
Security – 2025 Trends ................................................................................................................................ 137
IMD – 2025 Trends (Medical) ....................................................................................................................... 139
IMD – 2025 Trends (Imagers) ...................................................................................................................... 140
IMD – 2025 Trends (Displays) ..................................................................................................................... 141
Technology Directions – 2025 Trends ....................................................................................................... 142
INDEX ........................................................................................................................................................... 143
Technical Topics Mapped to Papers .................................................................................................................................................. 144
Selected Presenting Companies/Institution Mapped to Papers ......................................................................................................... 144
Contact Information .................................................................................................................................... 149

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Preamble
FAQ on ISSCC
What is ISSCC?
ISSCC (International Solid-State Circuits Conference) is the flagship conference of the IEEE Solid-State Circuits Society. According to
the Semiconductor Industry Association (SIA), in 2023, despite a cyclical market downturn that lingered early in the year, global sales
rebounded the second half of the year to reach $527 billion. Nearly 1 trillion semiconductors were sold globally, more than 100 chips for
every person on earth. With the downturn now over and demand for semiconductors high, industry analysts project double-digit annual
growth in the upcoming years. According to the World Semiconductor Trade Statistics (WSTS) Spring 2024 Semiconductor Industry
Forecast, a 16.0 percent growth is expected in the global semiconductor market compared to the previous year. The updated market
valuation for 2024 is estimated at US$611 billion. Looking ahead to 2025, WSTS forecasts a 12.5 percent growth in the global
semiconductor market, reaching an estimated valuation of US$687 billion. ISSCC continues to be the premier technical forum for
presenting advances in solid-state circuits and systems whose global market is increasing rapidly.
Who Attends ISSCC?
Attendance at ISSCC 2025 is expected to be around 2800. Corporate attendees from the semiconductor and system industries
typically represent around 60%.
Where is ISSCC?
The 72nd ISSCC will be held in-person with some online offering from February 16th through February 20th, 2025.
Are there Keynote Speakers?
After a day devoted to educational events, ISSCC 2025 begins formally on Monday, February 17, 2024, with four exciting plenary talks:
• Navid Shahriari, Senior Vice President, Foundry Technology Development, Intel
• Daniela Rus, Professor, EECS, Massachusetts Institute of Technology
• Jaihyuk Song, Corporate President & CTO, Device Solutions, Samsung Electronics
• Peter Schiefer, President/CEO, Infineon Technologies

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
What is the Technical Coverage at ISSCC?
ISSCC covers a full spectrum of design approaches in advanced technical areas broadly categorized as: (1) Communication Systems,
(2) Analog Systems, (3) Digital Systems, and (4) Innovations including micro-machines and MEMS, imagers, sensors, biomedical
devices, as well as forward-looking developments that may take three or more years for commercialization.
How are ISSCC Papers Selected?
For ISSCC 2025 around 914 submissions were received across the broad spectrum of specified topics. The submissions were reviewed
by a team of over 190 scientific and industry experts from the Far-East, Europe, and North America. These experts are organized into
12 Sub-Committees that cover the 4 broad areas described earlier:
• Communication Systems includes Wireless, RF, and Wireline Subcommittees
• Analog Systems includes Analog, Power Management, and Data Converter Subcommittees
• Digital Systems includes Memory, Digital Circuits, Digital Architectures and Systems, and Security Subcommittees
• Innovative Topics includes Imagers/MEMS/Medical Devices/Displays and Technology Directions Subcommittees
What Companies are Presenting this year?
Companies presenting papers at ISSCC 2025 include:
AMD, Analog Devices, Broadcom, Baker Hughes, Cadence, Co-Sensing, d-Matrix, IBM, Infineon Technologies, Intel, Kandou Bus,
KIOXIA, Ludwig Computing, Marvell, MediaTek, Meta, Novelda, Nvidia, SambaNova, Samsung, SKhynix, Semiconductor, Realtek
Semiconductor, Sony, Synopsos, Teledyne DALSA, Texas Instruments, TSMC, Vango, and Western Digital, just to name a few.
A more complete list can be found in the Index.
Are there educational sessions?
ISSCC features a variety of educational events which include:
• Ten Tutorials (targeted toward participants looking to broaden their horizon)
• Six Forums (targeted toward experts in an information sharing context)
• One Short Course (targeted toward in-depth appreciation of a current hot topic)
Are There Other Events?
A more complete list of all activities at ISSCC 2025:
• Four Plenary Presentations
• Eight Invited Talks, consisting of four Industry Talks on Highlighted Chip Releases
and four Talks on Innovative Out-of-the-box Ideas.
• Technical Sessions (37 distinct sessions)
• Four Evening Events and Panels, including:
o Student Research Preview (for the introduction of graduate-student research-in-progress)
o Quantum Computing: Whose Qubit is Better?
o Future of Analog Design: Still Magical or Mostly Digital?
o The Next Decade of AI – Barriers, Opportunities, & Directions
• Educational Sessions Featuring:
o Ten Tutorials
o Six Forums
o One Short Course
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
• Demonstration Sessions from Academia and Industry
• Exhibition (Corporation & Research Institutions)
• Networking Events
• Author Interview Sessions
• A Number of University Alumni Events
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
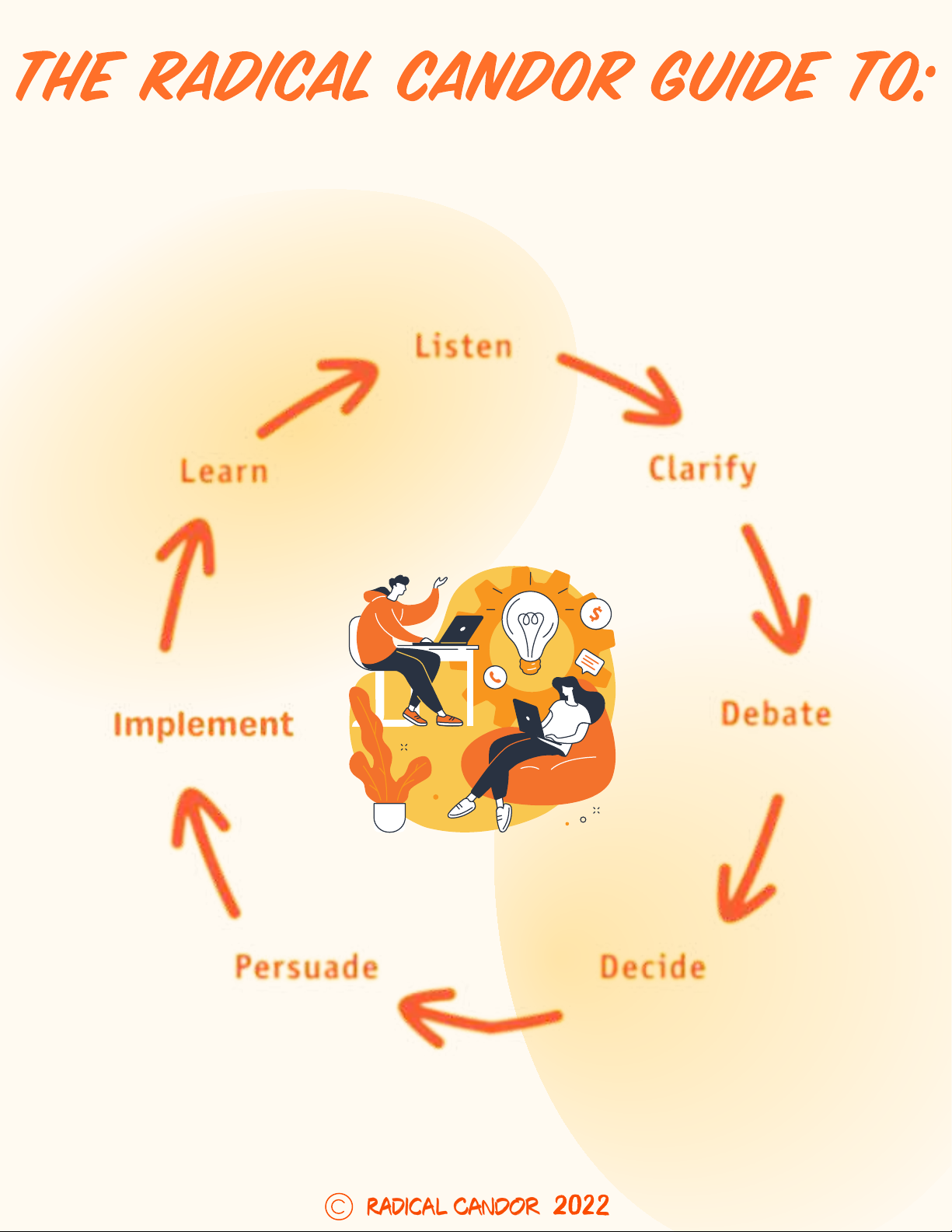
How Do I Use this Press Kit?
The Press Kit provides a PREAMBLE section that features this FAQ and other general information. The kit also includes SESSION
OVERVIEWS AND HIGHLIGHTS of all 37 technical sessions into which the 255 papers are grouped, together with brief descriptions and
context for each. As well, there is an abstract for each of the Plenary talks. For your convenience, the Kit includes two structural charts
in the INDEX section: (a) a list of the 4 Technical Topics and their associated Subcommittees and Sessions; (b) a list of contributing
companies and institutions with their associated papers. Thus, to locate information of interest you can access Chart 4.1 to identify
sessions of interest, after which you might logically access its Session’s Overview or Highlight section. Alternatively, if your interest is in
a particular organization then Chart 4.1 will direct you immediately to papers of interest each of which is detailed in its corresponding
Session Overview and possibly in the Highlights section. For anyone’s interest it is useful to use Chart 4.1 to access the appropriate
Trends information which provides a broad historical view of the context of your interest and often includes reference to current ISSCC
2025 papers.
Anything New This Year?
ISSCC will hold an invited Industry Track (Session 16) which will highlight recent hot-product releases from Broadcom, FuriosaAI,
Samsung Electronics, and SambaNova Systems, and will discuss innovative ways they solved product-level challenges. ISSCC will also
hold an invited session (Session 12) that will highlight some of the new and important developments outside of the circuit community that
can have profound impact on the solid-state circuits society either through emergence of new applications or via offering of new platforms
for processing, communications, and sensing.
Overview: ISSCC 2025 – “The Silicon Engine Driving the AI Revolution”
Now in its 72nd year, ISSCC is the flagship conference in solid-state circuit design. ISSCC reports innovative ideas that will fuel the
continued rapid evolution of integrated circuits (ICs). The IC design community has proven to be agile and resilient in a world scarred by
the worldwide pandemic, and for the 72nd edition of ISSCC we are focusing, more than ever, on how IC innovation can drive and support
the AI revolution.
• .
.
Plenary Session (Session 1)
The Plenary Session on the morning of February 17, 2025, will feature four renowned speakers:
• Navid Shahriari, Senior Vice President, Foundry Technology Development, Intel
• Daniela Rus, Professor, EECS, Massachusetts Institute of Technology
• Jaihyuk Song, Corporate President & CTO, Device Solutions, Samsung Electronics
• Peter Schiefer, President/CEO, Infineon Technologies
Highlights of these Plenary talks are provided in the following section.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
ISSCC 2025
PLENARY SESSION – INVITED PAPERS

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Plenary Session — Invited Papers
Chair: Edith Beigné, Meta, Menlo Park, CA
ISSCC Conference Chair
Associate Chair: Thomas Burd, Advanced Micro Devices, Santa Clara, CA
ISSCC International Technical-Program Chair
1.1 AI Era Innovation Matrix
Navid Shahriari, Senior Vice President, Foundry Technology Development, Intel, Chandler, AZ
AI holds transformative potential for humanity, enhancing our ability to solve complex problems with speed and accuracy, and
unlocking new realms of innovation and understanding. The lightning-fast progression of AI, unprecedented in history, necessitates
rapid advancements at a system level, from low-power and edge-AI devices to cloud-based computing, and in the communication
networks that connect them. This need for rapid AI system scaling is driving the innovation frontier in silicon, packaging, architecture,
and software. This paper describes a matrix of technologies that empowers the industry to achieve remarkable progress at every level,
from chips to systems.
1.2 From Chips to Thoughts: Building Physical Intelligence into Robotic Systems
Daniela Rus, Massachusetts Institute of Technology, Director,
CSAIL & Andrew (1956) and Erna Viterbi Professor, Cambridge, MA
In today’s robot revolution, a record 3.1 million robots are now working in factories, doing everything from assembling computers to
packing goods and monitoring air quality and performance. A far greater number of smart machines impact our lives in countless other
ways—improving the precision of surgeons, cleaning our homes, extending our reach to distant worlds—and we are on the cusp of even
more exciting opportunities. Future machines, enabled by recent advances in AI, will come in diverse forms and materials, embodying a
new level of physical intelligence. Physical Intelligence is achieved when the power of AI is to understand text, images, signals, and other
information is used to make physical machines such as robots intelligent. However, a critical challenge remains: balancing the capabilities
of AI with sustainable energy usage. To achieve effective physical intelligence, we need energy-efficient AI systems that can run reliably
on robots, sensors, and other edge devices. In this paper I will discuss the energy challenges of transformer-based foundational AI
models, I will introduce several state space models, and explain how they achieve energy efficiency, and how state-space models enable
physical intelligence.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Plenary Session — Invited Papers
1.3 AI Revolution Driven by Memory Technology Innovation
Jaihyuk Song, Corporate President & CTO, Device Solutions, Samsung Electronics, Hwaseong, South Korea
The recent AI revolution, spearheaded by Large Language Models (LLMs), demands substantial computing resources and corresponding
memory solutions. However, unlike processors that can leverage advancements in fabrication processes, memory devices are
increasingly struggling to meet the high bandwidth, large capacity, and power efficiency requirements of AI systems.
This paper analyzes the requirements and limitations of systems in the AI era, categorizing application-specific memory needs in terms
of performance, power, and capacity. We introduce performance-centric solutions such as HBM (High Bandwidth Memory) and PIM
(Processing-In-Memory) technologies, energy-efficient solutions including custom HBM and LPW (LPDDR Wide-IO) memory, and
capacity-focused solutions like SSD (Solid-State Drives) and CXL (Compute Express Link) Memories. Additionally, we discuss how
continuous scaling of DRAM and NAND Flash processes, as well as 3D-packaging technologies, can address the trade-offs among
performance, power, and capacity more effectively. Finally, the importance of software technologies in optimizing the utilization of these
increasingly specialized memory solutions is emphasized, along with a discussion of the enabling core technologies for each solution.
To meet the high demands of AI systems, the ongoing advancement of existing memory devices and the development of new memory
solutions will play crucial roles. These efforts will support the advancement of AI technologies and contribute to human society.
1.4 The Crucial Role of Semiconductors in the Software-Defined Vehicle
Peter Schiefer, President & CEO, Infineon Technologies, Munich, Germany
The automotive industry is undergoing a significant transformation, driven by the rise of software-defined vehicles (SDVs).
Semiconductors will play a pivotal role in enabling this transition, powering the complex systems that underpin the features and functions
of modern cars.
This paper explores the key trends driving the growth of the automotive semiconductor market, including green mobility, autonomous
driving, and smarter cars. It delves into the challenges and opportunities associated with the development of SDVs, highlighting the
importance of advanced microelectronics, artificial intelligence, and secure communication solutions.
The paper concludes by emphasizing the crucial role of semiconductors in shaping the future of mobility. By addressing the challenges
and embracing the opportunities presented by SDVs and AI, the automotive industry can create a more sustainable and innovative future.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
ISSCC 2025
EVENING EVENTS

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Evening Events (EE)
ISSCC 2025 will continue the popular tradition of evening sessions where experts often of opposing views, discuss topics
which range from the lighthearted to the controversial (but always informative and entertaining!). This year’s are “Quantum
Computing: Whose Qubit is Better?”, “Future of Analog Design: Still Magical or Mostly Digital?”, and “The Next Decade of AI
– Barriers, Opportunities, & Directions”.
In addition, ISSCC 2025 will include additional special events including “Student Research Preview” and a networking and
mentoring session.
Sunday, February 16
Bingo Networking Event
Women in Circuits (WiC) together with ISSCC will be holding a networking and mentoring session on Sunday afternoon. Distinguished
WiC members, and other participants will play getting-to-know-you bingo to promote engagement between various members of the
community. This will give participants the chance to network and mingle with people across a spectrum of seniority in the field in a casual
setting. This event is open to all ISSCC attendees and the public.
EE1: Student Research Preview
The Student Research Preview (SRP) will highlight selected student research projects in progress. The SRP consists of 24 sixty-second
presentations followed by a Poster Session, by graduate students from around the world, which have been selected on the basis of a
short submission concerning their on-going research. Selection is based on the technical quality and innovation of the work. This year,
the SRP will be presented in three theme sections: 1) Power and Analog, 2) ML, Cryogenic and Ising Machine, and 3) Data
Communications and Frequency Generation.
The SRP will include an inspirational lecture by Professor Jan Rabaey (UC Berkeley). SRP begins at 8:00 pm on Sunday, February
16th. It is open to all ISSCC registrants.
Tuesday, February 18
EE2: Quantum Computing: Whose Qubit is Better?
Quantum computing utilizes principles of quantum mechanics to solve intricate computational problems more efficiently than classical
computers. Various qubit technologies are being developed for this purpose, such as superconducting qubits, trapped ions, and silicon-
spin qubits. Each approach has its supporters and critics with prominent industry players investing heavily in one or more of these
technologies. The race is on to determine which qubit technology will emerge as the dominant choice. Be prepared to participate in a
discussion with our panel of experts as they weigh in on the advantages and challenges associated with each of the innovative
approaches to determine whose qubit will rise to the top.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Tuesday, February 21
EE3: Future of Analog Design: Still Magical or Mostly Digital?
A gradual paradigm shift has occurred over the past four decades for implementing analog functions in IC design from classical analog
circuits to digital-intensive circuits. The emergence of new digital architectures has further prompted explosive growth in digital circuits
providing analog functionality, including digital radios, transmitters (TXs), receivers (RXs), phase-locked loops (PLLs), low-dropout
voltage regulators (LDOs), and time-based analog-to-digital converters (ADCs). The success of these new digital approaches has been
further driven by improvements in area, power, and design time in advanced technology nodes. Classical analog circuits, however, often
provide superior performance as compared to their digital counterparts. In this panel, experts across industry and academia will explore
this digital/analog divide and provide insights into this IC design trade-off, including in the context of emerging technology trends.
EE4: The Next Decade of AI – Barriers, Opportunities, & Directions
The past decade has witnessed dramatic advances in Artificial Intelligence (AI) hardware, software, and models, paving the way for AI
applications that are shaping many facets of our everyday life. As AI ushers us into the next boom in autonomy, productivity, and
creativity, there are critical challenges that lie ahead such as energy consumption, costs, data availability, and government regulations
to name a few. Which of these or other potential barriers will limit AI progress in the next decade? What will be the unintended
consequences of the emergence of AI and what can we do to curb these? Which opportunities may arise from innovating solutions to
overcome these challenges? Our evening panel of experts in AI hardware, software, models, and government policy offer insightful
perspectives on these and other consequential questions that will influence the course of AI in the coming decade.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session Overviews and Highlights
ISSCC 2025
SESSION OVERVIEWS
AND HIGHLIGHTS

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Conditions of Publication
PREAMBLE
The Session Overviews and Highlights to follow serve to capture the context, highlights, and potential impact, of the papers to be
presented in each Session at ISSCC 2025 in February.
OBTAINING COPYRIGHT to ISSCC press material is EASY!
You may quote the Subcommittee Chair as the author of the text if authorship is required.
You are welcome to use this material, copyright- and royalty-free, with the following understanding:
o That you will maintain at least one reference to ISSCC 2025 in the body of your text, ideally retaining the date and
location. For detail, see the FOOTNOTE below.
o That you will provide a courtesy PDF of your excerpted press piece and particulars of its placement to
lcfujino@aol.com and shahriar@ece.ubc.ca
FOOTNOTE
• From ISSCC’s point of view, the phraseology included in the box below captures what we at ISSCC would like your readership
to know about this, the 72nd appearance of ISSCC, on February 16th to February 20th, 2025.
This and other related topics will be discussed at length at ISSCC 2025, the foremost global forum for new
developments in the integrated-circuit industry. ISSCC, the International Solid-State Circuits Conference,
will be held on February 16 - February 20, 2025
ISSCC Press Kit Disclaimer
The material presented here is preliminary.
As of November 5, 2024, there is not enough information to guarantee its correctness.
Thus, it must be used with some caution.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 2 Overview: Processors
Digital Architectures and Systems Subcommittee
Session Chair: Nathaniel Pinckney, Nvidia, Austin, TX
Session Co-Chair: Jie Gu, Northwestern University, IL
Processors are the driving workhorses of modern high-performance computing. This session presents the next-generation processors
for both general-purpose computing and specialized computing. The first three papers deliver the next-generation CPU processors and
networking processors, followed by a 20-chiplet heterogenous 2.5D system in the fourth paper. The remaining papers present the state-
of-the-art super-resolution image and video processors, as well as advanced 3D rendering processors.
• In Paper 2.1, AMD presents Zen5, their next-generation x86-64 microprocessor core, targeting both desktop and laptop applications. Built in
TSMC’s 4nm FinFET process, the 55mm2 core complex integrates 8.6B transistors across 8 CPU cores. Each core delivers a generational
~16% IPC improvement over Zen4, while maintaining a maximum frequency of 5.7GHz.
• In Paper 2.2, IBM showcases their next-generation 5.5GHz Telum II microprocessor with an enhanced AI accelerator and a new Data
Processing Unit for I/O offload. The 600mm2 die with 43B transistors in 5nm benefits from +40% L2 cache, on-chip voltage control, +36% X-
BUS bandwidth, and reliability enhancements, while staying within 5% power of the prior generation.
• In Paper 2.3, Intel describes the integration of their Xeon 6 SoC, Granite Rapids-D. In exploring the I/O die built in Intel 4 technology, details
of the 200Gbps Enterprise-Grade Ethernet, 32 lanes of 32Gbps PCIe5, and 16 lanes of PCIe4 are provided. Hardware accelerators
demonstrate 1.8× improvement in system-level benchmarks over prior generations.
• In Paper 2.4, Intel presents a 2.5D package integration approach with workload-dependent configurations. The system features 20 chiplets
from two different foundries assembled over a passive silicon base (22mm×19mm, >1650000mbumps, 120 power domains) with a power of
20.52W at 300MHz and running deep learning inference at a peak of 72TOPS.
• In Paper 2.5, National Tsing Hua University and Taiwan Semiconductor Research Institute present a 16nm CNN processor supporting
bidirectional FPN for small-object detection on high-resolution videos, achieving 5.7TOPS for 26.4% COCO mAPs on 896×896 inputs at
26.6fps with 1373mW at 1.09V.
• In Paper 2.6, Tsinghua University presents a 28nm 2.43mm2 3D Gaussian splatting processor for multi-scenario rendering on edge devices.
The work exploits dynamic reconfiguration through hybrid rasterizing and interpolating to achieve 1.96× higher peak throughput, while
delivering 7.9× lower energy per frame over state-of-the-art 3D rendering accelerators.
• In Paper 2.7, KAIST university presents a 28nm 20.25mm2 3D Gaussian splatting SoC for real-time interactive rendering. The spatial
computing SoC achieves 72fps real-time rendering with 34× faster performance and 300× lower energy than an edge GPU.
• In Paper 2.8, National Taiwan University and Google present an image signal processor for true video super-resolution (VSR) by utilizing
inter-frame dependencies. The 40nm 6.8mm2 chip delivers 210fps for 4K UHD with 3.5× higher frame rate and 7.3× better energy efficiency
than previous works.
• In Paper 2.9, National Tsing Hua University and TSMC present an 16nm 8mm2 space-time resolution enhancement neural-network processor
for next-generation display and streaming, achieving 8K-UHD 60fps inference with 10.2TOPS and 1425mW at 400MHz.
• In Paper 2.10, Fudan University presents a 22nm 6mm2 low-power (0.52mJ/frame), high-throughput (1K@107fps) super-resolution
processor. It uses a channel-number-adaptive caching strategy to reduce on-chip memory by 90%, a workload-balance engine cutting
execution cycles by 64%, and a hybrid data flow improving hardware utilization by 75%.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 2 Highlights: Processors
[2.1] “Zen 5”: The AMD High-Performance 4nm x86-64 Microprocessor Core
[2.2] IBM Telum II: Next Generation 5.5GHz Microprocessor with On-Die Data
Processing Unit and Improved AI Accelerator
[2.3] Granite Rapids-D: Intel Xeon 6 SoC for vRAN, Edge, Networking, and Storage
[2.6] A 1.78mJ/Frame 373fps 3D GS Processor Based on Shape-Aware Hybrid
Architecture Using Earlier Computation Skipping and Gaussian Cache Scheduler
[2.8] A 210fps Image Signal Processor for 4K Ultra HD True Video Super-Resolution
Paper 2.1 Authors: Teja Singh1, Sundar Rangarajan1, Shane Southard1, Alex Schaefer1, Sarah Tower1, Spence Oliver1, Kathy
Hoover1, Deepesh John1, Ted Antoniadis1, Shravan Lakshman1, Vibhor Mittal1, Brian Kasprzyk1, Ross McCoy1, Kurt Molhman1, Russ
Schreiber1, Sahilpreet Singh2, Carson Henrion3, Brett Johnson3, Nick Lance3, Darryl Prudich3, Justin Coppin3, Tim Jackson3, Anita
Karegar3, Ryan Miller3, Sabeesh Balagangadharan4, Hon-Hin Wong5, Wilson Li5, Michael McCabe5, James Pistole5, Daryl Lieu5
Paper 2.1 Affiliation: 1AMD, Austin, TX, 2AMD, Markham, ON, Canada, 3AMD, Fort Collins, CO, 4AMD, Bangalore, India, 5AMD, Santa
Clara, CA
Paper 2.2 Authors: Gerald Strevig1, Chris Berry2, Rahul Rao3, Noam Jungmann4, Michael Sperling2, Michael Becht2, Eduard Herkel5,
Matthias Pflanz5, Pat Meaney2, Michael Romain2, Mark Cichanowski1, Amanda Venton1, David Wolpert2, Elazar Kachir4, Luke
Hopkins2, Tim Bubb2, Andreas Arp5, Daniel Kiss5, Simon Büchsenstein5, Michael Wood2, Michael Spear1, Robert Sonnelitter2, Rajiv
Joshi6
Paper 2.2 Affiliation: 1IBM Infrastructure, Austin, TX, 2IBM Infrastructure, Poughkeepsie, NY, 3IBM Infrastructure, Bangalore, India,
4IBM Infrastructure, Tel Aviv, Israel, 5IBM Infrastructure, Böblingen, Germany, 6IBM Research, Yorktown Heights, NY
Paper 2.3 Authors: Raj R Varada1, Rohini Krishnan2, Ajith Subramonia2, Rathish Chandran2, Kalyana Chakravarthy2, Uttpal D Desai2,
Yun Kim1, Puneesh Puri2, David R Mulvihill3, Mike Bichan4, Vijayalakshmi Ramachandran5
Paper 2.3 Affiliation: 1Intel, Santa Clara, CA, 2Intel, Bengaluru, India, 3Intel, Fort Collins, CO, 4Intel, Toronto, ON, Canada, 5Intel,
Chandler, AZ
Paper 2.6 Authors: Xiaoyu Feng, Hedi Wang, Chen Tang, Huazhong Yang, Yongpan Liu
Paper 2.6 Affiliation: Tsinghua University, Beijing, China
Paper 2.8 Authors: Ying-Sheng Lin1, Jun Nishimura2, Chia-Hsiang Yang1
Paper 2.8 Affiliation: 1National Taiwan University, Taipei, Taiwan, 2Google, Mountain View, CA
Subcommittee Chair: Rahul Rao, IBM, Bangalore, India, Digital Architectures and Systems
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
CONTEXT AND STATE OF THE ART
● Slowing generational process scaling is bolstered by architectural improvements and AI accelerator integration, bringing
respectable IPC uplifts and sizable AI workload improvements.
● Lossy video encodings have been supercharged by machine learning to save on bandwidth and energy, while custom SoCs
focus on edge rendering.
● Multi-foundry 2.5D packaging integration allow for assembly-time configurations to better meet application demands.
TECHNICAL HIGHLIGHTS
● AMD presents Zen 5, their next-generation x86-64 microprocessor core.
o Microarchitectural improvements combined with L1/L3 cache size increases deliver a ~16% IPC increase in the
5.7GHz CPU core, while technology scaling combines with physical optimizations to achieve a 30% increase in
transistor density vs. Zen4.
● IBM demonstrates their 5nm Telum II microprocessor with an enhanced AI accelerator and new IO engine.
o Support for INT8 AI acceleration increases system compute performance to 768TOPs with 30 higher AI
TOPs/thread, while overall IPC per Watt increases by 1.3.
● Intel describes the integration of their Xeon 6 SoC, Granite Rapids-D.
o Designed to support both server-grade and edge applications, the SoC showcases a 200Gbps enterprise-class
Ethernet, 48 PCIe lanes with a total bandwidth of 189GB/s, and hardware accelerators delivering a 1.8 performance
lift.
● Tsinghua University demonstrates a Gaussian splatting processor for multi-scenario rendering aimed at next-
generation 3D rendering applications on power-constrained edge-devices.
o The processor achieves 1.96 higher peak throughput, 3.18 higher area-normalized throughput and 7.9 lower
energy per frame over SOTA 3D rendering accelerators, through a combination of dynamic reconfiguration and
cache-based spatio-temporal scheduling.
● National Taiwan University and Google present an image signal processor for true video super-resolution (VSR),
utilizing inter-frame dependency in encoded videos.
o The chip achieves a maximum frame rate of 210fps for 4K UHD, with 3.5 higher frame rate and 7.3 greater energy
efficiency than prior multi-image super-resolution designs, consuming 344 mW at 200MHz from a 0.98V supply.
APPLICATIONS AND ECONOMIC IMPACT
● Disaggregation of traditionally monolithic die into chiplet-based systems continues with increasing diversity into a wider range
of applications.
● Super-resolution video accelerators driven by machine learning techniques are rapidly increasing in frames per second and
resolution under tight edge energy budgets, while saving significantly on bandwidth.
● Real-time 3D edge processing unlocks potential in virtual reality and embodied artificial intelligence applications.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 3 Overview: Amplifiers and Analog Front-Ends
Analog Subcommittee
Session Chair: Jiawei Xu, Fudan University, Shanghai, China
Session Co-Chair: Ippei Akita, AIST, Tsukuba, Japan
Amplifiers and analog front-ends continue to achieve high precision without sacrificing power efficiency and stability. The first presentation
describes an audio amplifier utilizing a single-inductor buck-boost power stage to boost output power and achieve a high dynamic range
with low-voltage input devices. The following two presentations focus on improving the bandwidth-power efficiency and temperature
stability of precision amplifiers, respectively. The final paper showcases an on-chip heater-based self-trimming technique to enable easy
and fast post-package trim.
• In Paper 3.1, National Cheng Kung University presents a double-sided voltage-boosting (DSVB) modulation scheme that integrates a capacitively-
coupled chopper amplifier with a single-inductor buck-boost power stage achieving 121.3dB DR, 0.0019% THD+N, 87.2% peak efficiency, and
maximum POUT of 1.6W with an 8Ω load.
• In Paper 3.2, Fudan University introduces a 36V current-balancing instrumentation amplifier (CBIA) with adaptive biasing for improving power-
efficient input range, and negative capacitance for noise reduction and bandwidth extension, achieving 400MHz/µA GBW/IQ in a standard 0.18µm
BCD process.
• In Paper 3.3, Leibniz University Hannover shows a 3-in-1 multi-mode trimming-free amplifier with a Logarithmic Conformity Error (LCE) of 0.75%
over the full temperature range from -25 to 200°C.
• In Paper 3.4, Tsinghua University and TU Delft present an on-chip heater-based 2-temperature self-trimming technique. The CMOS opamp
achieves an offset of ±5.8μV (3σ) at room temperature and an offset drift of ±88nV/°C (3σ) from-40 to 125°C.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 3 Highlights: Amplifiers and Analog Front-Ends
[3.1] A 121.3dB-DR, 115dB-PSNR, Digital-Input Capacitive-Feedback Class-D Audio
Amplifier with Double-Sided Voltage-Boosting (DSVB) Modulation
Paper Authors: Jhuang-Wei Cyue, Tai-Haur Kuo
Paper Affiliation: National Cheng Kung University, Tainan, Taiwan
Subcommittee Chair: Viola Schaffer, Texas Instruments Deutschland GmbH, Freising, Germany, Analog
CONTEXT AND STATE OF THE ART
• In power-efficient Class-D audio amplifiers (CDAs), the maximum output power is limited by the available battery voltage.
• Although a capacitively-coupled chopper-amplifier (CCCA) topology-based CDA eliminates the thermal noise from the
resistive feedback, existing feedback-after-LC architecture requires two pairs of LC filters.
TECHNICAL HIGHLIGHTS
• National Cheng Kung University shows a double-sided voltage-boosting (DSVB) modulation scheme that integrates a
CCCA with a single-inductor buck-boost power stage, allowing to use only a single off-chip inductor (1L) and achieve
additional output power-boost capability.
• The Class-D audio amplifier achieves 121.3dB DR, 115dB PSNR, 0.0019% THD+N, 87.2% peak efficiency, and maximum
POUT of 1.6W with an 8Ω load.
APPLICATIONS AND ECONOMIC IMPACT
• The double-sided voltage-boosting (DSVB) modulation scheme not only increases the output power with high efficiency and
high dynamic range, but also effectively reduces modulation-induced common-mode EMI.
• The single-inductor buck-boost power stage leads to smaller PCB area and lower manufacturing costs.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 4 Overview: Analog Techniques
Analog Subcommittee
Session Chair: Jiawei Xu, Fudan University, Shanghai, China
Session Co-Chair: Drew Hall, University of California, San Diego, CA
Analog techniques to improve circuit performance, power efficiency, and cost-effectiveness are presented. The first paper introduces a
high-speed ADC front-end, followed by the second paper showing a fully integrated frequency management module. The next two papers
describe new analog conduction angle control techniques for ultra-low-power crystal oscillators, and a highly power-efficient RC oscillator
with an improved temperature coefficient follows. The last paper presents a CMOS-based voltage reference in a 3nm FinFET technology.
• In Paper 4.1, the University of Twente presents a 12.8GS/s 4× time-interleaved track-and-hold front-end. Fabricated in 22nm FDSOI, this ADC
front-end achieves 40.9dB SNDR and 49.6dB SFDR at 30.2GHz input frequency for RF sampling applications without the need for skew
calibration.
• In Paper 4.2, Shanghai Jiao Tong University introduces a 1.8-to-3.0GHz fully integrated frequency management module that employs a direct
frequency synthesis structure, achieving –47/+42ppm inaccuracy from –40 to 95°C and –150/+70ppm after accelerated aging while supporting a
fast frequency hopping with a 7μs settling time.
• In Paper 4.3, Hong Kong University of Science and Technology presents a crystal oscillator that controls its conduction angle by amplitude for
adaptive Class-C operation. This 32.768kHz oscillator consumes 0.36nW power and occupies only 820μm2 of area, the smallest among the state-
of-the-art crystal oscillators.
• In Paper 4.4, the Technical University Munich shows an ultra-low-power 32.768kHz oscillator with an analog amplitude regulation for sub-nano
power consumption of 0.36nW at 0.9V. The 0.047mm2 design in 0.18um CMOS technology enables a large supply voltage range from 0.9 to 2V
with process tracking.
• In Paper 4.5, the University of Electronic Science and Technology of China presents an open-loop reference-replication-based RC oscillator. The
prototyped 10MHz RC oscillator in 65nm CMOS achieves a power efficiency of 0.4μW/MHz, a temperature coefficient of 9.83 ppm/°C from –40
to 125°C, and a die area of 0.0085mm2.
• In Paper 4.6, TSMC presents a single-Vth CMOS-based voltage reference in a 3nm FinFET technology. The circuit provides a ripple-less reference
voltage with a line regulation of 0.04%/V, a power-noise rejection of <–40dB from DC to 1GHz, an untrimmed peak inaccuracy of 2.1%, and a
temperature coefficient of 31ppm/°C at a 0.8V supply while occupying a 294μm2 area.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 4 Highlights: Analog Techniques
[4.3] A 0.36nW, 820μm2, 32kHz Conduction-Angle-Adaptive Crystal Oscillator in 28nm
CMOS for Real-Time Clock Applications
Paper Authors: Peng Wang1, Manyu Wang1, Guangnan Dai1, Yujia Cao1,2, Sining Pan2, Yihan Zhang1
Paper Affiliation: 1Hong Kong University of Science and Technology, Hong Kong, Hong Kong, 2Tsinghua University, Beijing, China
Subcommittee Chair: Viola Schaffer, Texas Instruments Deutschland GmbH, Freising, Germany, Analog
CONTEXT AND STATE OF THE ART
● In duty-cycled sensor nodes, the ultra-low-power 32.768kHz crystal oscillator with good frequency stability plays a critical role
as an always-on real-time clock.
● Although pulse-injection crystal oscillators are popular due to their sub-nW power consumption, they require accurate injection
timing control, leading to complexity and area overhead. They also need separate start-up circuits to initiate the oscillation.
TECHNICAL HIGHLIGHTS
● Hong Kong University of Science and Technology and Tsinghua University present a conduction-angle-adaptive
crystal oscillator that controls the conduction angle by amplitude for adaptive Class-C operation, allowing a larger
conduction angle to avoid the overhead caused by the need for generating accurate delays.
o The crystal oscillator consumes a record-low 0.36nW power and occupies only 820μm2 of area, the smallest among
the state-of-the-art crystal oscillators.
o The crystal oscillator also has an intrinsic start-up capability, making it easy to use.
APPLICATIONS AND ECONOMIC IMPACT
● The ultra-low-power real-time clock can reduce the overall power consumption of the duty-cycled sensor node system.
● Small area lowers manufacturing cost, and intrinsic start-up capability makes it readily applicable to the system.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 5 Overview:
Front-End Circuits for High-Performance Transceivers
RF Subcommittee
Session Chair: Henrik Sjöland, Ericsson Research and Lund University, Lund, Sweden
Session Co-Chair: Hongtao Xu, Fudan University, Shanghai, China
Front-end circuits continue to evolve, demonstrating higher power efficiency, output power, and supported data-rates, along with increased
robustness to antenna impedance variations and higher integration levels. The first paper in this session presents a GaN PA operating in a
switchless Class-G Doherty continuum, achieving high efficiency over a wide bandwidth. This is followed by four papers showcasing the latest
developments in PA circuits. The next 4 papers focus on digital transmitters that deliver high output power, efficiency, and linearity. The final two
papers are on LNAs, with the last one demonstrating an LNA with improved linearity using a Doherty architecture.
• In Paper 5.1, Tsinghua University presents a GaN PA with high back-off efficiency over a wide frequency range operating in a SLCG-Doherty
continuum. It achieves over 38% efficiency at 6dB back-off from 1.35 to 7.6GHz.
• In Paper 5.2, Shanghai Jiao Tong University introduces a digital PA for beamforming transmitters with enhanced back-off efficiency. This design
in a 0.18µm SiGe technology achieves a peak 6dB back-off efficiency of 16% at 24GHz.
• In Paper 5.3, the University of Electronic Science and Technology of China shows a mm-wave PA with radial power combining. The 56-to-64GHz
PA in a 40nm bulk CMOS technology provides 30.2dBm PSAT with 23.5% PAE.
• In Paper 5.4, Samsung Electronics presents a 5G FR2 Doherty PA using 3-stack amplifier stages with an operation amplifier bias scheme. From
24 to 29GHz the 22nm FDSOI chip delivers a 5G NR 64-QAM OFDM 100MHz signal with Pavg>16.5dBm at an EVM of -25dB.
• In Paper 5.5, ETH Zürich demonstrates a compact and wideband load insensitive PA for large-scale phased arrays. The 22nm SOI design
operates from 34 to 40.8GHz, has a core area of 0.093mm2, and an OP1dB of 17.3dBm with a PAE of 37%.
• In Paper 5.6, the Institute of Science Tokyo presents a CORDIC-less digital polar transmitter using only 1b DSM-based PA and 3b PM signal
controls. It can support 50MS/s 256-QAM while achieving a PAE over 20% at 1.35GHz.
• In Paper 5.7, the University of Electronic Science and Technology of China introduces a polar SCPA using slope-to-phase self-calibration, which
achieves 27.7dBm peak Pout and 37.8% peak PAE at 4.7GHz. It can support 160MHz 64-QAM and 80MHz 256-QAM signals without a DPD.
• In Paper 5.8, the Delft University of Technology demonstrates a 20W CMOS/LDMOS digital transmitter with dynamic retiming and a glitch-free
phase mapper, achieving 68%/62% Peak Drain/System Efficiency at 1.7GHz.
• In Paper 5.9, Xidian University shows a 21-to-31GHz DPD-less quadrature RFDAC with invariant impedance and scalable LO leakage. It can
support 2.4Gb/s 256-QAM without a DPD and high-order modulation up to 4096-QAM.
• In Paper 5.10, the University of California, San Diego presents a mm-wave low-noise active bandpass filter employing an all-passive interferer
cancellation feedforward path. It consumes 3.5mW from 22 to 27GHz and achieves a noise figure of 3.8dB and an EVM<0.84% for up to 1024-
QAM 800MHz-bandwidth signals.
• In Paper 5.11, the University of Texas, Austin demonstrates a blocker-tolerant mm-wave low-noise amplifier utilizing Doherty load modulation. It
has 2.5dB NF at 27.2GHz and supports 400MHz 64-QAM with a -13.7dBm in-band blocker.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 5 Highlights:
Front-End Circuits for High-Performance Transceivers
[5.1] A GaN SLCG-Doherty-Continuum Power Amplifier Achieving >38% 6dB Back-Off
Efficiency over 1.35 to 7.6GHz
[5.6] A Power-Efficient CORDIC-less Digital Polar Transmitter Using 1b DSM-Based PA
Supporting 256-QAM
Paper 5.1 Authors: Guansheng Lv, Wenhua Chen, Xiaofan Chen, Zhenghe Feng
Paper 5.1 Affiliation: Tsinghua University, Beijing, China
Paper 5.6 Authors: Yuncheng Zhang, Zezheng Liu, Duo Li, Minzhe Tang, Yi Zhang, Hongye Huang, Dingxin Xu, Waleed Madany,
Ashbir Aviat Fadila, Wenqian Wang, Yuang Xiong, Daxu Zhang, Garry Pranata Kusuma, Hiroyuki Sakai, Kazuaki Kunihiro, Atsushi
Shirane, Kenichi Okada
Paper 5.6 Affiliation: Tokyo Institute of Technology, Tokyo, Japan
Subcommittee Chair: Brian Ginsburg, Texas Instruments, Allen,TX, RF subcommittee
CONTEXT AND STATE OF THE ART
● Front-end circuits with high power efficiency, providing high signal quality, and low noise and distortion are essential to
applications like 5G communications.
● Transceivers front-ends with wide bandwidths and high integration levels are key to reducing size and cost while supporting
high peak data-rates and operation across multiple frequency bands.
● Innovations on circuit and architecture levels, combined with advancements in semiconductor technologies, continue to
enhance front-end performance and functionality.
TECHNICAL HIGHLIGHTS
● Tsinghua University introduces a GaN PA achieving high back-off efficiency over a wide frequency band by
introducing operation in a switch-less Class-G-Doherty continuum.
o More than 38% 6dB back-off drain efficiency over a 1.35 to 7.6GHz frequency band is obtained. For a 100MHz LTE
signal with a 7.5dB PAPR, the average power is 29.1 to 31dBm with a drain efficiency from 35 to 49.2%.
● Tokyo Institute of Technology presents a CORDIC-less digital polar transmitter with good linearity and power
efficiency.
o The digital polar transmitter uses only a 1b DSM-based PA and 3b PM signal controls. It can support 50MS/s 256-
QAM and exhibits a PAE over 20% at 1.35GHz
APPLICATIONS AND ECONOMIC IMPACT
● Enhanced front-end performance improves the capacity of wireless communication and enables new wireless applications.
● Improved power efficiency extends battery life in mobile devices and reduces electricity costs for infrastructure.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 6 Overview: Imagers and Displays
Imagers, Medical, and Displays Subcommittee
Session Chair: Leonardo Gasparini, FBK, Trento, Italy
Session Co-Chair: Hyung-Min Lee, Korea University, Seoul, Korea
Image sensor technology continues to evolve in two main directions: (1) high-resolution, high-dynamic-range, high-speed imaging using 3D integrated technology, and
(2) low-power, background-resilient depth sensing using SPADs. The first paper introduces a high-resolution imager with hybrid shutter operation. This is followed by
two SPAD-based time-of-flight sensors, excelling in low power consumption, and immunity to strong background light, respectively. Finally, three imagers with pixel-
parallel ADC architectures are presented, offering high-quality global-shutter solutions for consumer cameras, AR/VR systems, and LW-IR imaging.
Display technology continues to advance in two main directions: (1) source-driver ICs with uniform, high color depth, area- and power-efficient design, and (2) touch
analog front-end ICs with high SNR and frame rate. The first three papers introduce different source-driver ICs: the first is designed for OLED-on-Silicon (OLEDOS)
displays with uniform outputs, the second features an OLED driver IC with a real-time pixel compensator, and the third focuses on a compact OLED driver IC utilizing
a delta-sigma modulation technique. The final paper presents an EMI-reduced touch analog front-end IC for CISPR 25 class 5 for automotive displays.
• In Paper 6.1, Samsung Electronics describes a 3-layer stacked CMOS Image Sensor providing switchable operation between a 50 Mpixel rolling shutter and a
12.5 Mpixel global shutter. The sensor provides a triple conversion gain, a FWC of 52 ke- and a RN as low as 2.4 e- in global shutter mode.
• In Paper 6.2, a joint development led by Ulsan National Institute of Science and Technology presents a 160×90 Flash LiDAR with variable frame rate, between 5
and 250fps, based on the available pixel SNR, through a combination of quaternary-search and indirect time-of-flight. The LiDAR system achieves 6cm precision
and 8cm accuracy in the range 1.5 to 22.5m, sustaining up to 30klux background light.
• In Paper 6.3, a joint development led by Yonsei University describes a 64×64-pixel, SPAD-based indirect time-of-flight sensor with 120klux background light
rejection capabilities thanks to the integration of a chopper in the in-pixel analog counter. The sensor covers a range of 76m with a precision of 6.4cm, and it is
able to acquire depth images at 50fps at 39.4mW power consumption.
• In Paper 6.4, Brillnics and Meta introduce a 3-layer stacked, 400×400-pixel CMOS Image Sensor with per-pixel ADC. By incorporating advanced processing
stages, including a frame averaging unit, an image processing unit, and a sparse readout mechanism, this Digital Pixel Sensor achieves a single-exposure DR of
117dB while consuming 3.06mW at 30fps, and FoM of 0.0049 e-rms∙pJ.
• In Paper 6.5, Sony Semiconductor Solutions reveals a 2-layer stacked, 25.2 Mpixel global shutter CMOS Image Sensor with pixel-parallel 14b ADC. The sensor
can acquire images at 120fps with a random noise of 2.66 e-rms at 0dB gain, achieving a record FoM of 0.083 e-rms∙nJ/step, previously achieved only by rolling-
shutter architectures.
• In Paper 6.6, Peking University presents a 320×256, 120.4dB Long-Wavelength Infrared Focal Plane Array. Leveraging on a pixel-parallel, low-power, 20b ADC
architecture based on a light-current-controlled oscillator, the sensor acquires images at 60fps with 2.2mK NETD, while consuming 6.4mW of power.
• In Paper 6.7, Hanyang University describes a 65nm CMOS source-driver IC designed for 6285-PPI OLED-on-Silicon displays, supporting 4K×4K resolution at a
120Hz frame rate. With all-channel automatic offset calibration and data-difference-dependent dynamic current source, the driver achieves a settling time of
0.69μs, DVO of 1.9mV, and silicon area per channel of 2273μm².
• In Paper 6.8, Korea University presents a 250nm CMOS source-driver IC for OLED with a real-time pixel compensator to minimize pixel variation effects. While
the driver supports the 4T1C pixels, the pixel compensator achieves a silicon area of 4442.8μm² and power consumption of 13.3μW per channel, utilizing 6
channels per single-pixel compensator.
• In Paper 6.9, a joint development led by Korea University presents an area efficient 10b source-driver IC with delta-sigma modulation interpolation DAC using
65nm CMOS process. The delta-sigma modulation DAC consists of low-voltage transistors and supports high linearity, achieving the smallest silicon area of
1884μm² and static current of 1.5μA per channel.
• In Paper 6.10, a joint development led by Sungkyunkwan University introduces an 80nm CMOS electromagnetic interference (EMI) tolerant automotive touch
analog front-end IC for CISPR 25 class 5 compliance with low-frequency driving under 150kHz. The 2.21mm² silicon area chip achieves an SNR of 49.6dB, frame
rate of 200Hz, and a power consumption of 10.5mW for the 8.0-inch 28×18 touch screen panel.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 6 Highlights: Imagers and Displays
[6.1] A 3-Stacked Hybrid-Shutter CMOS Image Sensor with Switchable 1.2µm-Pitch
50Mpixel Rolling Shutter and 2.4µm-Pitch 12.5Mpixel Global Shutter Modes for Mobile
Applications
[6.5] A 25.2Mpixel 120frames/s Full-Frame Global-Shutter CMOS Image Sensor with
Pixel-Parallel ADC
[6.8] A Real-Time Pixel-Compensated Source-Driver IC with Dual-Slope Error Detection
and Multi-Channel Time-Multiplexing Compensator for Compact OLED Displays
Paper 6.1 Authors: Heesung Shim, Seung-Sik Kim, Min-Woong Seo, Sangsu Park, Hyukbin Kwon, Yongjun Kim, Sanggwon
Lee, Sungbong Park, Daehee Bae, Si Gyoung Koo, Masamichi Ito, Jae-hoon Jeon, Sol Yoon, Sung-Jae Byun, Sangyoon Kim,
KwanSik Kim, Gihwan Cho, Joonho Lee, Tekyou Kim, Sungjae Jun, Jae-kyu Lee, Chang-Rok Moon, Jaihyuk Song
Paper 6.1 Affiliation: Samsung Electronics, Hwaseong, Korea
Paper 6.5 Authors: Toshiki Kainuma, Ryo Wakamatsu, Kimitaka Wada, Tohru Takeda, Shota Ueyama, Hiroki Suto, Tsukasa
Miura, Koushi Uemura, Masao Kimura, Masaki Sakakibara, Yusuke Oike
Paper 6.5 Affiliation: Sony Semiconductor Solutions, Atsugi, Japan
Paper 6.8 Authors: Jaewoong Ahn, Seung Hun Choi, Jun Yeol An, Hyung-Min Lee
Paper 6.8 Affiliation: Korea University, Seoul, Korea
Subcommittee Chair: Rikky Muller, University of California, Berkeley, CA
CONTEXT AND STATE OF THE ART
● 3-layer stacked image sensor technology with high-capacity DRAM can switch from global to rolling shutter modes and
combines the strengths of both architectures to achieve a large pixel array with a high dynamic range.
● Pixel-parallel ADC enables high-speed imaging at high resolution in full-frame global shutter image sensors for full-fledged
consumer cameras.
● Compact and low-power source drivers with high tolerance to process variations of TFT in each pixel are required in many
emerging applications such as high-resolution smartphone displays.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
TECHNICAL HIGHLIGHTS
● Samsung Electronics presents a 3-layer stacked hybrid shutter CMOS image sensor capable of switching between
global shutter and rolling shutter modes. The design combines the advantages of both architectures, offering a 50MP
rolling shutter with 1.2μm pixel pitch and a 12.5MP global shutter with 2.4μm pixel pitch.
o Featuring a high-capacity DRAM technology, this hybrid approach ensures a high dynamic range, excellent full-well
capacity of 52ke-, and low random noise 2.4e-, in global shutter mode.
● Sony Semiconductor Solutions introduces a 90nm/40nm 25.2Mpixel global shutter image sensor for full-fledged
consumer cameras capable of acquiring 14b 25.2Mpixel images at 120fps with 75.5dB dynamic range.
o A pixel-parallel ADC architecture converts pixel values with 14b accuracy and a random
noise of 2.66 e-rms at 0dB gain at high speed. This results in a record FoM of 0.083 e-
rms∙nJ/step.
● Korea University discloses a source-driver IC with real-time pixel compensation for compact OLED displays in 250nm
CMOS suppressing the effect of pixel variations.
o A compensator with noise-reduction current conveyor and dual-slope error detector reduces the pixel variation effect
while achieving the smallest silicon area of 4442.8μm² and the lowest power consumption of 13.3μW per channel.
APPLICATIONS AND ECONOMIC IMPACT
● Leveraging on 3D integrated technology, CMOS Image Sensors can acquire high-resolution, large-bit-depth images at high
frame rates and low power without compromises on image quality, opening new opportunities in consumer applications,
including mobile, AR/VR, and full-fledged cameras.
● High-quality displays with compact, low-power, pixel-compensated source drivers are suitable for mobile devices.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 7 Overview: Ultra-High-Speed Wireline
Wireline Subcommittee
Session Chair: Ben (Hyo Gyuem) Rhew, Samsung Electronics, Hwaseong, Korea
Session Co-Chair: Jay Im, AMD, San Jose, USA
Subcommittee Chair: Thomas Toifl, Cisco Systems, Thalwil, Switzerland
The advent of AI (artificial intelligence) and HPC (high performance computing) stretches the data communication bandwidth limit between chips,
modules, and data centers, leveraging ultra-high-speed wireline transceivers. The papers in this session describe transmitter and receiver architectures
that enable ultra-high-speed operation while consuming low power. The first two papers (7.1 and 7.2) present 212.5Gb/s DSP-based PAM-4 transceivers
compensating beyond long-reach channels (> 40dB channel loss). The third paper proposes an extra-short-reach 212.5Gb/s receiver employing a slice-
based CTLE and phase-interpolator-based clock generator achieving an energy efficiency of 1.11pJ/b. The fourth paper describes a 112 Gb/s DSP-
based PAM-4 receiver with an LC resonator-based CTLE compensating up to 52dB channel loss. The fifth paper demonstrates a 112Gb/s discrete
multitone receiver with a time-based ADC consuming 353mW. The sixth paper proposes a 106.25Gb/s PAM-4 receiver achieving an energy efficiency of
2.06pJ/b assisted by a 3-tap FFE and a 1-tap speculative DFE. Paper 7.7 and 7.9 present advancement in 50 and 60Gb/s NRZ burst-mode CDR solutions,
respectively, for passive optical network (PON) applications. Paper 7.8 describes a reference-less CDR exploiting a SAR-based frequency acquisition
technique to achieve 63.64Gb/s/μs acquisition speed. Paper 7.10, the last paper of this session demonstrates an 8-phase clock generator, achieving a
wide range of clock speeds from 8 to 28GHz with the help of a dual-feedback ring oscillator.
• In Paper 7.1, MediaTek presents a 4nm 212.5Gb/s DSP-based PAM-4 transceiver, in which each lane incorporates TX/RX PLLs. Designed in
4nm FinFET technology, the transceiver achieves an MLSD BER of 2.5e-6 and 1e-8 over a channel with 50.5dB and 46dB loss, respectively. The
RLM and SNDR of the transmitter are measured at 98.5 and 35.5dB, respectively. The receiver achieves an SNDR of 35dB at a 1GHz sinusoidal
input frequency. The transceiver consumes 5.3pJ/b per lane at a 212.5Gb/s data rate with 1.8pJ/b from DSP.
• In Paper 7.2, Marvell presents a 4-lane 212.5Gb/s PAM-4 transceiver, implemented in 5nm FinFET technology. The transceiver achieves a BER
of 6e-9 on a 46dB channel and an analog energy efficiency of 2.2pJ/b. The current mode transmitter shows an SNDR of 36.1dB and an RMS
jitter of 73fs at a 212.5Gb/s data rate.
• In Paper 7.3, Peking University presents a 224Gb/s XSR receiver in 12nm CMOS technology. The receiver features a slice-based CTLE with
optimized group delay, achieving a -3dB bandwidth of 59GHz and a maximum step size of 1.9dB. The PI-based clock generator with pre-distortion
enables an 8-way interleaved architecture. The receiver demonstrates a BER of 8.1e-7 at 224Gb/s over a 13.6dB-loss channel with only a 3-tap
TX FFE and an efficiency of 1.11pJ/b.
• In Paper 7.4, MediaTek describes a 112Gb/s DSP-based PAM-4 receiver implemented in 4nm FinFET technology. An LC-resonator-based CTLE
is proposed to compensate for > 52dB channel loss along with an analog data path latency reduction technique. A single lane receiver with CDR
consumes 210mW, and the analog transceiver occupies 0.367mm2.
• In Paper 7.5, Daegu Gyeongbuk Institute of Science and Technology demonstrates a 5nm ADC-based discrete multitone (DMT) wireline receiver
featuring a time-interleaved time-based ADC and a frequency domain DSP that equalizes DMT symbols. The receiver achieves a BER of 1e-4 at
112Gb/s over a 12dB-loss channel, consuming 353mW.
• In Paper 7.6, National Tsing Hua University presents a 106.25Gb/s PAM-4 receiver with 3-tap FFE and 1-tap speculative DFE in 28nm technology.
The adaptive FFE generates 1+0.5D and the speculative PAM-4 DFE resolves 1+0.5D response with a time-interleaved 3b+1b ADC. The receiver
can compensate for 21.2dB loss at a power efficiency of 2.06pJ/b.
• In Paper 7.7, Peking University describes an analog 50Gb/s burst-mode NRZ receiver in 28nm CMOS technology for symmetric 50G-PON. 5-tap
FFE and 7-tap DFE including 4 floating taps are implemented to achieve a sensitivity of -24dBm while consuming smaller power than the DSP-
based works. Edge equalization in this work realizes a max lock time of 15ns.
• In Paper 7.8, Xidian University proposes a reference-less CDR using a SAR-based frequency acquisition (FA) technique. The CDR achieves a
constant band switching time of 55ns utilizing the frequency error polarity information. With the help of the proposed charge pump, the total FA
time of <150ns is realized.
• In Paper 7.9, Xi’an JiaoTong University presents a 60Gb/s NRZ burst-mode CDR in 28nm technology. A cross-injection locking technique
suppresses the data-induced side-band noise of the recovered clock, with measured RJ of 140fs and TJ of 3.2ps at 30GHz. A flash phase detector
is introduced to extract the phase information within 2UI, achieving a total reconfiguration time of 0.13ns.
• In Paper 7.10, Fudan University demonstrates an 8-phase 8-to-28GHz clock generator, implemented in 28nm technology. The dual-feedback ring
oscillator proposed in this work decouples the frequency setting loop and the phase locking loop, thus expanding the maximum operation
frequency. The measured output jitter and the maximum phase error are below 40fs and 3° across 8-28GHz, respectively.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 7 Highlights: Ultra-High-Speed Wireline
[7.1] A 212.5Gb/s DSP-Based PAM-4 Transceiver with 50dB Loss Compensation for
Large AI Systems Interconnects in 4nm FinFET
Paper Authors: Henry Park*1, E-Hung Chen*2, Mohammed Abdullatif*1, Miguel Gandara1, Ahmed ElShater1, Amr Khashaba1, Shih-
Hao Huang2, Tsz-Bin Liu2, Atharav Atharav1, Joonyeong Lee1, Qaiser Nehal1, Mohamed Megahed1, Yusang Chun1, Cheng-En Shieh2,
Vidhan Jolly1, SoonWon Kwon1, Hsin-Ta Chien2, Ke-Chung Wu2, Cheng-En Liu2, Peng Yan1, Po-Jui Li2, Chun-Han Chen2, Tzu-Shun
Lin2, Pei-Chieh Liu2, Tamer Ali1
Paper Affiliation: 1MediaTek, Irvine, CA, 2MediaTek, Hsinchu, Taiwan
[7.2] A 2.2pJ/b 212.5Gb/s PAM-4 Transceiver with > 46dB Reach in 5nm FinFET
Paper Authors: A. Mostafa1, A. Hassan1, A. Hsu2, A.K. Singh3, C.-H. Wu4, C.-R. Yang1, D. Prabakaran3, D. Storaska5, D. Zhou1, D.
Visani1, E. Hsiao1, F. Chu1, F. Khan1, F. Lu1, G. Cui1, G. Wang1, H. Wang1, J. Natonio5, J. Deng1, J. Ding1, J. Guo1, J. Gu1, J. Zang1, L.
Jiang1, K. Chang1, K.-M. Lu4, M.Hasan1, M. Kelly6, M. H. Kashani2, M. Gambhir1, M. R. Patoju3, M. Singh1, M. Shannon5, M. Yang1, P.
Liu1, P. Ramakrishna3, R. Chen4, R. Ho7, S. N. Shahi8, S. Sivakumar1, S. Xu7, X. Yang1, X. Han1, Y.-P. Su4, Z. Guo1, Z. Li1, Z. Yu1, Z.
Yan1
Paper Affiliation: 1Marvell, Santa Clara, CA, 2Marvell, Toronto, Canada, 3Marvell, Bangalore, India, 4Marvell, Zhubei, Taiwan, 5Marvell,
Fishkill, NY, 6Marvell, Massachusetts, MA, 7Marvell, Burlington, VT, 8Marvell, Kanata, Canada
Subcommittee Chair: Thomas Toifl, Cisco Systems, Thalwil, Switzerland
CONTEXT AND STATE OF THE ART
• The advent of AI and high-performance computing (HPC) is pushing the bandwidth limits of data communication between
chips, modules, and data centers, relying on ultra-high-speed wireline transceivers.
• Innovative designs are crucial for achieving area and power efficiency in a 200Gb/s link while maintaining a low BER over
channels with losses exceeding 40dB.
TECHNICAL HIGHLIGHTS
• Mediatek presents a complete DSP-based PAM-4 transceiver at 212.5Gb/s in 4nm FinFET technology to compensate
channel loss over 46dB.
o The 4nm DSP-based PAM-4 transceiver incorporates TX/RX and PLLs in each lane.
o The RLM and SNDR of the transmitter and receiver are measured at 98.5% and 35.5dB respectively.
o The transceiver achieves an MLSD BER of 2.5e-6 and 1e-8 over a channel with 50.5dB and 46dB loss, respectively.
o The transceiver consumes 1127mW (5.3pJ/b) per lane at 212.5Gb/s data rate.
• Marvell demonstrates a 4-lane 212.5Gb/s PAM-4 transceiver in 5nm FinFET technology to compensate channel loss of
46dB.
o The Serdes transceiver is configured as a 4-lane module.
o The current mode transmitter shows a SNDR of 36.1dB and an RMS jitter of 73fs at a 212.5Gb/s data rate.
o The RX equalized eye after compensating for a loss of 46dB and achieving a PRE-FEC BER of 6e-9.
o The transceiver achieves an analog energy efficiency of 2.2pJ/b at a 212Gb/s data rate.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
APPLICATIONS AND ECONOMIC IMPACT
• Long-reach low-power 224Gb/s PAM-4 SerDes transceivers are key components to enable 1.6Tb/s Ethernet for emergent AI
applications.
• Burst-mode NRZ receivers incorporating an equalizer mitigate the bandwidth limitations of optical devices in the next
generation passive optical access networks.
• The presented circuits demonstrate application potentials in standards such as PCIe 7.0, 50G-PON, IEEE802.3dj and OIF
CEI-224G.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 8 Overview: Digital Techniques for System
Adaptation, Power Management and Clocking
Digital Circuits Subcommittee
Session Chair: Heein Yoon, UNIST, Ulsan, South Korea
Session Co-Chair: Benton Calhoun, University of Virginia, Charlottesville, VA
Digital architectures continue to improve energy efficiency through closed-loop hardware-software integration, on-die sensors, and real-
time adaptation. The first four papers in this session exemplify power management techniques that improve computing and energy
efficiency and enable efficient Dynamic Voltage and Frequency Scaling (DVFS) in computing systems such as CPU and SoCs. In the
second half of this session, papers explore advanced clocking and power management circuits, featuring a command-aware hybrid LDO
for HBM, a low-spur low-jitter all-digital output frequency divider, two sensors for monitoring thermal profiles or supply and temperature
simultaneously, and an on-cell battery monitoring system.
• In Paper 8.1, IBM presents dynamic guard-band features for the 5nm 5.5GHz zNext computing system. A combination of on-die sensors, a run-
time control loop, and reliability, serviceability and availability features demonstrate savings of 18% total chip power corresponding to 10% system
power savings enabling higher frequency, higher performance, multiple system configurations and new AI features.
• In Paper 8.2 MediaTek researchers present a run-time power management system featuring an on-die power sensor in a 3nm CPU, achieving
94.83% CPU power measurement accuracy with calibration by a silicon-based ML model. On-die current readouts at 10ms sampling rate limits
over-current excursion for power stability in smartphone applications.
• In Paper 8.3, Georgia Institute of Technology presents a dynamically reconfigurable voltage regulator fabric for energy-efficient DVFS in SoCs in
a 65nm CMOS process. The test chip demonstrates a peak power reduction compared to conventional static VR architectures by up to 45% over
single-buck regulation and 25% for two-buck regulation.
• In Paper 8.4, Samsung Electronics presents a voltage droop detector with a 4GHz frequency and sub-2-cycle detection latency in 2nm GAAFET
process. Experimental results demonstrate 0.69% accuracy and effective droop detection with 250ps response time, which is a 8× improvement
for over previous droop detectors, while reducing area overhead by 15-43%.
• In Paper 8.5, Seoul National University presents a command-aware hybrid LDO in a 40nm CMOS process to reduce voltage droops caused by
quarter-rate data strobe buffers in HBM by proactively leveraging the known current profile of memory accesses. The measured voltage droop is
less than 10mV, while consuming only 150mA of quiescent current with 20pF output capacitor.
• In Paper 8.6, the National University of Defense Technology presents an all-digital fractional output frequency divider in a 28nm CMOS process
integrating background calibration for both gain and INL using a split-DTC technique. The proposed design achieves spurious tones levels below
-77dBc and jitter smaller than 257fs with a chip area of 0.024mm².
• In Paper 8.7, Georgia Institute of Technology and Intel present a coupled voltage-temperature sensor employing sensor fusion in 65nm CMOS.
The proposed architecture employs pairs of low-cost sub-sensors of only 67mm² instantiated into voltage-scaled digital domains and relies on
computational sensor-fusion to achieve 2.4°C and 9mV ±3s inaccuracy.
• In Paper 8.8, Intel presents a 16nm digital thermal sensor based on a current-starved ring oscillator, aiming for fine-grain thermal profiling with
high resiliency in noisy environments. A chiplet with a buck IVR integrates an array of 204 sensors, demonstrating high accuracy of ±0.7°C
dissipating 18mW power and having a 400mm² area footprint per sensor.
• In Paper 8.9, Dukosi presents a single-chip solution in 55nm to monitor individual cells in electric vehicle battery packs using near-field contactless
monitoring to minimize the wiring overhead of up to 216 battery cells to a single antenna. The chip consumes an average of 550mW per cell at
3.7V during networked monitoring for 0.1Hz measurements and communication.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 8 Highlights: Digital Techniques for System
Adaptation, Power Management and Clocking
[8.1] Dynamic Guard-Band Features of the IBM zNext System
[8.2] Run-Time Power Management System by On-Die Power Sensor with Silicon AI
Calibration in a 3nm Octa-Core CPU
Paper 8.1 Authors: Tobias Webel1, Phillip J. Restle2, Ramon Bertran2, Alper Buyuktosunoglu2, Sean M. Carey3, Alejandro Cook1, Karl
Anderson3, Michael Romain3, Thomas Strach1, Pradeep Bhadravati Parashurama4, Aishwarya Tadkase4, Rahman Abber Tahir1, Luke
Jenkins3, Kevin Low3, Eberhard Engler1,
Paper 8.1 Affiliation: 1IBM Systems, Boeblingen, Germany, 2IBM Research, Yorktown Heights, NY, 3IBM Systems, Poughkeepsie,
NY, 4IBM Systems, Bangalore, India
Paper 8.2 Authors: Chien-Yu Lu1, Bo-Jr Huang1, Min-Chieh Chen1, Alfred Tsai1, Eric Jia-Wei Fang1, Yuju Cho1, Rex Liu1, Ericbill
Wang1, Hugh Mair2, Shih-An Hwang1
Paper 8.2 Affiliation: 1MediaTek, Hsinchu, Taiwan, 2MediaTek, Austin, TX
Subcommittee Chair: Huichu Liu, Meta, Sunnyvale, CA, Digital Circuits
CONTEXT AND STATE OF THE ART
● Dynamic adaptation and run-time power management employing on-die sensors, firmware and workload management
continues to be critical for realizing robust and energy-efficient advanced-node processors from datacenter to mobile
applications.
● Advances in on-die circuit sensing, including ML-based calibration, enable robust and efficient run-time management of digital
systems.
TECHNICAL HIGHLIGHTS
● IBM introduces dynamic guard-band features for the 5nm 5.5GHz zNext computing system.
o On-die digital droop sensors, multiple control loops, and reliability, availability and serviceability features are
effectively combined to achieve 18% total chip power reduction, resulting in 10% system power savings, enabling
higher performance system configurations and new AI features.
● MediaTek presents a run-time power management system in a 3nm octa-core mobile processor SoC, featuring an on-
die power sensor with calibration by a silicon-based ML model.
o An on-die power sensor implemented in a 3nm CPU core complex measures power draw with 94.8% accuracy. The
sensor, calibrated with a silicon-based ML model, is used to achieve per-core power budgeting and to control over-
current excursion for power stability in smartphone applications.
APPLICATIONS AND ECONOMIC IMPACT
● Dynamic guard banding and advanced run-time power management are critical to enable high performance with high
frequency and reduce total power to enable new features in systems, like AI acceleration. High accuracy on-die sensors
coupled with firmware and workload balancing provide a framework for high availability and reliable systems that reduce
overall life-time operating cost.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 9 Overview: Ubiquitous Power Delivery
Power Management Subcommittee
Session Chair: Dongsu Kim, Samsung Electronics, Hwaseong, Korea
Session Co-Chairs: Chen-Yen Ho, MediaTek, Hsinchu, Taiwan
Power delivery circuits are employed in all types of electronic applications, and their technological innovations continue to advance. In
this session, the latest advanced technologies for AC-DC converters, supply modulators for RF power amplifiers, low dropout regulators,
wireless power transfer, and hybrid converters are presented to demonstrate their novel topologies achieving higher efficiency, higher
output power, faster transient response and smaller form factor.
• In Paper 9.1, University of Macau presents a capacitor-drop sigma-floating-SC AD-DC converter for IoT and smart home devices. With a sigma-
SC rectifier and a floating-SC converter, it achieves 81.3% peak efficiency and maintain high efficiency for wide load current range.
• In Paper 9.2, University of California, Berkeley presents a fully integrated symbol-power-tracking (SPT) CMOS RF power amplifier with a non-
uniform multi-level supply modulator and a SPT-adaptive-biasing network. This work supports 5G FR2 standard with 400MHz channel bandwidth
and has a 30% improved efficiency compared to the average power tracking operation.
• In Paper 9.3, University of California, San Diego presents a GaN monolithic integrated adjustable supply modulator for digital envelope tracking
transmitters in 5G base stations. The implemented circuit supports 4 tunable voltage levels and improves the power-added efficiency of a
transmitter with a rated power of 74W/48V by 6.9%.
• In Paper 9.4, University of Science and Technology of China presents a symbol-power-tracing (SPT) supply modulator for 5G NR power amplifiers.
With a ripple-cancellation technique and a small load capacitance, it achieves fast up- and down-tracking of 510ns/5V and 900ns/5V, and <12mV
output voltage ripple.
• In Paper 9.5, Sogang University presents a sub-1V PMOS analog low dropout regulator (LDO). The LDO with a rail-to-rail pseudo impedance
buffer (RRPB) and a load-independent Gm-boosting cell (LIGC) supports very wide load current from 0 to 1.2A, input voltage from 0.7 to 1.4V and
dropout voltage from 0.05 to 0.2V while maintaining the phase margin.
• In Paper 9.6, Nanjing University presents a 6.78MHz single-stage dual-output regulating rectifier for a biomedical wireless powering. By supporting
a simultaneous charging of dual outputs in a half cycle and a charge distribution operation, it achieves 92.2% peak efficiency with a negligible
load transient response and an unnoticeable cross-regulation.
• In Paper 9.7, Xi’an JiaoTong University presents a Class-E transmitter for a wireless power transfer system. With an adaptive real-part impedance-
matching technique and an imaginary-part phase compensation controller, the transmitter achieves high transmitter efficiencies of 88.0 to 94.2%
for very wide load range from 3 to 29W, and a maximum E2E output power of 33W.
• In Paper 9.8, Samsung Electronics presents a 50W high-power wireless charging system with an acoustic noise-reduced ASK modulation
technique and an internal hybrid voltage-/current-mode ASK demodulator. This work significantly reduces an acoustic noise of MLCC capacitors
up to 20dB and eliminates all related external components of the demodulator.
• In Paper 9.9, University of Macau presents a bi-directional dual-path boost-48V-buck hybrid converter for a high-voltage power transmission cable
in light-weight humanoid robots. By reusing a parasitic cable inductor and employing a phase alignment scheme, the converter achieves a peak
efficiency of 96.7% at 16.5W and a maximum transmission power of 45W without requiring an additional bulky power inductor.
• In Paper 9.10, Southern University of Science and Technology presents a hybrid boost converter with continuous input and output currents. By
placing an inductor between two switched-capacitor step-up stages, the converter has a significantly reduced inductor current at a high voltage
conversion ratio and a fast transient response due to the elimination of a right-half-plane zero. It delivers a maximum output power of 10.8W with
a peak efficiency of 93% and a high power density of 49.5mW/mm3.
• In Paper 9.11, University of Science and Technology of China presents a single-mode hybrid buck-boost converter for Li-ion battery management.
The converter has a half-Vin voltage stress and a continuous output current delivery using 7 switches and 2 flying capacitors, and it achieves
98.3% peak efficiency and 7mV output voltage ripple without mode transition issues.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 9 Highlights: Ubiquitous Power Delivery
[9.1] An 85-230VAC to 3.3-4.6VDC 1.52W Capacitor-Drop Sigma-Floating-SC AC-DC
Converter with 81.3% Peak Efficiency
[9.2] A 400MHz Symbol-Power-Tracking (SPT) Supply Modulator with SPT-Adaptive-
Biasing Network Supporting 5G FR2 CMOS PA
Paper 9.1 Authors: Fei Song1, Shousheng Han1,2, Rui P. Martins1, Yan Lu1,2
Paper 9.1 Affiliation: 1University of Macau, Macao, China, 2Tsinghua University, Beijing, China
Paper 9.2 Authors: Jongbeom Baek, Ali Niknejad
Paper 9.2 Affiliation: University of California, Berkeley, CA
Subcommittee Chair: Bernhard Wicht, University of Hannover, Germany, Power Management
CONTEXT AND STATE OF THE ART
● A merged topology of a sigma-SC rectifier and a floating-SC converter improves output power and efficiency by the three
energy flow paths to the output capacitor.
● A non-uniform multi-level supply modulator and a SPT-adaptive-biasing network optimize the supply voltage and operating
bias point of the mmWave CMOS RF power amplifier and improve its efficiency and linearity performances.
TECHNICAL HIGHLIGHTS
● University of Macau presents a capacitor-drop sigma-floating-SC AD-DC converter with a sigma-SC rectifier and a
floating-SC converter for IoT and smart home devices.
o The AD-DC converter generates a 3.3-4.6VDC output from an 85-230VAC input with a maximum output power of
1.52W and a peak efficiency of 81.3%.
● University of California, Berkeley presents a fully integrated symbol-power-tracking (SPT) CMOS RF power amplifier
with a non-uniform multi-level supply modulator and a SPT-adaptive-biasing network.
o The SPT CMOS RF power amplifier supports 5G FR2 standard with 400MHz channel bandwidth and has a 30%
improved efficiency compared to the average power tracking operation.
APPLICATIONS AND ECONOMIC IMPACT
● The AC-DC converter with high efficiency and small form factor enhances the cost and power competitiveness of IoT and
smart home devices.
● The SPT CMOS RF power amplifier improves the performance of 5G FR2 communication in terms of data rate and power
consumption.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 10 Overview: Transceiver Chipsets for
Communication and Radar
Wireless Subcommittee
Session Chair: Matteo Bassi, Infineon Technologies, Villach, Austria
Session Co-Chair: Shahriar Shahramian, Nokia – Bell Labs, New Providence, NJ
Integrated circuits continue to advance the performance of wireless applications from a few megahertz to hundreds of gigahertz. Wireless
communication, radar chipsets & ultra-low-power transceivers are ubiquitous in our industry. This session presents several key
innovations in such domains.
• In Paper 10.1, East China Normal University demonstrates a 77GHz TDMA-MIMO Phased-Array radar implemented in a 55nm CMOS process.
It includes 8TX and 2× 4RX elements with 32dBm EIRP and 16.8dB Noise Figure while providing chirp bandwidth of 8GHz.
• In Paper 10.2, Tianjin University presents a D-Band 4TX-4RX FMCW transceiver array with Antenna-in-Package leveraging an LTCC substrate.
The module achieves a maximum of 28dBm EIRP, minimum Noise Figure of 7.8dB and up to 24GHz of chirp bandwidth.
• In Paper 10.3, ETH Zurich presents a reflect-array operating in D-Band leveraging orthogonally polarized on-chip antennas. The 4×4 array chipset
includes angle-of-arrival detection demonstrating a non-line-of-sight 6Gb/s wireless link at 1.3m.
• In Paper 10.4 Samsung Electronics presents a dual transceiver IR-UWB chipset with shared antennas that is compliant with IEEE 802.15.4/4.
The IC supports channels 5 to 12 with a peak power of 14dBm and a Noise Figure of 4.2dB with a transformer-based LC resonator at the TX/RX
shared ports.
• In Paper 10.5, XINYI Information Technology and XINYI Semi present a low-cost (QFN) 28nm RF transceiver supporting LTE Cat1bis for IoT
applications. The low-power IC consumes 40mW in receive mode and 113mW in TX mode covering 0.6 to 2.7GHz. The receiver achieves an
FDD/TDD sensitivity of better than -99dBm.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 10 Highlights: Transceiver Chipsets for
Communication and Radar
[10.2] A 132-to-148GHz CMOS 4TX-4RX FMCW Radar Transceiver Array with Cavity-
Backed Antenna-in-Package Achieving 28dBm EIRP
[10.3] A D-Band 2-D Scalable 4×4 Active Reflective Relay with Orthogonally-Polarized
On-Chip TX/RX Antennas and In-Front-End Common-Centroid Fast Azimuth/Elevation
Angle-of-Arrival Detection
Paper 10.2 Authors: Bing Liu, Jiancheng huang, Zheng Yang, Xuguang Li, Jing Zhang, Xu Wang, Hao Shi, Zhenghua Xu, Fei Li,
Ruipeng Liu, Shuangxu Li, Yongqiang Wang, Keping Wang, Haipeng Fu, Fanyi Meng, Kaixue Ma
Paper 10.2 Affiliation: Tianjin University, Tianjin, China
Paper 10.3 Authors: Basem Abdelaziz Abdelmagid, Boce Lin, Hua Wang
Paper 10.3 Affiliation: ETH Zurich, Zurich, Switzerland
Subcommittee Chair: Chih-Ming Hung, Taiwan, Taipei, Wireless
CONTEXT AND STATE OF THE ART
● With the increasing demand for data rates, the mm-wave and sub-THz spectrums have been actively explored for future high-
resolution radars and high-data-rate wireless communications.
● The high free-space path loss (FSPL) and the challenges related to establishing non-line-of-sight (NLOS) communication links
limit the effectiveness of communication and radar systems at those frequencies.
● Innovations in architectures and circuit techniques for transceivers, including packaging, help advance the performance barrier
with robustness.
TECHNICAL HIGHLIGHTS
● Tianjin University presents a 132-to-148GHz 4TX-4RX FMCW radar transceiver array that achieves state-of-the-art EIRP.
o A cavity-backed antenna-in-package (AiP) 4-transmitter and 4-receiver FMCW array achieves a remarkable 28dBm
equivalent isotropic radiated power (EIRP) without additional lenses in CMOS technology. The design incorporates a
high-power amplitude-phase harmonic modulated quadrupler, a low-loss power-combiner-based high-power power
amplifier (PA), and a cavity-backed AiP, enabling high-resolution radar and 3D imaging capabilities.
● ETH Zurich presents a D-Band active reflective relay with on-chip TX/RX orthogonally-polarized antennas.
o Non-line-of-sight (NLOS) communication is demonstrated with successful data transmission rates of 2.4 to 4.8Gb/s
over a 1.3-meter round-trip distance without prior knowledge of the incident beam's AoA. This is achieved with novel
design of a 120GHz 2-D scalable active reconfigurable reflective relay, which incorporates orthogonally polarized on-
chip 4×4 TXRX antennas and in-front-end distributed common-centroid mixed-signal fast angle-of-arrival (AoA)
detection.
APPLICATIONS AND ECONOMIC IMPACT
● Advancements in architectures, circuits and packaging techniques for mm-wave enable the development of new products and
services, such as high-capacity wireless networks, advanced radar systems, and medical imaging devices.
● Millimeter-wave technologies can improve the efficiency of existing industries by providing faster data transfer rates, higher
resolution imaging, and more accurate sensing capabilities.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 11 Overview:
RF and mm-Wave Wireless Receivers
Wireless Subcommittee
Session Chair: Negar Reiskarimian, Massachusetts Institute of Technology, Cambridge, MA
Session Co-Chair: Hao Gao, Eindhoven University of Technology, Netherlands
This session presents five papers on various techniques for improving RF and mm-wave wireless receiver performance. The first paper
demonstrates a phased-array RX capable of receiving concurrent right- and left-handed circular polarizations. Papers 2 and 5 focus on
techniques to combat interference in RF and mm-wave receivers, one using non-uniform multi-level time-approximation filtering and
another using a higher-order TIA. Paper 3 demonstrates a wideband full-duplex receiver, and Paper 4 focuses on a low-power GNSS
receiver for positioning.
• In Paper 11.1, the Institute of Science Tokyo and Axelspace present a 256-element Ka-band phased-array receiver using switch-type quadrature-
hybrid-first architecture supporting single/dual linear or circular polarizations. The receiver consumes 4.6/9.1W while receiving single/dual circular
polarizations with up to 8Gb/s data rate.
• In Paper 11.2, the University of Southern California and the University of Waterloo present a blocker-tolerant receiver featuring a non-uniform
VCO-based multi-level time-approximation filter. Operating at 32GHz, the 28nm CMOS prototype achieve maximum 65dB rejection supporting
150MHz 256-QAM modulation with EVM of -36/-31dB in the presence of a -20/+24dBc blocker.
• In Paper 11.3, Fudan University presents a 0.5-to-5GHz full-duplex RX with Hilbert transform cancellation in RF/BB based on multi-stage all pass
filters, achieving >37dB on-chip cancellation over 80-to-120MHz BW.
• In Paper 11.4, Southeast University and the Nanjing Low Power IC Technology Institute present a 28nm 0.47mm2 GNSS receiver. A 0.65V Gm-
C signal-quadrature RF front-end is embedded within a passive mixer, allowing the receiver to achieve a 3.2dB NF, -164dBm tracking sensitivity
and -148dBm acquisition sensitivity at 2mW power consumption.
• In Paper 11.5, Fudan University presents a 0.5-to-3GHz blocker-tolerant RX front-end with high linearity (OOB IIP3 of 14.4dBm and 19dBm for
offset/BW = 1 and 2, respectively) and selectivity (-100dB/decade far-OOB roll-off), for wideband applications (0.5 to 3GHz) at
71.5mW+11.7mW/GHz.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 11 Highlights:
RF and mm-Wave Wireless Receivers
[11.5] A 200MHz-BW Blocker-Tolerant Receiver with Fifth-Order Filtering Achieving
19dBm Adjacent-Channel IIP3
Paper 11.5 Authors: Liangbo Lei, Yanxiang Chen, Yijie Li, Zhiliang Hong, Yumei Huang
Paper 11.5 Affiliation: Fudan University, Shanghai, China
Subcommittee Chair: Chih-Ming Hung, MediaTek, Taiwan
CONTEXT AND STATE OF THE ART
• 5G radios need to operate over a multitude of closely spaced bands, particularly at sub-7GHz frequencies, enabling global
spectrum compatibility.
• These radios should operate over a wide frequency range with increased bandwidth while rejecting strong blockers and
interferers both within (as close as adjacent channel) and outside the band.
TECHNICAL HIGHLIGHTS
• Fudan University introduces a 0.5-to-3GHz interference-tolerant radio front-end using a first-order N-path notch filter
in parallel with the LNTA and a fourth-order TIA to achieve fifth-order filtering.
o The 40nm IC adopts a multi-gate average biasing technique within the LNTA to enhance IIP3. The proposed TIA
architecture enables a steep close-in selectivity. The RX achieves OOB IIP3 of 19dBm for offset/BW = 2 and -100
dB/decade far-OOB roll-off.
APPLICATIONS AND ECONOMIC IMPACT
• With the expansion of 5G wireless networks the need for interference-resilient radios both in-band and out-of-band becomes
more and more significant.
• Demands for higher data rates impose stringent design requirements on the RF receivers in terms of BW, power consumption
and linearity.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 12 Overview:
Innovations from Outside the (ISSCC) Box
Technology Directions Subcommittee
Session Chair: Kaushik Sengupta, Princeton University, Princeton, NJ
Session Co-Chair: Firooz Aflatouni, University of Pennsylvania, Philadelphia, PA
There have been numerous new and important developments outside the circuit community that can have profound impact on the solid-
state circuits society, either through emergence of new applications, or, via offering of new platforms for processing, communications,
and sensing. This invited session seeks to provide exposure to a few of such developments for the ISSCC audience who may not have
day-to-day interactions with such subjects in the hope of inspiring new ways of thinking in circuit design and collaboration opportunities.
• In Paper 12.1, Berkeley presents an overview of principle of computation for artificial Intelligence and optimization based on Onsager’s Principle
of minimum entropy generation, referred to as Onsager Computing as opposed to conventional Von Neumann Computing. Electrical Onsager
computers is an emerging computing paradigm with potential for drastic reduction of time and energy to solution compared to conventional
machines. The paper presents several inequalities in physics as opportunities to be utilized for energy-efficient computing.
• In Paper 12.2, Purdue presents a new paradigm of computation, which is neither analog nor digital, titled the ‘p-circuit’. The p-circuit is a stochastic
computing element, and not a deterministic Boolean function of the inputs. The output of the device is a random binary variable whose probability
of being 1 is given by an analog function of the inputs. Utilizing such devices, new computing architectures can emerge that can enable orders of
magnitude reduction in energy for computing, optimization and learning problems.
• In paper 12.3, Caltech presents methodologies for optical imaging through deep tissues. The high optical turbidity of biological tissues prevents
scientists and clinicians from performing deeply penetrating high resolution optical imaging through humans and animal models alike. The paper
presents significant advances in wavefront shaping that have allowed time-reversing scattering and enabling focusing of light deep through
biological tissue for imaging and other applications. The paper also presents opportunities for integrated optoelectronic solutions for transformative
impact.
• In Paper 12.4, Stanford presents advances in e-skin technologies for developing electronic materials inspired by skin’s properties, such as
stretchability, self-healing ability and biodegradability. This class of new active materials can enable skin-like integrated circuits for neuromorphic
signal processing to generate spike-train signals. The paper presents broad opportunities for such skin-like sensors and integrated circuits for
applications in medical devices, robotics and wearable electronics.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 12 Highlights:
TBA
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 13 Overview: Cool Computation Circuits
Technology Directions Subcommittee
Session Chair: Joseph Bardin, Google & UMass Amherst, USA
Session Co-Chair: Shawn S. H. Hsu, National Tsing Hua University, Hsinchu, Taiwan
This session focuses on cool design techniques for unconventional AI accelerators and cryogenic controllers for quantum computers.
The first two papers present high-accuracy high-dynamic-range voice activity detection and spoken language understanding SoCs
enabled by analog feature extractions. The next three papers describe cryo-CMOS ICs for ion-trap quantum processors and
semiconductor quantum devices. The final paper presents a low-cost energy-efficient DNN processor with via-programmable neuron
arrays.
• In Paper 13.1, Peking University, Advanced Institute of Information Technology of Peking University, and Nano Core Chip Electronic Technology
demonstrate a voice activity detection (VAD) system achieving 84%~98% accuracy across 0~15dB SNR at 161nW power. The system employs
an analog-domain information-aware data compressor that extracts extreme values of the raw signal to save the power of ADC and neuromorphic
temporal-spatial feature extractor.
• In Paper 13.2, University of Zurich/ETH Zurich and Aalto University present an SoC for end-to-end user intent understanding with continuous
speech input. The 65nm prototype exploits direct analog-to-feature conversion, delta-activation sparsity, and temporal pooling, to achieve >85%
32-class spoken language understanding (SLU) accuracy over 75dB input range at 8.62μW. Its analog feature extractor with global and channel-
level AGC boosts the dynamic range.
• In Paper 13.3, TU Braunschweig, Leibniz University, and Keio University present a cryo-BiCMOS 130nm IC for the control of single-qubit gates
on 9Be+ trapped ions, with the controller achieving 99.97% fidelity while dissipating 21.5mW per qubit.
• In Paper 13.4, University of Electronic Science and Technology of China presents a cryo-CMOS 65-nm controller adopting two 18-bit R-2R DACs
to accurately bias the terminals of a Single Electron Transistor (SET). Operating at 60mK with a total chip power dissipation of 60μW, each of the
DAC can ensure 0.8b/0.8b INL/DNL with a 4.5μV LSB.
• In Paper 13.5, CEA-Léti, CEA-List, CEA-Pheliqs, and Quobly present a cryo-CMOS readout IC for semiconductor spin qubits fabricated in a 22nm
FDSOI process, which exploits QAM modulation to multiplex several charge sensors for qubits sensing through the same front-end. Operated at
4.2K, the circuit dissipates 37.2μW to read out the conductance of 2 SETs with a BER=10-3 in a 5.5µs integration time.
• In Paper 13.6, University of Tokyo presents a via-programmable neuron array (VPNA) technology for low-cost, energy-efficient DNN processor
solutions for AI-IoT, where a prefabricated base chip can be configured for diverse DNN layers by adjusting the placement of vias. The proposed
bit- and neuron-serial circuit and sparse binary weighted DNN techniques reduce the chip area and the required number of tiles.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 13 Highlights: Cool Computation Circuits
[13.1] A 0.22mm2 161nW Noise-Robust Voice Activity Detection Using Information-
Aware Data Compression and Neuromorphic Spatial-Temporal Feature Extraction
[13.2] A Cryo-BiCMOS Controller for 9Be+ Trapped-Ion-Based Quantum Computers
Paper 13.1 Authors: Ying Liu*1, Jie Li*1, Qining Zhang*1, Tianhao Zhao2, Chenhao Shi1, Ninghui Shang1, Yufei Ma1, Zhixuan Wang3,
Ru Huang1, Linxiao Shen1, Le Ye1,2
Paper 13.1 Affiliation: 1Peking University, Beijing, China, 2Advanced Institute of Information Technology of Peking University,
Hangzhou, China, 3Nano Core Chip Electronic Technology, Hangzhou, China
Paper 13.2 Authors: Peter Toth1, Paul Eugine Shine1, Sebastian Halama2, Yerzhan Kudabay1, Kaoru Yamashita1,3, Hiroki Ishikuro3,
Christian Ospelkaus2, Vadim Issakov
Paper 13.2 Affiliation: Technische Universität Braunschweig, Braunschweig, Germany, 2Leibniz University Hannover, Hannover,
Germany, 3Keio University, Yokohama, Japan
Subcommittee Chair: Ali Hajimiri, Caltech, Pasadena, CA
CONTEXT AND STATE OF THE ART
● AI-enabled audio processing is widely demanded in the IoT space. Conventional digital processors are power-hungry for
such always-on applications, while analog-to-information front ends with algorithm-circuit co-design offer a promising
solution to circumvent the energy bottleneck while keeping sufficient accuracy.
● Cryogenic quantum processors are typically controlled by room-temperature electronics. However, when scaling up to the
large number of quantum bits (qubits) required for practical applications, wiring to such room-temperature controllers may
become the bottleneck.
TECHNICAL HIGHLIGHTS
● Peking University, Advanced Institute of Information Technology of Peking University, and Nano Core Chip
Electronic Technology extract extreme points from raw audio signals in the analog domain to achieve 2.6 data
reduction while keeping 97% information, which is followed by a neuromorphic temporal-spatial feature
extractor.
o The SoC achieves state-of-the-art 84%~98% voice activity detection (VAD) accuracy across 0~15dB input SNR, at
merely 161nW power consumption.
● TU Braunschweig, Leibniz University, and Keio University demonstrate a cryogenic controller for ion-trap-based
quantum computers.
o The BiCMOS 130nm cryogenic IC demonstrates a control fidelity of 99.97% when driving a single qubit gate on a
9Be+ trapped ion, which is on par with state-of-the-art room temperature controllers.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
APPLICATIONS AND ECONOMIC IMPACT
● Always-on intelligent audio processing at an extremely low power budget facilitates interactions between humans and
electronic devices, advancing the frontier of AI IoT applications.
● Cryogenic controllers for quantum processors break the wiring bottleneck, hindering quantum-computer scaling, thus
enabling the control of the large-scale quantum processors needed for practical applications.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 14 Overview: Compute-In-Memory
Memory Subcommittee
Session Chair: Saekyu Lee, IBM Research, Yorktown Heights, USA
Session Co-Chair: Xueqing Li, Tsinghua University, Beijing, China
Memory access has been a major system-performance and energy-consumption bottleneck for traditional von Neumann system
architectures. Compute-in-memory (CIM) architectures eliminate this bottleneck by integrating compute operations into the memory array,
to reduce memory access latency and data movement overhead. Innovations in CIM design continue to improve energy and area
efficiencies while maintaining overall AI network accuracy. This session includes 7 papers showcasing the latest developments in gain-
cell, SRAM, and non-volatile CIM. Featured innovations include the 1st demonstration of a microscaling data format and STT-MRAM
based Bayesian neural network.
• In Paper 14.1, National Tsing Hua University and TSMC present an STT-MRAM CIM macro for noise-tolerant Bayesian neural networks with a
heterogeneous in- and near-memory MAC structure. The 22nm macro achieves 104.5TOPS/W with a 0.03% accuracy loss for CIFAR-100.
• In Paper 14.2, TSMC and National Tsing Hua University demonstrate the first CIM macro demonstrating the microscaling data format; achieving
133.5TFLPOS/W in a 16nm process.
• In Paper 14.3, Southeast University presents a 28nm floating-point macro with an adaptive-alignment scheme and non-2’s-complement MAC
achieving 62.84TFLOPS/W.
• In Paper 14.4, Tsinghua University presents a CIM macro targeting compound AI models with static/dynamic sparsity-aware acceleration and
post-CIM alignment to reduce error rates. The 28nm macro demonstrates 51.6TFLOPS/W for FP16 operations.
• In Paper 14.5, IME-CAS demonstrates a digital transpose CIM macro for floating-point training and inference; targeting edge-AI applications with
accurate/approximate dual-mode MAC operations. It achieves 48.08TFLOPS/W and 2.34TFLOPS/mm2 for BF16 operations in 28nm CMOS.
• In Paper 14.6, Southeast University presents a hybrid-CIM macro that implements a bit-rotated feature-in scheme for efficient compute allocation
between digital and analog domains. The macro achieves 67.8TOPS/W for INT8 operations in 28nm CMOS.
• In Paper 14.7, Southeast University presents a mimetic-path-searching CIM macro that demonstrates dual-direction searching to achieve a 3670M
nodes/s search rate and a 69.4fJ/node energy consumption.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 14 Highlights: Compute-in-Memory
[14.1] A 22nm 104.5TOPS/W μ-NMC-Δ-IMC Heterogeneous STT-MRAM CIM Macro for
Noise-Tolerant Bayesian Neural Networks
[14.2] A 16nm 216kb, 188.4TOPS/W and 133.5TFLOPS/W Microscaling Multi-Mode Gain-
Cell CIM Macro for Edge-AI Devices
Paper 14.1 Authors: De-Qi You1, Win-San Khwa2, Bo Zhang3, Fang-Yi Chen1, Andrew Lee1, Yu-Cheng Hung1, Yi-Ming Li1, Yu-Hui
Wang1, Chung-Chuan Lo1, Ren-Shuo Liu1, Kea-Tiong Tang1, Chih-Cheng Hsieh1, Yu-Der Chih4, Tsung-Yung Chang4, Meng-Fan
Chang1,2
Paper 14.1 Affiliation: 1National Tsing Hua University, Hsinchu, Taiwan, 2TSMC Corporate Research, Hsinchu, Taiwan, 3TSMC
Corporate Research, San Jose, CA, 4TSMC, Hsinchu, Taiwan
Paper 14.2 Authors: Win-San Khwa1, Ping-Chun Wu2, Jian-Wei Su2,3, Chiao-Yen Cheng2, Jun-Ming Hsu2, Yu-Chen Chen2, Le-Jung
Hsieh2, Jyun-Cheng Bai2, Yu-Sheng Kao2, Tsung-Han Lou2, Ashwin Sanjay Lele4, Jui-Jen Wu1, Jen-Chun Tien2, Chung-Chuan Lo2,
Ren-Shuo Liu2, Chih-Cheng Hsieh2, Kea-Tiong Tang2, Meng-Fan Chang1,2
Paper 14.2 Affiliation: 1TSMC Corporate Research, Hsinchu, Taiwan, 2National Tsing Hua University, Hsinchu, Taiwan, 3Industrial
Technology Research Institute, Hsinchu, Taiwan, 4TSMC Corporate Research, San Jose, CA
Subcommittee Chair: Meng-Fan Chang, National Tsing Hua University (NTHU), Taiwan
CONTEXT AND STATE OF THE ART
● Compute-in-memory has emerged as a power-efficient and area-efficient computing paradigm for neural-network acceleration
and other data-intensive applications for both cloud and edge scenarios.
● The AI-workload evolution requires higher accuracy and data format compatibility using lower area and power. Progress is
hindered by data-format conversion, adder-tree implementation, device and circuit non-idealities, and system-to-macro data
transfers.
● Innovations highlighted in this session enable reliable and high-efficiency computation in non-volatile STT-MRAM and volatile
gain-cell arrays with enhanced accuracy and data-format compatibility.
TECHNICAL HIGHLIGHTS
● NTHU and TSMC introduce an STT-MRAM-based CIM macro capable of performing noise-tolerant Bayesian neural-
network acceleration
o A μN-ΔI-CIM macro based on 22nm STT-MRAM achieves a 104.5TOPS/W power efficiency in BNN-INT8 mode with
a 0.03% accuracy loss for CIFAR-100 tasks.
● TSMC and NTHU present a microscaling integer/floating-point multi-mode gain-cell CIM macro capable of ultra-
power-efficient edge-AI acceleration.
o A 16nm 216kb multi-mode gain-cell CIM macro demonstrates a 133.5TFLOPS/W peak energy efficiency for MXINT8
inputs and MXINT8 weights, and a 91.9TFLOPS/W for BF16 inputs and BF16 weights with FP32 outputs.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
APPLICATIONS AND ECONOMIC IMPACT
● The current commercial-AI hardware implementations are consuming significant amounts of power and silicon area; thus,
making AI-accelerator implementations more efficient is critical for expanding to new application scenarios.
● Compute-in-memory circuits and architectures enable low-power consumption and reduced manufacturing costs, while
preserving computing accuracy and reliability for emerging-AI workloads in various scenarios.
● AI compute-in-memory requirements will boost the development of fundamental volatile and non-volatile memory
technologies.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 15 Overview: Neural Interfaces and Edge
Intelligence for Medical Devices
Imagers, Medical and Displays Subcommittee
Session Chair: Azita Emami, California Institute of Technology, USA
Session Co-Chair: Taekwang Jang, ETH Zurich, Switzerland
Neural recording and decoding circuits continue to improve in terms of precision, robustness, and energy efficiency. The first three papers
present edge-computing SoCs for decoding the neural signals with high efficiency and accuracy. The next paper introduces an SoC with
advanced wireless communication and power telemetry capability. The final three papers describe reconfigurable, noise-efficient and
artifact tolerant neural interface circuits.
• In Paper 15.1, National Taiwan University presents a speech-decoding processor that supports a communication rate of up to 200words/min with
power consumption of 3.9mW.
• In Paper 15.2, Delft University of Technology introduces a spike-sorting chip that processes 1,024-channel neural signals with area and energy
efficiencies of 0.00029mm2/ch and 74nW/ch, respectively.
• In Paper 15.3, University of Notre Dame shows an uncertainty-quantifiable Bayesian convolutional neural network accelerator for ventricular
arrhythmia detection achieving 1.7µJ/inference.
• In Paper 15.4, University of Toronto presents a wireless neuroprosthetic SoC supporting simultaneous wireless power transfer and data link
(200Mb/s Tx, 60Mb/s Rx) with a resonant frequency splitting link. It also introduces an unsupervised adaptive clustering approach with 1.6µW/ch
multi-class spike sorting.
• In Paper 15.5, University of Toronto describes an event-based reconfigurable neural interface IC that offers three modes of 1b inverter-based
spike detector, zoomed active electrode, and high dynamic range interface, for high energy efficiency, high precision, and artifact tolerance,
respectively.
• In Paper 15.6, ETH Zurich introduces a direct-digitization neural front-end proposing delta-amplification, which improves both noise efficiency and
dynamic range, achieving an NEF of 3.47 and an FoMs of 175.2dB.
• In Paper 15.7, Ulsan National Institute of Science and Technology presents an AFE for two-electrode bio-potential recording amplifier with
common-mode interference tolerance of 133V using a common-mode interferer follower.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 15 Highlights: Precision neural and cardiac chips
[15.2] A 1024-Channel 0.00029mm2/ch 74nW/ch Online Spatial Spike-Sorting Chip with
Event-Driven Spike Detection and Self-Organizing Map Clustering
[15.3] A 65nm Uncertainty-Quantifiable Ventricular Arrhythmia Detection Engine with
1.75μJ per Inference
[15.7] A 4.6μW 2.6-NEF Biopotential Amplifier with 133VPP Common-Mode Interference
Tolerance and 102dB Total Common-Mode Rejection Ratio for Two-Electrode
Recording System
Paper 15.2 Authors: Arash Akhoundi1, Yawende Landbrug1, Pumiao Yan2, E. J. Chichilnisky2, Boris Murmann3, Dante Gabriel
Muratore1
Paper 15.2 Affiliation: 1Delft University of Technology, Delft, The Netherlands, 2Stanford University, Stanford, CA, 3University of
Hawaii, Honolulu, HI
Paper 15.3 Authors: Jianbo Liu, Zephan Enciso, Boyang Cheng, Likai Pei, Steven Davis, Yifan Qin, Zhenge Jia, Xiaobo Sharon Hu,
Yiyu Shi, Ningyuan Cao
Paper 15.3 Affiliation: University of Notre Dame, Notre Dame, IN
Paper 15.7 Authors: Yongjae Park1, Yeong-Jin Mo2, Jeong-Hoon Kim3, Gert Cauwenberghs3, Seong-Jin Kim2
Paper 15.7 Affiliation: 1Ulsan National Institute of Science and Technology, Ulsan, Korea, 2Sogang University, Seoul, Korea,
3University of California, San Diego, CA
Subcommittee Chair: Rikky Muller, University of California, Berkeley, CA
CONTEXT AND STATE OF THE ART
● Next-generation brain-computer interfaces require high-density multi-electrode arrays that produce massive amounts of raw
data that must be reduced on-chip to enable wireless operation.
● Although deep-learning methods have improved Ventricular Arrhythmia detection, they suffer from unquantified uncertainties
that limit their reliability in critical medical decisions and impede widespread adoption in trustworthy smart health applications.
● A two-electrode recording IC suffers from large common-mode interferences, potentially saturating an analog front-end (AFE)
or resulting in large common-mode to differential-mode conversion.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
TECHNICAL HIGHLIGHTS
● Delft University introduces a spike-sorting chip with >10 lower power and area and >3 more channels than
previous designs
o A 1024-ch spike sorting chip that achieves 74nW/ch, 0.00029mm2/ch and >87% accuracy by using event-driven
spike detection and spatial features.
● University of Notre Dame presents the first end-to-end uncertainty-quantifiable Bayesian Convolutional Neural
Network accelerator for ventricular arrhythmia detection
o This chip enables fully parallel in-memory analog GRNG and vector-matrix multiplication operations and achieves
100% VA detection accuracy, 1.75μJ/inference energy and 360fJ/sample GRNG.
● Ulsan National Institute of Science and Technology presents an AFE for two-electrode bio-potential recording
systems with very high common-mode interference (CMI) tolerance and common-mode rejection
o The proposed CMI-Follower allows the common-mode input source itself to drive the floating chip ground,
dynamically suppressing the CMI up to 133VPP with a power consumption of 4.6μW.
APPLICATIONS AND ECONOMIC IMPACT
● Energy-efficient and multi-channel spike sorting enables significant data reduction and low-latency close-loop neural interfaces
that have the potential to improve motor and speech decoding devices.
● The proposed detection engine facilitates low-power and uncertainty-quantification-enabled Ventricular Arrhythmia detection,
ensuring reliable performance under out-of-distribution data, hardware imperfections and temperature variations.
● An AFE that suppresses large CMIs and achieves high CMRR and low power is crucial for mobile healthcare applications
where power efficiency and CMI resilience are essential.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 16 Overview: Highlighted Chip Releases:
Digital and Machine Learning Processors
Invited Industry Session
Session Chair: Alicia Klinefelter, NVIDIA, Durham, NC
Session Co-Chair: Vivek De, Intel, Hillsboro, OR
This session highlights recent, productized advancements in digital processors and systems for AI acceleration and high-performance
networking. Key innovations include novel architectures for AI processing, sophisticated memory architectures, and advanced switch
chip designs. The work presented in this session demonstrates significant improvements in AI capabilities, power efficiency, and
scalability across various applications, from mobile devices to data centers. The session provides an overview of current state-of-the-art
hardware solutions addressing the demands of modern computing workloads.
• In Invited Paper 16.1, Broadcom presents Tomahawk5, a switch chip for data centers and AI environments, offering 51.2Tb/s switching capacity.
The chip includes 512 lanes of 106.4Gb/s PAM4 SerDes, supports multiple I/O configurations, has a 168MB shared-buffer architecture, and is
designed as a monolithic die with 9,352 pins and six ARM processor cores, achieving 450W typical power consumption in actual deployments.
• In Invited Paper 16.2, FuriosaAl presents their 5nm inference chip that utilizes parallelism and data locality inherent in tensor contraction, featuring
HBM3 memory, slice redundancy, and a high-bandwidth NoC. It delivers 256TFLOPS/512TOPS for BF16/INT8 with 256MB of on-chip SRAM,
and achieves 12.3 queries/s at 99% accuracy for GPT-J.
• In Invited Paper 16.3, Samsung introduces their Exynos 2400 SoC, used in the Galaxy S24 smartphone. It features a 4nm EUV process and
supports on-device AI with a heterogeneous NPU architecture consisting of vector engines and two types of tensor engines. The 4nm SoC
achieves improved AI performance through better heat dissipation using fan-out wafer level packaging, with the NPU occupying 12mm² and
operating at 0.55 to 0.83V and 533 to 1196MHz.
• In Invited Paper 16.4, SambaNova discusses their SN40L, a Reconfigurable Dataflow Unit for AI applications. It features a three-tier memory
system and dual accelerator dies on a CoWoS-S interposer. Each socket delivers 640 BF16 TFLOPs, and includes 520MB on-chip SRAM. The
SN40L’s architecture enables improved energy efficiency and performance capable of hosting up to 5 trillion parameter models.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 16 Highlights: Highlighted Chip Releases:
Digital and Machine Learning Processors
[16.1] Tomahawk5: 51.2Tb/s 5nm Monolithic Switch Chip for AI/ML Networking
Paper Authors: Asad Khamisy1, Mohan Kalkunte1, Peter Del Vecchio1, Yokai Cheok1, Greg Barsky1, Karlheinz Muth1, Reza Sharifi2
Paper Affiliation: 1Broadcom, San Jose, CA, 2Broadcom, Irvine, CA
CONTEXT AND STATE OF THE ART
Advancements in switch chip technology address the growing demands of data centers and AI applications for higher bandwidth,
lower latency, and improved power efficiency. The innovations in chip design, packaging, and optical integration are key steps
forward in the evolution of high-performance networking infrastructure.
High-speed links in advanced chip designs face significant signal integrity challenges, including isolation issues, insertion loss, and
return loss, which are exacerbated by traditional BGA patterns and ball pitches. Approaches such as custom BGA patterns
and advanced packaging techniques are required.
TECHNICAL HIGHLIGHTS
Broadcom's Tomahawk5 is a 51.2Tb/s Ethernet switch chip featuring 512 lanes of PAM4 SerDes, support for various
connectivity options including co-packaged optics, and innovative power-saving techniques, all implemented in a
monolithic, 5nm die.
Achieves low power consumption through various techniques, including multi-bin Adaptive Voltage Scaling (AVS). It
typically consumes about 450W, representing a 30% power reduction from the previous generation.
Integrates Broadcom's Peregrine SerDes technology, providing native support for multiple physical connectivity options
including direct attach copper (DAC), front panel pluggable optics, linear pluggable optics (LPO), and co-packaged
optics (CPO). This allows data center operators to choose the most cost-effective connectivity solutions.
APPLICATIONS AND ECONOMIC IMPACT
The high bandwidth and advanced features of Tomahawk 5 are specifically designed to handle AI and machine learning traffic
patterns. This allows data centers to more efficiently run these in-demand and compute-intensive workloads.
A single Tomahawk5 chip can replace multiple previous-generation switches, allowing data centers to consolidate equipment. This
reduces networking hardware costs. The increased switching capacity and reduced power also translates to improvements in
energy efficiency and data center cost savings.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 16 Highlights: Highlighted Chip Releases:
Digital and Machine Learning Processors
[16.2] RNGD: A 5nm Tensor Contraction Processor for Power-Efficient Inference on
Large Language Models
Paper Authors: Sang Min Lee1, Hanjoon Kim1, Jeseung Yeon1, Minho Kim1, Changjae Park1, Byeongwook Bae1, Yojung Cha1,
Wooyoung Choe1, Jonguk Choi1, Younggeun Choi1, Ki Jin Han2, Seokha Hwang1, Kiseok Jang1, Jaewoo Jeon1, Hyunmin Jeong1,
Yeonsu Jung1, Hyewon Kim1, Sewon Kim1, Suhyung Kim1, Won Kim1, Yongseung Kim1, Youngsik Kim1, Hyukdong Kwon1, Jeong Ki
Lee1, Juyun Lee1, Kyungjae Lee1, Seokho Lee1, Minwoo Noh1, Junyoung Park1, Jimin Seo1, June Paik1
Paper Affiliation: 1FuriosaAI, Seoul, Korea, 2Dongguk University, Seoul, Korea
CONTEXT AND STATE OF THE ART
As large language models become more prevalent and complex, there's a growing need for specialized hardware that can
efficiently handle these workloads.
With data centers increasingly concerned about energy consumption and sustainability, RNGD addresses the need for high-
performance AI acceleration with significantly lower power requirements.
TECHNICAL HIGHLIGHTS
FuriosaAI presents their RNGD AI accelerator optimized for large language models (LLMs) with superior performance
efficiency compared to GPUs for LLM inference tasks.
Uses tensor contraction as a primitive instead of matrix multiplication, enabling massive parallelism and time-axis
pipelining.
Implements a flexible architecture with Processing Elements (PEs) that can be split into smaller compute units called
slices, allowing for adaptable configurations and efficient data reuse.
Demonstrates superior performance efficiency, with the chip delivering 2.7x better performance per watt than the H100
and 4.1x better than L40s GPUs for LLM inference tasks.
APPLICATIONS AND ECONOMIC IMPACT
LLMs are revolutionizing businesses by enhancing decisions, customer interactions, and industry-wide innovation. As these
models evolve, the demand for specialized AI accelerators is growing to efficiently handle increasingly sophisticated LLM
workloads.
By 2027 AI servers could use between 85 and 134 terawatt hours (TWh) annually. There is an increasing demand for companies
to prioritize electricity consumption in the development of the next generation of AI hardware and software. The significantly
lower power consumption of RNGD could lead to substantial cost savings for data centers.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 16 Highlights: Highlighted Chip Releases:
Digital and Machine Learning Processors
[16.3] An On-Device Generative AI Focused Neural Processing Unit in 4nm Flagship
Mobile SoC with Fan-Out Wafer-Level Package
Paper Authors: Jun-Seok Park, Taehee Lee, Heonsoo Lee, Changsoo Park, Youngsang Cho, Mookyung Kang, Heeseok Lee, Jinwon
Kang, Taeho Jeon, Dongwoo Lee, Yesung Kang, Kyungmok Kum, Geunwon Lee, Hongki Lee, Minkyu Kim, Suknam Kwon, Sung-
beom Park, Dongkeun Kim, Chulmin Jo, HyukJun Chung, Ilryoung Kim , Jongyoul Lee
Paper Affiliation: Samsung Electronics, Hwaseong, Korea
CONTEXT AND STATE OF THE ART
NPUs offer superior energy efficiency compared to both CPUs and GPUs. This makes them particularly valuable for edge
computing environments where power constraints are critical.
FOWLP (Fan-Out Wafer-Level Packaging) significantly improves thermal characteristics, and reduces thermal resistance. This
thermal improvement allows for increased clock frequencies without an increase in power, resulting in better AI performance.
TECHNICAL HIGHLIGHTS
Samsung presents their 4nm Exynos™ 2400 NPU with a heterogeneous architecture, supporting
various neural networks and increasing the maximum clock frequency by 30% while
consuming the same power due to FOWLP.
Uses a heterogeneous NPU architecture with vector engines and two types of tensor engines (8K and 512 MACs). It
supports diverse neural networks, including memory-intensive LLMs and compute-intensive LVMs.
Has memory hierarchy with Q-caches and prefetching maximizes data reuse and reduces latency, particularly effective
for CNNs.
Implements a skewness curve-based tiling method that optimizes matrix/tensor tiling for maximum data reuse within
memory constraints.
APPLICATIONS AND ECONOMIC IMPACT
The semiconductor market is projected to reach around $400 billion by 2030, with AI semiconductors expected to make up over
30% of this market. Traditional CPUs struggle to handle AI workloads, while GPUs are large, expensive, and energy-intensive.
This has led to the development of NPUs as a more specialized and efficient solution for AI processing.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 16 Highlights: Highlighted Chip Releases:
Digital and Machine Learning Processors
[16.4] SambaNova SN40L: A 5nm 2.5D Dataflow Accelerator With Three Memory Tiers
for Trillion Parameter AI
Paper Authors: Raghu Prabhakar, Junwei Zhou, Darshan Gandhi, Youngmoon Choi, Mahmood Khayatzadeh, Kyunglok Kim, Uma
Durairajan, Jeongha Park, Satyajit Sarkar, Jinuk Luke Shin
Paper Affiliation: SambaNova Systems, Palo Alto, CA
CONTEXT AND STATE OF THE ART
LLMs and other AI models have been growing exponentially in size, requiring more computational power and memory capacity. As
these AI models become larger and more complex, there's a growing need for more energy-efficient hardware solutions.
Modern AI applications often require the ability to run multiple models or switch between models quickly, necessitating flexible
hardware architectures.
TECHNICAL HIGHLIGHTS
SambaNova presents the SN40L, a 5nm AI accelerator with a flexible on-chip dataflow architecture offering high
performance and energy efficiency for modern AI training and inference applications.
Utilizes a dual-die design with 102 billion transistors per socket, delivering 640 BF16 TFLOPs and 520 MB on-chip
SRAMs.
Implements a three-tier memory hierarchy with on-chip SRAM, on-package High Bandwidth Memory (HBM), and off-
package DRAM, enabling efficient handling of large AI models.
Includes a Power Estimation Unit (PEU) that dynamically adjusts operating conditions within microseconds, optimizing
performance while staying within power limits.
Can host up to 5 trillion parameter models in an 8-socket system.
APPLICATIONS AND ECONOMIC IMPACT
LLMs with a higher number of parameters can capture more intricate patterns and nuances in data, leading to improved
performance. Additionally, as AI applications evolve, the demand for larger models will grow. Accelerators that support many
parameters enable improved performance, scalability, and future-proofing.
AI accelerators that dynamically adjust operating conditions to optimize performance under varying workload demands are crucial
for managing the computational requirements of different phases in LLM processing, such as the compute-intensive prompt
phase and the lighter generation phase.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 17 Overview: Hardware Security
Security Subcommittee
Session Chair: Takeshi Sugawara, University of Electro-Communications, Tokyo, Japan
Session Co-Chair: Leibo Liu, Tsinghua University, Beijing, China
The session covers hardware security solutions across design hierarchies, from processor architectures to circuits. The first paper
introduces a sensor for detecting side-channel eavesdropping attacks using the silicon debug tool, the laser voltage prober. The next two
papers present processor architectures designed to accelerate fully homomorphic encryption (FHE) and FHE-based cryptographic
schemes. These are followed by two papers that discuss physically-unclonable-function (PUF) circuits with extremely low error rates.
The final paper highlights a clock generator designed to detect fault injection attacks.
● In Paper 17.1, National University of Singapore demonstrates on-chip detection for laser voltage probing attacks without using an explicit sensor
through transistor leakage shifted by a laser. The proposed detection principle, implemented in a 28nm process, exhibits an overhead of
approximately 0% in power, 1.23% in performance, and 4.35% in area.
● In Paper 17.2, Tsinghua University describes a reconfigurable multi-scheme processor for FHE, enabling energy-efficient execution of the BGV,
BFV and CKKS schemes. The processor, fabricated as a 5.4mm2 chip using a 28nm process, achieves 4.05μJ/encryption at 0.7V for client-side
operations and 20.92kHMul/s at 1.0V for server-side evaluations.
● In Paper 17.3, National Taiwan University introduces a processor for secure multi-party computation using the multi-key (MK) CKKS scheme. The
chip, fabricated using a 40nm process, reaches a maximum throughput of 6.72GOPS with 221mW power consumption at 210MHz from a 1.3V
supply.
● In Paper 17.4, Samsung describes a PUF circuit, implemented in both 3nm GAA and 8nm FinFet technologies. A Vth tilting technique for screening
of unstable selections is utilized to achieve a key error rate (KER) below 5.5E-20.
● In Paper 17.5, University of Ulm presents an eye-opening arbiter (EOA) PUF circuit, implemented in 28nm technology featuring an auto-error
detection, which achieves a bit-error rate of 2E-8 over aging, temperature and supply voltage variation.
● In Paper 17.6, Nvidia presents a compact self-calibrating RC oscillator for detecting clock attacks. The proposed 0-trim self- calibrating oscillator
in 3nm FinFET technology, provides a stable 100MHz clock with 11.6ps period jitter and frequency error of ±0.26%.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 17 Highlights: Hardware Security
[17.1] Sensor-Less Laser Voltage Probing Attack Detection via Run-Time Leakage Shift
Monitoring with 4.35% Area Overhead
[17.2] A 28nm 4.05
J/Encryption 8.72kHMul/s Reconfigurable Multi-Scheme Fully
Homomorphic Encryption Processor for Encrypted Client-Server Computing
Paper 17.1 Authors: Hui Zhang1, Longyang Lin2, Dingyi Xiong1, Massimo Bruno Alioto1
Paper 17.1 Affiliation: 1National University of Singapore, Singapore, Singapore, 2Southern University of Science and Technology,
Shenzhen, China
Paper 17.2 Authors: Sijia Lu1, Wenping Zhu1, Bohan Yang1, Jiajun Yang1, Tongwei Dai1, Chen Chen1, Xiangdong Han1, Jinjiang
Yang2, Hanning Wang1, Min Zhu3, Shaojun Wei1, Aoyang Zhang1, Leibo Liu1
Paper 17.2 Affiliation: 1Tsinghua University, Beijing, China, 2Wuxi Research Institute of Applied Technologies, Tsinghua University,
Wuxi, China, 3Wuxi Micro Innovation Integrated Circuit Design Company Ltd., Wuxi, China
Subcommittee Chair: Ingrid Verbauwhede, KU Leuven, Leuven, Belgium, Security
CONTEXT AND STATE OF THE ART
● Resource-constrained embedded systems are vulnerable to sophisticated physical attacks such as laser voltage probing and
require the development of low-overhead on-chip solutions for attack detection and mitigation.
● Fully homomorphic encryption (FHE) provides a cryptographic framework for privacy-preserving computation, but its compute
and memory bottlenecks necessitate the design of efficient and flexible hardware accelerators.
TECHNICAL HIGHLIGHTS
● National University of Singapore introduces an on-chip sensor-less laser voltage probing attack detector circuit in
28nm CMOS achieving significantly reduced power and area overhead compared to state-of-the-art.
o Leakage shifts in sleep transistors in the presence of a laser are used for attack detection, while preserving standard-
cell design and achieving low overhead of approximately 0% in power, 1.23% in performance and 4.35% in area.
● Tsinghua University introduces a multi-scheme FHE processor in 28nm CMOS for client-side encryption / decryption
and server-side encrypted computation with improved energy efficiency compared to state-of-the-art.
o A reconfigurable array of processing elements is used for execution of BGV, BFV and CKKS levelled FHE schemes,
achieving 4.05J/encryption for client-side operations and 20.92kHMul/s for server-side evaluations.
APPLICATIONS AND ECONOMIC IMPACT
● Advanced circuit techniques for low-cost on-chip laser voltage probing attack detection without the use of explicit sensors
enable low-power solutions for improved resilience against sophisticated physical attacks.
● Energy-efficient hardware acceleration of multiple FHE schemes enables computation on encrypted data, e.g., machine-
learning tasks, suitable for privacy-sensitive applications such as big data, finance and healthcare.
● Hardware security innovations are demonstrated across design hierarchies through circuit and architecture optimizations.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 18 Overview:
Noise-Shaping and SAR-Based ADCs
Data Converter Subcommittee
Session Chair: Xiyuan Tang, Peking University, Beijing, China
Session Co-Chair: Pieter Harpe, Eindhoven University of Technology, Eindhoven, The Netherlands
Session Chair: Ying-Zu Lin*, Mediatek, Hsinchu, Taiwan
This session presents eight ADCs where noise-shaping techniques and SAR/Pipe-SAR structures are well exploited. These papers are
sorted in ascending order of speed. With <1MHz bandwidth, the first 4 ADCs achieve over 90dB SNDR with more than 180dB Schreier
FoM (FoMS). Ranging from 2.5 to 80MHz bandwidth, the following 3 ADCs have FoMs >170dB. The last paper is a cryo-CMOS CI-SAR
ADC with a 4fF input capacitance.
• In Paper 18.1, UESTC presents a fully dynamic NS-SAR ADC achieving 120.6dB SNDR and 132.5dB SFDR in 1kHz BW, resulting in 189.2dB
FoMS. The performance is enabled by predict and skip, hybrid mismatch shaping, system-level chopping, and FIA.
• In Paper 18.2, Peking University introduces a Gain-Embedded Bootstrapped Sampler input stage adopted in zoom pseudo-pseudo-differential
ADC. This ADC achieves 99.6dB SNDR over 4kHz bandwidth and a FoMS of 184.8dB.
• In Paper 18.3, Peking University proposes a calibration-free pipelined-SAR ADC with cross-stage gain-mismatch error shaping. Inherently
preserving residue voltage for noise-shaping, the prototype achieves 180.4dB FoMS.
• In Paper 18.4, Peking University presents an incremental noise-shaping pipeline ADC with single amplification based kT/C noise cancellation.
This ADC realizes an SNDR of 92.5dB at 1.6MS/s and 467.3uW power, leading to an FoMS of 184.8dB.
• In Paper 18.5, Peking University introduces a 3rd-order noise-shaping SAR ADC with a continuous-time correlated level-shifting embedded ADC
driver. This ADC achieves 82.9dB SNDR at 40MS/s, with an FoMS of 176.3dB.
• In Paper 18.6, Peking University shows an easy-drive 16MS/s pipelined-SAR ADC with a split coarse-fine input buffer sampling scheme. This
ADC achieves 79.4dB SNDR and an FoMS of 176.3dB.
• In Paper 18.7, Tsinghua University presents a filter-embedded pipe-SAR ADC with a progressive conversion scheme and a dynamic floating-
charge transferrer. This ADC achieves 70.1dB over 80MHz BW with 172.2dB FoMS; it provides >30dB out-of-band suppression.
• In Paper 18.8, KU Leuven reveals a 7b cryo-CMOS charge-injection SAR ADC with a low input capacitance of 4fF. It achieves an SNDR of 40.7dB
at a temperature of 6.5K while consuming 2.89mW at a sampling rate of 800MS/s.
*1981-2024
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 18 Highlights:
Noise-Shaping and SAR-Based ADCs
[18.3] A 93.3dB SNDR, 180.4dB FoMS Calibration-Free Noise-Shaping Pipelined-SAR
ADC with Cross-Stage Gain-Mismatch Error-Shaping Technique and Negative-R-
Assisted Residue Integrator
[18.7] A 70dB-SNDR 80MHz-BW Filter-Embedded Pipe-SAR ADC Achieving 172dB FoMS
with Progressive Conversion and Floating Charge-Transfer Amplifier
Paper 18.3 Authors: Jihang Gao, Yaohui Luan, Siyuan Ye, Xinhang Xu, Zhuoyi Chen, Jiajia Cui, Ru Huang, Linxiao Shen
Paper 18.3 Affiliation: Peking University, Beijing, China
Paper 18.7 Authors: Siyu Huang, Zhishuai Zhang, Xiyu He, Mingyang Gu, Yunsong Tao, Yi Zhong, Nan Sun, Lu Jie
Paper 18.7 Affiliation: Tsinghua University, Beijing, China
Subcommittee Chair: Jan Westra, Broadcom, Bunnik, The Netherlands, Data Converters
CONTEXT AND STATE OF THE ART
● Non-idealities such as gain error, DAC mismatch, and clocking skew pose a limit to prevent ADCs from achieving high
linearity. On the other hand, thermal and kT/C noise induce a tradeoff between SNR and power/area.
● High-precision ADCs usually require complicated architecture and circuit techniques to enhance SNR and linearity. The
consequent overhead is various foreground/background calibrations.
● With the advancement of ADC systems, the peripheral circuits including filters and buffers, become increasingly important for
overall system performance/cost.
TECHNICAL HIGHLIGHTS
● Peking University introduces a calibration-free pipeline-SAR ADC with hardware-efficient cross-stage gain-mismatch
error shaping.
o The calibration-free prototype achieves 93.3dB SNDR, 180.4dB SNDR FoMS, which is the highest among previous
calibration-free ADCs with gain/mismatch error suppression techniques. It also has the largest gain-error tolerance
range.
● Tsinghua University presents a filter-embedded pipeline-SAR ADC with progressive conversion and floating charge-
transfer amplifier.
o The progressive conversion mitigates the speed penalty of the filtering operation, and a dynamic floating charge
transfer realizes high-speed, high-efficiency residue amplification. It realizes 70.1dB SNDR over 80MHz BW, and
provides >30dB out-of-band suppression for full-scale blockers.
APPLICATIONS AND ECONOMIC IMPACT
● Hardware/time-efficient calibration or calibration-free high-precision noise-shaping ADCs will be attractive for industry mass
production.
● kT/C noise poses a fundamental limitation to high SNR design. kT/C cancellation not only decreases the power consumption
of the ADC, but also the reduced input capacitance is power friendly to its input driver.
● ADCs with embedded filtering capability can ease system integration, making them suitable for compact, cost-sensitive
industries such as consumer electronics and IoT.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 19 Overview:
Frequency Synthesizers and Series-Resonance VCOs
RF Subcommittee
Session Chair: Dmytro Cherniak, Infineon Technologies, Austria
Session Co-Chair: Wei Deng, Tsinghua University, Beijing, China
Frequency synthesizers are essential components of any wireless communication systems and modern SerDes applications. The session
features elven papers on ultra-low-noise fractional-N PLLs, LO systems, and series-resonance VCOs. The final paper presents a PLL
with 15.8fs jitter.
• In Paper 19.1, the University of Macau presents a 28nm-CMOS 5.5GHz fractional-N cascaded RO-based digital PLL with voltage-domain
feedforward noise cancellation achieving a 290.8fs jitter with <10% variation over PVT.
• In Paper 19.2, the University of Tokyo presents a fractional-N cascaded PLL that uses two MMDs with a shared DSM for quantization noise
cancellation. The PLL, implemented in 65nm CMOS, achieves 96fsrms jitter, a -70.6dBc worst-case fractional spur, and a -247.1dB FoM near
5.2GHz.
• In Paper 19.3, MediaTek presents a 9.5GHz fractional-N PLL with a multipath feedback technique and implemented in 22nm CMOS. The PLL
demonstrates 34fs jitter, -64.8dBc fractional spur, and -255.5dB FoM.
• In Paper 19.4, University College Dublin presents an 8.1-to-9.9GHz single-core oscillator, which employs pseudo-series-resonance topology. This
oscillator, implemented in 28nm CMOS, achieves -128dBc/Hz phase noise at a 1MHz offset.
• In Paper 19.5, the South China University of Technology presents a 7.7-to-9.1GHz differential series-resonance CMOS VCO with a pole-
convergence technique. The VCO achieves -152.9dBc/Hz phase noise at a 10MHz offset when implemented in 65nm CMOS.
• In Paper 19.6, KAIST describes a fast-hopping LO that uses an SSB-mixer-based structure. Implemented in 28nm CMOS, the LO achieves sub-
nanosecond settling, −56dBc worst-case spur, and 60.3fs rms jitter.
• In Paper 19.7, the University of Macau shows a 27GHz fractional-N subsampling PLL achieving 57.9fsrms jitter, -249.7dB FoM, and 1.98μs locking
time in a 28nm CMOS technology.
• In Paper 19.8, the Chinese Academy of Sciences presents a 0.65V 10.4-to-11.8GHz low-voltage low-jitter fractional-N sampling PLL that uses a
hybrid cascaded digital pre-distortion technique, low-jitter low-voltage digital-to-time converter, and low-voltage sampling phase detector.
• In Paper 19.9, Tsinghua University describes a FMCW PLL with an overlap-snapshot posterior-segmentation DPD technique and a cycle-slipping-
immune TDC for ultra-high-slope chirp generation. It achieves 0.043% rms frequency error under 3.4GHz/μs slope and 5.32GHz bandwidth. The
proposed DPD converges within 5 chirp cycles.
• In Paper 19.10, ETH Zürich proposes a PLL-XO co-design where XO provides a clean reference to the PLL and PLL provides the precise injection
timing with a narrow angle for the pulse XO driver. The proposed design achieves -255.2dB FoMJ including all the power and noise of the frequency
synthesis chain.
• In Paper 19.11, Xidian University shows a 13GHz charge-pump PLL with a low-noise resistive-discharge time-amplifying phase-frequency detector
and a series-resonance voltage-controlled oscillator achieving 15.8fs jitter and a -98.5dBc reference spur.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 19 Highlights:
Frequency Synthesizers and Series-Resonance VCOs
[19.2] A 96fsrms-Jitter, -70.6dBc-Fractional-Spur Cascaded PLL Employing Two MMDs
with Shared DSM for Quantization Noise Cancellation
[19.4] An 8.1-to-9.9GHz Single-Core Pseudo-Series-Resonance Oscillator Achieving -
128.7dBc/Hz PN at 1MHz
[19.10] A 4.6GHz 63.3fsrms PLL-XO Co-Design Using a Self-Aligned Pulse-Injection
Driver Achieving -255.2dB FoMJ Including the XO Power and Noise
Paper 19.2 Authors: Haoming Zhang, Yuyang Zhu, Masaru Osada, Tetsuya Iizuka
Paper 19.2 Affiliation: University of Tokyo, Tokyo, Japan
Paper 19.4 Authors: Jiawen Chen1, Kai Xu2, Teerachot Siriburanon1, Robert Bogdan Staszewski1
Paper 19.4 Affiliation: 1University College Dublin, Dublin, Ireland, 2King's College London, London, United Kingdom
Paper 19.10 Authors: Can Livanelioglu, Long He, Jiang Gong, Sina Arjmandpour, Taekwang Jang
Paper 19.10 Affiliation: ETH Zürich, Zurich, Switzerland
Subcommittee Chair: Brian Ginsburg, Texas Instruments, Dallas, TX, RF Subcommittee
CONTEXT AND STATE OF THE ART
● Low-phase-noise PLLs are essential for new high-bandwidth wireless communication standards.
● Cascading PLL architecture demonstrates outstanding jitter and spurious performance.
● A new series-resonance VCO topology stands out as a viable way to further reduce the phase noise required for future 6G
wireless communication.
TECHNICAL HIGHLIGHTS
● The University of Tokyo presents a 5.7GHz fractional-N cascaded PLL employing two MMDs with shared DSM for
quantization noise cancellation
o A cascaded fractional-N PLL achieves 96fsrms-Jitter, –70.6dBc fractional spur, and -247.1dB FoM.
● University College Dublin presents an 8.1-to-9.9GHz single-core oscillator with pseudo-series-resonance topology.
o An oscillator achieves -128dBc/Hz phase noise at a 1MHz offset and 189.8-to-191.4dBc/Hz FoM at 1MHz.
● UTH Zunich presents a PLL-XO co-design where XO provides a clean reference to the PLL and PLL provides the
precise injection timing with a narrow angle for the pulse XO driver.
o The PLL achieves 63fs jitter and -255dB FoM with 2.25mW power consumption.
APPLICATIONS AND ECONOMIC IMPACT
● Advanced low-phase-noise PLLs are required for high-bandwidth wireless communication.
● Digital techniques can be applied to reduce calibration time and overall system cost.
● Lower power consumption while preserving performance enables the integration in battery-powered devices.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 20 Overview:
Sensors and Actuators for Health and Autonomy
Technology Directions Subcommittee
Session Chair: Milin Zhang, Tsinghua University, China
Session Co-Chair: Kyeongha Kwon, KAIST, Korea
Sensing and actuation technologies are becoming specialized and diverse, with a focus on multi-modality, miniaturization and power
efficiency for innovative applications. The session begins with gas sensing technologies, featuring a multi-modal gas sensor chip
and a nose-on-a-chip with on-chip learning for non-invasive disease diagnosis. The next paper presents a novel RFID-inspired bio-
analyzer for point-of-care diagnostics, followed by a MEMS-free e-nose sensor array. This session then explores biochemical
diagnostic solutions and autonomous/adaptive systems, featuring a wireless electrochemical sensing SoC, a self-propelling
microrobot with sub-GHz energy harvesting, a biochemical chip with precise temperature control, a battery-free silicon platform for
adaptive sensing, and an autonomous microactuator system with flying solid-state batteries. A BodyID system featuring a clockless
wake-up receiver and a γ photon spectrometer for precision cancer resection round out the session.
• In Paper 20.1, Osaka University demonstrates a 16-channel multi-modal gas sensor employing membrane-based stress sensors integrated
with readout electronics. The system is demonstrated to measure the concentrations of multiple gasses, while maintaining state-of-the-art
sensitivity, sample rate, and power consumption.
• In Paper 20.2, Tsinghua University presents an E-nose system with on-chip incremental learning for non-invasive diagnosis of diseases. The
chip consumes 67μW/Channel and obtains a 98% accuracy for 10-class gas recognition with one-shot learning.
• In Paper 20.3, University of California at Berkeley, presents a fully wireless CMOS/microfluidics bioanalyzer for point-of-care use. It integrates
amperometric, pH, and temperature sensors, which, combined with PDMS vacuum-actuated microfluidics, enables immunoassays to be
demonstrated.
• In Paper 20.4, ETH Zurich demonstrates an E-nose with 4096 capacitance-gas interfacing pixels with sigma-delta ADCs and in-pixel heaters
for thermodynamic modulation and reusability. Metal-Organic Framework (MOF) materials, provide selectivity and achieve a LoD of 5 ppm.
• In Paper 20.5, Tsinghua University presents a 4.3×4.1×4 mm3 16-channel wireless electrochemical sensor with integrated thin-film Organic
Electrochemical Transistor, for 0.1pM LoD. Ultrasonic power and communications employ an active rectifier and backscatter OOK
modulation.
• In Paper 20.6, Shanghai Jiao Tong University presents a self-propelling microrobot that moves through ionic fluids at mm/s. It employs on-
chip traveling wave electroosmosis pump for actuation and a sub-GHz parity-time symmetry energy harvesting method for enhanced energy
transfer efficiency during movement.
• In Paper 20.7, ADI demonstrates a ASIC comprising 384 thermally-isolated sites with individual temperature control. Each site can be
controlled with +/- 0.12°C precision enabling double-strand DNA purification via selective melting.
• In Paper 20.8, University of Macau proposes a distributed, adaptive, and event-driven sensing framework. A battery-less chip compresses
the sensor data to reduce the wireless transmission payload, limiting the power to 94.8nW.
• In Paper 20.9, University of California, San Diego and CEA-Léti presents a high-voltage microactuator drive system without extra passive
components. It generates up to 56.1V output enabling over 50 hours continuously working at 20Hz with a total weight of 1.8g.
• In Paper 20.10, University of California at Berkeley presents a 200GHz 200-pixel 2-D near-field imager employing active split-ring resonators
(ASRRs) with Q-boosting for biomedical applications. The system achieves 46µm×54µm pixel dimensions and demonstrates tissue imaging
with 27dB pixel-to-pixel isolation.
• In Paper 20.11, Purdue University demonstrates an asynchronous, ultra-low-power wake-up receiver and a crystal-less clock recovery circuit
designed for on-body communication. The reported system achieves a startup time of less than 80µs while consuming under 425.2nW.
• In Paper 20.12, University of California at Berkeley demonstrates a configurable Gamma-photon spectrometer for precision radio guided
cancer resection. The system measures the voltage decay on a small reverse biased diode to resolve the energy with sub-keV resolution
and 1.315 MeV dynamic range.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 20 Highlights:
Sensors and Actuators for Health and Autonomy
[20.3] An RFID-inspired One-step Packaged Multi-mode Bio-analyzer with Vacuum
Microfluidics for Point-of-Care Diagnostics
[20.7] A 384-site chip platform for biochemical applications with individual site
precision temperature control
Paper 20.3 Authors: Yan-Ting Hsiao, Ya-Chen Tsai, Wei Foo, Hung-Yu Hou, Yun-Chun Su, Yueting Lily Li, Jun-Chau Chien
Paper 20.3 Affiliation: University of California at Berkeley, Berkeley, CA, National Taiwan University, Taipei City, Taiwan
Paper 20.7 Authors: Michael Coln, Qingdong Meng, Viorel Bucur, Ramji Lakshmanan, Aditya Yadav, David Lloyd, Nicol Ferri, Mark
Bignell, Daniele Di Nuzzo, Phillip Nadeau, Matthew Hayes, Roman Trogan
Paper 20.7 Affiliation: Analog Devices, Boston, MA, Analog Devices, Limerick, Ireland, Analog Devices, San Jose, CA, Evonetix, Ltd,
Cambridge, United Kingdom
Subcommittee Chair: Ali Hajimiri, California Institute of Technology, Pasadena, CA, Technology Directions
CONTEXT AND STATE OF THE ART
● Integrating millimeter-sized CMOS integrated circuits with microfluidics presents a promising solution for multiplexed bio-
marker detection with low cost and reduced size.
● The integration of microfluidics for more advanced functions presents a significant challenge in terms of packaging and cost.
● Effective thermal isolation, localized heat delivery, and precise local temperature sensing are key to efficient temperature
control with multiple independent channels.
TECHNICAL HIGHLIGHTS
● University of California at Berkeley introduces a near-field inductively powered CMOS bio-analyzer that seamlessly
integrates with PDMS microfluidics, eliminating the need for electrical connections.
o The utilization of naturally-formed Al2O3 oxide as a pH sensing membrane eliminates the need for any post-CMOS
processing.
● Analog Devices demonstrates a chip platform with thermally controlled biochemistry
o The integration of post-processed heated reaction sites on an ASIC enables the individual programming of 384 sites
within the temperature range of 25-125°C, while maintaining minimal thermal crosstalk (< +/- 0.12°C).
APPLICATIONS AND ECONOMIC IMPACT
● Millimeter-sized bioanalyzer for molecular diagnostics enables point-of-care (POC) detection directly at or near the patient’s
location.
● Temperature control with greater throughput enables precise thermally-controlled for biochemical applications.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 21 Overview: Compute & USB Power
Power Management Subcommittee
Session Chair: John Pigott, NXP Semiconductors, Chandler, Arizona, USA
Session Co-Chair: Rinkle Jain, Nvidia, Portland Oregon, USA
The overarching theme of this session is design innovation in power converter topologies and control yielding simple and robust circuits
that broadly achieves the following: 1) inherently reducing passive needs; 2) effective volume utilization of existing passives through
continuous conduction; and 3) auto current and voltage balancing across the many phases or passives within.
The session has excellent representation of innovations in the compute and USB area from both industry as well as university researchers
spanning from basic buck converters to hybrid yet inductive converters as well as a resonant SC converter and a digital LDO.
Overall, we have five papers covering 12V to 1V converters with currents over 4.5A.
• In Paper 21.1 from Zhejiang University, Hangzhou, China describes a 12-to-1V two-stage converter with regulated resonant switched-capacitor
regulators using 65nm CMOS and reaching 89.3% efficiency.
• In Paper 21.2 from Samsung Electronics, Hwaseong, Korea introduces a dual-input bidirectional 3-Level battery charger with VCF balancing and
a wide input from 4.65 to 12 V for mobile applications using 130nm BCD and reaching 96.8% efficiency.
• In Paper 21.3 from University of Macau covers a Multi-Phase Hybrid Converter with Inherently Auto-Balanced ILs using a 180nm BCD process
which reaches 92.9% efficiency and can deliver 6A.
• In Paper 21.4 from Korea University, Seoul, Korea covers a half-inductor-current hybrid bidirectional converter performing USB to 2-cell
bidirectional power transfer reaching 97.4% efficiency using a 180nm technology and only requiring 5V transistors.
• In Paper 21.5 from Intel, Santa Clara, California, USA presents a 60MHz integrated multi-phase regulator which features an autonomous mode
transition from hard-switching to soft-switching to discontinuous conduction mode using a 3nm FinFET technology.
• In Paper 21.6 from Sogang University, Seoul, Korea describes a 2A analog distribution LDO for a SoC in a 28nm technology with excellent noise
immunity in an SoC application.
• In Paper 21.7, researchers from University of California San Diego, California, USA describe a merged hybrid and multi-phase implementation of
a 6-phase triple-step-down DC-DC converter which can reach 91% efficiency and deliver 7A using a 180nm process at a current density of
868A/cm³.
• In Paper 21.8 from University of Macau, Macao, China presents a scalable hybrid DC-DC converter with a power ring for current balance and a
back ring for phase shedding, named as ‘HOOP’. Implemented in 180nm BCD, this converter can reach 90.2% efficiency and deliver up to 16A.
• In Paper 21.9, from University of Macau, Macao, China presents a 20MHz & 1MHz dual-loop multi-inductor hybrid DC-DC converter with non-
uniform current allocating optimizing both up and down transient performance as low as 6.3% using a 180nm BCD technology.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 21 Highlights: Compute & USB Power
[21.9] A 20MHz & 1MHz Dual-Loop Non-Uniform-Multi-Inductor Hybrid DC-DC Converter
with Specified Inductor Current Allocation and Fast Transient Response
Paper 21.9 Authors: Junwei Huang1, Xiangyu Mao1, Zhiguo Tong1, Zhewen Yu1, Wenjie Yang1, Chi-Seng Lam1, Rui P. Martins1, Yan
Lu1, 2
Paper 21.9 Affiliation: 1University of Macau, Macao, China, 2Tsinghua University, Beijing, China
Subcommittee Chair: John Pigott, NXP Semiconductors, Chandler, Arizona, USA
CONTEXT AND STATE OF THE ART
● Efficient high-performance power conversion to supply modern loads from a 12V source is critical to enable high-end
computing. Higher efficiency and fast transient response reduces volumes and costs. These features are critical for all
compute loads, including servers, portable computers, and automotive applications.
● Innovations in DC-DC architectures, including novel hybrid topologies with hybrid power delivery and multiple regulation loops
continue to advance the state-of-the-art in this field.
TECHNICAL HIGHLIGHTS
● The University of Macau introduces a 20MHz & 1MHz dual-loop non-uniform-multi-inductor hybrid DC-DC converter
with specified inductor current allocation and fast transient response.
o Two hybrid power stages combine to deliver 4.5A by controlling the allocation of power from each stage. While a
1MHz stage delivers most of the power, a 20MHz stage performs load regulation and controls fast transient response
using optimized core devices with a 180nm technology.
APPLICATIONS AND ECONOMIC IMPACT
● Automotive, server and portable compute applications continue to require high quality power delivery at high efficiency and
low volume.
● Hybrid converter topologies allow partitioning of the regulation amongst separate circuits optimized for efficiency and for fast
transient response, while combining and controlling the outputs effectively.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 22 Overview: Memory Interface
Memory Subcommittee
Session Chair: Dongkyun Kim, SK Hynix, Korea
Session Co-Chair: Hidehiro Shiga, KIOXIA, Japan
SK hynix and Seoul National University present PAM3 GDDR7 interfaces that can achieve 42Gb/s: SK hynix describes a DFE which
provides feedback within 1UI, and Seoul National University describes a clock-referred transceiver technology. Hanyang University and
Korea University introduce PAM4 interfaces: Hanyang University introduces a 32-50Gb/s transmitter that includes a ZQ-based FFE, and
Korea University introduces a 32Gb/s single-ended receiver that includes a capacitive-feedback equalizer. In addition, Seoul National
University presents a low-power and low-jitter quadrature-clock generator for high-bandwidth HBMs.
• In Paper 22.1, Seoul National University (SNU) presents a low-power (0.275pJ/b) high-speed (42Gb/s/pin) single-ended PAM3 transceiver that
achieves <10-12 BER with 200mVPP injected feed noise.
• In Paper 22.2, Seoul National University introduces a 850μW injection-locked quadrature-clock generator, with 2 - 5GHz jitter filtering and instant
toggling for HBM interfaces.
• In Paper 22.3, SK Hynix presents a 42Gb/s single-ended PAM-3 receiver with a DFE that combines a direct-feedback and loop-unrolled DFE to
minimize area and power overhead for GDDR7 memory interfaces.
• In Paper 22.4, Hanyang University presents a 32 - 50Gb/s/pin single-ended PAM-4 transmitter using a ZQ-based FFE and PAM-4 LSB DBI-DC
encoding.
• In Paper 22.5, Korea University introduces a 32Gb/s/pin single-ended PAM-4 receiver with a delay-less capacitive-feedback equalizer (CFE)
achieving a low-power, 0.3pJ/b, consumption in a 28nm CMOS technology.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 22 Highlights: Memory Interface
[22.1] A 0.275pJ/b 42Gb/s/pin Clock-Referenced PAM-3 Supply-Noise-, Reference-
Offset- and Cross-Talk-Tolerant Transceiver for Chiplets and Short-Reach Memory
Interfaces
[22.2] An 850μW 2-to-5GHz Jitter-Filtering and Instant-Toggling Injection-Locked
Quadrature-Clock Generator for Low-Power Clock Distribution in HBM Interfaces
Paper 22.1 Authors: Kahyun Kim1 , Jung-Hun Park2, Ha-Jung Park1, Jia Park1, Jihee Kim1, Woo-Seok Choi1
Paper 22.1 Affiliation: 1Seoul National University, Seoul, Korea, 2University of California at Berkeley, California, USA
Paper 22.2 Authors: Jeongbeom Seo*1, Yoonseo Cho*1,2, Yuhwan Shin1,2, Jaehyouk Choi1
Paper 22.2 Affiliation: 1Seoul National University, Seoul, Korea, 2Korea Advanced Institute of Science and Technology, Daejeon,
Korea
Subcommittee Chair: Dongkyun Kim, SK Hynix, Korea, Hidehiro Shiga, KIOXIA, Japan
CONTEXT AND STATE OF THE ART
● A high-speed and low-power single-ended PAM3 transceiver that uses a differentially-weighted driver and a combined-
sampler DFE to reduce power consumption, and a far-end-reflection (FEXT) cancelation scheme with an FS-puller.
● Injection-locked quadrature-clock generator for low-power and low-jitter clock distribution for HBM interfaces.
TECHNICAL HIGHLIGHTS
● Seoul National University (SNU) presents a low-power (0.275pJ/b) high-speed (42Gb/s/pin) single-ended PAM3
transceiver that achieves <10-12 BER with 200mVPP injected feed noise.
o Forwarded clocks act as reference voltages for supply-noise and reference-offset tolerance. A differentially-
weighted-PAM3 driver and combined-sampler DFE are used to improve power-efficiency, while a XTC-combined FS
puller cancels FEXT.
● Seoul National University (SNU) demostrate a 850μW injection-locked quadrature-clock generator (IL-QCG), with 2 -
5GHz jitter filtering and instant toggling for HBM interfaces.
o IL-QCG has the ability to toggle the output clock instantly, without requiring a continuous clock. It suppresses input-
clock jitter, reducing it from 3.02 to 1.31psRMS, and achieves a PSIJ from 5.80 to 1.73psRMS.
APPLICATIONS AND ECONOMIC IMPACT
● Developing DRAM interface technology is an important technology that can satisfy the high-bandwidth and high-energy
efficiency required by AI computing
● In PAM3, the fastest scheme among DRAM interfaces, improvements such as PSIJ, offset, and cross-talk noise in output
circuits can be a major technology to solve memory BW constraints.
● The precise implementation of the quadrature-clock generator is also an essential and important technology that needs to be
improved in for high-speed DRAM data transmission.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 23 Overview: AI Accelerators
Digital Architectures and Systems Subcommittee
Session Chair: Soojung Ryu, Seoul National University, Seoul, Republic of Korea
Session Co-Chair: Hugh Mair, MediaTek, Dallas, TX, USA
AI hardware accelerators are driving innovations in modern computing, influencing generative AI, large language models, and 3D point
cloud analysis. The initial papers focus on reducing external memory accesses and enhancing energy efficiency through hardware-aware
algorithms and novel processing units. Later papers highlight the need for energy-efficient solutions for edge devices and scalable AI
systems, showcasing advancements in optimizing AI hardware for cloud and edge applications. These innovations reflect ongoing efforts
to enhance performance and efficiency in AI hardware design.
• In Paper 23.1, Columbia University and Intel present a 16nm FinFET, 10.15mm2 transformer accelerator that reduces external memory accesses
(EMA) and enhances hardware utilization. Algorithmic model compression lowers EMA by up to 31×, while the chip achieves processing times of
68-567ms/token and energy consumption of 0.41-3.95mJ/token.
• In Paper 23.2, The Hong Kong University of Science and Technology presents a 28nm 13.93mm2 CNN-Transformer accelerator for semantic
segmentation, achieving 3.86-to-10.91× energy reduction over previous designs. It features a hybrid attention unit, layer-fusion scheduler, and
cascaded feature-map pruner, with peak energy efficiency of 52.90TOPS/W (INT8).
• In Paper 23.3, KAIST presents a 418mJ/inference few-step diffusion model accelerator for image generation. The 28nm 20.25mm2 accelerator
achieves 3.3-to-6.8× lower energy consumption than prior work on text-to-image and image-to-image benchmarks.
• In Paper 23.4, Peking University and Reconova Technologies present Nebula, a 28nm 1.5mm2 on-chip accelerator for 3D point cloud analysis.
Nebula employs tree-based adaptive partitioning, multi-skipping, and delayed-aggregation, achieving 109.8TOPS/W energy efficiency,
5.6TOPS/mm² area efficiency, and a 5263.2fps in state-of-the-art benchmarks.
• In Paper 23.5, MediaTek presents a 3nm, 0.168mm² neural processing unit for edge device generative AI. Featuring depth-first fusion, H-reuse
caching, and optimized scheduling, delivering 0.63TOPS with 3.74TOPS/mm² area efficiency. Operating at 0.575V and 546MHz, it achieves
12.38TOPS/W energy efficiency and 84.5% utilization for the TAESD model.
• In Paper 23.6, MIT and Chung-Ang University propose a 28nm 12.96mm2 generative AI processor featuring: 1) MEGA.mini architecture for 5.1×
efficiency, 2) an output synchronizer 3) a cross-shaped memory reducing power by 34.7%, and 4) a unified tensor streaming core. It delivers 8.1×
higher efficiency in non-diffusion and 4.1× in diffusion models compared to conventional processors.
• In Paper 23.7, KAIST presents BROCA, a 28nm 20.25mm2 mobile social agent SoC delivering 3.3× speedup and 1.8× lower energy consumption.
Key features include: 1) ABTU with ACER for energy-efficient response generation, 2) ACBU to reduce vocoder power, and 3) LTMU for low-
latency dialogue context retention.
• In Paper 23.8, Tsinghua University presents a 28nm 3.52mm2 LLM accelerator with: 1) an active-bit-allocate format reducing EMA by 3.87×, 2) a
cluster-aligned mixed-precision processing element lowering power by 4.87×, and 3) a bi-dimensional reformulation enhancing efficiency by
22.3%. It achieves a peak energy efficiency of 88.36TOPS/W in LLaMA-2-7B inference.
• In Paper 23.9, KAIST presents Slim-Llama, a 28nm 20.25mm2 ASIC reducing energy consumption in large language models by minimizing
external memory accesses. Using binary/ternary quantization and a sparsity-aware look-up table, it achieves up to 4.59× better energy efficiency
than previous designs and efficiently runs a billion-parameter Llama model at 4.69mW.
• In Paper 23.10, KAIST presents HuMoniX, a 14nm 12mm2 real-time text-to-motion processor using heterogeneous engine clusters, achieving
57.3fps and 12.8TFLOPS/W. It reduces computation with output sparsity and data compaction, and lowers latency by selectively building meshes
based on inter-frame similarity, supporting mixed-precision data for improved efficiency.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 23 Highlights: AI Accelerators
[23.1] T-REX: A 68-567
s/Token, 0.41-3.95
J/Token Transformer Accelerator with
Reduced External Memory Access and Enhanced Hardware Utilization in 16nm FinFET
[23.5] MAE: A 3nm 0.168mm2 576MAC Mini Autoencoder with Line-Based Depth-First
Scheduling for Generative AI in Vision on Edge Devices
[23.6] MEGA.mini: A Universal Generative AI Processor with a New Big/Little Core
Architecture for NPU
[23.8] An 88.36TOPS/W Bit-Level-Weight-Compressed Large Language Model
Accelerator with Cluster-Aligned INT-FP-GEMM and Bi-Dimensional Workflow
Reformulation
Paper 23.1 Authors: Seunghyun Moon1, Mao Li1, Gregory K. Chen2, Phil C Knag2, Ram Krishnamurthy2, Mingoo Seok1
Paper 23.1 Affiliation: 1Columbia University, New York, NY, 2Intel, Hillsboro, OR
Paper 23.5 Authors: Shih-Wei Hsieh, Chia-Hung Yuan, Ming-Hung Lin, Ping-Yuan Tsai, You-Yu Nian, Chia-Yuan Cheng, Hung-
Wei Chih, Po-Han Chiang, Ming-Hsuan Chiang, Yuan-Jung Kuo, Yu-Wei Wu, Yi-Syuan Chen, Po-Heng Chen, Sandy Huang,
Ming-En Shih, Chia-Ping Chen, Abrams Chen, ShenKai Chang, Chih-Ming Wang, Po-Yu Yeh, Jett Liu, Yung-Chang Chang,
Chung-Yi Chen, Chi-Cheng Ju, CH Wang, Kevin Jou
Paper 23.5 Affiliation: MediaTek, HsinChu, Taiwan
Paper 23.6 Authors: Donghyeon Han 1,2, Anantha P. Chandrakasan1
Paper 23.6 Affiliation: 1Massachusetts Institute of Technology, Cambridge, MA, 2Chung-Ang University, Seoul, Korea
Paper 23.8 Authors: Yubin Qin, Yang Wang, Jiachen Wang, Zhiwei Lin, Yushu Zhao, Shaojun Wei, Yang Hu, Shouyi Yin
Paper 23.8 Affiliation: Tsinghua University, Beijing, China
Subcommittee Chair: Rahul Rao, IBM, Bangalore, India
CONTEXT AND STATE OF THE ART
● The existing transformer accelerator designs exhibit large external memory access and low hardware utilization, resulting in
high energy consumption and latency, requiring innovations in transformer accelerator architectures.
● Supporting generative AI for vision on edge devices drives the need for the design of tiny NPUs for running autoencoders with
low external memory access and high temporal utilization, which can cooperate with large NPUs allowing workloads with
different characteristics to be handled efficiently.
● LLM models face challenges of high external memory access, mixed precision GEMM, and non-linear function dependencies,
requiring novel LLM accelerator architecture and circuit techniques to address these issues.
● Accelerating both diffusion and non-diffusion models for generative AI requires a universal generative AI processor with a
novel architecture for efficient computation of both models.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
TECHNICAL HIGHLIGHTS
● Columbia University and Intel describe a transformer accelerator designed to reduce external memory accesses
(EMA) and enhance hardware utilization.
o Model compression reduces external memory accesses (EMA) by up to 31, while dynamic batching for variable
input lengths further lowers EMA and boosts utilization by 3.3. A custom register file accessible in row- and column-
directions enhances utilization by an additional 1.2, achieving processing times of 68-567s/token and energy
consumption of 0.41-3.95J/token.
● MediaTek presents a 3nm tiny NPU accelerating auto-encoders and -decoders for generative AI on edge devices.
o The accelerator achieves an energy efficiency of up to 12.3TOPS/W and area efficiency of 3.74TOPS/mm2 on dense
workloads due to optimized scheduling of depth-first fused operators and local H-reuse caching with a direct link
between the convolution and add and concatenation units.
● MIT and Chung-Ang University present a heterogeneous neural processing architecture with large fixed-point and
small floating-point cores.
o The 12.96mm² SoC, fabricated in 28nm CMOS, supports diffusion and non-diffusion models with 1.8-to-8.1 higher
efficiency across five operating modes.
● LLM accelerator from Tsinghua University in 28nm CMOS executes a variety of large-scale generative models.
o External memory access is reduced by 3.87 with an active-bit-allocate format, while a mixed-precision matrix
multiply cuts power consumption by 4.87 and a bi-dimensional reformulation boosts efficiency by 22.3%. The
accelerator achieves peak energy efficiency of 88.36TOPS/W for LLaMA-2-7B inference.
APPLICATIONS AND ECONOMIC IMPACT
● An energy-efficient and low-latency transformer accelerator from Columbia University enables a wide range of AI applications
on the edge, including vision, language and speech.
● A tiny NPU running an autoencoder with high energy efficiency and temporal utilization from MediaTek enables generative AI
for vision on edge devices.
● A universal generative AI processor with a new big-little core architecture from MIT enables efficient acceleration of both
diffusion and non-diffusion models for generative AI applications.
● An LLM accelerator with bit-level weight compression and cluster-aligned INT-FP-GEMM from Tsinghua University
considerably improves the energy efficiency of LLM computations in natural language processing applications.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 24 Overview: High-Frequency ADCs
Data Converters Subcommittee
Session Chair: Seung-Tak Ryu, KAIST, Daejeon, Korea
Session Co-Chair: Vanessa Chen, Carnegie Mellon University, Pittsburgh, USA
Despite a long history and well-established design techniques, ADC architectures and circuit technologies for high-speed operation
continue to evolve. The conversion rates presented in this session range from 1 to 72GS/s, demonstrating innovative ADC structures
and circuit techniques aimed at achieving not only high speed but also exceptional energy efficiency. Key advancements introduced
include piecewise-linear nonlinearity calibration, dual-path amplification, sub-quantizer design, a mutually exclusive selection technique
to reduce metastability, wideband input buffers, time-interleaved ADC skew calibration using fractional-delay FIR filters, a hierarchical TI
ADC in 4nm CMOS, passive gain combined with automatic buffer power gating, and more.
• In Paper 24.1, Tsinghua University introduces a gated-LMS-based PWL nonlinearity calibration and dual-path amplification for better accuracy
and efficiency. The prototype ADC achieves 58.8dB SNDR at 3GS/s with 32.5mW power consumption, corresponding to a FoMs of 165dB.
• In Paper 24.2, Xidian University presents a 14b 1GS/s pipelined ADC with SAR sub-quantizer, achieving 68.2dB SNDR, 85.8dB SFDR, and
173.3dB FoMS. A dynamic dead-zone ring amplifier enhances efficiency without bias tuning.
• In Paper 24.3, University of Macau presents a 2× interleaved 2.2GS/s ADC using a gated-CCRO quantizer with improved energy efficiency and
PVT robustness, achieving 45.8dB SNDR, 65.7dB SFDR, and 19.7fJ/step FoMw.
• In Paper 24.4, University of Macau presents a 10b 3GS/s time-domain ADC with mutually exclusive selection technique to reduce metastability
errors. It achieves 47.2dB SNDR in low metastability mode and 49.3dB in split ADC mode at Nyquist input.
• In Paper 24.5, University of Macau presents a 16nm FinFET 72GS/s 9b time-interleaved pipeline SAR ADC with wideband input buffers and a
dual-path bootstrapped switch, achieving 55.3dB SFDR and 41.9dB SNDR at 20GHz input.
• In Paper 24.6, MediaTek presents a 4nm FinFET 12b 16GS/s time-interleaving ADC, consuming 570mW and occupying 0.430mm², achieving -
155dBFS/Hz noise spectral density and reducing spurs lower than -68dBFS at 7.4GHz input with digital calibration.
• In Paper 24.7, Tsinghua University presents an 8b 10GS/s time-interleaved pipelined ADC, achieving a sampling rate of 5GS/s per channel.
Automatic buffer power gating improves efficiency, achieving an FoMW of 22fJ/conv-step.
• In Paper 24.8, Analog Devices presents a 12GS/s 9b 16× time-interleaved SAR ADC in 16nm FinFET, achieving 48.1dB SNDR at 5.33GHz,
consuming 160mW, with one reservoir capacitor per bit and SAR loop feedback innovations.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 24 Highlights: High-Frequency ADCs
[24.1] A 3GS/s 12b Pipelined ADC with Gated-LMS-Based Piecewise-Linear Nonlinearity
Calibration
[24.5] A 72GS/s 9b Time-Interleaved Pipeline-SAR ADC Achieving 55.3/49.3dB SFDR at
20GHz/Nyquist Inputs in 16nm FinFET
Paper 24.1 Authors: Mingyang Gu, Yi Zhong, Lu Jie, Nan Sun
Paper 24.1 Affiliation: Tsinghua University, Beijing, China
Paper 24.5 Authors: Yannan Zhang1, Minglei Zhang1, Zehang Wu1, Yan Zhu1, R. P. Martins1,2, Chi-Hang Chan1
Paper 24.5 Affiliation: 1University of Macau, Macau, Macau, 2Instituto Superior Tecnico/University of Lisboa, Lisboa, Portugal
Subcommittee Chair: Jan Westra, Broadcom, Bunnik, The Netherlands, Data Converters
CONTEXT AND STATE OF THE ART
● Compact single-channel high-speed ADCs with low power consumption and high linearity are highly required in many
advanced applications such as 6G communication systems.
● On-chip linearity calibration techniques have become nearly mandatory to alleviate the power demands of analog circuits,
leveraging digital-assisted analog approaches.
● As data rates in wireline applications pursue several hundred Gb/s, there is growing interest in massively interleaved ultrahigh-
speed ADCs in compact chip area.
TECHNICAL HIGHLIGHTS
● Tsinghua University introduces a single-channel 12b 3GS/s pipelined ADC with compact on-chip digital piecewise-
linear nonlinearity calibration and dual path amplification for improved speed and energy efficiency.
o A single-channel 28nm CMOS 12b pipelined ADC with dual-path amplification and compact on-chip digital piecewise-
linear nonlinearity calibration demonstrates 9.4 ENOB at 3GS/s with only 32.5mW and FoMS of 165dB.
● University of Macau presents a 64× 72GS/s TI pipelined-SAR ADC with wideband linearized analog front-end,
achieving the highest SFDR among previously published similar CMOS ADCs and best FoMS.
o A 16nm FinFET 72GS/s 9b time-interleaved pipeline SAR ADC with wideband input buffers and a dual-path
bootstrapped switch achieves 55.3dB SFDR and 41.9dB SNDR at 20GHz input.
APPLICATIONS AND ECONOMIC IMPACT
● High-speed ADCs with resolutions exceeding 12 bits and conversion speeds beyond several GHz will be critical enablers for
advancing next-generation wireless communication standards like 6G.
● Ultrahigh-speed ADCs with good linearity are in high demand for wireline communication applications, as they are vital for
managing advanced modulation schemes and higher oversampling rates.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 25 Overview: High Concepts at High Frequencies
Technology Directions Subcommittee
Session Chair: Noriyuki Miura, Osaka University, Suita, Japan
Session Co-Chair: Denis Daly, Apple, Waltham, MA
High frequency and high bandwidth integrated circuits that interact with the electromagnetic spectrum in new ways continue to emerge.
The first two papers present two highly analog/mixed-signal implementations of 3-SAT solvers and cross-correlators that demonstrate
how compute in analog domain offers promise to achieve higher throughput and area efficiencies than traditional digital implementations.
The third paper presents an AI-enabled end-to-end algorithm flow for rapid architecture discovery, circuit topology and parameter
optimization for RFICs. The next two papers explore high frequency measurement. First, Paper 25.4 presents a micromachined
heterogeneously integrated active-probe enabling in-situ measurements from DC to 50GHz. The session concludes with a highly
integrated, low power time-domain channel analyzer with a measurement range from DC to 40GHz.
• In Paper 25.1, the University of Michigan presents an oscillator-based 3-SAT solver that leverages physics-inspired heuristics in a mixed-signal
compute fabric. The prototype implements a continuous-time dynamical system and Dynamic CT Injection (DaCTI) to solve 20/50-variable 3-SAT
problems with improved speed and energy efficiency compared to state-of-the-art solvers.
• In Paper 25.2, Washington University and Oregon State University present a fully-analog 256×256 cross-correlator based on sampling-based
approach and margin propagation paradigm. The IC operates up to 4GS/s input and template data rate and achieves 1000 TOPS/W with high
compute density up to 1.3 TOPS/mm2.
• In Paper 25.3, Princeton University demonstrates an AI-enabled end-to-end algorithm flow for architecture discovery, circuit topology and
parameter optimization for RFICs. The RFICs combine reinforcement learning and inverse methods to synthesize mm-Wave and sub-THz PAs
in 90nm SiGe.
• In Paper 25.4, Sandia National Laboratories presents a high-speed, high-impedance integrated silicon micromachined probe bonded to a DC-to-
50GHz sense amp for measurement applications. The amplifier, realized in a 45nm PD-SOI process, achieves a measured 3dB cutoff frequency
up to 50GHz, with < 90fF input capacitance, a 0dBm IP1dB, a 7.5dBm IIP3 and a 4% THD.
• In Paper 25.5, Peking University presents an integrated channel analyzer implemented in a 28nm CMOS process. The TX utilizes a patterned
step technique with a 4:1 clock gated multiplexer to enhance the SNR of the captured waveforms. The sampler adopts a clock booster to reduce
leakage and minimize the hold errors. The integrated channel analyzer achieves an equivalent sample rate of 1.792THz, 9.1ps rise time,
99.5mW/port power consumption, and a measurement range from DC to 40GHz.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 25 Highlights: High Concepts at High Frequencies
[25.1] AI-enabled Design Space Discovery and End-to-end Synthesis for RFICs with
Reinforcement Learning and Inverse Methods Demonstrating mmWave/sub-THz PAs
between 30-120 GHz
Paper 25.1 Authors: Jonathan Zhou1, Emir Ali Karahan1, Sherif Ghozzy1, Zheng Liu1,2, Hossein Jalili1, Kaushik Sengupta1
1Princeton University, Princeton, NJ, 2Kilby Labs, Texas Instruments, Dallas, TX
Subcommittee Chair: Ali Hajimiri, Caltech, Pasadena, CA
CONTEXT AND STATE OF THE ART
● AI-enabled algorithmic flow for architecture discovery, circuit topology and parameter optimization for RFICs, particularly
exploring design spaces beyond human intuition.
● Compared to prior works on optimizing circuit parameters with circuit simulation, this is the first work that demonstrates an
end-to-end RFIC AI-enabled synthesis with both active and passive optimization, and from specifications to layout with
fabricated and measured results.
TECHNICAL HIGHLIGHTS
● Princeton University and Texas Instruments leverage an AI-enabled end-to-end analog RF circuit automatic discovery
and design scheme to demonstrate a mmWave/Sub-THz circuit quickly synthesis RF circuit topology and design
parameters.
o The design time can be reduced between 3 to 6 months for a sub-THz PA designing to few minutes.
APPLICATIONS AND ECONOMIC IMPACT
● Huge design time savings for cost reduction of custom circuits design especially for RFICs.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 26 Overview:
Wireless Transmitters and Front-Ends
Wireless Subcommittee
Session Chair: Alireza Zolfaghari, Broadcom, Irvine, US
Session Co-Chair: Giuseppe Gramegna, imec, Leuven, Belgium
This session highlights the latest advancements in the area of wireless transmitters and front-ends. The first three papers introduce RF
transmitters (TX) in different applications spanning from a 24GHz implementation enabling high data rates to a sub-6GHz digital TX,
followed by a low-power IC driven by a neural network engine. The last two papers feature RF front-ends focusing on improved efficiency
and noise figures.
• In Paper 26.1, the University of Southern California presents a 65nm CMOS 24GHz digital TX that uses a multiphase subharmonic (SH) switching
power amplifier and a phase-shifted LO divider for improved SH spur suppression, enabling 3.2Gb/s data rate with 256QAM at -30.8dB EVM and
20.3% PAE.
• In Paper 26.2, Fudan University describes a 0.88mm2 28nm CMOS digital TX with joint digital-analog interpolation to deliver >42dBc replica
rejections for a WiFi 80MHz 256-QAM signal and >33dB dynamic power range. The TX achieves 27.8dBm/27.3dBm/24.8dBm Pout with
30.4%/30.5%/14.9% peak efficiency at 2.6GHz/3.6GHz/5.1GHz, respectively.
• In Paper 26.3, the University of Michigan introduces a 28nm CMOS crystal-less TX IC with the digital modulation and coding implemented with a
neural network, and an analog front-end achieving 41.1% power-efficiency resilience to carrier drift, and 10/4.4dB improvement in receive power
at 0.1% BER compared to uncoded/coded BLE.
• In Paper 26.4, Rice University presents a 0.22mm2 22nm CMOS 24-to-29GHz front-end featuring a two-way asymmetric Doherty PA co-designed
with LNA input matching and T/R switch, that achieves 19.6-to-20.6dBm Pout at 25.0%-to-27.7% PAE and 14.2%-to-19.8% PAE at 9.5dB back-
off, with 3.1 to 4.0dB NF.
• In Paper 26.5, Zhejiang University shows a 65nm CMOS 17.7-to-29.5GHz front-end with a PA load-capacitance-cancellation network T/R switch
in RX mode to achieve 20.2dBm OP1dB with 20.6% PAE and a NF of 3.3 to 5.0dB.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 26 Highlights:
Wireless Transmitters and Front-Ends
[26.2] A Wideband Replicas-Rejection Digital Transmitter Using Joint-Digital-Analog
Interpolation and Filtering in 28nm CMOS
Paper 26.2 Authors: Chunxiao Hu*, Jiaxiang Li*, Jie Lin, Hongtao Xu, Yun Yin
Paper 26.2 Affiliation: Fudan University, Shanghai, China
Subcommittee Chair: Chih-Ming Hung, Mediatek, Taiwan
CONTEXT AND STATE OF THE ART
● Improvement on system efficiency, data rate and cost reduction are required by all multiple wireless communications systems
and are driving the development of digital TX (DTX) architectures.
● In a DTX, undesired sampling replicas are close to the signal band, violating emission mask requirements, and requiring
oversampling with external filters.
● The trade-off of oversampling and selectivity of external filtering is made more challenging for a multiband system, which can
be solved using fully separated DTXs.
TECHNICAL HIGHLIGHTS
● Fudan University describes a 0.88mm2 28nm CMOS digital TX with joint digital-analog interpolation achieving
o > 42dBc replicas rejection and > 33dB dynamic power range for WiFi 40MHz 64-QAM and 80MHz 256-QAM signals,
and
o 27.8dBm/27.3dBm/24.8dBm Pout with 30.4%/30.5%/14.9% peak efficiency at 2.6GHz/3.6GHz/5.1GHz, respectively.
APPLICATIONS AND ECONOMIC IMPACT
● The technique allows efficient rejection of digital replicas and simplification of the system with associated cost reduction.
● The wideband technique alleviates the need to split a multiband system into multiple TXs and simplifies the implementation of
future multiband systems.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 27 Overview: Sensor Interfaces
Analog Subcommittee
Session Chair: Caspar van Vroonhoven, Analog Devices, Germany
Session Co-Chair: Chinwuba Ezekwe, Robert Bosch, CA
Duty-cycling and dynamic biasing improve power efficiency and scalability of sensor interfaces, while precision circuit techniques enable
new levels of absolute accuracy. The first paper describes a partially duty-cycled MEMS Gyroscope drive control loop that minimizes
standby power dissipation, while the third paper presents a frequency-controlled biasing method that enables a wide range of conversion
rates. The second paper demonstrates a CMOS Hall sensor with state-of-the-art offset performance. Two final papers present
temperature sensors that achieve state-of-the-art performance in both their power efficiency and temperature-sensing inaccuracy.
• In Paper 27.1, Xidian University presents a MEMS Gyroscope with an always-on drive loop, enabled by a burst-mode phase-locked loop. A
partially duty-cycled drive excitation loop maintains the gyroscope in semi-stable oscillation to enable a wake-up time of 2.8ms while limiting the
average standby power consumption to 1.5µW.
• In Paper 27.2, TU Delft presents a voltage-biased CMOS Hall sensor. Octagonal Hall plates are operated in spinning-current mode and read out
using a current-to-digital converter. The sensor achieves a magnetic field offset of 1.0μT (3σ) and a noise floor of 60nT/√Hz.
• In Paper 27.3, Zhejiang University and Vango Technologies present a continuous-time sensor interface. A frequency-controlled current source
enables a gm-C CTΣ∆M to achieve a near-consistent SNDR of ~84dB over a 225× bandwidth range. The sensor interface operates from a sub-
1V supply, has an input-referred noise density of 46nV/rtHz and an FoM of 178.2dB.
• In Paper 27.4, TU Delft presents an NPN-based temperature sensor that uses a noise-optimized charge-balancing scheme and a current-assisted
two-stage amplifier to improve both energy efficiency and accuracy. The sensor achieves an 80fJ∙K2 resolution FoM and an inaccuracy of ±0.1°C
(3σ) from -70°C to 125°C.
• In Paper 27.5, the University of Macau presents a wire-metal-based temperature sensor that uses a fractional-discharge frequency-locked-loop
and a time-domain amplifier to achieve a resolution FoM of 45fJ∙K2 and an inaccuracy of ±0.2°C (3σ) from -40°C to 125°C.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 27 Highlights: Scalable Sensor Interface
[27.3] A Sub-1V 14b 5.8nW/Hz BW/Power-Scalable CT Sensor Interface with a
Frequency-Controlled Current Source Achieving a 225× Scalable Range
Paper Authors: Xinjie Wu1, Yuyan Liu2, Xiaopeng Yu1, Nick Nianxiong Tan2, Zhong Tang2
Paper Affiliation: 1Zhejiang University, Hangzhou, China, 2Vango Technologies, Hangzhou, China
Subcommittee Chair: Viola Schaffer, Texas Instruments Deutschland GmbH, Freising, Germany, Analog
CONTEXT AND STATE OF THE ART
• Various IoT and wireless sensor-node applications require sensor interfaces with a variable conversion rate.
• Sensor interfaces with switched-capacitor front-ends such as SARs and discrete-time delta-sigma modulators are bandwidth
scalable but suffer from noise folding. Continuous-time front-ends do not suffer from noise folding but are not scaled as easily
when their internal circuitry incorporates fixed time constants.
TECHNICAL HIGHLIGHTS
• A continuous-time Delta-Sigma (ΔΣ) ADC is biased by a frequency-dependent current source, allowing the converter
to operate over a wide range of frequencies.
o A capacitively-biased-diode technique is used to generate a constant-Gm bias current that is proportional to
frequency but stable over temperature and supply voltage.
o A 2nd-order continuous-time ΔΣ modulator uses Gm-C integrators and an asynchronous multi-bit quantizer to achieve
bandwidth/power-scalable operation at a near-consistent SNDR of 84dB and power scaling of 5.8nW/Hz over a 225×
bandwidth range.
APPLICATIONS AND ECONOMIC IMPACT
• A bandwidth/power-scalable sensor interface enables adaptive signal acquisition – the ADC conversion rate may be adjusted
based on e.g. the richness of the sensor input data and/or the amount of energy available in the system. Adaptive signal
acquisition may enable more feature-rich IoT and wireless sensor nodes.
• More versatile sensor interfaces may reduce development time and cost due to their straightforward reconfigurability.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 28 Overview: Capacitive Sensor Readout
Analog Subcommittee
Session Chair: Caspar van Vroonhoven, Analog Devices, Germany
Session Co-Chair: Chinwuba Ezekwe, Robert Bosch, CA
Time-domain signal processing, two-step conversion, and continuous-time signal chains enable improvements in the performance of
capacitance-to-digital converters for a diverse range of applications. The techniques revealed in this session include the combination of
time-domain signal processing and two-step conversion to improve input range and conversion time (Paper 28.1), the use of continuous-
time high-pass noise-shaping to mitigate thermal noise aliasing and flicker noise (Paper 28.2), the use of a novel phase-domain add-
then-subtract lead-compensation scheme to stabilize a controlled-oscillator-based backend 2nd-order delta-sigma modulator (Paper 28.3),
and the use of phase-domain signal processing to enhance immunity to EMI (Paper 28.4).
• In Paper 28.1, KAIST, ETH, and NYU present a period-modulation-SAR hybrid capacitance-to-digital converter. The converter combines a period-
modulation front-end with a SAR-ADC backend to achieve 14.5b ENOB, 6.1μs conversion time, and an 18.1pF-to-18.5nF scalable full-scale
range.
• In Paper 28.2, KAIST and NYU present a continuous-time noise-shaping SAR capacitance-to-digital converter. The converter combines a
continuous-time capacitance-to-voltage converter with a continuous-time highpass noise-shaping SAR ADC to mitigate thermal noise aliasing
and flicker noise, achieving a 189.3dB-FoMS with 14.5fJ/conversion-step FoMW at 5.12pF full-scale range.
• In Paper 28.3, Peking University presents an incremental zoom capacitance-to-digital converter. The converter combines a SAR front-end with a
2nd-order delta-sigma modulator backend, which employs a Gm-C-based 1st stage and a controlled-oscillator-based 2nd stage, stabilized by an
add-then-subtract lead-compensation scheme, to achieve an 18.2fJ/conversion step FoMW at 1.2pF full-scale range.
• In Paper 28.4, Tsinghua University and CoSensing reveal a capacitance-to-digital converter for EMI-sensitive floating-target displacement-sensing
applications. Using a capacitance-to-phase-converter front-end and a phase-domain delta-sigma modulator, which together provide inherent
band-pass filtering and common-mode rejection, the converter achieves 143dB DR, with CMRRs of 119dB and 97dB near DC and 100MHz,
respectively.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 28 Highlights: Capacitive Displacement Sensor
[28.4] A 143dB-Dynamic-Range 119dB-CMRR Capacitance-to-Digital Converter for
High-Resolution Floating-Target Displacement Sensing
Paper Authors: Sining Pan1, Xiaolong Zhang1, Baoyi Zheng1, Yihang Cheng1, Hui Jiang2, Huaqiang Wu1
Paper Affiliation: 1Tsinghua University, Beijing, China, 2CoSensing, Utrecht, The Netherlands
Subcommittee Chair: Viola Schaffer, Texas Instruments Deutschland GmbH, Freising, Germany, Analog
CONTEXT AND STATE OF THE ART
• Capacitive floating-target displacement sensors, which sense the capacitance between a probe and a target, could be a lower-
power alternative to eddy-current-based floating-target displacement sensors.
• Existing solutions are based on singe-ended readout, which is highly vulnerable to EMI, or differential-switched-capacitor
readout, which is still vulnerable to EMI, especially at high frequencies, in any practical realization with inevitably imperfectly
matched differential-sensing capacitors.
TECHNICAL HIGHLIGHTS
• A capacitance-to-digital converter for floating-target displacement-sensing applications combines differential
readout with phase-domain signal processing to improve robustness against EMI.
o A capacitance-to-phase-converter front-end and a phase-domain delta-sigma modulator together provide inherent
bandpass filtering and common-mode rejection, enabling the converter to reject EMI as demonstrated by CMRRs of
119dB and 97dB near DC and 100MHz, respectively.
o The converter achieves a dynamic range of 143dB while dissipating 625µW.
APPLICATIONS AND ECONOMIC IMPACT
• Displacement sensors are widely used in high-precision nano-mechatronic systems.
• An EMI-robust capacitive solution offers the possibility to integrate floating-target displacement-sensing functionality into EMI-
rich environments for lower cost and low power dissipation.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 29 Overview: SRAM
Memory Subcommittee
Session Chair: John Wuu, AMD, Fort Collins, CO
Session Co-Chair: Yih Wang, TSMC, Hsinchu, Taiwan
SRAM continues to play an indispensable role in the relentless pursuit for higher compute performance. As traditional transistor scaling
slows, innovations and design-technology co-optimization (DTCO) are required more than ever to further extend SRAM’s density, speed
and functionality for energy-efficient compute. This session highlights four SRAM papers and one TCAM paper that push density, speed,
power and operation boundaries by combining architectural and circuit innovations with SRAM bitcells in advanced-process technologies
that include FinFET, Nanosheet and RibbonFET CMOS with backside interconnects.
• In Paper 29.1, TSMC introduces a 38.1Mb/mm2 SRAM in 2nm-CMOS-nanosheet technology for high-density and energy-efficient compute
applications. The design uses a 0.021um2 high-density bitcell, and through DTCO improves the overall SRAM density by 1.1× compared to the
previous technology node.
• In Paper 29.2, Intel reveals their SRAM design in the 18A-RibbonFET-CMOS technology, with PowerVia for back-side power delivery, using a
0.023um2 high-current and a 0.021um2 high-density bitcell. The gate-all-around technology demonstrates a 68mV VMIN reduction for the
34.3Mb/mm2 high-density SRAM design over the prior FinFET technology and supports up to 38.1Mb/mm2 area density.
• In Paper 29.3, MediaTek presents a 3nm Fin-FET TCAM with dynamically-gated search lines for data center ASICs. The 2.2G-searches/s
0.305fJ/b design achieves a 37.7% power and a 46.6% peak-current reduction through its power-optimization features at 4.97Mb/mm2.
• In Paper 29.4, Synopsys demonstrates a dual-rail SRAM design in 3nm FinFET technology. By optimizing level shifters, the design achieves a
38Mb/mm2 area density, while supporting 0.38 - 1.4V logic and 0.54 - 1.4V array voltage ranges.
• In Paper 29.5, TSMC presents a 3nm 3.6GHz dual-port SRAM with backend-RC optimizations and a far-end write-assist scheme. The 0.052um2
dual-port-bitcell based design exhibits 3.6GHz operation at 1.0V and 495mV VMIN.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 29 Highlights: SRAM
[29.1] A 38.1Mb/mm2 SRAM in a 2nm-CMOS-Nanosheet Technology for High-Density
and Energy-Efficient Compute
[29.2] 0.021μm2 High-Density SRAM in Intel 18A RibbonFET Technology with PowerVia-
Backside Power Delivery
Paper 29.1 Authors: Tsung-Yung Jonathan Chang, Yen-Huei Chen, K. Venkateswara Reddy, Nikhil Puri, Teja Masina, Kuo-Cheng Lin,
Po-Sheng Wang, Yangsyu Lin, Chih-Yu Lin, Yi-Hsin Nien, Hidehiro Fujiwara, Ching Wei Wu, Robin Lee, Hung-Jen Liao, Quincy Li, Ping
Wei Wang, Geoffrey Yeap
Paper 29.1 Affiliation: TSMC, Hsinchu, Taiwan
Paper 29.2 Authors: Xiaofei Wang1, Yusung Kim1, Hasan Abdullah1, Gwang Hyeon Baek1, Kunal Girish Bannore1, Kaushal Dave1,
Arash Joushaghani1, Narae Kang1, Minwoo Ko1, Kae Yih Lim2, Anandkumar Mahadevan Pillai3, Hema Chandra Prakash Movva1,
Gyusung Park1, Muktadir Rahman1, Seenivasan Subramaniam1, Vinay Vashishtha1, Teng Yang1, Zheng Guo1, Eric A Karl1
Paper 29.2 Affiliation: 1Intel, Hillsboro, OR, 2Intel, Penang, Malaysia, 3Intel, Santa Clara, CA
Subcommittee Chair: Meng-Fan (Marvin) Chang, National Tsing Hua University (NTHU), Taiwan
CONTEXT AND STATE OF THE ART
● Compute density and power efficiency are critical knobs for meeting the ever-increasing demand for compute, especially in the
age of explosive machine-learning growth.
● 3nm FinFET is the current state-of-the-art technology; however, nanosheet and RibbonFET CMOS technologies, especially
when combined with back-side power delivery, hold the promise to further propel SRAM energy efficiency.
● In the face of decelerating Moore’s Law, design innovations must also accompany technology advancements to continue
SRAM area and efficiency scaling.
TECHNICAL HIGHLIGHTS
● TSMC presents a high-density SRAM in 2nm-nanosheet CMOS for high-density and energy-efficient compute
o The high-density SRAM macro, featuring a 0.021μm2 high-density (HD) SRAM bitcell in a 2nm nanosheet CMOS,
achieves a bit density of 38.1Mb/mm2: a ~10% improvement over the prior 3nm FinFET CMOS technology.
● Intel reveals their SRAM design in the 18A RibbonFET CMOS technology with PowerVia for back-side power delivery,
using 0.023um2 high-current and 0.021um2 high-density SRAM bitcells
o Gate-all-around technology demonstrates a 68mV VMIN reduction for the 34.3Mb/mm2 high-density SRAM design,
compared to the prior FinFET technology, and support for up to a 38.1Mb/mm2 area density.
APPLICATIONS AND ECONOMIC IMPACT
● First high-volume demonstration of SRAMs from leading technology providers on a 2nm-nanosheet and 18A-RibbonFET
technology with backside power delivery.
● Technology optimization and design-technology co-optimization (DTCO) enable SRAM-density and energy-efficiency
enhancements over prior technologies, benefiting products across the industry to advance compute and broaden applications
to enrich human experiences.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 30 Overview: Nonvolatile Memory and DRAM
Memory Subcommittee
Session Chair: Seung-Jae Lee, Samsung, Korea
Session Co-Chair: Thomas Hein, Micron, Germany
Cutting-edge technologies continue to emerge, leading to increased memory capacities and faster performance. Samsung demonstrates
a NAND Flash memory with 4XX WL layers and 5.6Gb/s IO rate. Kioxia introduces a NAND Flash memory with the highest bit density.
Samsung introduces the 1st 24Gb GDDR7 DRAM, with a 42.5Gb/s IO rate and power-efficiency techniques. Samsung presents a 16G
LPDDR5X operating at 12.7Gb/s, with a self-calibrating IO scheme. SK Hynix introduces the highest-capacity (2Tb) QLC NAND Flash
memory, with a six-plane architecture. Kioxia and SK Hynix present the world’s highest density 64Gb cross-point MRAM chip.
• In Paper 30.1, Samsung presents a 4XX-layer 1Tb 3b/cell 3D NAND Flash with a wafer-bonding architecture, achieving a 28.2Gb/mm² bit density.
Eliminating dummy holes and using a 2-transistor coded-GSL scheme enables a 4% array size and 8% power consumption reduction. This design
also offers a fast 5.6Gb/s/pin IO speed and a low-power option with PI-LTT, cutting channel power by 73% compared to LTT.
• In Paper 30.2, Kioxia and Western Digital introduce a 1Tb 3b/cell 3D Flash memory, achieving a 29% read energy-efficiency improvement and
features a 4.8Gb/s I/O interface using PI-LTT. The I/O circuit area is reduced by 17% by circuit optimization and CMOS directly-bonded-to-array
(CBA) technology. This design also achieves a bit density over 29Gb/mm² with 332-WL layers.
• In Paper 30.3, Samsung shows the 1st implementation of a 24Gb GDDR7 DRAM and 42.5Gb/s data rate, with power reduction techniques for
WCK clocking and core operation; thereby, achieving a 13.6% energy-efficiency improvement over prior GDDR7.
• In Paper 30.4, Samsung presents a 16Gb 12.7Gb/s LPDDR5X DRAM with a self-calibrating IO scheme and AC-coupled equalization in a 5th-
generation 10nm technology. The distributed 4-phase clock skew is reduced by 33.7% via self-calibration.
• In Paper 30.5, SK Hynix presents a 2Tb 4b/cell 3D-NAND Flash memory with a 3.2Gb/s IO speed and a 6-plane architecture. Increased internal-
bias levels, during programming, reduce program disturbance by 18%. A precise bias generator ensures consistent bias levels across
temperatures, while efficient power gating in the TX interface decreases CIO by 20% and area by 55%.
• In Paper 30.6, Kioxia and SK Hynix introduce the world’s highest density 64Gb cross-point MRAM chip, featuring a 0.001681µm² 20.5nm HP 1-
selector 1-MTJ cell. The work presents a timing-controlled-discharge reading scheme, combined with a local-capacitance mode which enables a
high-speed 3ns read pulse and a read margin of over 4σ, while addressing read disturbances using the smallest cell size to date.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 30 Highlights: Nonvolatile Memory and DRAM
[30.1] A 28Gb/mm2 4XX-Layer 1Tb 3b/cell WF-Bonding 3D-NAND Flash with 5.6Gb/s/pin
IOs
[30.3] A 24Gb 42.5Gb/s GDDR7 DRAM with Low-Power-WCK Distribution, an RC-
Optimized Dual-Emphasis TX, and Voltage/Time-Margin-Enhanced Power Reduction
Paper 30.1 Authors: Sang-Soo Park, Jae-Doeg Lyu, Myungjun Kim, Jaeyun Lee, Younsun Song, Chung-Ho Yu, Hirano Makoto,
Yongseok Kwon, Jong-Hoon Park, Ho-Joon Kim, Daein Lee, Donghyun Seo, Byungrok Go, Seoyoon Jeon, Yoonjee Kim, Doo-Hyun
Kim, Youngmin Jo, Hyunjun Yoon, Junehong Park, Inmo Kim, Sunghoon Kim, Hokil Lee, Je-Hyeon Yu, Sang-Lok Kim, Hwan-Seok Ku,
Jungmin Seo, Jindo Byun, Seung-Hyeon Yun, Kyoungtae Kang, Seung-Beom Kim, Yohan Lee, Yongkyu Lee, Kyunghwa Kang, Han-
Jun Lee, Younghwan Ryu, Hyundo Kim, Wontae Kim, Hyeongdo Choi, Juho Jeon, Ansoo Park, Raehyun Song, Jae-Hwan Kim, Jung-
Soo Kim, Hwa-Seok Lee, Moo-Kyung Lee, Jae-Ick Son, Jiho Cho, Moosung Kim, Jae-Woo Im, Jongmin Park, Hyuckjoon Kwon,
Youngdon Choi, Chiweon Yoon, Seungjae Lee, Kiwhan Song, Sung-Hoi Hur
Paper 30.1 Affiliation: Samsung Electronics, Hwaseong-si, Korea
Paper 30.3 Authors: MSang-Hoon Kim, Jaehyeok Baek, Moon-Chul Choi, Daewoong Lee, Donggun An, Se mi Kim, Yeonggeun
Song, Minkyo Shim, Sung-Yong Cho, Dongha Lee, Gunhee Cho, In-Woo Jun, Juseop Park, TaeYoon Lee, Hwan-Chul Jung,
Chanyong Lee, Gil-Young Kang, Hye-Ran Kim, Jongmyung Lee, Young Su Joo, Hyo-Jin Jung, Bokyeon Won, Ji-Hak Yu, Sangkeun
Han, Yechan Hwang, Chungman Kim, Seok-Jung Kim, YoungSeok Lee, Young-Tae Kim, Myeong-O Kim, Wonhwa Shin, Tae-Young
Oh, SangJoon Hwang
Paper 30.3 Affiliation: Samsung Electronics, Hwaseong, Korea
Subcommittee Chair: Meng-Fang Chang, Tsing Hua University, Taiwan, Memory
CONTEXT AND STATE OF THE ART
● Paper 30.1 describes NAND Flash with 4XX WL layers and 5.6Gb/s/pin data rate, it emphasizes power reduction and
improved IO speed, thereby addressing current challenges in NAND Flash memory.
● High-speed graphics GDDR7 with PAM3 interfaces is on the forefront of interface speed and DRAM architecture. The focus is
now shifted towards power efficiency, while still increasing the speed.
TECHNICAL HIGHLIGHTS
● Samsung introduces a 1Tb 3b/cell 3D-NAND Flash with 4XX WL layers and 5.6Gb/s/pin IO speed.
o By removing dummy holes and adopting a 2-transistor coded-GSL scheme, they reduce array size by 4% and power
consumption by 8%.
o This work achieves the fastest (5.6Gb/s/pin) IO speed, along with a low-power using PI-LTT that reduces channel
power by 73% than LTT.
● Samsung Electronics presents the 1st implementation of a 24Gb GDDR7 DRAM achieving a data rate of 42.5Gb/s with
power-reduction techniques for core operation.
o A two-row DQ architecture, with low-power WCK-distribution techniques, reduces clock-distribution power. The
sense-margin enhancement and power-reduction techniques achieve a 13.6% energy efficiency improvement.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
APPLICATIONS AND ECONOMIC IMPACT
● It is anticipated that enhanced performance will be achieved in mobile and PCIe applications, while power consumption is
reduced.
● High-performance graphics DRAMs are now used everywhere where high bandwidth is required: gaming, AI training and
inference, and advanced driver-assist systems (ADAS) for automotive applications.
● Architectural and circuit changes are required to achieve the highest bandwidth, while still achieving the lowest possible power
consumption. Novel high-speed interface techniques are applied to achieve reliable PAM3 data transmission.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 31 Overview: Energy Harvesting and IoT Power
Power Management Subcommittee
Session Chair: Gaël Pillonnet, CEA-Leti, Grenoble, France
Session Co-Chair: Sung-Wan Hong, Sogang University, Seoul, Korea
Recent advancements in energy harvesting and IoT power management are featured in four papers at this year's ISSCC. Paper 31.1
presents a hybrid system that combines piezoelectric and electromagnetic harvesters to achieve improved efficiency and circuit
compactness. Paper 31.2 introduces a biased-SECE interface for fast maximum power point tracking in piezoelectric harvesting. Paper
31.3 highlights a sense-and-track MPPT circuit designed for continuous power extraction under various conditions, including periodic and
shock excitations. The final paper, 31.4, showcases a PMIC optimized for mm-scale IoT applications, enhancing burst energy delivery
through a hybrid combination of capacitors and batteries.
• In Paper 31.1, TU Delft presents a fully integrated hybrid energy harvesting system using a coil-sharing structure, combining piezoelectric and
electromagnetic harvesters. It achieves 2.72mW power with 90% efficiency, eliminating the need for a bulky off-chip electrical interface.
• In Paper 31.2, KAIST presents a biased-SECE interface with geometric-mean computational MPPT for a piezoelectric harvester. It tracks MPP
quickly and accurately without interrupting the harvesting, achieving 99.9% efficiency. Fabricated in 180nm BCD, the system improves FoMs by
9.29× for periodic excitation and 5.02× for shock inputs.
• In Paper 31.3, TU Delft University presents a sense-and-track MPPT circuit for piezoelectric energy harvesting, achieving fast, continuous MPPT
and improving power extraction by 718% under periodic and 568% under shock excitations. Fabricated in 0.18μm BCD, the circuit operates
efficiently with a 0.67mm² active area.
• In Paper 31.4, University of Macau presents a capacitive PMIC with 91.25% peak efficiency for mm-scale IoT applications, featuring a
reconfigurable HV converter. It achieves a ~70% energy extraction efficiency (EEE) and delivers up to 5.68mJ using a 220μF capacitor, improving
EEE by over 35× and burst energy by 27×, while reducing storage capacitance by 34× compared to prior designs.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 31 Highlights: Energy Harvesting and IoT Power
[31.1] An Inductor-less Capacitor-less Synchronous Piezoelectric-Electromagnetic
Hybrid Energy Harvesting Platform with Coil-Sharing Scheme
Paper Authors: Y. Wei, X. Yue, Z. Chen, S. Du
Paper Affiliation: Delft University of Technology, Delft, The Netherlands
Subcommittee Chair: Bernhard Wicht
CONTEXT AND STATE OF THE ART
• The growing adoption of IoT and edge AI applications is increasing the demand for sustainable and compact energy harvesting
solutions to power devices, aiming to replace batteries or extend their lifespan.
• Current piezoelectric-based energy harvesting interfaces often rely on bulky off-chip inductors or multiple capacitors, which adds
to the system's volume and bill of materials (BoM), emphasizing the need for innovative solutions to enhance integration.
• Combining different types of harvesters can offer more reliable and efficient energy production; however, this approach faces
challenges with interface complexity, which can further increase the size and impact the overall performance.
TECHNICAL HIGHLIGHTS
• A novel hybrid energy harvesting platform integrates piezoelectric and electromagnetic sources, utilizing a coil-sharing
structure and synchronized energy phases to eliminate the need for passive components in the electrical interface and
maximize harvested power.
o The energy harvesting system, which extracts energy from both electromagnetic and piezoelectric sources, achieves
a maximum output power of 2.72mW and a peak efficiency of 90% without the use of additional passive components,
significantly boosting energy extraction capabilities for IoT devices.
APPLICATIONS AND ECONOMIC IMPACT
• This energy harvesting solution is ideal for powering small-scale IoT devices in vibration-rich environments, enabling self-
sustained operation or extending battery life with a minimal electrical interface. Utilizing dual sources enhances the robustness
and power density of energy harvesting by employing two mechanisms.
• By eliminating the need for passive components used in traditional electrical interfaces, this platform lowers production costs
and simplifies system-level manufacturing, making it a compelling choice in the expanding energy harvesting market.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 32 Overview: Isolated Power and Gate Drivers
Power Management Subcommittee
Session Chair: Lin Cheng, University of Science and Technology of China, China
Session Co-Chair: Shusuke Kawai, Toshiba Corporation, Japan
Isolated Power and Gate Drivers are critical for ensuring safety and reliability in harsh industrial environments, such as electric vehicles
and industrial automation. This session aims to showcase some of the best work in the isolated power and gate drivers area, featuring
novel topologies that offer high conversion efficiency, reduced electromagnetic interference (EMI), and advanced power regulation for
isolated converters, as well as precise gate control techniques for GaN gate drivers.
• In Paper 32.1, The University of Macau and Instituto Superior Tecnico/University of Lisboa present an isolated DC-DC converter with a Q-downsize
Class-D power amplifier with inherent shoot-through current blocking. The design achieves 45.3% peak efficiency and 1W maximum output power
at 180MHz, while meeting CISPR-32 Class-B certification.
• In Paper 32.2, Iowa State University introduces a single-link multi-domain-output (SLiMDO) isolated DC-DC converter, providing two regulated
outputs and achieving global power modulation via a single FPC micro-transformer with passive magnetic flux sharing and Rx behavior sensing.
The design achieves 62.6% peak efficiency at 610mW and 1.13W maximum output power.
• In Paper 32.3, National Yang Ming Chiao Tung University, Chip-GaN Power Semiconductor, Realtek Semiconductor and Taiwan Semiconductor
Research Institute present a GaN-based CGS isolated driver featuring an accurate secondary-side controller for precise dead-time control. It
achieves less than 3ns delay to turn on/off GaN-based rectifiers.
• In Paper 32.4, University of Science and Technology of China presents a dual-LC-resonant isolated DC-DC converter incorporating inherent
backscattering, which enhances efficiency and eliminates the need for a digital isolator. The design achieves 65.4% peak efficiency and 1.5W
maximum output power.
• In Paper 32.5, University of Science and Technology of China and Hefei CLT Microelectronics present a multi-core isolated DC-DC converter
with an embedded magnetic-core transformer to reduce EMI and output voltage ripple. The design achieves 53.2% peak efficiency and less than
5mV ripple while meeting CISPR-32 Class-B EMI compliance.
• In Paper 32.6, National Yang Ming Chiao Tung University, Chip-GaN Power Semiconductor, Realtek Semiconductor, and Taiwan Semiconductor
Research Institute present a GaN load switch for bidirectional current transfer and reverse current blocking. It achieves 91.4% inrush current
reduction and 89.5% overshoot reduction.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 32 Highlights: Isolated Power and Gate Drivers
[32.1] A 180MHz 45.3% Peak Efficiency Isolated Converter Using Q-Downsize Class-D
Power Amplifier with Inherent Shoot-Through
Paper 32.1 Authors: Tian Xia*1, Qiujin Chen*1, Shujing Wang1, Rui Paulo Martins1,2, Mo Huang1
Paper 32.1 Affiliation: 1University of Macau, Taipa, Macau, 2Instituto Superior Tecnico/University of Lisboa, Lisbon, Portugal of
Science and Technology of China, Hefei, China
Subcommittee Chair: Bernhard Wicht, University of Hannover, Germany, Power Management
CONTEXT AND STATE OF THE ART
● Isolated DC-DC converters with low electromagnetic interference (EMI) are essential for high reliability systems in harsh
industrial environments. Class-D PA and Class-D oscillation circuits are used to reduce noise and improve efficiency.
TECHNICAL HIGHLIGHTS
● The University of Macau and Instituto Superior Tecnico/University of Lisboa propose a Q-downsize Class-D PA type
isolated converter that combines the advantages of Class-D PA and Class-D oscillator circuits. The proposed circuit
simultaneously reduces the through current and the MOS drive loss at the TX, improving efficiency.
o The converter using the Q-downsize technique achieves a 45.3% peak efficiency and maximum 1W output power, at
a 180MHz operating frequency. The converter with symmetrical topology meets the CISPR-32 Class-B certification
requirements.
APPLICATIONS AND ECONOMIC IMPACT
● The proposed converter achieving highly efficient, low noise, and high frequency operation contributes to reducing system
volume, lowering power consumption, and improving reliability for systems in harsh industrial environments.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 33 Overview: Components for Beyond 100GHz
RF Subcommittee
Session Chair: Jeremy Dunworth, Qualcomm Technologies Inc., CA
Session Co-Chair: Hiroshi Hamada, NTT, Atsugi, Japan
Session Co-Chair: Mona M. Hella*, Rensselaer Polytechnic Institute, NY
Systems operating in the frequency range above 100GHz continue to face challenges associated with output power, tuning range,
power consumption, and integration levels. This session explores circuit techniques, advanced transistor technology options, and
package integration and co-design that address such challenges. The session includes an amplifier-multiplier chain with high output
power above 200GHz, a highly integrated GaN PA MMIC and module, two D-band phase shifters, and a G-band VCO. These
papers enable applications in high resolution radars, sensing, spectroscopy, ultra-high speed communications, and others.
• In Paper 33.1, the Massachusetts Institute of Technology describes a 232-to-260GHz amplifier-multiplier-chain (AMC) array in the Intel16
CMOS process radiating 11.1dBm. This is achieved due to a high-power RF FinFET transistor technology and a patterned dielectric matching
sheet to replace the conventional silicon lens.
• In Paper 33.2, the National Key Laboratory of Solid-State Microwave Devices and Circuits, Nanjing Electronic Device Institute, and Tianjin
University demonstrate a solid-state power amplifier with a maximum output power of 1.54W at 223GHz achieved by combining 32 GaN
MMICs co-designed with the package. The GaN MMIC PAs are enhanced by carefully designed AlN/GaN heterojunction
(fT/fMAX=180GHz/420GHz), and the design procedure utilizes a multiband large-signal impedance-correction technique.
• In Paper 33.3, the University of Pavia showcases a hybrid active/passive phase shifter in 55nm SiGe BiCMOS. The phase shifter achieves
360-degree range across 125-to-170GHz band using an outphasing gain and phase calibration. The output 1dB compression point is above
2dBm with 31mW DC power consumption, corresponding to a 5× power efficiency enhancement against previous works.
• In Paper 33.4, ETH-Zurich presents a bidirectional phase shifter featuring 11.25° resolution and achieving a calibration-free fractional
bandwidth of 24% with <2.38°/0.63dB rms phase and gain errors across the 110-to-140GHz band in 22nm SOI.
• In Paper 33.5, Rensselaer Polytechnic Institute demonstrates a nearly 20% tuning range G-Band VCO (202.1 to 246.8GHz) with a varactor-
less multisection switch-loaded coupled-line resonator responsible for the extended tuning range and improved quality factor (>10) across
the band in 22nm FDSOI.
*1971 to 2025
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 33 Highlights: Components for Beyond 100GHz
[33.2] A 216-to-226GHz Watt-Level GaN Solid-State Power Amplifier with Multiband
Large-Signal Impedance Correction and Circuit-Package Co-Design Technique
Paper Authors: Weibo Wang1,2, Zhe Li3, Haifeng Cheng1,2, Fangjin Guo1,2, Yibin Zhang1,2, Kai Li3, Keping Wang3
Paper Affiliation: 1National Key Laboratory of Solid-State Microwave Devices and Circuits, Nanjing, China, 2Nanjing Electronic Device
Institute, Nanjing, China, 3Tianjin University, Tianjin, China
Subcommittee Chair: Brian Ginsburg, Texas Instruments, Dallas, TX,, RF subcommittee
CONTEXT AND STATE OF THE ART
● 220GHz solid-state power amplifiers are typically built in InP, SiGe, or CMOS technologies. Amplifiers in CMOS/SiGe
technologies have limited output power due to low operating voltage and low (fT/fmax) while InP suffers from high cost and low
yield.
● Although GaN HEMTs possess wide bandgap, high breakdown voltage, and electron saturation drift velocity, no G-band
(220GHz) PAs in GaN HEMT technology have been reported to date.
TECHNICAL HIGHLIGHTS
● A 216-to-226GHz GaN solid-state power amplifier achieves 1.53W peak output power at 223GHz by using waveguides
to combine the outputs of 4 GaN MMIC modules. Each module consists of 8 GaN MMIC PAs with max Psat of 20.4dBm
per PA.
o GaN transistors fT and fmax are improved through several modifications to the GaN epitaxy, which increase
transconductance, reduce contact resistance, gate-source and gate-drain capacitances, and enhance the 2DEG
concentration via an AlN/GaN strongly polarized heterojunction.
o A large-signal impedance-correction technique is employed to measure output-power (Pout) peaks across W and D-
bands with broadband output matching networks. The large-signal model is corrected to improve Pout across all
frequencies.
o The GaN PA MMIC, waveguide cavity, bondwire, and probe-microstrip-transition structures are co-designed to avoid
impedance variations at assembly interfaces.
APPLICATIONS AND ECONOMIC IMPACT
● Increased G-band power-amplifier Psat enables future high-data-rate wireless communication, imaging, and radar systems.
● The availability of over 1W Psat at frequencies above 200GHz creates opportunities for instrumentation and sub-THz systems
that would not otherwise be possible.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 34 Overview:
Digital PLLs and Waveform-Shaping VCOs
RF Subcommittee
Session Chair: Xiang Gao, Zhejiang University, Hangzhou, China
Session Co-Chair: Yu-Li Hsueh, MediaTek, Taiwan
Digital PLLs and waveform-shaping VCOs continue to evolve and diversify. The first paper in this session describes a low-jitter, quantization-error-
compensating, BBPD-based fractional-N DPLL. The second paper introduces a DPLL-based frequency modulator for BLE. In the third paper, a DPLL
design is presented featuring a harmonic-shaping DCO with adaptive tuning of its common-mode resonance. An octave-tuning-range VCO with
magnetic mode switching and wide-band common-mode resonator is introduced in the 4th paper. This is followed by a quad-core class-F23 VCO,
designed without 2nd/3rd harmonic tuning. The final paper showcases a mm-wave VCO design incorporating a two-port resonator-based quasi-Class-
E Colpitts oscillation.
• In Paper 34.1, Seoul National University presents a 10.1GHz low-jitter fractional-N DPLL with a quantization-error-compensating BBPD, which
reduces the in-band noise and rms jitter. It also utilizes orthogonal-polynomial LMS multi-variable calibration to accelerate its convergence speed.
The DPLL achieves 65fs rms jitter and -252.2dB FoM.
• In Paper 34.2, Politecnico di Milano introduces a 2.25-to-2.5GHz digital-PLL-based frequency modulator, supporting 1Mb/s GFSK and 80MHz
frequency hopping for BLE. It exploits a fast-hopping technique with gain calibration of the DCO tuning curve and a gear-shift mechanism for re-
locking. The PLL consumes 380µW with sub-20µs settling time for the GFSK modulator.
• In Paper 34.3, Politecnico di Milano presents an adaptive technique to automatically tune the common-mode resonance of a harmonic-shaping
DCO in a DPLL. The DCO phase noise is automatically minimized in the flicker- and white-noise regions, and the PLL achieves 45.86fs rms jitter
and -257dB FoM.
• In Paper 34.4, Rice University presents an octave-tuning-range VCO with magnetic mode switching and a tuning-free, octave-BW common-mode
resonator for 1/f3 PN corner reduction. The 65nm-CMOS LO-generator design demonstrates a wide tuning range from 9.05 to 37GHz,
190.7dBc/Hz worst-case FoM, and 212.3dBc/Hz worst-case FoMT.
• In Paper 34.5, the Nanjing University of Science and Technology introduces a quad-core Class-F23 VCO with a circular trifilar transformer to
extend the differential-mode resonance around the 3rd harmonic and an 8-shape stacked inductor to extend the common-mode resonant peak
around the 2nd harmonic. The 65nm-CMOS 18.5-to-23.6GHz VCO achieves -139.3 to -138.0dBc/Hz phase noise, 193.0 to 190.1dBc/Hz FoM at
a 10MHz offset, and 140 to 250kHz 1/f3 corner frequency.
• In Paper 34.6, the Chinese University of Hong Kong proposes to improve the VCO PN by exploiting quasi-Class-E Colpitts oscillation based on a
two-port resonator. It enables fundamental oscillation, waveform shaping for power efficiency enhancement, and PN suppression. A 40nm-CMOS
prototype exhibits an FTR of 47.3 to 58.4GHz (21.1%), PN from –124.9 to –119.8dBc/Hz at a 10MHz offset, 5.5 to 10.5mW power consumption,
and 198.8 to 192.6dBc/Hz FoMT.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 34 Highlights:
Digital PLLs and Waveform-Shaping VCOs
[34.2] A 380μW and -242.8dB FoM Digital-PLL-Based GFSK Modulator with sub-20μs
Settling Frequency Hopping for Bluetooth Low-Energy in 22nm CMOS
Paper Authors: Simone Mattia Dartizio, Giacomo Castoro, Stefano Gallucci, Michele Rossoni, Riccardo Moleri,
Francesco Tesolin, Pietro Salvi, Saleh Karman, Andrea Leonardo Lacaita, Salvatore Levantino
Paper Affiliation: Politecnico di Milano, Milano, Italy
Subcommittee Chair: Brian Ginsburg, Texas Instruments, Dallas, TX, RF Subcommittee
CONTEXT AND STATE OF THE ART
● A very low-power PLL-based frequency modulator supports 1Mb/s GFSK and 80MHz frequency hopping for BLE. It exploits a
fast-hopping technique with gain calibration of the DCO tuning curve and a gear-shift mechanism for re-locking.
TECHNICAL HIGHLIGHTS
● Politecnico di Milano presents a 22nm digital-PLL achieving 1Mb/s GFSK frequency modulation and fast frequency
hopping with very low power consumption
o A 2.25-to-2.5GHz frequency modulator supporting 1Mb/s GFSK and 80MHz frequency hopping for BLE. It exploits a
fast-hopping technique with dither-based gain calibration of the DCO tuning curve and a gear-shift mechanism for re-
locking. The PLL consumes 380µW with sub-20µs settling for the GFSK modulator.
APPLICATIONS AND ECONOMIC IMPACT
● High power-efficiency techniques for PLL-based frequency modulators.
● Suitable for ultra-low-power applications, such as BLE.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 35 Overview:
Implantable and Wearable Biomedical Devices
Imagers, Medical, and Displays Subcommittee
Session Chair: Mehdi Kiani, Pennsylvania State University, University Park, PA, USA
Session Co-Chair: Bo Zhao, Zhejiang University, Hangzhou, China
Biomedical devices for implantable and wearable applications integrate various functionalities, including wireless power and data transfer,
recording and stimulation, security, and imaging. The papers in this session continue to explore different modalities for wireless power
and data transfer (e.g., inductive, ultrasound, magnetoelectric), neural stimulation (e.g., electrical, ultrasound), and biomedical imaging
(e.g., photoacoustic, bioimpedance spectroscopy). The first half of the session focuses on ASICs designed for security, ultrasound
stimulation and imaging, and bioimpedance spectroscopy, while the second half highlights ASICs with wireless power/data capabilities.
• In Paper 35.1, Delft University of Technology presents an efficient high-voltage transmit beamformer ASIC for wearable ultrasound stimulation. It
drives a 32-element array with 36V phase-delayed pulses using a single inductor that resonates with the capacitance of the transducer elements,
reducing the energy loss by 88.2%.
• In Paper 35.2, Rice University introduces a low-power photoacoustic receiver for wearable imagers that employs a multichannel analog spatial-
domain compressive sensing. The ASIC provides 4× reduction in output data rate and number of ADCs.
• In Paper 35.3, University College London presents a 30MHz wideband bioimpedance spectroscopy IC with time-to-digital demodulation. The IC
achieves an equivalent sampling rate of 21.6GHz with a 240MHz clock utilizing a co-prime delay-locked sampling method. At 30MHz, the IC has
an overall 92.7dB SNR, 99.6% accuracy with 0.39% magnitude error and 0.57° phase error, and 3.18mW power consumption.
• In Paper 35.4, Rice University introduces a mechanical-input-based two-factor authentication (2FA) protocol in a miniature implant powered
wirelessly by a magnetoelectric transducer. It achieves a 2FA success rate of 98.27% and demonstrates continuous uplink with on-off keying
modulation at up to 110kb/s.
• In Paper 35.5, Korea Advanced Institute of Science & Technology shows a wireless adiabatic neural stimulation system employing current-mode
power reception through inductive coupling. The ASIC achieves precise charge delivery, a power conversion efficiency of 72.5%, and a stimulation
efficiency factor of 6.02.
• In Paper 35.6, Korea Advanced Institute of Science & Technology presents an enhanced-frequency-splitting-based wireless power and data
transfer system for small implants employing link-load isolation. The wireless system achieves an end-to-end power efficiency of 60.2% and a
downlink data rate of 1Mb/s using a sub-cm receiver coil.
• In Paper 35.7, Pohang University of Science and Technology presents an automated resonant current-mode ASIC for wireless power transfer
with a three-dimensional receiver coil. The power-management ASIC achieves up to 75.1% power conversion efficiency, while the three-
dimensional receiver coil provides robustness against misalignments.
• In Paper 35.8, University of California at Berkeley describes DustNet, an ultrasound-based transceiver capable of supporting up to 8 implants
through time-division multiplexing with 16-level amplitude-shift-keying backscatter modulation. The wireless system operates at 90mm depth with
a maximum data rate of 400kb/s at 2MHz carrier frequency (50kb/s uplink per implant).
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 35 Highlights: Photoacoustic/Implant RXs
[35.2] A Spatial-Domain Compressive-Sensing Photoacoustic Imager with Matrix-
Multiplying SAR ADC
[35.6] An Enhanced-Frequency-Splitting-Based Wireless Power and Data Transfer
System Achieving 60.2% End-to-End Efficiency and 1Mb/s Data Rate with a Sub-cm RX
Coil for Miniaturized Implants
Paper 35.2 Authors: Huan-Cheng Liao, Shunyao Zhang, Yumin Su, Arvind Govinday, Yiwei Zou, Wei Wang, Vivek Boominathan,
Ashok Veeraraghavan, Lei Li, Kaiyuan Yang
Paper 35.2 Affiliation: Rice University, Houston, TX
Paper 35.6 Authors: Yechan Park, Chul Kim, Minkyu Je
Paper 35.6 Affiliation: KAIST, Daejeon, Korea
Subcommittee Chair: Rikky Muller, University of California, Berkeley, CA
CONTEXT AND STATE OF THE ART
● A compact and low-power photoacoustic RX employs a multichannel analog spatial-domain compressive sensing to achieve a
significant reduction in output data rate and number of ADC.
● A matrix-vector multiplying SAR ADC supports a general sensing matrix with a ternary setting, while two reconstructed methods
based on fast iterative shrinkage-thresholding algorithm and implicit neural representations reconstruct the compressed signal.
● An enhanced-frequency-splitting-based wireless power and data transfer system for miniaturized implants achieves a high end-
to-end efficiency and a high data rate using a sub-cm RX coil.
● The system minimizes coil size by employing a dynamically controlled LC tank and link-load isolation, enhancing the
performance in compact wireless implants.
TECHNICAL HIGHLIGHTS
● Rice University introduces a spatial-domain compressive sensing photoacoustic RX with matrix-multiplying SAR
ADC
o A photoacoustic RX chip incorporating spatial domain compressive sensing achieves a compression of the output
data rate by a factor of 4 to 8.
● KAIST presents an enhanced-frequency-splitting-based wireless power and data transfer system for miniaturized
implants.
o The enhanced-frequency-splitting-based wireless power and data transfer system achieves 60.2% end-to-end
efficiency and 1Mb/s data rate using a sub-cm RX coil.
APPLICATIONS AND ECONOMIC IMPACT
● Compressive sensing RX hardware supports a general sensing matrix while using fewer ADCs than input channels, potentially
enabling the envisioned wearable photoacoustic imager.
● The technique minimizes coil size and mitigates trade-offs in wireless power and data transfer systems, enabling enhanced
performance in compact wireless implants.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 36 Overview: Ultra-High-Density D2D
and High-Performance Optical Transceivers
Wireline Subcommittee
Session Chair: Masum Hossain, Carleton University, Ottawa, Canada
Session Co-Chair: Tamer Ali, MediaTek, Irvine, USA,
Subcommittee Chair: Thomas Toifl, Cisco Systems, Thalwil, Switzerland
ML-driven computing demands higher bandwidth density and improved energy efficiency. High-density die-to-die interconnects with ultra-high-speed
silicon photonics solutions can provide low latency and wide-bandwidth connectivity with excellent energy efficiency on a chiplet platform. The first three
papers in the session will present high-density electrical interconnect solutions whereas the last five papers will focus on different challenges of optical
transceivers. The first paper from TSMC reports the highest beachfront density in 3nm finFET technology. The second paper in the session presents
innovative crosstalk and echo cancellation techniques for single-ended signaling. The third paper from Cadence presents UCIe-compliant high-density
interconnect over a 2.5D interposer interface in 3nm FinFET. In the fourth paper, Intel will present the highest reported speed VCSEL driver and
transimpedance amplifier front-end in CMOS technology. In the fifth paper, Xi'an JiaoTong University presents a low-latency solution for 200Gb/s
pluggable optics. The sixth paper in the session introduces several circuit techniques to achieve a 112Gb/s PAM-4 linear TIA with 0.61pJ/b energy
efficiency. The seventh paper from the University of Illinois at Urbana-Champaign will present a 64Gb/s, 16-QAM analog coherent receiver designed
for high-speed short-reach optical links. The 8th paper from the Southern University of Science and Technology will present a 160Gb/s PAM-4 driver
with a swing of 3.8Vppd in 130nm SiGe BiCMOS. In the last paper of the session, Marvell will present a 212Gb/s PAM-4 retimer solution in 5nm FinFET
technology achieving a swing of 3Vppd with a BW of 54GHz and a TDECQ of 2.04dB when driving a Mach-Zehnder Modulator.
• In Paper 36.1 TSMC presents a UCIe-compliant die-to-die interface achieving 10.5Tb/s/mm beachfront density in 3nm technology. Over 64 lanes
this paper demonstrates an aggregate eye width of 19ps (61% UI) and an eye height of 560mV at 32Gb/s after lane deskew correction, with an
energy efficiency of 0.6pJ/b.
• In Paper 36.2, Peking University presents a 64Gb/s/wire single-ended simultaneous bi-directional transceiver using crosstalk and echo
cancellation techniques for die-to-die interfaces over 3mm shield-less on-chip channel achieving BER of 1e-16.
• In Paper 36.3, Cadence presents a 0.29pJ/b, 5.27Tb/s/mm UCIe interface over 2.5D interposer interface in 3nm FinFET. The PHY supports 4-
16Gb/s/pin achieving a BER of 1e-15 and latency of 3.5ns.
• In Paper 36.4, Intel presents a PAM-4 VCSEL-based direct-drive optical engine that integrates VCSEL driver and transimpedance amplifier front-
end CMOS ICs. Several circuit techniques are introduced to enable the >100Gb/s PAM-4 operation to achieve 0.9pJ/b energy efficiency.
• In Paper 36.5, Xi’an JiaoTong University presents a low-latency solution for 200Gb/s pluggable optics. The link includes a 200G transceiver with
a 200Gb/s analog MUX/DEMUX in 130nm SiGe and a 100Gb/s mixed-signal transceiver in 28nm CMOS achieving BER of 1e-12 transferring
PRBS7 at 200Gb/s.
• In Paper 36.6, Southern University of Science and Technology presents a 112Gb/s PAM-4 linear TIA. Employing several design techniques
including regulated active-input-termination TIA (AIT-TIA) and signal interpolation-based single-ended-to-differential converter (S2D) achieves
the longest 0.2inch PD-TIA reach with an excellent power efficiency of 0.61pJ/b.
• In Paper 36.7, the University of Illinois at Urbana-Champaign presents a low-power 16-QAM analog coherent receiver designed for high-speed
short-reach optical links. The prototype receiver recovers 64Gb/s data with a BER better than 1e-10 and achieves a power efficiency of 1.54pJ/b
in 28nm CMOS.
• In Paper 36.8, Southern University of Science and Technology presents a high swing linear driver. The driver topology utilizes cross-coupled Gm
cells and a cross-folded transmission line to achieve a maximum data rate of 160Gb/s PAM-4 with a swing of 3.8Vppd and a THD of 2.21% at 4Vppd
5GHz sinusoidal output in 130nm SiGe BiCMOS.
• In Paper 36.9, Marvell presents a 212Gb/s PAM-4 retimer solution demonstrating electrical long-reach capability and high swing optical driver in
5nm FinFET technology. The optical driver achieves a swing of 3Vppd with a BW of 54GHz and a TDECQ of 2.04dB when driving a Mach-Zehnder
Modulator. The C2M interface achieves a BER of 1.8e-10 on a 40dB loss channel with an energy efficiency of 2.76pJ/b.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 36 Highlights: Ultra-High-Density D2D
and High-Performance Optical Transceivers
[36.1] A 32Gb/s 10.5Tb/s/mm 0.6pJ/b UCIe-Compliant Low-Latency Interface in 3nm
Featuring Matched-Delay for Dynamic Clock Gating
Paper Authors: Mu-Shan Lin1, Chien-Chun Tsai1, Shenggao Li2, Wei-Chih Chen1, Wen-Hung Huang1, Yu-Chi Chen1, Yu-Jie Huang1,
Alan Drake3, Chin-Hua Wen1, Paul Ranucci3, Hsin-Hung Kuo1, Aidong Yin3, Shu-Chun Yang1, Farsheed Mahmoudi3, Han-Tzung Ke1,
Chao-Chieh Li1, Nai-Chen Cheng1, Jimmy Wang4, Kevin Lin1, Harry Liao4, Jie-Ren Huang1, Meng-Hsuan Wu4, Kenny Cheng-Hsiang
Hsieh1, Nicholas Amatruda5, William Polanco5, David King5, Todd Basso6, Anwar Kashem6
Paper Affiliation: 1TSMC, Hsinchu, Taiwan, 2TSMC, San Jose, CA, 3TSMC, Austin, TX, 4TSMC, Nanjing, China, 5AMD, Austin, TX,
6AMD, San Jose, CA
[36.9] A 212Gb/s PAM-4 Retimer with Integrated High-Swing Optical Driver and Chip-to-
Module Long Reach Capability of 40dB in 5nm FinFET
Paper Authors: V Gurumoorthy1, A Tan1, A Iyer1, A Fan2, A Farhoodfar1, B Alnabulsi3, C Abidin2, C Loi4, D Cartina5, H Lo1, I Fabiano6,
J Riani1, J H Teo4, J Q Wang1, K Raviprakash1, K K Ravi Prakash1, L Cai4, L Patra1, M Bachu1, N Codega6, N Shivashankar1, S Ray1, S
Chong4, S Jafarlou2, S Yu4, T F Wu2, W Y Neo4, X Ding4, Y Wang4, Z Yan1, Z Sun4, S Jantzi2, L Tse1, K Chang1
Paper Affiliation: 1Marvell, Santa Clara, CA, 2Marvell, Irvine, CA, 3Marvell, Ottawa, ON, Canada, 4Marvell, Singapore, Singapore,
5Marvell, Burnaby, BC, Canada, 6Marvell, Pavia, Italy
Subcommittee Chair: Thomas Toifl, Cisco Systems, Thalwil, Switzerland
CONTEXT AND STATE OF THE ART
• Accelerated by AI/ML-driven growth in computing performance, system disaggregation into chiplets using organic or advanced
packaging technologies with high bandwidth density has introduced challenges such as xtalk, low power and low latency
circuit design.
• In support of rapidly increasing demand for higher bandwidth and reach, ultra-high-speed optical interconnects have found
new applications such as data center switches to extend the reach of electrical interconnects.
TECHNICAL HIGHLIGHTS
• TSMC presents the industry first 32Gb/s/lane UCIe-compliant advanced (UCIe-A) packaging interface, via a 1.7mm
silicon bridge, achieving 10.5Tb/s/mm beachfront bandwidth density with an energy efficiency of 0.6pJ/b in 3nm
FinFET.
o The first demonstration of a 32Gb/s/lane UCIe-A compliant module, comprising 64 transmitter and 64 receiver lanes.
It achieves 30% higher beachfront bandwidth density than state-of-the-art die-to-die (D2D) work.
o The matched-delay architecture limits the data-to-clock relative phase drift to 0.3ps (< 1% UI), enabling dynamic
clock gating to tolerate instantaneous voltage drops and runtime recalibration for long-term temperature drift.
o Applying per-lane deskew correction improves the aggregate eye width from 26% to 61% UI.
o The D2D channel routing uses five metal layers in the bridge die where each signal is shielded by ground to minimize
crosstalk noise.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Marvell presents a 4-lane 212Gb/s PAM-4 complete re-timer solution with the first CMOS integrated high-swing optical
driver and chip-to-module (C2M) with capability of 40dB loss compensation, fabricated in 5nm FinFET.
o The integrated high-swing optical driver achieves a swing of 3Vppd with a bandwidth of 54GHz when driving a Mach-
Zehnder Modulator.
o Direct DAC-based transmitter architecture achieves 0.9Vppd swing with 60GHz BW.
o The design employs a back-to-back latch-based retimer to improve the timing window and single-edge jitter
attenuation technique.
o This design achieves 3 orders of magnitude better BER than prior art while communicating over a 2dB higher loss
channel.
APPLICATIONS AND ECONOMIC IMPACT
• UCIe interconnects enable system disaggregation into chiplets, communicating over 2/2.5/3D channels with high throughput at
low power consumption and latency. By enabling chiplet reuse and modularity, UCIe can accelerate time-to-market.
• 200+ Gb/s complete re-timer solution, including chip-to-module interfaces to drive long electrical interconnects in GPU-based
racks, can enable optical direct detect applications such as top-of-rack switches.
• Demonstrated circuit architectures with robust performance pave the way to mass deployment in commercial applications and
can lead to future standards such as co-packaged applications.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 37 Overview: Design-Technology Optimization
and Digital Accelerators
Digital Circuits Technique Subcommittee
Session Chair: Jae-sun Seo, Cornell Tech, New York, NY
Session Co-Chair: Mahmut Ersin Sinangil, NVIDIA, Santa Clara, CA
This session presents eight papers that push the boundaries of digital circuit techniques for design-technology optimization, domain-specific computing
and digital accelerators, aiming to enhance energy efficiency, system performance, and application-specific capabilities. The first paper explores
design-technology co-optimization (DTCO) for an industrial processor design, and the second paper presents a chiplet solution for networks-on-textiles
with system-on-chip and networking chiplets. The third paper demonstrates a compute-in-memory (CIM)-based microprocessor utilizing embedded
MRAM for neural network inference, and the fourth paper reports a reusable active TSV-interposer with programmability. The fifth paper introduces a
complete KSAT solver that achieves 100% solvability or proves unsatisfiability, and the sixth paper showcases a diffusion accelerator leveraging SRAM
CIM and eDRAM storage. The seventh paper highlights a GPS acquisition accelerator designed with energy-accuracy-driven optimization and
computing, and the eighth paper presents a low-power keyword spotting system featuring on-chip training for accented users.
• In Paper 37.1, IBM and University of Bonn present design technology co-optimization for the 8-core 5.5GHz IBM Tellum II processor in 5nm,
packing 1.38× more transistors in 1.13× area footprint and 1.05× power envelope, while simultaneously meeting a reliability target of 99.999999%
system uptime. Key innovations in standard cell library architecture, low-power sequential circuits, soft-error-tolerant design and design-for-
manufacturability are demonstrated.
• In Paper 37.2, researchers from the University of Virginia and Nautilus Defense LLC present two chiplets in 65nm, a system-on-chip and a
networking chiplet bySPI, that are designed for direct-die attachment to an embroidered conductive-yarn in-textile bus. The 0.6mmx2.15mm
chiplets enable networks-on-textiles that operate at 1.8V with the SoC consuming 3.34mW at 80MHz and the bySPI consuming 0.27mW at
34MHz.
• In Paper 37.3, authors from Samsung Advanced Institute of Technology, Seoul National University, Samsung Electronics and Harvard University
present an MRAM IMC-based processor for neural network inference in 28nm technology. Featuring 1.1Mb of embedded MRAM with system-
wise calibration techniques, this work achieves 20TOPS/W processor-level energy efficiency for 1b precision at 1.0V.
• In Paper 37.4, Fudan University and Kiwimoore Semiconductors present a 586mm2 reusable active TSV-interposer in 28nm CMOS
TSV/microbump technology integrating 512Mb SRAM and programmable 2.5D and 3D Network-on-active-interposer with up to 307.2GB/s BW,
integrated buck VRs, PLLs and a boot CPU.
• In Paper 37.5, Peking University presents a complete K-SAT solver in 28nm, achieving 100% solvability and unsatisfiable problem detection with
an SRAM-based dual-path macro, an incremental updater, and a position-encoded counter. This chip achieves average solving time of 218-
clause 50-variable SAT problems in 17.1ms or proves unsatisfiability in 42.1ms average time, at 0.9V and 200MHz, consuming 3.39mW.
• In Paper 37.6, researchers from Peking University describe a 864kb SRAM CIM-based accelerator in 22nm with 3Mb eDRAM storage for diffusion
models that perform image, 3D and video generation. The chip features bandwidth-aware memory partition and a bitline-segmented CIM cluster
design, achieving 60.81TFLOPS/W for INT8/BF16 hybrid precision at 180MHz and 0.6V.
• In Paper 37.7, researchers from Seoul National University and Columbia University present an end-to-end GPS acquisition accelerator using
mixed-radix IFFT optimizations and ROM-assisted computing in 28nm technology. Achieving 18.1mJ/acquisition at 88.5MHz and 0.6V, the
proposed accelerator supports acquisition of 32 satellites across all 41 doppler bins.
• In Paper 37.8, researchers from the Korea Advanced Institute of Science and Technology, ETH Zürich and Columbia University present a keyword
spotting system to recognize 35 keywords spoken by users with accents, featuring efficient feature extraction and on-chip training. The 28nm chip
achieves 92.2% accuracy on accented speech, while consuming 10.93mW for inference and 13.46mW for training at 0.75MHz under a 1V analog
and 0.7V digital supply.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Session 37 Highlights: Design-Technology Optimization
and Digital Accelerators
[37.6] A 22nm 60.81TFLOPS/W Diffusion Accelerator with Bandwidth-Aware Memory
Partition and BL-Segmented Compute-in-Memory for Efficient Multi-Task Content
Generation
Paper Authors: Yiqi Jing, Jiaqi Zhou, Yiyang Sun, Siyuan He, Ru Huang, Le Ye, Tianyu Jia
Paper Affiliation: Peking University, Beijing, China
Subcommittee Chair: Huichu Liu, Meta, Sunnyvale, CA, Digital Circuits
CONTEXT AND STATE OF THE ART
• Diffusion models have rapidly expanded into many content-generation tasks, e.g. 3D scenes or video, and deliver exceptional
performance. Due to the large number of denoising steps, generating content using such models consumes significant
latency.
• Compute-in-memory (CIM) accelerators improve computational performance thanks to efficient array-level parallelization, but
their use for practical image or multi-task diffusion models remains limited due to dynamic memory bandwidth requirements,
suboptimal CIM macro utilization, and compute-intensive consistency operations of emerging diffusion models.
TECHNICAL HIGHLIGHTS
• Peking University reports a CIM-based accelerator for diffusion models targeting image, 3D, and video generation
tasks, integrating 3Mb eDRAM storage, 864kb digital-CIM SRAM and a RISC-V CPU. The 22nm chip achieves
60.81TFLOPS/W at 180MHz and 0.6V for state-of-the-art diffusion models on customized hybrid BF16-W4A8
precision.
• A dynamic bandwidth-aware memory partition scheme is developed with on-chip eDRAM storage to optimize CIM utilization
and reduce external memory access, achieving a 2.68 performance gain with optimized hardware utilization.
• A bitline-segmented CIM cluster is designed with reuse-aware weight reordering, enhancing macro energy efficiency by
2.17. A hierarchical consistency optimization flow is presented to minimize frame/pixel-level operations and offers 3.71
speedup.
• Multiple content generation tasks are evaluated using state-of-the-art diffusion models, such as SD-v1.5, Wonder3D, and
SVD, based on customized hybrid BF16-W4A8 quantization The 22nm chip achieves 60.81TFLOPS/W at 180MHz and 0.6V.
APPLICATIONS AND ECONOMIC IMPACT
• The contributions in the demonstrated compute-in-memory-based diffusion model accelerator can overcome the memory
bottleneck and further advance energy-efficient image/video generation tasks.
• Improved performance enables running additional consistency operations between views and frames for smooth rendering in
generative 3D and video applications.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Trends
ISSCC 2020
TRENDS
ISSCC 2025
TRENDS

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Conditions of Publication
PREAMBLE
The Session Overviews and Highlights to follow serve to capture the context, highlights, and potential impact, of the papers to be
presented in each Session at ISSCC 2025 in February.
OBTAINING COPYRIGHT to ISSCC press material is EASY!
You may quote the Subcommittee Chair as the author of the text if authorship is required.
You are welcome to use this material, copyright- and royalty-free, with the following understanding:
o That you will maintain at least one reference to ISSCC 2025 in the body of your text, ideally retaining the date and
location. For detail, see the FOOTNOTE below.
o That you will provide a courtesy PDF of your excerpted press piece and particulars of its placement to
lcfujino@aol.com and shahriar@ece.ubc.ca.
FOOTNOTE
• From ISSCC’s point of view, the phraseology included in the box below captures what we at ISSCC would like your readership
to know about this, the 72nd appearance of ISSCC, on February 19th to February 20th, 2025.
This and other related topics will be discussed at length at ISSCC 2025, the foremost global forum for new
developments in the integrated-circuit industry. ISSCC, the International Solid-State Circuits Conference,
will be held virtually on February 16 - February 20, 2025
ISSCC Press Kit Disclaimer
The material presented here is preliminary.
As of November 5, 2024, there is not enough information to guarantee its correctness.
Thus, it must be used with some caution.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
HISTORICAL TRENDS IN TECHNICAL THEMES
ANALOG SYSTEMS
ANALOG SUBCOMMITTEE
POWER MANAGEMENT SUBCOMMITTEE
DATA CONVERTERS SUBCOMMITTEE

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Analog – 2025 Trends
Subcommittee Chair: Viola Schaffer, Texas Instruments Deutschland GmbH, Freising, Germany
As in previous years, ISSCC 2025 continues the focus on energy-efficient precision. New analog technique combinations enable
improvements in the performance of oscillators, amplifiers, references, sensor interfaces, and other circuits.
Significant advances in the energy-efficient stabilization of RC oscillators are disclosed. Figure 1 shows oscillator temperature stability
vs. energy per cycle of an RC oscillator among others published over the last 16 years. By using a reference replica to continuously and
dynamically cancel both comparator offset and delay, the RC oscillator achieves a TC of 9.83ppm/°C, limited by resistor temperature
drift, at 0.4pJ/cycle.
Disclosures on crystal oscillators include low-complexity analog methods for controlling conduction angle to reduce crystal-oscillator
power dissipation to sub-nano-Watt levels.
Figure 1: Trends in RC oscillator stability and energy per cycle.
The same theme of energy-efficient realization of high precision circuits prevails in amplifiers. A boosted audio amplifier uses a single-
inductor buck-boost power stage to directly transfer power from battery to speaker, potentially mitigating the losses associated with the
traiditonal two-stage boost-converter-Class-D combination. Other amplifer techniques focus on improving the bandwidth-power efficiency
and temperature stability of precision amplifiers.
0.1
1
10
100
1000
10000
100000
0.100 1.000 10.000 100.000 1,000.000
Stability (ppm/oC)
Energy/Cycle (pJ)
ISSCC VLSI
CICC ESSCIRC
ASSCC ISSCC2025

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
The theme extends to interfaces for a variety of sensors. Figure 2 shows the performance of two temperature sensors presented at
ISSCC 2025, among other published temperature sensors. Precision and low-power circuit techniques enable an NPN-based
temperature sensor to achieve an 80fJ∙K2 resolution FoM and a 3σ inaccuracy of ±0.1°C, and a wire-metal-based temperature sensor
to achieve a 45fJ∙K2 resolution FoM and a 3σ inaccuracy of ±0.2°C. These represent new levels of combined energy efficiency and
absolute accuracy in CMOS temperature sensors.
In capacitive sensor interaces, time-domain signal processing, two-step conversion, and continuous-time signal chains enable
improvements in performance for a diverse range of applications. A capacitance-to-digital converter (CDC) combines a period-
modulation-SAR front-end with a SAR-ADC backend to achieve 14.5b ENOB and 6.1µs conversion time across a 1000× scalable full-
scale range. Another CDC combines a SAR capacitance-to-voltage-converter front-end with a continuous-time highpass noise-shaping
SAR-ADC backend to achieve a 14.5fJ/conversion step FoMW at 5.12pF full-scale range. A third CDC combines a SAR front-end with a
controlled-oscillator-based 2nd-order delta-sigma modulator backend to achieve an 18.2fJ/conversion step FoMW at 1.2pF full-scale
range. A fourth CDC combines a capacitance-to-phase-converter front-end with a phase-domain delta-sigma modulator to achieve a high
degree of immunity to EMI in floating-target precision-displacement-sensing applications.
In other sensor interfaces, duty cycling and dynamic biasing improve power efficiency and scalability. A MEMS-gyroscope paritially duty-
cycles key circuit blocks to minimize standby power dissipation, while enabling sufficiently fast wake-up for always-on applications. A
continuous-time delta-sigma modulator uses a frequency-controlled biasing method to enable a 225× adjustable conversion rate while
maintaining its signal-to-noise ratio. Finally, to serve increasing system-level speed requirements, techniques are presented for improved
high frequency power-supply rejection of voltage references, for a temperature- and aging-stable frequency management module and
for high speed track-and-hold circuits.
Figure 2: Trends in Resolution FoM of temperature sensors.
1.00E-06
1.00E-05
1.00E-04
1.00E-03
1.00E-02
1.00E-01
1.00E+00
1.00E+01
1.00E+02
1.00E+03
2014 2016 2018 2020 2022 2024
Resolution FOM (nJ·K2)
Year
BJT
Res
ISSCC 2025

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Power Management – 2025 Trends
Subcommittee Chair: Bernhard Wicht, Leibniz University, Hannover, Germany
Integrated power management is an indispensable building block in all electronic devices and has become one of the most critical parts
of ever-demanding systems, ranging from high-performance computing, 5G/6G communications, energy harvesting, wireless power
transfer, automotive and various other consumer and industrial applications. The diverse applications come with a large variety of
input/output voltage and current requirements for the integrated power management units that are both challenging and very exciting for
this unique area of solid-state circuits. For example, to power high-performance processors and AI/ML accelerators at the sub-1V core
voltage levels at the power up to 1-3 kW, the integrated power regulators need to convert from very high voltages (~48V) to reduce the
input distribution loss. Supply modulators for power amplifiers in 5G/6G transmitters need to regulate the outputs with near-instantaneous
changes in voltage and current levels, while other applications like automotive require extreme reliability and careful design to minimize
electromagnetic interference (EMI). Some integrated power converters must transfer power and/or signals across isolation boundaries,
and yet others must efficiently process and recover energy from intermittent low-power transducers. With this diversity, integrated power
management needs to be custom designed to specific applications and requirements. While this diversity makes it harder to evaluate the
quality of a certain design, common key performance indicators (KPIs) for integrated power converters are high power and/or current
density, high efficiency (minimal power loss), small overall footprint, and low cost.
In order to meet the wide range of challenges associated with the vast diversity of
applications and input and output requirements, researchers in integrated power
management need to investigate a large set of technologies from converter topologies,
active and passive devices, to methods of integration. This is well reflected in the
submissions and accepted papers at ISSCC in every previous year and also this year.
Figure 1 and 2 on the right illustrate this trend on the submitted and accepted papers to
this year’s ISSCC. There are relatively small shifts of percentage among different
converter categories from submitted papers to accepted papers because of the large
difference between the numbers of submissions (124) and accepted papers (30) with a
competitive ~24.2% acceptance rate.
Notably, the diversity of topics and their relative shares of the pool stay relatively
consistent, in which hybrid converter stands out to hold the largest share. This is
evidence of an apparent increase in interest from both academia and industry to combine
and leverage the benefits of both inductor and capacitor and low-voltage switches to
tackle the challenges in power delivery, particularly in simultaneously achieving high
power density, high efficiency, and large input-output voltage difference. Following
publications from previous years, hybrid converter papers in this year continue to explore
new circuit designs and techniques to address a wide range of input-output voltages,
provide more output voltages, mitigate the voltage and current stresses for inductors
such that size reduction is possible, balance flying capacitor voltages, or reduce output
voltage ripples and increase transient responses, etc.
It is no doubt a daunting task to evaluate and fairly compare the performance among the converters, especially when they are designed
for different applications with different sets of specifications. However, the common key performance indicator (KPI) of efficiency versus
power density (the higher the better for both) is generally agreed among experts in the field. This metric is used to compare the
performance of hybrid converter papers accepted to ISSCC 2025 and in previous years in Fig. 3 and 4 on the right. Power density is a
good metric, but only fair in comparing converters with the same voltage conversion ratio (VCR: the ratio between the input and output
voltages, Vin/Vo) and the same maximum input voltage. Higher input voltages and higher VCR would make it much more difficult to
achieve the same efficiency at the same power density. Figures 3 and 4 show that ISSCC 2025 papers continue to push the limit of
converter designs for higher efficiency and higher power density at higher VCRs and higher input voltages. While it is more difficult to
apply the same metric to papers in the other categories, similar considerations for high efficiency, small overall footprint, and low cost

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
are used for evaluation. ISSCC attendees are advised to pay close attention
to these metrics to assess certain papers and techniques at the conference.
It is of particular interest to the members of technical program committee
(TPC) in power management (PM) as well as ISSCC TPC at large to see the
trend in these topics over the year, presented in Fig. 5. While the 3-year data
have a good correlation with the submission numbers and interests, the exact
number in each topic and fluctuations over the year also depends on the
quality of works and paper submissions, the diversity of PM TPC members
and their possible charging perspective over the year. With that being
considered, the four notable trends in the last 3 years of integrated power
management are: 1) Power management will stay very diverse, 2) Hybrid
converter is the most popular, followed by wireless power transfer (WPT) and
energy harvesting (EH), 3) Supply modulator becomes more important, 4)
Isolated power converter draws more interest, and 4) LDO research is still
interesting.
Aligned with the interests and trend to increase input voltages to reduce the
input distribution loss while keeping the cost low for fabrication, we see an
undeniable favor of higher-voltage Bipolar-CMOS-DMOS (BCD) processes as
reported in Fig. 6. The researchers are spending a lot of effort in addressing
one of the most challenging issues in the industry today: achieve the KPIs at
a higher input voltage level.
One of the most important emerging technologies that is expected to dominate
high-voltage power converters is GaN power IC. However, in the last 3 years,
GaN power ICs have struggled to gain a larger foothold at ISSCC with the
number of accepted papers limited to three or below each year. This reflects the early
stage of the technology where getting access to a GaN process and fabrication is a big
challenge in itself. Another headwind for this direction is the challenge to prove its
superiority compared to a BCD process, e.g., 180nm BCD, in a practical implementation
even when GaN power switches can theoretically offer 10X-100X higher FOMs (RdsQg)
compared with the BCD counterpart. In addition, GaN device experts are still trying to
improve the overall yield and reliability of the process and GaN devices. Regardless,
there is a good sign in the industry with the superior performance promise and and
research synergy in academia that GaN power IC will still keep its foothold, even still at
of the relatively small number of publications each year, waiting for a larger increase in
a near future when the key drawbacks of fabrication access, yield, and reliability are
alleviated.
One the side of low voltage but extremely high output current delivery for high-performance computing, this ISSCC 2025 will exhibit the
first ever complete fully-integrated switching converter in a 3nm FinFET process that includes zero current detection, and soft-switching
techniques to enable the operations in both discontinuous conduction mode and continuous conduction mode. The converter utilizes a
next-generation package integrated coaxial magnetic integrated inductor (CoaxMIL) to achieve a remarkable output current density of 55
A/mm2.
The readers of this article are advised to also watch the highlights and full contents of the four power management sessions at ISSCC
2025 to experience, to the fullest, the diversity, the breadth, and the depths of one of the most popular and important areas of the solid-
state circuits society today.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Data Converters – 2025 Trends
Subcommittee Chair: Jan Westra, Broadcom, Bunnik, The Netherlands
Achieving high resolution at high sampling rates has been the driving force behind creativity and new architectural advancements in
wireline and wireless applications. This year at ISSCC, high-speed ADCs with resolutions exceeding 12 bits and conversion speeds
beyond several GHz are showcased, demonstrating remarkable energy efficiency. New architectural choices, circuit innovations, and
calibration techniques are pushing the boundaries of performance. Challenges in advanced nodes are addressed and innovative
parallelization in pipeline SAR ADCs are introduced. The use of time-domain and ring oscillator circuits is leveraged to maximize the
converter speeds, taking full advantage of technology scaling. Various noise-shaping techniques and SAR/Pipe-SAR designs are
explored, achieving over 180dB Schreier FoMs and more than 90dB SNDR for high-fidelity applications.
The three figures below represent traditional metrics that capture the innovative progress in ADC design. The first figure plots power
dissipated relative to the Nyquist sampling rate (P/fsnyq), as a function of signal-to-noise and distortion ratio (SNDR), to give a measure of
ADC power efficiency. Note that a lower P/fsnyq metric represents a more efficient circuit on this chart. For low- to medium-resolution
converters, energy is primarily expended to quantize the signal; thus the overall efficiency of this operation is typically measured by the
energy consumed per conversion and quantization step. The dashed trend-line represents a benchmark of 1fJ/conversion-step. Circuit
noise becomes more significant with higher-resolution converters, necessitating a different benchmark proportional to the square of the
signal-to-noise ratio, represented by the solid line. Designs published from 1997 to 2023 are shown in circles. ISSCC 2024 designs are
shown with blue stars and ISSCC 2025 designs are shown with orange stars.
The second figure plots signal fidelity vs. the Nyquist sampling rate normalized to power consumption. At low sampling rates, converters
tend to be limited by thermal and flicker noises, independent of the sample rate. Higher speeds of operation present additional challenges
in maintaining accuracy in an energy-efficient manner, indicated by the roll-off vs. frequency in the dashed line. The last ten years have
resulted in an improvement of over 10dB in power-normalized signal fidelity, or a 10× improvement in speed for the same normalized
signal fidelity. At ISSCC this year, hybrid pipelined-SAR and noise-shaping SARs are continuing the trend in the speed vs efficiency
corner of the graph. Time-based conversion of signal and time-domain quantization are becoming an integral part of converters in scaled
nodes. Time-interleaving multiple channels with error correction over process, voltage and temperature (PVT) as well as clock skew
between channels is a necessity in these architectures to achieve robust performance in high-speed conversion rates.
The final figure plots ADC bandwidth as a function of SNDR. Sampling jitter or aperture errors deteriorate the ADC resolution and signal
bandwidth. In recent years we have seen designs with aperture errors below 100fsrms published at ISSCC.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Figure. 1. Power dissipated relative to the Nyquist sampling rate (P/fsnyq) versus SNDR.
1.E-01
1.E+00
1.E+01
1.E+02
1.E+03
1.E+04
1.E+05
1.E+06
1.E+07
10 20 30 40 50 60 70 80 90 100 110 120
P/fsnyq [pJ]
SNDR @ fin,hf [dB]
ISSCC 2025
ISSCC 2024
ISSCC 1997-2023
VLSI 1997-2024
FOMW=1fJ/conv-step
FOMS=185dB

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Figure. 2. Schreier figure of merit versus Nyquist sampling rate.
120
130
140
150
160
170
180
190
200
1.E+02 1.E+04 1.E+06 1.E+08 1.E+10 1.E+12
FOMS,hf [dB]
fsnyq [Hz]
ISSCC 2025
ISSCC 2024
ISSCC 1997-2023
VLSI 1997-2024
Envelope

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Figure. 3. Input bandwidth versus SNDR.
1.E+06
1.E+07
1.E+08
1.E+09
1.E+10
1.E+11
10 20 30 40 50 60 70 80 90 100 110 120
fin,hf [Hz]
SNDR @ fin,hf [dB]
ISSCC 2025
ISSCC 2024
ISSCC 1997-2023
VLSI 1997-2024
Jitter=1psrms
Jitter=0.1psrms

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
HISTORICAL TRENDS IN TECHNICAL THEMES
COMMUNICATION SYSTEMS
RF SUBCOMMITTEE – WIRELESS SUBCOMMITTEE
WIRELINE SUBCOMMITTEE
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
RF – 2025 Trends
Subcommittee Chair: Brian Ginsburg, Texas Instruments, TX
The RF papers to be presented at ISSCC 2025 demonstrate record-setting advancements in phase-locked loops (PLLs), voltage-
controlled oscillators (VCOs) and multipliers, RF power amplifiers (PAs), low noise amplifiers (LNAs), phase shifters, and transmitters
(TXs). These innovations are driven by emerging requirements in 5G and 6G communications, the Internet of Things (IoT), radars, and
imaging at RF, mm-wave, and THz frequencies. This document provides a highlight of these trends.
Frequency Synthesis: At ISSCC 2025, papers introducing new PLL concepts for generating RF and mm-wave frequency carriers will
be presented. These papers feature concept demonstrations with record-setting achievements in low jitter, low-power consumption, and
settling time. These achievements extend the number of publications with jitter-power FoM below -250dB for both fractional-N and integer-
N PLLs, as shown in Fig. 1.
For instance, a cascaded 4.7-to-5.7GHz fractional-N PLL adds a fractional divider between its two stages. By sharing the DSM of the two
fractional dividers, they are able to cancel their quantization error, achieving 96fsrms jitter, a -70.6dBc fractional spur, and a -247.1dB FoM.
Additionally, a cascaded 5.5GHz fractional-N RO-based digital PLL achieves <290.8fsrms jitter with a 10% variation over PVT and -
237.6dB FoM by utilizing a TVC and ADC to maintain low-quantization-noise phase-noise quantization and voltage-domain feed-forward
noise cancellation. Moreover, a low-voltage 10.4-to-11.8GHz fractional-N PLL achieves 73.8fsrms jitter and -251.3dB FoM by utilizing a
hybrid cascaded DPD to compensate for the INL of a low-voltage DTC and sampling PD. A 10.1GHz fractional-N digital PLL minimizes
DTC static and dynamic delays, exploiting a quantization error compensating BBPD and attains 65fsrms jitter and -252.2dB FoM. Another
fractional-N PLL reaches 38.5fsrms and -254dB FoM by employing a multipath feedback technique based on multiple weighted CP
components and re-timed feedback paths to reduce DSM quantization noise and mitigate in-band noise. Furthermore, a 27GHz fractional-
N subsampling PLL features a polarity-reversible subsampling PD to reduce the DTC range. The automatic TDC gain calibration of the
FLL enables a <2µs locking time. This PLL exhibits 57.9fsrms jitter and -249.7dB FoM.
Two papers target fast-hopping LO generation. One paper describes a 2.25-to-2.54GHz digital PLL-based GFSK modulator that utilizes
an ultra low-power DCO and fast-converging gain estimation to achieve a 2.1% FSK error with a sub-20µs settling time and power
dissipation of only 380µW. The other paper discusses a 53.2-to-64.9GHz SSB-mixer-based integer-N PLL with a <1ns settling time. It
addresses mixer-induced spurs with an injection-locked oscillator filter and background I/Q calibrations, resulting in a -56dBc worst-case
spur level and 60.3fsrms jitter.
Additionally, two PLLs exploit low-PN oscillators to enhance their performance. One PLL uses an adaptive technique to automatically
tune the common-mode resonance of a harmonic-shaping DCO integrated into a 4.75GHz integer-N digital PLL, achieving a 45.8fsrms
jitter and -257dB FoM. The other PLL incorporates a series-resonance oscillator in a 13GHz charge-pump integer-N PLL and, with the
assistance of a time-amplifying PFD and a sampling-based filter for the reference spur, attains 15.8fsrms jitter and -257dB FoM.
One paper discusses the co-designs a PLL and XO. The XO provides a clean reference to the PLL, while the PLL provides injection
timing with a narrow angle for the pulse XO driver. This integer-N PLL operates at 4.6GHz and achieves 63.3fsrms jitter and -255.2dB
FoM, including the XO power and noise.
Additionally, another paper presents an 11-to-16.4GHz FMCW digital PLL that proposes a DPD technique to compensate for the DCO
non-linearity. It achieves a 0.043% rms frequency error under 3.4GHz/μs slope and a 5.32GHz bandwidth.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Fig. 1. PLL trends. The ISSCC 2025 results are identified in red.
Waveform shaping and series-resonator-based oscillators: The ISSCC 2025 will showcase five new contributions to RF and mm-
wave oscillators. This year, three waveform shaping oscillators will be presented. The first is an 18.5-to-23.6GHz quad-core class-F2,3
oscillator, which achieves a peak FoM of 193dBc/Hz and a <250kHz 1/f3 PN corner without 2nd/3rd harmonic manual tuning. The second
oscillator covers a frequency range from 9.05 to 37GHz (121%) and utilizes a new magnetic mode switching to achieve its high tuning
range. It attains >190.7dBc/Hz FoM at a 10MHz offset frequency through a tuning-free octave BW common-mode resonator. The last
oscillator operates within the 47.3-to-58.4GHz range and is a quasi class-E Colpitts oscillator based on a two-port resonator, achieving
a peak FoMT of 198.8dBc/Hz. The remaining two oscillators are both CMOS series-resonator based. One utilizes a mixed-mode resonator
consisting of a series-LC tank magnetically coupled with a parallel-LC tank and a single-inverter active core. This 8.1-to-9.9GHz oscillator
achieves -124 to -128.7dBc/Hz PN at a 1MHz offset frequency while consuming <36.3mW. The other oscillator operates within 7.65-to-
9.13GHz range and is a differential CMOS series-based resonator with a pole convergence technique, reaching -150.5 to -153dBc/Hz
PN and peak FoM of 190dBc/Hz at a 10MHz offset frequency.
Front-End Circuits for High-Performance Transceivers: ISSCC 2025 features eleven new contributions to RF front-end circuits, which
includes two LNA papers, five PA papers, and four TX (including RF DAC) papers. A highly linear 65nm-CMOS 27GHz LNA employing
Doherty active load modulation is presented to improve its blocker tolerance. It achieves minimum NF of 2.5dB and IIP3 of -2.5dBm. A
low-noise active bandpass filter (LNA-BPF) based on a cascode amplifier with a tunable band-stop filter to create the passive feedforward
cancellation is proposed in a 22nm FDX process. It shows the minimum NF of 3.6 to 4.2dB across the 22-to-27GHz band and sharp
filtering characteristics. A PA architecture that combines the merits of Doherty and switchless class-G (SLCG) PAs is proposed in a
250nm GaN process. Over 38% 6dB back-off drain efficiency and 29.1-to-31dBm average output power (Pavg) for a 100MHz 64-QAM
LTE signal are demonstrated over a 1.35-to-7.6GHz frequency range. A VSWR-resilient PA that uses a proposed LC-complex cascode
architecture is presented in a 22nm SOI CMOS technology. It achieves the Pavg of 9.5 and 6.8dBm for50Ω and 4:1 VSWR load
conditions for a 39GHz 100Mbaud 64-QAM signal. Time-modulated PA chain architecture supporting digitally controlled beamforming
with high back-off efficiency is proposed in a 0.18µm SiGe process. It shows the 6dB back-off efficiency of 16% and enables ±30° beam
steering without phase shifters at 24GHz. A 24-to-29GHz Doherty PA using 3-stacked amplifier cores with an operational amplifier (OPA)-
based bias scheme is presented in a 22nm SOI CMOS technology. It achieves 23-to-24.1dBm Psat, 6-to16.8dBm Pavg for 800Mbaud
64-QAM OFDM signal and 1000h temperature reliability. A 56-to-64GHz PA with scalable matched-zone-expanding radial power

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
combining, which uses the combination of voltage and current combining, is presented in 40nm bulk CMOS. The PA demonstrates Psat
of 30.2dBm and OP1dB of 28.9dBm. A 1b digital polar transmitter employing a CORDIC-less polar encoding scheme that converts multibit
I/Q input into a 1b AM and 3b PM signals is proposed in 65nm CMOS. It supports 1.35GHz 50Mbaud 256-QAM modulation with 16.9dBm
output power, 20.2% PAE, and 19.5% system efficiency. A digital 40nm-CMOS PA using an in-cell fast slope-to-phase self-calibration
technique is proposed to improve AM-PM linearity of a switched-capacitor PA (SCPA) operating at high frequency and supporting
modulation signals without DPD. It achieves 27.7dBm peak Pout and 37.8% peak PAE at 4.7GHz and supports 160Mbaud 64-QAM and
80Mbaud 256-QAM signals without DPD. A high-power digital transmitter with dynamic retiming and a glitch-free phase mapper operation
is proposed using 40nm CMOS and LDMOS. Operating at 1.7GHz, the transmitter achieves 43dBm peak output power, 63% peak system
efficiency, and 34.9dBm Pavg with 28.1% system efficiency under 53Mbaud 64-QAM modulation. A 21-to-31GHz reconfigurable
2×8b/2×11b quadrature RFDAC with an impedance-compensation array for invariant impedance and digital pre-modulator for scalable
LO leakage is presented in a 40nm CMOS technology. It supports 2.4Gb/s 256-QAM modulation without DPD. Fig. 2 illustrates Psat vs
frequency trends of other PAs including those that will be presented at the ISSCC 2025.
Components for Beyond 100GHz: ISSCC 2025 introduces several exciting and innovative circuit components operating at D band and
beyond. In particular, two phase shifters at D band, one multiply-by-16 radiation source at 250GHz, one 32 way power amplifier (PA) at
220GHz, and one voltage controlled oscillator (VCO) at 225GHz are showcased. One phase shifter is based on a frequency/switching-
staggered 5-stage reflective-type phase shifter and achieves bi-directional and calibration-free 360° phase shifting in a 110-to-140GHz
band. The phase shifter is implemented in 22nm CMOS SOI and shows 11.25° phase resolution with rms phase and gain errors of 0.64°
to -2.38° and 0.12dB to 0.63dB across the band, respectively. Another phase shifter achieves a maximum output power at 1dB gain
compression (OP1dB) of 3.5dBm at 130GHz by eliminating the variable-gain amplifier (VGA) and replacing it with phase shifters for gain
and phase calibration. This work was implemented in 55nm SiGe and shows 360° phase control in 9° steps across 125 to 170GHz. The
multiply-by-16 radiation source takes advantage of a patterned dielectric matching sheet installed at the back of the chip to enhance the
wave coupling from silicon to air and to replace a silicon lens with a low-cost and planar alternative. This radiator is implemented in 16nm
FinFET CMOS and operates from 232 to 260GHz with a peak radiation power and equivalent isotropic radiated power (EIRP) of 11.1dBm
and 24.5dBm, respectively. A varactor-less VCO is presented that uses multiple coupled line resonators along with switches to improve
the tuning range at 224GHz. The VCO is implemented in 22nm FDSOI and achieves 19.9% tuning range with peak FoMT of -182dBc/Hz.
Finally, large-signal impedance correction is used in a 50nm GaN HEMPT PA to achieve 1350mW/mm power density at 216GHz. This
individual PA is packaged and 32 of them are combined to generate >1W of power at 216 to 226GHz.
Fig. 2. PA trends.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Wireless – 2025 Trends
Subcommittee Chair: Chih-Ming Hung, MediaTek, Taipei, Taiwan
The persistent demands for high data throughput and low power consumption continue to drive the development of wireless integrated
transceivers. The crowded frequency spectrum further motivates interference-tolerant receivers. This year at ISSCC 2025, several
transmitter and receiver papers were selected to showcase the advancements in wireless systems across a wide range of applications,
including LTE, UWB, mm-Wave, and D-band frequency ranges. The key development includes:
1. Towards 6G communication systems: Increasing operation frequency and high-speed data transfer
Communication transceivers for 6G are designed to operate at higher frequencies with a wider bandwidth, such as those in the
frequency range 3 (FR3, 7 to 24GHz), millimeter-wave frequency (30 to 300 GHz) and even terahertz bands, which allow for ultra-
fast data transmission (up to 1 Tb/s) and ultra-low latency. According to the published papers this year, designs for wireless
communication transceivers and relays targeting 6G communication represent a significant portion of the total publications. On
Tuesday, a 29GHz satellite-communication phased-array receiver is presented, achieving a data rate up to 16Gb/s with two circular
polarization beams. Additionally, a D-band active relay transceiver was highlighted for its capability to perform 2-D angle-of-arrival
detection, demonstrating data rates of up to 6Gb/s for none-line-of-sight communication. Figure 1 demonstrates a visual
representation of the trends for data rates accomplished from millimeter-wave to sub-terahertz frequency.
Figure 1: Data-rate trend of mm-wave and sub-THz wireless transmitters and receivers.
2. FMCW radar: Increasing frequency, resolution and range
In the past few years, many 24GHz FMCW radars have been developed for sensing and imaging. These systems typically use single
PLLs to synthesize frequency. In the mm-wave range, 76-to-81GHz FMCW radars are widely used for vehicle distance sensing and
SLAM. These systems often feature frequency synthesizers that use PLLs with multipliers. In recent years, FMCW radar systems
are advancing into sub-THz range, offering expanded bandwidths of tens of GHz, which improve range resolution to the millimeter
level. Achieving such high frequencies often requires long frequency up-conversion chains. Multi-band approaches are also

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
proposed to enhance bandwidth. Figure 2 illustrates a clear trend, showing a general improvement in resolution from cm-level to
mm-level across the FMCW radar at different bands.
Figure 2: Radar resolution trend of mm-wave and sub-THz FMCW radar transceivers.
24GHz and 77GHz mm-wave radars have achieved transmission distances up to 100 meters. However, sub-THz radar systems
face significant propagation losses, around 28dB/m or more, limiting communication to less than 1 meter. Extending sub-THz
transmission ranges has become a key focus, with high-directivity antennas or arrays being a crucial solution. Recent designs using
AiP technology in D-band phased-array transceivers have shown promise. The accepted ISSCC 2025 paper highlighted in Figure 2
presents a D-band FMCW radar transceiver Antenna in Package (AiP), achieving a transmission range of 16.8 meters, which is one
of the largest values in D-band design, although the demonstrated range resolution is only 13mm.
3. Wide bandwidth, multiband receiver: low power, high linearity, and high blocker tolerance.
In recent years, wide-bandwidth (WB) receivers covering multiple communication protocols have garnered significant attention in
wireless design. These WB receivers not only provide a compact solution for a wide variety of applications but also reduce the overall
complexity of transceiver architecture, becoming the cornerstone of software-defined radio systems. However, the inevitable
presence of jammers imposes significant design challenges on the linearity and blocking tolerance of WB receivers. Figure 3 presents
how in-band IIP3 advanced with increasing receiver bandwidth. In ISSCC 2025, several notable advancements are presented:
● A 0.5-to-3GHz LNTA-based receiver achieving an adjacent IIP3 of 19dBm.
● A 31-to-34GHz mixer-first receiver utilizing a non-uniform time-approximation filter to achieve >65dB blocking rejection.
● A 0.5-to-5GHz full-duplex receiver employing multi-stage all-pass filters (APFs) to achieve >65dB self-interference cancellation
(SIC) for bandwidths greater than 120MHz.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Figure 3: Trend of Receiver IIP3 vs Bandwidth for Papers Published at ISSCC.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Wireline – 2025 Trends
Subcommittee Chair: Thomas Toifl, Cisco System, Thalwil, Switzerland
Ever-increasing bandwidth and performance demands, accelerated by the extensive deployment of AI/ML workloads, are straining
the capabilities of today’s electrical and optical interconnect solutions. To meet the performance needs of applications ranging from
telecommunication networks, to datacenters, to mobile devices, electrical and optical interconnect solutions with higher throughput
and energy efficiency are required. To keep pace, Figure 1 shows that the data rates per pin double almost every 3-4 years across
different IO standards. Figure 2 illustrates the data rates for published transceivers versus process nodes. While taking advantage
of process scaling, designing energy-efficient interconnects with 100-200+ Gb/s data rates face steep challenges of channel loss,
reflection, xtalk and noise. Figure 3 shows energy efficiency vs. channel loss of up to 52dB at the Nyquist frequency. Significant
innovations in energy-efficient analog and digital equalization, xtalk/noise cancellation, low-jitter clocking techniques, heterogeneous,
chiplet-based and co-packaged integration are made to meet the exponential bandwidth growth need.
Papers presented at ISSCC this year include examples of 212.5Gb/s wireline transceivers with 50dB and > 46dB loss compensation
capabilities, an XSR analog RX operating at 224Gb/s, a 212Gb/s re-timer for optical communication and a 32Gb/s 10.5Tb/s/mm
UCIe compliant interface:
1. A 212.5Gb/s DSP-Based PAM-4 Transceiver with 50dB Loss Compensation for Large AI Systems Interconnects in 4nm FinFET.
2. A 2.2pJ/b 212.5Gb/s PAM-4 Transceiver with > 46dB reach in 5nm FinFET.
3. A 1.11pJ/b 224Gb/s XSR Receiver with Slice-Based CTLE and PI-Based Clock Generator in 12nm CMOS.
4. A 353mW 112Gb/s Discrete Multi-tone Wireline Receiver Datapath with Time-Based ADC in 5nm FinFET.
5. A 212Gb/s PAM-4 Retimer with Integrated High-Swing Optical Driver and Chip-to-Module Long Reach Capability of 40dB in
5nm FinFET.
6. A 0.9pJ/b 108Gb/s PAM4 VCSEL-Based Direct-Drive Optical Engine.
7. A 112Gb/s 0.61pJ/b PAM-4 Linear TIA Supporting Extended PD-TIA Reach in 28nm CMOS.
8. A 1.54pJ/b 64Gb/s 16-QAM Intradyne Coherent Optical Receiver in 28nm CMOS.
9. A 50Gb/s Burst-Mode NRZ Receiver with 5-Tap FFE, 7-Tap DFE and 15ns Lock Time in 28nm CMOS for Symmetric 50G-PON.
10. An 8-28GHz 8-Phase Clock Generator using Dual-Feedback Ring Oscillator in 28nm CMOS.
Ultra-High-Speed Wireline and High-Performance Clocking Techniques
With explosive bandwidth demand of data-intensive applications such as artificial intelligence (AI) and high-performance computing
(HPC), 100Gb/s/lane interconnects are transitioning to 200Gb/s/lane to enable 1.6Tb/s Ethernet. Design innovations in equalization
techniques, multi-phase low-jitter clock generation, clock and data recovery (CDR), employing various modulation schemes such as
pulse amplitude modulation (PAM) and discrete multitone (DMT) are imperative to achieve such aggressive data rates with
competitive energy and area efficiency. In Paper 7.1, MediaTek presents a complete DSP-based PAM-4 transceiver at 212.5Gb/s,
implemented in 4nm FinFET and achieved <1e-10 and 2.5e-6 BER over a channel loss of 40 and 50.5dB, respectively. The energy
efficiency of transceiver is 5.3 pJ/b with 1.8pJ/b from DSP. A jitter-cleanup PLL (JCPLL) generates a clean, low-frequency reference
clock to 20-28GHz LC VCO which employs a high-Q inductor and second-harmonic LC filter achieve low phase noise performance.
The entire receiver clocking path is filtered by an LDO with noise canceling path. In Paper 7.2, Marvell demonstrates a 212.5Gb/s
transceiver with analog energy efficiency of 2.2pJ/b and loss compensation of 46dB, fabricated in 5nm FinFET technology. The
current mode transmitter shows an SNDR of 36.1dB and an RMS jitter of 73fs at a 212.5Gb/s data rate. In Paper 7.3, Peking
University presents a 224Gb/s XSR receiver (RX) in 12nm CMOS technology. The RX design, featuring a slice-based CTLE with a
3dB bandwidth of 59GHz, demonstrates a BER of 8.1e-7 over a 13.6dB channel loss with an energy efficiency of 1.11pJ/b. In Paper
7.5, Daegu Gyeongbuk Institute of Science and Technology demonstrates a 112Gb/s ADC-based DMT wireline RX in 5nm FinFET
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
with 1e-4 BER for 12dB channel loss at 26GHz. The DSP equalizes DMT symbols that are independently bit- and power-loaded
over 63 sub-channels to fit the channel SNR profile.
Low-jitter multi-phase clock generators and CDRs with fast lock time are key building blocks of wireline transceivers. In Paper 7.7,
Peking University presents an analog 50Gb/s burst-mode NRZ receiver in 28nm CMOS for symmetric 50G-passive optical network
(PON) applications. An edge equalization is introduced to enhance lock accuracy under large ISI and poor SNR, achieving a
maximum lock time of 15ns. In Paper 7.10, Fudan University reports an 8-phase 8-to-28GHz clock generator comprising a dual-
feedback ring oscillator injection locked by a delay locked loop. Fabricated in a 28nm CMOS process, the clock generator output
jitter and the maximum phase error are measured less than 40fs and less than 3°, respectively.
.
Ultra-High-Density Die-to-Die Interconnects
AI/ML-driven growth in computing performance has accelerated system disaggregation into chiplets using organic or advanced
packaging technologies (2D/2.5D/3D). The UCIe (Universal Chiplet Interconnect Express) has been developed to standardize chiplet
interconnects on a package and targets high energy efficiency and high bandwidth density with low latency. In Paper 36.1, TSMC
presents a 32Gb/s/pin UCIe-compliant advanced package D2D interconnect, connected via a 1.7mm silicon bridge. Fabricated in
3nm FinFET technology, each module, comprising 64 transmitter and 64 receiver lanes, achieves 10.5Tb/s/mm beachfront
bandwidth density at 0.6pJ/b. In paper 36.2, Peking University reports a 64Gb/s/wire single-ended simultaneous bi-directional
transceiver for D2D interconnects. A dynamic voltage threshold circuit decouples the bi-directional signal and cancels the crosstalk.
A synchronous clock and reset distribution network ensure precise crosstalk cancellation. Implemented in 28nm CMOS, the
transceiver measures 10.5Tb/s/mm beachfront bandwidth density at 1.21pJ/b and BER of less than 1e-16 on a 3mm shield-less on-
chip channel. In paper 36.3, Cadence demonstrates a 4-16Gbps/pin UCIe 2.5D over 1.4mm interposer D2D interconnect, achieving
5.27Tb/s/mm at 0.29pJ/b in 3nm FinFET. By running 8.192Tb/s of data traffic on 8 links, a 0.29UI eye opening at 1e-15 BER for
16Gb/s/pin is measured. The PHY latency is measured to be 3.5ns.
Ultra-High-Speed Optical Interconnects
As interconnect data rates continue to increase in support of rapidly increasing demand for higher bandwidth in hyperscale
datacenters, the reach of electrical interconnects is becoming shorter, despite significant recent advancements. Datacenter
interconnects combine direct-attach copper cables for intra-rack connectivity, pluggable optical modules for reach longer than a few
meters and coherent optical transceivers for long-haul telecommunication applications. Co-packaged optics (CPO) can address the
electrical interconnect scalability and reach/power bottleneck by closely integrating optical components with a computing system. In
Paper 36.4, Intel presents a 108Gb/s PAM-4 VCSEL-based direct-drive optical engine targeting CPO applications, achieving 0.9pJ/b
and 2.4e-4 BER. A VCSEL driver with linear complex-zero CTLE and a linear differential TIA with an active complex-zero CTLE,
fabricated in 22nm FinFET, are introduced to enable >100Gb/s PAM-4 operation. In Paper 36.5, Southern University of Science and
Technology reports a 112Gb/s PAM-4 TIA in 28nm CMOS, featuring a regulated active-input-termination and interpolation-based
single-ended-to-differential (S2D) converter, that achieves a long 0.2inch PD-TIA reach at 0.61pJ/b. In Paper 36. 7, University of
Illinois at Urbana-Champaign demonstrates a QAM-16 analog coherent receiver, fabricated in 28nm CMOS, which recovers 64Gb/s
data at 1.54pJ/b with a BER better than 1e-10. By using the weighted sum of phase errors extracted from the inner and outer symbols
of the QAM-16 constellation, the phase detector range is extended, and transition density is doubled, enabling a robust carrier phase
recovery. In Paper 36.9, Marvell presents a 212Gb/s PAM-4 re-timer with the integrated optical driver at 4.4pJ/b and chip-to-module
(C2M) capability of 40dB loss compensation at 2.76pJ/b, fabricated in 5nm FinFET technology. The optical driver achieves a swing
of 3Vppd with a bandwidth of 54GHz and a TDECQ of 2.04dB when driving a Mach-Zehnder Modulator. The C2M interface has a
measured BER of 1.8e-10 over a 40dB-loss channel.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Concluding Remarks:
As aggressive bandwidth scaling of wireline interconnects continues, meeting system power, cost, reliability and thermal budget
become extremely challenging. Relentless innovations in systems, circuit architectures and integrated photonics as well as advances
in packaging, interconnect topologies, and process scaling play a pivotal role in overcoming the limitations and pushing the
boundaries beyond today’s interconnects. ISSCC 2025 will highlight the most promising of these emerging technologies for electrical
and optical interconnects.
Figure 1: Per-lane data rate vs. year for a variety of common I/O standards.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Figure 2: Data-rate vs. process node and year.
1
10
100
1000
110 100
Data Rate [Gbps]
Process Node [nm]
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018
2019
2020
2021
2022
2023
2024
2025

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Figure 3: Power efficiency vs. channel loss and year.
0.10
1.00
10.00
100.00
1000.00
020 40 60
Power Efficiency [mW/Gbps]
Channel Loss at Nyquist [dB]
Other
ISSCC 2025

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
HISTORICAL TRENDS IN TECHNICAL THEMES
DIGITAL SYSTEMS
DIGITAL ARCHITECTURES & SYSTEMS SUBCOMMITTEE
DIGITAL CIRCUITS SUBCOMMITTEE
MEMORY SUBCOMMITTEE
SECURITY SUBCOMMITTEE

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Digital Architectures & Systems (DAS) – 2025 Trends
Subcommittee Chair: Rahul Rao, IBM, Bangalore, India
This year continued the trend of fewer dies in more stable packaging. Chiplet-based disaggregation continues to help keep down costs
through yield improvements. Technology scaling packed more transistors within the same die area and microarchitectural improvements
ensured those transistors translated to gains in instruction per cycle (IPC) and accelerating AI workloads. Total cache sizes continue to
increase from SRAM density improvements, further lifting application-level performance. Robustness and reliability in processors is
improved through metal capacitor short detection, cache RAID protection, and fine-grained self-healing of memories. An emphasis on
I/O and data processing units is also seen in this year's papers increasing throughput for network and edge server use cases.
Figure 1: Core-count and die-count trends (red diamond designates multi-chip module).
Figure 2: Chip-complexity scaling trends in terms of transistor count and total cache-size (red diamond designates multi-chip module).
Edge computing saw an increased focus on AI for video applications, including multiple papers on super resolution (SR) for low-
bandwidth, high-resolution streaming applications and Gaussian splatting for real-time immersive experiences. While super resolution is
not new for this year, there is continued focus in pushing SR energy efficiency to achieve high resolution and frames-per-second, while
maintaining low bandwidth usage. Real-time photorealistic rendering in Gaussian splatting processors also made a strong appearance
this year. Together, both technologies make strides towards real-time video in virtual and augmented reality, embodied AI, and immersive
display applications. Finally, safety of autonomous vehicle and robotics applications is improved at edge through small-object detection
in high-resolution videos.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Figure 3: Application-processor trends in handheld devices.
With deep neural networks (DNNs) now extensively deployed across a wide range of application domains and market segments, including
wearables, mobile devices, edge and servers, DNN models are also continuously evolving to meet diverse application demands. These
DNN models vary significantly in size and computational complexity, creating a growing demand for highly efficient and high-performance
neural-network computing chips. The recent trend toward focusing on machine-learning accelerators for applications such as rendering,
robotics, and image generation continues to evolve, expanding the range of model architectures, including convolutional neural networks,
transformers, diffusion models, and spiking neural networks (SNNs) as shown in Figure 4.
Hardware accelerators provide critical optimizations that balance energy efficiency, performance, and accuracy across various DNNs.
Key system-level metrics remain energy-per-inference (or per-training-example), inferences/second (or training-examples/s), utilization,
and operations per mm² on a specific task at a given inference (or final trained) accuracy for both dense and sparse levels of sparsity.
With the rise of generative AI, accelerators are adapting to meet the growing computational demands of tasks like image generation and
large language models. These workloads require efficient memory handling and high computational throughput, driving advancements
in hardware designs aimed at improving overall efficiency while maintaining accuracy. A major focus this year is on reducing external
memory access (EMA), a key factor in improving both performance and energy efficiency, particularly for large models such as
transformers used in generative AI. Techniques like model compression and on-chip memory enhancements have become essential in
minimizing EMA-related bottlenecks.
Figure 4: Various parameters impacting low-level and system-level benchmarking metrics.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
At ISSCC, several key emerging trends in machine learning and AI are shaping the landscape:
1. Energy Efficiency and Performance: A major focus this year is on improving energy efficiency across various machine learning
tasks, particularly in generative AI and large models like transformers. Metrics such as energy per inference and inferences per
second remain central to evaluating accelerators, with this year’s designs pushing the boundaries of efficiency through
techniques like optimized scheduling, depth-first processing, and compute-memory integration. These improvements allow
hardware to handle increasingly complex models while keeping energy consumption low, driving better performance at reduced
power levels.
2. Memory Efficiency and Model Compression: As model sizes grow, reducing external memory access (EMA) has become
more critical than ever. This year’s papers showcase significant advancements in algorithmic model compression and memory-
efficient designs. Techniques like quantization—specifically binary and ternary—and optimized bit allocation are helping to
minimize EMA, leading to lower energy consumption and more efficient memory usage. These strategies are essential for
managing the high data throughput required by large-scale applications like generative AI.
3. Domain-Specific and Hybrid Accelerators: Tailored, domain-specific accelerators are increasingly being used for applications
ranging from real-time processing to 3D point-cloud analysis. This year’s designs emphasize hybrid architectures that combine
multiple model types, such as CNNs and transformers, to optimize both performance and energy efficiency. Techniques like
layer fusion, hybrid attention mechanisms, and task-specific pruning are enabling these accelerators to handle the diverse
computational needs of modern machine learning workloads effectively.
4. Exploiting Sparsity and Hardware-Software Co-Design: Sparsity exploitation continues to be a key method for reducing
computational complexity and improving efficiency. This year’s designs leverage sparsity-aware techniques, such as
binary/ternary quantization and look-up tables, to avoid unnecessary computations. Hardware-software co-design is also
becoming more prevalent, allowing accelerators to optimize data flow and memory use in an integrated manner, resulting in
highly efficient processing across various tasks.
Figure 5: Heterogeneity in deep-learning accelerators.
Integer
Floating-point
Logarithmic
Custom Arbitrary Bases
Mixed-Precision
Digital CMOS
Compute-In-Memory
(SRAM, RRAM, eDRAM)
Analog/Mixed signal
CNN core
RNN core
Depthwise-Separable core
Transformer core
Heterogeneous
SoC
Sparse accelerator
Dense accelerator

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
With the increased diversity in machine-learning accelerators aimed at different applications and sparsity, a fair comparison across these
designs for true system-level benchmarking metrics (e.g. energy/inference or inferences/s) is challenging. Hence, we look at reported
metrics of operations/s and energy/operation within the neural network where possible. Figure 6 plots the evolution of both energy
efficiency and area efficiency (throughput-per-unit-area) over the past few years. Though it is difficult to draw definitive trends from these
graphs, it does indicate a drive towards higher efficiency at higher bit-precisions. It should be noted that these metrics (TOPS/W and
TOPS) are highly dependent on the topology being used, and the sparsity of the associated data set. While attempts have been made
to establish a benchmarking methodology that can properly account for the application context [1], its adoption has been limited. In the
meantime, clever combinations of sparsity, variable precision and in-memory computing technologies are continuing to enhance deep-
learning processor efficiency and throughput.
Figure 6: Evolution in energy efficiency (TOPS/W) and throughput per unit area (TOPS/mm2) of ML inference processors.
[1] G. W. Burr, S. Lim, B. Murmann, R. Venkatesan and M. Verhelst, "Fair and Comprehensive Benchmarking of Machine
Learning Processing Chips," in IEEE Design & Test, vol. 39, no. 3, pp. 18-27, 2022.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Digital Circuits – 2025 Trends
Subcommittee Chair: Huichu Liu, Meta, Sunnyvale, CA
The escalating demand for energy-efficient platforms, from low-power wake-up sensors to AI accelerators, is fueling ongoing innovations
in CMOS digital design. This year's ISSCC papers demonstrate continued progress in addressing key trends, including the need for co-
optimized design and technology, overcoming memory bottlenecks in large language model accelerators, and expanding silicon
technology into novel form factors like textiles. Additionally, the conference highlighted advancements in clocking, power management,
3D heterogeneous integration, and the growing use of runtime regression and machine learning techniques in digital circuits.
Digital Clocking Circuits for Low-Jitter Applications: Large multi-domain SoCs require efficient generation of multiple clock domains
capable of low-voltage operation, and fine-grained output frequency control with low jitter. Figure 1 presents the trade-off between power
and jitter captured into a composite figure of merit (FoM) for different types of clock generators. Frequency output dividers (FODs)
continue to grow in popularity, each producing fractional clock frequencies from a single high-frequency clock source. Digital-to-time
converters have been used to minimize spurious tones (spurs) created by reference sampling or fractional division in multi-modulus
dividers, and this year’s ISSCC publications continue this trend. Circuit imperfections the form of gain and integral non-linearity (INL) are
suppressed, reducing spurs while maintaining energy efficiency and realizing competitive FoMs (Figure 2).
Figure 1. Advances in pareto-optimal performance between jitter and power in digital clock generators
along with key figure of merit (FoM) across recent years, defined as: FoM = 10 log10{ (JitterRMS/1s)² (Power/1mW) },
showing fractional ratio clock sources now reaching the same performance as integer ratio clock sources.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Figure 2. Joint improvement of spur rejection and FoM in recent digital clock generators:
spur suppression is becoming the main challenge to improve jitter and reduce FoM.
Integrated voltage regulators (VRs) and power-delivery designs: The relentless pursuit of power-constrained performance in scaled
technologies has intensified challenges in power delivery and point-of load voltage regulation. Supply noise and VR transient response
remain significant contributors to system inefficiency. Moreover, 3D integration introduces additional constraints on power distribution
networks (PDNs) and decoupling capacitance resources. To address these challenges, this year's ISSCC papers showcase control
techniques aimed at enhancing transient response and simplifying control of increasingly complex multi-domain hierarchical power
delivery architectures. Run-time control for power management continues to gain widespread adoption. Notable techniques include
adjustment of supply voltage and droop mitigation thresholds at run time, and reconfigurable VR fabrics to enable more energy efficient
dynamic voltage and frequency scaling (DVFS). Power management systems that rely on run-time load-current sensing to ensure load
current compliance are also reported.
Advances in digital circuits for 3D heterogeneous integration (3DHI): 3DHI is driving the need for solutions offering modular system
construction addressing a diverse range of needs in I/O, power delivery and memory bandwidth. The more complex and challenging
thermal environment resulting from 3DHI is expected to require effective, scalable thermal management solutions to maximize system
performance without compromising reliability. This year’s papers describe compact, DVFS friendly thermal sensors, thermal profiling
measurements, and active interposers targeted toward enabling increasingly modular 3DHI construction.
Widening use of regression and ML to augment circuit capabilities: As circuit design challenges continue to mount with each
technology node, a notable trend reflected in this year’s ISSCC papers is a growing adoption of regression and ML based techniques to
augment circuit techniques to improve area, power and performance while reducing circuit complexity. This year’s papers demonstrate
the use of these techniques for more compact, scalable thermal sensors, and load-current sensors to enable more efficient system-wide
power management.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Memory – 2025 Trends
Subcommittee Chair: Meng-Feng Chang, National Tsing Hua University
The demand for high-speed, high-density, and low-energy memory systems is rapidly growing due to developments in deep-learning (DL)
and machine-learning (ML) artificial intelligence (AI). Furthermore, the role of embedded memories and compute-in-memory (CIM) is
becoming increasingly significant in high-performance systems.
This year, the highest-density 64Gb DDR4, based on STT-MRAM, is introduced. Two 1Tb 3b/cell 3D-NAND-Flash memories are
demonstrated: with the highest density based on 4xx-layer, improvements to read energy efficiency, and a 4.8 and 5.6Gb/s/pin IO speed.
The first 24Gb GDDR7 achieves a 42.5Gb/s/pin IO speed with a dual-emphasis TX. A 38Mb/mm2 dual-rail SRAM in 3nm-FinFET
technology and a 37.9Mb/mm2 SRAM in a 2nm CMOS-nanosheet technology are introduced. A 16nm 216kb microscaling, integer or
floating-point multi-mode gain-cell CIM macro demonstrates a power-efficiency improvement.
TOP PAPERS FROM ISSCC 2025 INCLUDE:
● A 16Gb 12.7Gb/s/pin LPDDR5-Ultra-Pro DRAM with 4-Phase Self-Calibration and AC-Coupled Transceiver Equalization in a
5th-Generation 10nm DRAM Process
● A 28Gb/mm2 4XX-Layer 1Tb 3b/cell WF-Bonding 3D-NAND Flash with 5.6Gb/s/pin IOs
● A 24Gb 42.5Gb/s GDDR7 DRAM with Low-Power-WCK Distribution, an RC-Optimized Dual-Emphasis TX, and Voltage/Time-
Margin-Enhanced Power Reduction
● A 1Tb 3b/cell 3D-Flash Memory with a 29%-Improved-Energy-Efficiency Read Operation and 4.8Gb/s Power-Isolated Low-
Tapped-Termination IOs
● 0.021μm2 High-Density SRAM in Intel 18A RibbonFET Technology with PowerVia-Backside Power Delivery
● A 38.1Mb/mm2 SRAM in a 2nm-CMOS-Nanosheet Technology for High-Density and Energy-Efficient Compute
● A 16nm 216kb, 188.4TOPS/W and 133.5TFLOPS/W Microscaling Multi-Mode Gain-Cell CIM Macro for Edge-AI Device
SRAM
Static random-access memory (SRAM) continues to be the predominant on-die memory technology and a critical component of modern
system-on-chip (SoC) designs. The continued pursuit for high-performance and energy-efficient computing fuels advancements in both
semiconductor technology and design. This session showcases the latest developments in embedded SRAM and TCAM designs, as
well as the industry’s 1st 6-transistor (6T) SRAM implementations in sub-2nm gate-all-around (GAA) CMOS technology, including
backside power delivery with PowerVia technology.
COMPUTE IN MEMORY
Memory access is a major bottleneck to system performance and energy consumption for traditional von Neumann system architectures.
A compute-in-memory (CIM) architecture eliminates this bottleneck by bringing the compute operations into the memory array; thereby,
reducing memory-access latencies and data-movement overhead. Innovations in CIM designs continue to improve energy and area
efficiencies, while maintaining AI network accuracy. Developments in gain-cell, SRAM, and non-volatile CIM are shown. Featured
innovations include the 1st demonstration of a microscaling data format and an STT-MRAM based Bayesian neural network.
HIGH-SPEED AND HIGH-DENSITY DRAM
In recent years, AI developments have accelerated demand for high-speed and high-density memories. This year, the 2nd generation of
GDDR7 is demonstrated. The first 24Gb graphic DRAM achieves up to 42.5Gb/s/pin, the highest per-pin speed, and also achieves the
highest GDDR density. Also, a 12.7Gbp/s/pin LPDDR5x achieves the highest per-pin speed with the help of self-calibrated clocks, and
AC equalization for both TX and RX.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Figure 1 - DRAM data bandwidth growth

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
NON-VOLATILE MEMORY (NVM)
In the past decade, significant investment has been put into emerging memories to find an alternative to floating-gate memory. Emerging
NVMs, such as magnetic spin-torque-transfer (STT-MRAM), are showing potential to achieve a high-cycling capability and lower power-
per-bit read/write operations.
Conventional Flash memories are continuously improving, in terms of performance and their cost/bit, confirming them as today’s
mainstream non-volatile memory; however, emerging NVMs are becoming very important as embedded memories for MCUs, IoT devices,
SRAM-like applications, and some aspects of AI.
Figure 2 shows the non-volatile memory capacity trend.
Figure 2 - Non-volatile memory capacity trend.
NAND FLASH MEMORY
NAND Flash memories continue to advance towards higher density, higher performance and lower power; resulting in low-cost storage
solutions that are replacing traditional magnetic hard-disk storage with solid-state disks (SSDs). The 3D-memory technology is the
mainstream for mass-produced NAND Flash memory by semiconductor industries. Periphery-under-the-array is the reference
architecture for TLC and QLC to enable high bit density and multiple planes to improve throughput: TLC is focused on performance
improvement, while QLC is focused on bit-density improvement. However, new advanced architectures for CMOS directly bonded to
array (CBA) have emerged, with the added benefit of further optimizing the memory array and CMOS peripheral circuitry for improved
cell performance and IO speed. The industry continues to invest in Flash memories to improve their performance and bit density; funding
is expected to continue for the next few years.
This year’s papers report improvements in read and write performance, as well as the highest (5.6Gb/s) IO speed for a 3D-TLC-Flash
memory utilizing the CBA wafer-bonding technology. Also reported is the highest density (2Tb) QLC with a 6-plane architecture.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Figure 3 shows the ISSCC reported trends in NAND Flash memory density for the past 25 years.
Figure 3 - 25-year NAND Flash memory density trend.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Security – 2025 Trends
Subcommittee Chair: Ingrid Verbauwhede, KU Leuven, Leuven, Belgium
The increasingly connected nature of embedded systems and the ever-increasing risk of cyber-attacks, continues to make hardware
security a must-have feature. ISSCC features state-of-art implementations of circuit techniques that form the basis of security guarantees
that are required by these systems. The work presented builds on three themes. First, we have cost-effective and robust root-of-trust
circuits such as PUFs (physically unclonable functions) and TRNGs (true random-number generators). These circuits, when integrated
into larger SoCs, underpin critical operations like secret key generation. Next, we continue to have innovative cryptographic accelerator
designs that implement the latest algorithms such as post-quantum cryptography and homomorphic encryption. These designs provide
an early look at the technology required to keep us safe multiple decades into the future. Finally, techniques to counteract sophisticated
physical attacks are being integrated into work presented at the conference providing a glimpse of how hardened designs can achieve
higher levels of security with modest increases in cost and complexity.
More specifically, this year’s selection of security papers highlights a mix of the most advanced security techniques implemented in
hardware. Innovative low-overhead circuit techniques are presented for detection of physical attacks such as laser voltage probing and
clock glitching. Next-generation cryptographic accelerator designs are presented which include fully homomorphic encryption and secure
multi-party computation processors. PUF implementations with very low bit error rates are demonstrated in advanced CMOS nodes,
including experimental evaluations as well as theoretical modeling to build more confidence in the underlying security claims.
Figure 1: Security Trends
Figure 1 contextualizes this year’s contributions against the overall landscape of security innovations presented at ISSCC over the past
years. We see a clear trend toward designs in advanced nodes as well as an increase in the rigor of the designs presented. Cryptographic
accelerators have increased in completeness and this year’s designs continue the trend of more sophisticated processors implementing
new algorithms. Finally, we see a continuation of the trend in implementation of more comprehensive countermeasures against a diverse
set of physical attacks.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
HISTORICAL TRENDS IN TECHNICAL THEMES
INNOVATIVE TOPICS
IMAGERS/MEDICAL/DISPLAYS SUBCOMMITTEE
TECHNOLOGY DIRECTIONS SUBCOMMITTEE

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
IMD – 2025 Trends (Medical)
Subcommittee Chair: Rikky Muller, University of California, Berkeley, CA
The future of biomedical technology lies in integrating secure, efficient, and adaptable systems that push the boundaries of signal quality,
device sustainability, and therapeutic potential. These cutting-edge systems promise significant impacts in both medical and scientific
domains, enabling safer, more precise, and robust applications that seamlessly blend into human life.
Key advances in wireless power transfer (WPT) and data communication, particularly for biomedical applications like miniaturized
implants, include frequency-splitting, current-mode power reception, and resonance-based WPT to achieve high efficiency. These
systems dynamically adapt to orientations and positions, maximizing power extraction and extending device life for deep-tissue and multi-
implant applications.
In neural and brain-machine interfaces (BMI), progress in data rate and energy efficiency supports demanding applications like speech
decoding and neural signal processing. New processors enable rapid, energy-efficient decoding, while event-based neural interfaces and
high-channel spike-sorting chips enhance artifact tolerance and scalability. These improvements are essential for applications requiring
extensive neural data from large groups of neurons.
Wearable and implantable healthcare devices are benefiting from enhanced bio-signal processing and bioimpedance spectroscopy,
emphasizing low power and efficient data handling. Advances in photoacoustic and bioimpedance systems improve data acquisition and
compression through innovative ADC and sampling methods, achieving high signal-to-noise ratios and minimal power consumption—
ideal for compact, continuous health monitoring.
Security and robustness are central, with solutions like mechanical-input-based two-factor authentication (2FA) for implants, offering
protection against unauthorized access. Adaptive power management and noise-efficient architectures ensure consistent performance
across varied tissue interfaces, which is crucial for reliable operation in interconnected and data-intensive medical implants.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
IMD – 2025 Trends (Imagers)
Subcommittee Chair: Rikky Muller, University of California, Berkeley, CA
Image sensor technology is evolving rapidly, driven by the demand for higher resolution, dynamic range, and power efficiency. One key
development is the emergence of hybrid-shutter CMOS sensors, which combine rolling and global shutter modes to offer flexibility for
different imaging scenarios. These sensors are designed for high-dynamic-range imaging, delivering superior performance with minimal
power consumption. In parallel, pixel-parallel ADC architectures are becoming more prominent, particularly in global-shutter image
sensors for consumer and professional applications like cameras, AR/VR, and infrared imaging. These innovations enable high-speed
image capture, reduced random noise, and enhanced sensitivity, ensuring that high-quality visual capture remains at the forefront of
imaging technology.
LiDAR systems, particularly those using SPAD-based time-of-flight (ToF) sensors, are also experiencing breakthroughs. These sensors
are excelling in low-light performance and are highly resilient to background light, making them ideal for precise depth sensing in
autonomous vehicles, robotics, and industrial applications. New architectures are focusing on power efficiency and data optimization,
with techniques like edge-guided depth sensing that selectively activate 3D detection, significantly reducing data bottlenecks. Additionally,
dynamic frame rate adjustments based on signal-to-noise ratios allow these systems to adapt to varying conditions, extending their range
and precision while minimizing power consumption.
Beyond image sensors and LiDAR, long-wavelength infrared (LW-IR) imaging is also benefiting from innovations in low-power, high-
sensitivity architectures. These advancements are particularly relevant for scientific and defense applications, where thermal imaging
requires both high precision and efficiency. The use of pixel-parallel ADC architectures in these systems is enabling accurate, low-noise
imaging while keeping power consumption low, making them suitable for a range of high-performance, mission-critical applications.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
IMD – 2025 Trends (Displays)
Subcommittee Chair: Rikky Muller, University of California, Berkeley, CA
Displays represent visual information through an integrated circuit known as a Display Driver IC (DDI). These components are used in
various display devices, including computers, smartphones, and automotive displays. As display technology continues to advance, there
is a growing demand for DDI to offer uniform, high color depth, cost-effectiveness, and compact designs. Additionally, the rise of AR/VR
technologies presents new challenges that necessitate the development of innovative driving solutions. Hanyang University describes a
10b source driver IC providing a settling time of 0.69μs, DVO of 1.9mV, and silicon area per channel of 2273μm² for OLED-on-Silicon
(OLEDOS) displays. Korea University and Samsung Electronics present an area-efficient 10b source driver IC with sigma-delta
modulation interpolation DAC using a 65nm CMOS process, achieving a compact area of 1884μm2 and static current of 1.5μA per
channel.
In addition, since OLED displays are illuminated by the driving current through the thin-film transistors (TFT) that are affected by process
variations as well as thermal and electrical stress, display performance degrades over time across each pixel. To address this issue, a
compact and real-time compensator is required for each pixel to detect errors and provide compensation. Korea University presents a
source driver IC with a real-time pixel compensator for OLED displays that achieves the pixel compensator silicon area of 4442.8μm² and
a power consumption of 13.3μW per channel.
Automotive displays have evolved to enable user interaction through display technologies with capacitive touch sensors. However, driving
touch sensors can generate electromagnetic radiation, potentially degrading system stability and leading to malfunctions. The CISPR 25
Class 5 standard has been established to regulate electromagnetic interference in automotive environments, ensuring that systems meet
stringent requirements for stability and reliability. Sungkyunkwan University presents an electromagnetic interface tolerant automotive
touch analog front-end IC for CISPR 25 class 5 compliance. The chip achieves the SNR of 49.6dB, frame rate of 200Hz, and power
consumption of 10.5mW.
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Technology Directions – 2025 Trends
Subcommittee Chair: Ali Hajimiri, Caltech, Pasadena, CA
Sensing and actuation technologies are rapidly advancing, focusing on specialization, diversity, and innovation. These technologies
provide real-time data collection and analysis, allowing healthcare professionals to make informed decisions and provide personalized
care. ISSCC 2025 highlights cutting-edge systems in portable gas sensors and millimeter-sized bio-marker monitoring, aiming to enhance
power consumption, processing approaches, and system volume. ISSCC 2025 showcases integration of millimeter-sized CMOS
integrated circuits with microfluidics and organic electrochemical transistors, presenting a promising solution for multiplexed bio-marker
detection with low cost and reduced size. Additionally, effective thermal isolation, localized heat delivery, and precise local temperature
sensing are key to efficient temperature control with multiple independent channels. ISSCC 2025 demonstrates that the integration of
post-processed heated reaction sites on an ASIC enables the individual programming of hundreds of sites within a wide temperature
range while maintaining minimal thermal crosstalk.

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
INDEX

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
INDEX
A paper number mentioned in this section follows the convention S.P, where S is the session number and P is the paper number. For
example, 23.2 will be the second paper in the twenty-third session. You can refer back to the TECHNICAL SESSION OVERVIEWS in
this Press Kit for additional details on any given paper. Some of the papers will also be available in the “not-so-technical” SESSION
HIGHLIGHTS part of this Press Kit. All sessions and papers are in ascending order in both the Session Overviews and the Session
Highlights sections of the Press Kit.
Technical Topics Mapped to Papers
Technical Topic
All papers in the following Sessions
Communication Systems
includes RF, Wireless and Wireline Subcommittees
5, 7, 10, 11, 19, 26, 33, 34, 36
Analog Systems
includes Analog, Data Converter and Power
Management Subcommittees
3, 4, 9, 18, 21, 24, 27, 28, 31, 32
Digital Systems
includes Digital Architectures and Systems, Digital
Circuits, Memory, and Security Subcommittees
2, 8, 14, 17, 22, 29, 30, 33, 37
Innovative Topics
includes Imagers/MEMS/Medical Devices/Displays and
Technology Directions Subcommittees
6, 12, 13, 15, 16, 20, 25, 35
Selected Presenting Companies/Institution Mapped to Papers
Chart 4.1
Affiliation
PaperNumbers
*now at imec
28.2
Aalto University
13.2
Advanced Institute of Information Tecnhology of Peking University
13.1, 37.6
AI Chip Center for Emerging Smart System
23.2
AMD
2.1, 36.1
Ampleon
5.8
Analog Devices
20.7, 24.8, 33.5
ARGUS SPACE AG
5.5
Axelspace
11.1
Baker Hughes
3.3
Beijing Advanced Innovation Center for Integrated Circuits
7.3, 7.7, 25.5, 36.2
Beijing Institute of Technology
14.5
Beijing Ningju Technology
20.5
Brillnics
6.4

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Broadcom
16.1
Cadence
36.3
California Institute of Technology
12.3
CEA-Léti
13.5, 20.9, 21.7
CEA-List
13.5
CEA-Pheliqs
13.5
Chinese University of Hong Kong
34.6
Chip-GaN Power Semiconductor
32.3, 32.6
Chung-Ang University
23.6
Columbia University
23.1, 37.7, 37.8
CoSensing
28.4
d-Matrix
11.2
Daegu Gyeongbuk Institute of Science and Technology
7.5
Delft University of Technology
3.4, 5.8, 15.2, 31.1, 31.3, 35.1
Dongguk University
16.2
Donghai Laboratory
26.5
Dukosi
8.9
East China Normal University
7.3, 7.7, 10.1, 25.5, 36.2
Efficient Power Conversion
9.3
ETH Zürich
5.5, 10.3, 15.6, 19.10, 20.4, 28.1, 33.4, 37.8
Evonetix
20.7
Fraunhofer IZM
5.8
Fudan University
2.10, 3.2, 4.5, 7.10, 11.3, 11.5, 19.11, 26.2, 26.5,
31.1, 37.4
FuriosaAI
16.2
Gaxtrem Technology
5.1
Georgia Institute of Technology
8.3, 8.7, 26.5
Google
2.8
Hangzhou Institute of Technology, Xidian University
24.2
Hanyang University
6.7, 22.4
Harvard University
37.3
Hefei CLT Microelectronics
9.11, 32.5
Hong Kong University of Science and Technology
4.3, 23.2, 36.8
Huazhong University of Science and Technology
31.3
Hunan University
8.6
IBM
37.1
IBM Research
2.2, 8.1
IBM Research Europe
7.5
IBM Systems
2.2, 8.1
IBM T. J. Watson Reseach Center
9.6
Industrial Technology Research Institute
14.2
Infineon Technologies
34.2
Institute of Microelectronics of the Chinese Academy of Sciences
14.5
Institute of Semiconductors, Chinese Academy of Sciences
19.8
Instituto Superior Tecnico/University of Lisboa
19.1, 19.7, 20.8, 21.3, 24.3, 24.4, 24.5, 27.5, 31.4,
32.1

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Intel
2.3, 2.4, 8.7, 8.8, 21.5, 23.1, 29.2, 36.4
Iowa State University
32.2
KAIST
2.7, 8.5, 19.6, 22.2, 23.10, 23.3, 23.7, 23.9, 28.1,
28.2, 31.2, 34.1, 35.5, 35.6, 37.8
Keio University
13.3
King's College London
19.4
KIOXIA
30.2, 30.6
KIOXIA Korea
30.6
Kiwimoore (Shanghai) Semiconductors
37.4
Korea Aerospace Research Institute
19.6
Korea Institute of Science and Technology
6.3
Korea University
6.8, 6.9, 21.4, 22.5
KU Leuven ESAT-MICAS
18.8
Kyung Hee University
8.5
Leibniz University Hannover
3.3, 13.3, 21.8
Ludwig Computing
12.2
M-CHIP
4.5
Marvell
7.2, 36.9
Massachusetts Institute of Technology
23.6, 33.1
MediaTek
7.1, 7.4, 8.2, 19.3, 23.5, 24.6, 29.3
Meta
6.4
Myongji University
6.3
Nanjing Electronic Device Institute
33.2
Nanjing Low Power IC Technology Institute
11.4
Nanjing University
9.6
Nanjing University of Science and Technology
34.5
Nano Core Chip Electronic Technology
13.1, 37.6
National Center of Technology Innovation for EDA
14.3, 14.7
National Cheng Kung University
3.1
National Institute for Materials Science
20.1
National Key Laboratory of Solid-State Microwave Devices and Circuits
33.2
National Taiwan University
2.8, 15.1, 17.3, 20.3
National Tsing Hua University
2.5, 2.9, 7.6, 14.1, 14.2, 15.4, 20.2
National University of Defense Technology
8.6
National University of Singapore
17.1
National Yang Ming Chiao Tung University
32.3, 32.6
Nautilus Defense LLC
37.2
New York University Abu Dhabi
28.1, 28.2
now with Kandou Bus SA
34.3
now with Marvell
36.3
Nvidia
17.6
Oregon State University
25.2
Osaka University
20.1
Peking University
6.6, 7.3, 7.7, 10.5, 13.1, 18.2, 18.3, 18.4, 18.5, 18.6,
23.4, 25.5, 28.3, 36.2, 37.5, 37.6
Pohang University of Science and Technology
35.7

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Politecnico di Milano
34.2, 34.3
Princeton University
25.3
Purdue University
12.2, 20.11
Quobly
13.5
Realtek Semiconductor
32.3, 32.6
Reconova Technologies
23.4
Rensselaer Polytechnic Institute
33.5
Rice University
26.4, 34.4, 35.2, 35.4
SambaNova Systems
16.4
Samsung Advanced Institute of Technology
37.3
Samsung Electronics
5.4, 6.1, 6.10, 6.3, 6.9, 8.4, 9.8, 10.4, 16.3, 17.4,
21.2, 21.6, 22.4, 30.1, 30.3, 30.4, 35.6
Samsung Research America
9.3
Samsung Semiconductor
37.3
Sandia National labs
25.4
Seoul National University
8.5, 22.1, 22.2, 22.3, 34.1, 37.3, 37.7
Sesame AI
6.4
SGR Semiconductors
5.2
Shanghai Institute of Technical Physics Chinese Academy of Sciences
6.6
Shanghai Jiao Tong University
4.2, 5.2, 20.6
Silan Microelectronics
27.1
SK hynix
22.3, 30.5, 30.6
Sogang University
6.2, 9.5, 15.7, 21.6
SolidVue
6.2
Sony Semiconductor Solutions
6.5
South China University of Technology
4.2, 19.5
Southeast University
8.6, 11.4, 14.3, 14.6, 14.7
Southern University of Science and Technology
9.10, 13.4, 17.1, 34.5, 36.6, 36.8
Stanford University
12.4, 15.2
Sungkyunkwan University
6.10, 6.2
Synopsys
29.4
Taiwan Semiconductor Research Institute
2.5, 32.3, 32.6
Technical University Munich
4.4
Technische Universität Braunschweig
13.3
Teledyne DALSA Semiconductors
4.1
Teledyne e2v
4.1
Texas Instruments
25.3
Tianjin University
10.2, 33.2
Tokyo Institute of Technology
5.6, 11.1
Toronto Western Hospital
15.4
Tsinghua University
2.6, 3.4, 4.3, 5.1, 9.1, 9.10, 9.9, 14.3, 14.4, 17.2,
18.7, 19.9, 20.2, 20.5, 21.8, 21.9, 23.8, 24.1, 24.7,
26.1, 27.2, 28.4
TSMC
4.6, 14.1, 29.1, 29.5, 36.1
TSMC Corporate Research
2.9, 14.1, 14.2
TSMC Design Technology Japan
29.5
TU Delft
27.2, 27.4

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Ulsan National Institute of Science and Technology
6.2, 15.7
UM Hetao IC Research Institute
9.9, 21.8, 21.9
University College Dublin
19.4
University College London
35.3
University of Bonn
37.1
University of California
4.2, 5.10, 9.2, 9.3, 12.1, 15.7, 19.6, 20.10, 20.12,
20.3, 20.9, 21.7, 22.1, 25.2, 35.8
University of Chinese Academy of Sciences
6.6, 14.5, 19.8
University of Electronic Science and Technology of China
4.5, 5.3, 5.7, 13.4, 18.1
University of Hawaii
15.2
University of Illinois
36.7
University of Macau
4.5, 9.1, 9.10, 9.9, 14.5, 19.1, 19.7, 20.8, 21.3, 21.8,
21.9, 24.3, 24.4, 24.5, 27.5, 31.4, 32.1
University of Michigan
25.1, 26.3
University of Minnesota-Twin Cities
9.3
University of Notre Dame
15.3
University of Pavia
33.3
University of Pennsylvania
5.2, 15.4
University of Pittsburgh
15.6
University of Science and Technology of China
9.11, 9.4, 32.4, 32.5
University of Southern California
11.2, 20.1, 26.1
University of Texas
5.11
University of Tokyo
13.6, 19.2
University of Toronto
15.4, 15.5
University of Tsukuba
20.1
University of Twente
4.1
University of Ulm
17.5
University of Virginia
37.2
University of Waterloo
11.2, 26.1
University of Zurich and ETH Zurich
13.2
Vango Technologies
27.3
Washington University in St. Louis
25.2
Western Digital
30.2
Wuxi Micro Innovation Integrated Circuit Design
17.2
Xi'an JiaoTong University
7.7, 7.9, 9.7, 36.5
Xidian University
5.9, 7.8, 19.11, 24.2, 27.1
XINYI Information Technology
10.5
XINYI Semi
10.5
XO Semiconductor
6.3
Yonsei University
6.3
Zhejiang University
21.1, 26.5, 27.3

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Contact Information
CONTACT INFORMATION

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
ANALOG
Subcommittee Chair: Viola Schaffer
Texas Instruments
Work Phone: +49-8161-802943
Email: schaffer_viola@ti.com
Press Designates: Qiang Li
Chinwuba Ezekwe
DATA CONVERTERS
Subcommittee Chair: Jan Westra
Broadcom
Work Phone: +31-30-6084517
Email: jan.westra@broadcom.com
Press Designates: Xiyuan Tang
Shahrzad Naraghi
DIGITAL ARCHITECTURES & SYSTEMS
Subcommittee Chair: Rahul Rao
IBM India
Work Phone: +91-80-406-61261
Email: rahulmrao@in.ibm.com
Press Designates: Nathaniel Pinckney
Ji-Hoon Kim
DIGITAL CIRCUITS
Subcommittee Chair: Huichu Liu
Meta
Work Phone: 917-328-5513
Email: huichu@meta.com
Press Designates: Ping-Hsuan Hsieh
Carlos Tokunaga
Yvain Thonnart
IMAGERS, MEDICAL & DISPLAYS
Subcommittee Chair: Rikky Muller
University of California, Berkeley
Work Phone: +1-617-519-8508
Email: rikky@berkeley.edu
Press Designates: Mutsumi Hamaguchi
Carolina Mora Lopez
Augusto Ximenes
MEMORY
Subcommittee Chair: Meng-Fan Chang
National Tsing Hua University
Work Phone: +886-900846406
Email: mfchang@ee.nthu.edu.tw
Press Designates: Saekyu Lee
Hye-Ran Kim
POWER MANAGEMENT
Subcommittee Chair: Bernhard Wicht
University of Hannover
Work Phone: +49-511-762-19690
Email: bernhard.wicht@ims.uni-hannover.de
Press Designates: Hanh-Phuc Le
Mo Huang
RF
Subcommittee Chair: Brian Ginsburg
Texas Instruments
Work Phone: 214-567-6311
Email: bginzz@ti.com
Press Designates: Omeed Momeni
Hiroshi Hamada
Mina Shahmohammadi
SECURITY
Subcommittee Chair: Ingrid Verbauwhede
KU Leuven
Work Phone: +32-16-32-86-25
Email: ingrid.Verbauwhede@esat.kuleuven.be
Press Designates: Rabia Tugce Yazicigil
Utsav Banerjee
TECHNOLOGY DIRECTIONS
Subcommittee Chair: Ali Hajimiri
Caltech
Work Phone: +1-626-487-8463
Email: hajimiri@caltech.edu
Press Designates: Daniel Morris
Jacques "Chris" Rudell
WIRELESS
Subcommittee Chair: Chih-Ming Hung
MediaTek
Work Phone: +1 512-887-2080
Email: hungcm@hotmail.com
Press Designates: Wu-Hsin Chen
Yuanjin Zheng
WIRELINE
Subcommittee Chair: Thomas Toifl
Cisco Systems
Work Phone: +41-76-527-1304
Email: ttoifl@cisco.com
Press Designates: Mozhgan Mansuri
Wei-Zen Chen
© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION
Program Chair, ISSCC 2025
Tom Burd
Phone: +1-408-749-2805
Email: tom.burd@amd.com
Program Vice-Chair, ISSCC 2025
Keith Bowman
Phone: +1-919-237-4750
Email: kbowman@qti.qualcomm.com
Press Coordinator
Shahriar Mirabbasi
University of British Columbia
Email: shahriar@ece.ubc.ca
Press-Relations Liaison
Laura Fujino
University of Toronto
Work Phone: 416-418-3034
Email: lcfujino@aol.com

© COPYRIGHT 2025 ISSCC—DO NOT REPRODUCE WITHOUT PERMISSION