Symposium i anvendt statistik 2025 PDF Free Download
1 / 281/281
100%

Symposium
i anvendt
statistik
2025
Økonomisk Institut og Klinisk Institut Symposium i
Syddansk Universitet Anvendt Statistik

SYMPOSIUM
I
ANVENDT
STATISTIK
2025
Redigeret af Peter Linde
på vegne af organisationskomiteen for
Symposium i Anvendt Statistik
Støttet af SAS Institute Inc.
Økonomisk Institut og Klinisk Institut Symposium i Anvendt Statistik
Syddansk Universitet

Forord
Det er symposiets formål at fremme information om såvel anvendt statistik
som statistisk databehandling. Symposiet er tværfagligt med særlig vægt på
metodik, formidling og fortolkning af statistiske analyser. I år er Økono-
misk Institut og Klinisk Institut på Syddansk Universitet, vært for symposi-
et, hvilket vi gerne vil takke for. Symposiet arrangeres af Symposium i An-
vendt Statistik og Økonomisk Institut og Klinisk Institut på Syddansk Uni-
versitet. Symposiet i Anvendt Statistik er ansvarlig for det faglige program
og økonomien.
Symposiet har til formål at understøtte delingen af statistiske analyser.
Dette års indlæg spænder over mange forskellige fagområder og lægger
derudover vægt på metoder og analyser. Som det er normalt ved faglige
indlæg, er bidragsyderne ansvarlige for indholdet af indlæggene, og
spørgsmål herom kan rettes direkte til forfatterne.
Med symposiet tilstræbes det at skabe et forum for tværfaglig inspiration og
dialog for at udbygge kommunikationen mellem personer, der arbejder med
beslægtede metoder inden for forskellige fagområder.
Peter Linde, Organisationskomiteen
ISBN 978-87-989370-5-0
Trykt hos PRinfoTrekroner i 80 eksemplarer

Organisationskomiteen for Symposium i Anvendt Statistik 2025
Lisbeth la Cour Peter Linde
Økonomisk Institut Statistikkonsulent
Copenhagen Business School Granparken 187
Porcelænshaven 16A 2800 Lyngby
2000 Frederiksberg peter@brede.dk
llc.eco@cbs.dk
Anders Milhøj Esben Høg
Økonomisk Institut Institut for Matematiske Fag
Københavns Universitet Aalborg Universitet
Øster Farimagsgade 5 – B26 Thomas Manns Vej 23
1353 København K 9220 Aalborg Ø
Anders.Milhoj@econ.ku.dk esben@math.aau.dk
Gorm Gabrielsen Sören Möller
Institut for Finansiering Faculty of Health Sciences
Copenhagen Business School Syddansk Universitet
Solbjerg Plads 3 J. B. Winsløws Vej 19
2000 Frederiksberg 5000 Odense C
stgg@cbs.dk Moeller@health.sdu.dk
Helle M. Sommer Sara Armandi
Konsulent Laerdal
Hjortholmsvej 26 Njalsgade 19D
2830 Virum 2300 København
helle.m.sommer13@gmail.com sara.armandi@laerdal.com
Nils Karl Sørensen Klaus Rostgaard
Institut for Økonomi Kræftens Bekæmpelse
Campusvej 55 Strandboulevarden 49
5230 Odense M 2100 København Ø
nks@sam.sdu.d klar@cancer.dk
Jørgen Lauridsen Niels Kærgaard
Økonomisk Institut Fødevare- og Ressourceøkonomi
Syddansk Universitet Københavns Universitet
Campusvej 55 Rolighedsvej 25
5230 Odense M 1958 Frederiksberg
jtl@sam.sdu.dk nik@life.ku.dk
Hans Bay Jane Rusbjerg
Ekstern lektor Data og Analyse
Københavns Universitet Kriminalforsorgen
Øster Farimagsgade 5 Strandgade 100
1353 København K 1401 København K
hans.bay@econ.ku.dk Jane.Rusbjerg@krfo.dk
Arne Henningsen
Fødevare- og Ressourceøkonomi
Københavns Universitet
Rolighedsvej 23
1958 Frederiksberg
arne@ifro.ku.dk

Indholdsfortegnelse
Sundhed I
Identifikation af blinde i danske sundhedsregistre
Katrine Prisak Jakobsen1,2, Lonny Stokholm1.2, Linda Juel Ahrenfeld3, Jakob Grauslund
2,4,5 og Sören Möller1,2. 1 Open Patient data Explorative Network, OUH, 2 Klinisk Institut,
SDU, 3 Forskningsenheden for Almen Praksis, SDU, 4 Øjenafdelingen, OUH, 5 Steno
Diabetes Center, OUH ......................................................................................................... 1
Modelling height and weight in The Danish National Child Health Register
Gry Juul Poulsen, Center for Molecular Prediction of Inflammatory Bowel Disease –
PREDICT, Department of Clinical Medicine, Aalborg University ..................................... 5
GDPR and other issues in reporting multiple outcomes to a common exposure
Klaus Rostgaard, Danish Cancer Institute, Danish Cancer Society ................................ 14
Imputering af manglende blodprøver i laboratoriedatabasen
Frederik Lykke Petersen1, Sören Möller1,2, 1 Open Patient data Explorative Network,
Odense Universitetshospital, 2 Klinisk Institut, Syddansk Universitet .............................. 17
Statistisk metode
(Fejl)fortolkninger af konfidensintervaller
Tom Engsted, Institut for Økonomi, Aarhus Universitet .................................................. 23
Measurement Error or Individual Variation
Gorm Gabrielsen, Copenhagen Business School, Department of Finance ....................... 32
Using higher dimensional space to find solutions of problems
Jacob Hjelmborg, The Faculty of Health Sciences, Department of Public Health,
Epidemiology, Biostatistics and Biodemography, University of Southern Denmark ........ 33
Statistisk analyse og Nyheder i SAS
Objektiv sensitivitetsanalyse for tidsvarierende konfundere
Andreas Kristian Pedersen1,2, Anna Mejdal 2, Afsaneh M. Nejad3 og Soren Möller2,4,
1 Klinisk forskningsafdeling, Sygehus Sønderjylland, 2 OPEN, Odense Universitet,
Hospital, 3 Institut for Matematik og Datalogi, SDU, 4 Klinisk Institut, SDU ................ 34
Violent aggression: Consequences of ostracism and violence against vulnerable
adolescents
Mogens Nygaard Christoffersen, VIVE, The Danish Center for Social Science .............. 38
FAIR data and Open Science: some insights from a work package in the PIGWEB project
Leslie Foldager, Dept. of Animal and Veterinary Sciences, Bioinformatics Research
Centre, AU .......................................................................................................................... 49
SAS and Open Source – A Legendary Alliance in Data Analytics
Sara Armand, Laerdal ...................................................................................................... 252
Samfund
Hvor liberale er Liberal Alliances vælgere?
Anders Malhøj, Økonomisk Institut, Københavns Universitet ........................................... 55
Kan BBR registeret bruges til retvisende ejendomsvurderinger?
Peter Linde, Statistikkonsulent .......................................................................................... 64
Arbejdsmarkedsreformer – øger de beskæftigelsen?
Jesper Jespersen, RUC ...................................................................................................... 74
Økonomers køn og løn - en statistisk sammenligning af kvindelige og mandlige cand.
polit’ers lønfordelinger
Nadja Eiler, Rockwool Fondens Interventionsenhed, og Henrik Hansen, Økonomisk
Institut, Københavns Universitet ........................................................................................ 86
Økonomi
Definering af buskundepotentiale ved spatial regression af socioøkonomiske data
og passagerforhold på Fyn
Thorbjørn Revsbech Sørensen og Diana Andreea Vasile, Plan FynsBus, Patrycja Anna
Zieba, Marked FynsBus, Flemming Albæk og Seher Øzden Økonomi og Analyse
Fynsbus ............................................................................................................................. 99
Studying the First Modern Economy with the Sound Toll Data
Lisbeth la Cour and Battista Severgnini, Copenhagen Business School ........................ 242
Aid for Trade and CO2 Emissions: The Case of Middle-Income Countries
$\úH$UÕ'HSDUWPHQWRI(FRQRPLFV0HUVLQ8QLYHUVLW\-¡UJHQ7/DXULGVHQ'HSDUWPHQW
of Economics, University of Southern Denmark, and Elvan Küpeli, Department of
Economics, Mersin University ....................................................................................... 107
Uddannelse
Fra prompt til praksis - Undervisning i anvendt statistik med generativ AI
Sara Armandi, Hans Bay, Anders Milhøj, Markus Roed Schøler og Nina Johanna Åberg-
Jensen, Økonomisk Institut, Københavns Universitet ..................................................... 120
De spildte talenter. Blandt de mange unge danske fodboldtalenter får nogle
muligheden for at spille på
DBU’s udvalgte hold, - men er chancen lige stor for alle?
Steen Andersen, Institut for Økonomi, BSS, Aarhus Universitet ..................................... 143
Hvem har gode matematikkundskaber trods matematikskræk
Anders Milhøj, Økonomisk Institut, Københavns Universitet .......................................... 151
Sundhed II
Aktivitetsdeltagelse, dødelighed og indlæggelser: Et dansk kohortestudie
Linda Juel Ahrenfeldt1, Tobias Anker Stripp1,2,3, Jens Søndergaard1, og Sören Möller4,5.
1 Forskningsenheden for Almen Praksis, Institut for Sundhedstjenesteforskning, SDU,
2 The Human Flourishing Program, Quantitative Institute for Social Sciences, Harvard
Universitet, Cambridge, 3 Center for Videnskab og Tro, Københavns Universitet, 4 Open
Patient data Explorative Network, OUH,5 The OPEN Research Unit, Klinisk Institut, Sy
University of Southern Denmark ..................................................................................... 161
Triangulation of contradictory evidence from three randomized trials
of an early 2-dose measles schedule in Guinea-Bissau from 2003-2019
Sebastian Nielsen, Bandim Health Project, Department of Clinical Research, SDU, and
Sören Möller, Open Patient data Explorative Network (OPEN), Department of Clinical
Research, University of Southern Denmark ..................................................................... 173
Estimating Healthcare Transitions: Integrating Logistic Regression and Markov
Models to Predict Mortality from Continuity and Discontinuity of Care
Troels Kristensen, DaCHE, Department of Public Health, University of Southern
Denmark .......................................................................................................................... 184
Network meta-analysis of diagnostic test accuracy trials
Oke Gerke1,2 and Werner Vach3,4. 1 Department of Nuclear Medicine, OUH,
2 Department of Clinical Research, SDU, 3 Basel Academy for Quality and Research in
Medicine, Switzerland and 4 Department of Sports Science and Clinical Biomechanics,
University of Southern Denmark ...................................................................................... 196
Bilag: Vurderingsmodel for ejerboliger 2019 .............................................................. 206

Identifikation af blinde i danske sundhedsregistre
Katrine Prisak Jakobsen1,2, Lonny Stokholm1,2, Linda Juel Ahrenfeldt3, Jakob
Grauslund2,4,5og S¨oren M¨oller1,2
1Open Patient data Explorative Network, Odense Universitetshospital
2Klinisk Institut, Syddansk Universitet
3Forskningsenheden for Almen Praksis, Syddansk Universitet
4Øjenafdelingen, Odense Universitetshospital
5Steno Diabetes Center Odense, Odense Universitetshospital
Introduktion
Der formodes at cirka 20,000 borgere i Danmark er blinde eller stærkt svagtsynede, men
det præcise antal er ukendt [2]. Blindhed er ifølge internationale studier associeret med
ulighed i sundhed og livskvalitet, dette er dog ikke nærmere undersøgt i Danmark [4,1]. Vi
planlægger derfor i projektet AVID - Addressing Health and Socio-economic Disparities
among Visually Impaired Individuals in Denmark at undersøge ulighed mellem blinde og
den resterende befolkning i Danmark p˚a basis af nationale registerdata. Som første skridt
i dette projekt ønsker vi at bestemme kriterier, der kan anvendes til at identificere blinde
i danske registre, samt at estimere det samlede antal blinde i den danske befolkning.
Studiedesign og datakilder
Vores studie baserer sig p˚a to datakilder, p˚a den ene side et udtræk fra Landspatien-
tregisteret (LPR) og CPR-registeret, som inkluderer alle 6,622,068 personer, der havde
bopæl i Danmark og var i live 31.12.2022. P˚a den anden side et udtræk af Dansk Blin-
desamfunds (DBS) medlemsdatabase med alle nulevende medlemmer p˚a udtræksdatoen
primo 2023, som hver især er bekræftet blind eller stærkt svagseende af en øjenlæge, som
krav til indmeldelsen. P˚a baggrund af disse to datakilder, har vi bestemt hyppigheden
af øjnerelaterede ICD-10 diagnoser (samt tilsvarende ICD-8-koder) fra LPR b˚ade blandt
DBS medlemmer, og bland den resterende befolkning.
Epidemiologiske resultater
I tabellen rapporterer vi den samlede gruppe af øjenrelaterede diagnostiske ICD-10-koder
(DH*), samt de enkelte koder, der optr˚adte hyppigst i LPR for de personer, der indg˚ar i
DBS-datasættet. Vi observerer, at kun 6,4% af DBS-medlemmerne er registreret med en
kode, der indikerer dobbeltsidet blindhed (DH540), og 2,4% med en kode, der indikerer
stærk synsnedsættelse. Alts˚a ville disse koder kun være i stand til at identificere mindre
end 10% af DBS-medlemmerne som blinde, baseret udelukkende p˚a LPR-data. P˚aden
anden side er 90,8% af DBS-medlemmerne registreret i LPR med mindst en ICD-10-kode
relateret til en øjensygdom. Alts˚a har langt størstedelen af de blinde været i behandling i
det danske hospitalsvæsen i forbindelse med øjensygdomme, for de fleste af dem dog uden
1

at være blevet registreret med en kode for blind/stærkt svagtseende i registrene. Derimod
er der kun mindre end 0,1% af ikke-DBS-medlemmerne, der er registreret med en kode,
der indikerer blindhed / stærk svagtsynethed, som dog stadig giver 1344 individer, som m˚a
formodes at være blinde, uden at være medlem af DBS, og som derfor ikke kan identificeres
via DBS-data alene.
Dansk Blindesamfund Resterende befolkning
Total 7.184 6.614.884
DH* 6.522 (90,8%) 960.090 (14,5%)
DH259 2.690 (37,4%) 238.699 (3,6%)
DH264 1.112 (15,5%) 53.341 (0,8%)
DH353 2.596 (36,1%) 71.305 (1,1%)
DH353J 1.094 (15,2%) 24.267 (0,4%)
DH353L 521 (7,3%) 8.868 (0,1%)
DH355 903 (12,6%) 2.130 (0,0%)
DH401 689 (9,6%) 16.593 (0,3%)
DH405 444 (6,2%) 4.679 (0,1%)
DH409 419 (5,8%) 9.130 (0,1%)
DH540 457 (6,4%) 815 (0,0%)
DH541 176 (2,4%) 529 (0,0%)
DH579 937 (13,0%) 71.694 (1,1%)
Capture-recapture-metoden
P˚a basis af ovenst˚aende resultater, er det tydeligt, at b˚ade LPR og DBS, kun kan identifi-
cere en andel af de blinde personer i den danske befolkning, og at der m˚a forventes et stort
mørketal af blinde, som ikke identificeres via hverken den ene eller den anden datakilde.
Mens dette mørketal næppe kan identificeres p˚a individniveau, giver capture-recapture-
metoden (oprindeligt foresl˚aet af den danske biolog C.G.J. Petersen, [3]) mulighed for at
ekstrapolere størrelsen af dette mørketal, og dermed det samlede antal blinde i Danmark.
Vi vil i det følgende antage at sensitiviteten af en blinderegistrering (B) i DBS hen-
holdsvis LPR er givet ved
P(DBS|B)=pB
DBS
P(LP R|B)=pB
LP R.
Samtidigt vil vi for nemheds skyld antage at specificiteten i b˚ade DBS og LPR er 1, alts˚a
P(DBS|¬B)=p¬B
DBS =0
P(LP R|¬B)=p¬B
LP R =0
Mens dette næppe er fuldstændigt korrekt, s˚a forventer vi at specificiteten er tæt p˚a1,
da DBS kræver en undersøgelse hos en øjenlæge og en LPR-registrering for blindhed ogs˚a
antages at være af høj validitet.
Der vi alts˚a gælde
P(DBS)=pB
DBS ·P(B)+p¬B
DBS ·P(¬B)=pB
DBS ·P(B)
P(LP R)=pB
LP R ·P(B)+p¬B
LP R ·P(¬B)=pB
LP R ·P(B).
Desuden vil der nødvendigvis gælde formelle sammenhænge
P(DBS&LP R|B)=αBpB
DBSpB
LP R >0
P(DBS&LP R|¬B)=α¬Bp¬B
DBSp¬B
LP R =0
2

s˚afremt b˚ade pB
DBS >0ogpB
LP R >0, hvilket m˚a antages, hvis datakilderne skal have
nogen værdi.
P˚a bagrund af Bayes formel kan vi derfor bestemme:
P(DBS&LP R)=P(DBS&LP R|B)·P(B)+P(DBS&LP R|¬B)·P(¬B)
=αBpB
DBSpB
LP R ·P(B)+0·P(¬B)
=αBpB
DBSpB
LP R ·P(B)
=αBP(DBS)
P(B)
P(LP R)
P(B)·P(B)
=αBP(DBS)·P(LP R)
P(B)
og alts˚a(s˚afremt P(B)>0)
P(B)=αBP(DBS)·P(LP R)
P(DBS&LP R).
I vores datasæt observerer vi
P(DBS)= 7184
6622068 =0,1085%
P(LP R)=457 + 176 + 815 + 529
6622068 =0,0299%
P(DBS&LP R)=457 + 176
6622068 =0,0096%
alts˚a
P(B)=αBP(DBS)·P(LP R)
P(DBS&LP R)
=αB0,001085 ·0,000299
0,000096
=αB0,003379 = αB·0,3379%
Og alts˚a vil det samlede antal blinde nBi befolkningen være
nB= 6622068 ·0,003379αB= 22376αB.
Hvis αB= 1, svarende til DBS og LPR værende uafhængige i deres identifikation, ville
det indebære 22.376 blinde i Danmark.
Vi kan observere at konstanten αBhar denne relation til korrelationen mellem (DBS|B)
og (LP R|B):
Cor(DBS|B, LPR|B)=(αB−1) pB
DBS ·pB
LP R
(1 −pB
DBS)·(1 −pB
LP R)
3

Eftersom vi har observeret individer, der b˚ade er i DBS og LP R m˚aαB>0, men
det kunne principielt tænkes at de to datakilder er stærkt negativt associerede, og at den
totale andel og antal blinde derfor, som minimum, kunne være
P(B)=P(DBS)+P(LP R)−P(DBS&LP R)=0,1288%
nB= 6622068 ·0,001288 = 8529.
svarende til, at der kun er de blinde i befolkningen, som vi har indentificeret i vores to
datakilder.
I det andet ekstremum, kunne det tænkes at de to datakilder er stærkt positivt as-
socieret, med en (næsten) vilk˚arlig stor værdi af αB, og derfor en vilk˚arlig høj andel blinde
i befolkningen. Dette er selvfølgeligt meget usandsynligt, men det er svært at give en øvre
grænse for graden af positiv association.
Konklusion
Det viser sig at hverken DBS eller LPR i sig selv bidrager med nok information, til at
kunne identificere alle, eller blot langt størstedelen, af de blinde i Danmark. Tilsammen
giver disse to datakilder dog en formodentligt valid gruppe af blinde, der kan undersøges
i registerstudier, dog med det forbehold, at der sandynligvis findes et mørketal p˚a mindst
50% af de blinde i befolkningen med denne tilgang, hvilket det er vigtigt at være opmærk-
som p˚a i fortolkningen af registerstudier p˚a blinde.
Finansiering og taksigelser
Projektet er finansieret af Danmarks Frie Forskningsr˚ad AVID - Addressing Health and
Socio-economic Disparities among Visually Impaired Individuals in Denmark (10.46540/3165-
00105B) og Gundhild Jenny Andersens fond (OUHs overlæger˚ads forskningsfond) Identi-
fikation af blinde i danske sundhedsregistre. Vi takker desuden Dansk Blindesamfund for
samarbejdet og tilladelse til at anvende et udtræk fra deres medlemsdatabase.
Referencer
1. Blinde og stærkt svagsynedes levevilk˚ar. VIVE – Det Nationale Forsknings- og Anal-
ysecenter for Velfærd (2017).
2. Bengtsson, S., Mateu, N. C., and Høst, A. Blinde og stærkt svagsynede: barri-
erer for samfundsdeltagelse. SFI - Det nationale Forskningscenter for Velfærd (2010).
3. Petersen,C.G.J.The yearly immigration of young plaice into the Limfjord from
the German Sea. Report of the Danish Biological Station Band 6 (1896), 5–84.
4. Ulldemolins, A. R., Lansingh, V. C., Valencia, L. G., Carter, M. J., and
Eckert, K. A. Social inequalities in blindness and visual impairment: a review of
social determinants. Indian J. Ophthalmol. 60, 5 (Sept. 2012), 368–375.
4

5
Modelling height and weight in The Danish National Child Health Register
Gry Juul Poulsen,
Center for Molecular Prediction of Inflammatory Bowel Disease – PREDICT,
Department of Clinical Medicine,
Aalborg University
Summary:
In recent years new health Registries have been made available for research, such as
Danish National Child Health Registry and the Register of Laboratory Results for
Research, which include continuous variables measured at irregular and potentially
informative time points. These data can allow researchers to study trajectories over
time, but also pose certain challenges. In this talk I will discuss some of the challenges
we have encountered in a study of growth trajectories before diagnosis of pediatric
inflammatory bowel disease where we used height- and weight measurements from the
Danish National Child Health Registry.
Background:
While most of the Danish health registries contain data on dates with categorical
labels, such a date of hospitalization with associated diagnosis codes, some of the
newer registries include data on continuous variables measured at a range of different
time points. These datasets can potentially be used to study trajectories, for example of
development in biomarkers before onset of disease, but the data have some shared
challenges. The data are longitudinal but measured at irregular and potentially
informative time points, and though the overall datasets may be huge, at an individual
level the data can be sparse with potentially only a few observations per individual
which can make modelling individual trajectories difficult.
One such resource is the Danish National Child Health Registry (DNCHR) which was
established in 2009 and collects data on weight and height from health nurses and
general practitioners along with data on breastfeeding and passive smoking in the
home (Andersen 2023). Unlike birth cohort studies or other research projects where
longitudinal data on children’s height and weight are collected according to a pre-
planned follow-up schedule, the data in the DNCHR are a mix of measurements from
routine health checks and additional measurements taken because of concerns of the
child’s health, growth or weight.
Health registry data can address research questions that often cannot be answered with
clinical databases such as long-term trajectories or trajectories before onset of a
specific disease and have the advantage of covering all cases in the population rather
than cases from a single specialized clinic. One example is inflammatory bowel
disease (IBD) where registry studies have shown that patients show differences in
medication use and biomarkers compared to population controls many years before
they get an IBD diagnosis which suggests that inflammatory processes begin years

6
before onset of gastrointestinal symptoms (Vestergaard 2023, Bonfils 2023). For
pediatric IBD, it is well-known that many patients have low weight and height for their
age at time of diagnosis (Ishige 2019), but it is unknown how long before IBD
diagnosis growth began to deviate. Brusco De Freitas 2025 examined how long before
pediatric IBD diagnosis it was possible to identify differences in the mean height,
weight and body mass index (BMI) by comparing Z-scores for height, weight, and
BMI in up to 10 years prior to IBD diagnosis to up to 3 years after IBD diagnosis. In
the following, I will discuss some the issues related to standardizing the height, weight
and BMI measurements to a reference population and the problem of informative
observation times.
Data:
The Danish National Child Health Registry (DNCHR) includes data on height and
weight measured in infancy by child health nurses, at age 1-5 years at annual health
checkups at general practitioners and at age 5-17 by school health nurses (Andersen
2023). During school age, measurements are taken at least three times: once in the year
of starting school, once in middle school and once during last part of school. For some
children more measurements are taken, in particular if there are concerns about the
child’s health, growth or weight. Figure 1 shows the distribution of age at
measurements.
From the DNCHR, we identified a reference population consisting of 916,133 children
born between 1997 and 2015 with at least one height/weight measurement during
school age (between 5.5 and 16.5 years) and with birth length and weight recorded in
the Danish Medical Birth Registry. We did not include observations in the first year of
Figure 1: Distribution of number of height and weight observations in DNCHR by age at observation.
Measurements are a mix of scheduled routine measurements and additional follow
-up visits.

7
life or measurements where either height or weight were outside +/- 5 standard
deviation (SD) according to the 2014 Danish growth reference (Tinggaard 2014). After
these exclusions the median number of measurements on each child was 3 with
interquartile range (IQR) 4. Within this population, we identified an IBD population of
1,522 individuals diagnosed with IBD at age 5-17 years and available height and
weight measurements between 10 years before and 3 years after first IBD contact. IBD
was defined based on at least two inpatient hospital contacts/ outpatient visits with
IBD (ICD10 code: K50, K51) within two years in the Danish National Patient Registry
(Agrawel 2022). In addition to the IBD population, we identified a sibling population
as a comparison group consisting of full siblings to the IBD population who did not
themselves have IBD.
Methods
Standardization of data on height and weight
Since the aim of the study was to compare height, weight and BMI relative to time
before and after IBD diagnosis, it was necessary to remove the dependence of age on
height, weight and BMI. One way to do this is to calculate age- and sex-specific z-
scores. If the underlying data are normally distributed, z-scores will have mean zero
and standard deviation 1 and 99.9% of observations will be within -3 to 3. These
properties make z-scores useful for comparisons across groups. However, if the data
are not normally distributed, the z-scores will still have mean 0 and standard deviation
1, but the data are not necessarily within -3 and 3 and comparisons across groups can
give misleading results if some groups have more skewed distributions than other
groups.
The way that height, weight and BMI depend on age and sex is not straightforward:
not only does the mean height and weight increase non-linearly with age, but for
weight and BMI the standard deviation and skewness also changes non-linearly with
age. One solution is to use an external growth reference such as the 2014 Danish
growth reference (Tinggaard 2014). This growth reference was derived using methods
that take age-dependent standard deviation and skewness into account, and the
reference reports parameters in six-months interval that enable researchers to convert
measurements into z-scores. However, because of the rapid growth during childhood
using six-month means that children at the beginning of the age interval will get too
low scores and at the end of the intervals too high scores, so using this reference would
add noise to the data. Another solution is to use the DNCHR to create an internal
reference; this is a sensible solution given the size of the DNCHR and has the further
advantage that it eliminates the need of a non-IBD comparison group. Some authors
have ignored the non-normality of data and simply standardized data by subtracting
the mean and dividing by the standard error within intervals of age and by sex.
However, as explained above, because the skewness in weight and BMI increases with
age this approach might give misleading results as it does not completely remove the
dependence of age. A better way to calculate z-scores is to use generalized additive
8
models for location, scale and shape (GAMLSS) to model height, weight and BMI as
recommended by Borghi 2006. The GAMLSS model is a flexible, semi-parametric
model that allows both mean, standard deviation, skewness and curtosis to depend
non-linearly on covariates. We therefore fitted GAMLSS models with Box-Cox power
exponential distributions for boys and girls separately including age as a continuous
covariate using the lms function from the GAMLSS package in R (Stasinopoulos &
Rigby 2008).
Selection of reference sample
The height and weight measurements in the DNCHR are a mix of scheduled routine
measurements and additional measurements where either weight and height or other
health problems gave rise to concern and additional follow-up visits. As example,
children with at least one standardized BMI measurement greater than 2 according the
2014 Danish growth reference had a median of 5 (IQR 6) measurements compared
with children who never had a standardized BMI measurement above 2 who had a
median of 3 (IQR 3) measurements. Similarly, children with at least one standardized
measurement below -2 had a median of 7 (IQR 6) measurements. This means that if all
observations are used, children with either high or low weight for their age contribute
with more observations than children with normal weight. For this reason, we chose to
use one random measurement per child for the GAMLSS model to allow each child to
contribute equally. This was done by drawing a random subsample consisting of
100,000 children using a weighted sampling upweighting measurements from age
intervals with few measurements. The choice to use only 100,00 children out of the
full reference population was made because of the long computation time of the lms
and because the full reference population was much bigger than necessary. To examine
whether taking a subsample of the reference population made any difference, we
performed a sensitivity analysis where we drew ten different subsamples.
Analysis of growth in pediatric IBD patients and their siblings
Next the height, weight and BMI measurements of IBD patients and their siblings
were standardized to z-scores which were modelled by years before and after IBD
diagnosis using linear regression models including a random intercept for each child.
Results
Results from modelling growth by age and sex
Figure 2 shows the results of fitting the GAMLSS model with Box-Cox power
exponential distributions to the height, weight and BMI data for boys and girls. In the
figure actual measurements are coarsened to protect privacy and color is used to show
the number of observations. For height the model fit the data well, except at 16 years
where the curve unexpectedly begins to drop which may be an edge effect. For weight

9
and BMI, the fit is not quite as good: though the means are fairly stable the curves
representing 2 and 3 standard deviations over the mean is less stable. Increasing the
smoothing performed by the lms function did not help to make lines smoother. It is
Figure 2: Fit of by GAMLSS models forheight, weight and BMI by age and sex. Underlying observations are coarsened to
protect privacy and color is used to indicate number of observations in each cell. Lines represent means and 1, 2 and 3
standard deviations from the mean.

10
notable that the jumps in the 2 and 3 SD curves occur at age intervals where there are
fewer observations; this could both be due to fewer observations in the age intervals or
the fact that measurements in these intervals are less likely to be routine measurement
and more likely to be extra measurements taken in children where there was a need to
monitor height or weight more closely.
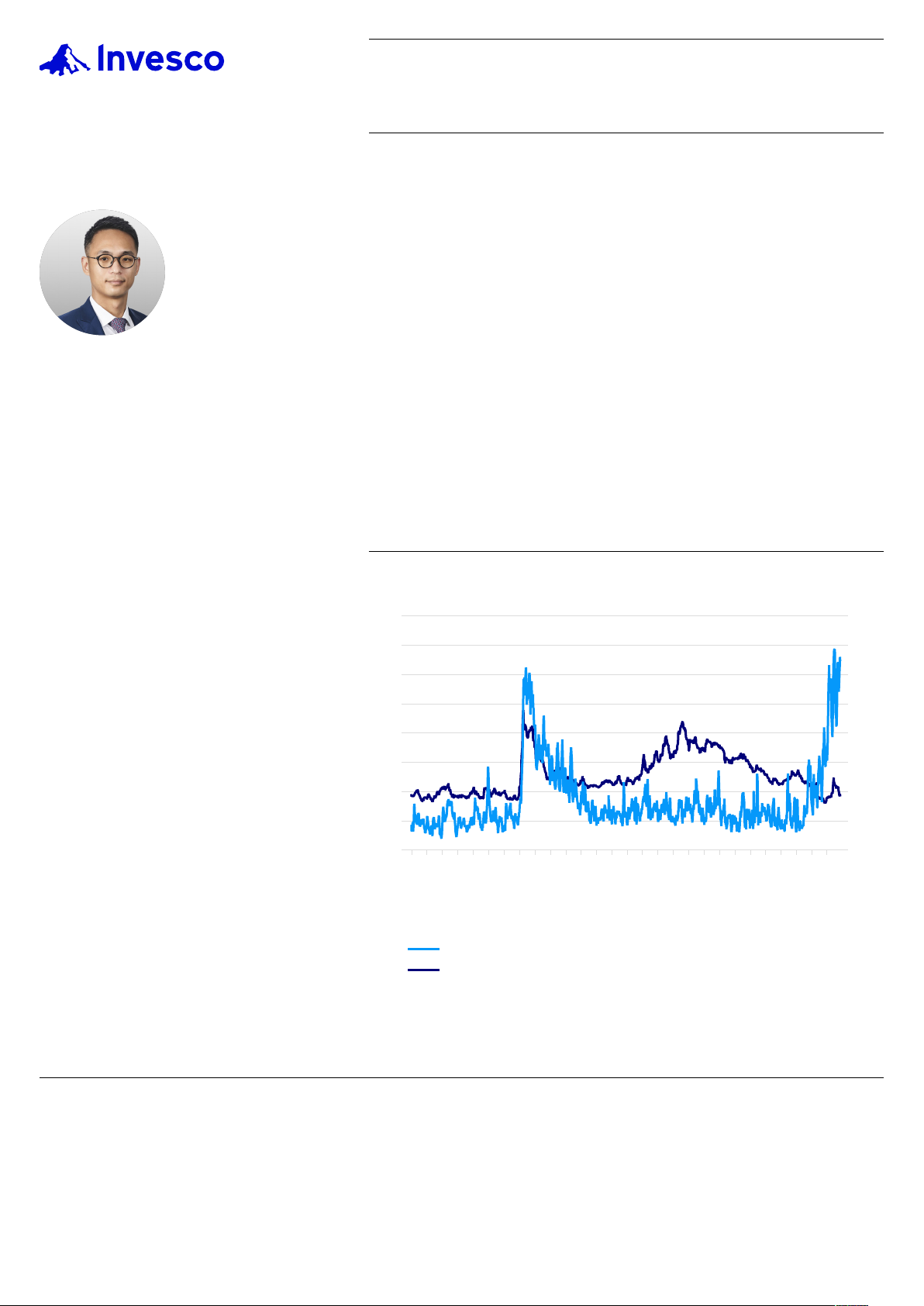
Figure 3 shows the three different methods applied on height and weight from children
at age 5-16.5 and displays range of z-scores along with means and standard deviations
in intervals of one tenth of a year. Using the 2014 Danish growth reference introduced
small variations across six-moth age intervals for both height and weight. For height
using the crude, untransformed z-scores and the z-scores derived from the GAMLSS
model gave similar result, but for weight a substantial skewness was found in the
crude, untransformed z-scores.
Figure 3: Results from standardizing height and weight on the reference population by three diƯerent methods:
according to the 2014 Danish growth reference, by crude standardization without transformation and by GAMLSS
models. The Ʊgure shows the range of the observations with mean marked by black dots and plus/minus standard
deviation around the mean by dark purple. Age at measurement is divided into one tenth of a year.

11
Results from the analysis of growth in pediatric IBD patients and their siblings
The mean z-score for height, weight and BMI by time before and after IBD diagnosis
is shown in Figure 4 and shows that children with IBD experienced a period of lower
height, weight and BMI, both at year of diagnosis, but also in the years leading up the
diagnosis and in the years after the diagnosis. For BMI the mean z-score was higher in
the year of diagnosis than in the year before and after diagnosis. This may be due to
systemic corticosteroids which 52% of the children received in year of diagnosis. By
comparison, the siblings to IBD patients showed no departures from their normal
height, weight and BMI through the period, which suggests that the changes in the
BMI population is due to the onset of disease and not to family or environmental
factors which would mostly be shared between full siblings.
Discussion:
Here I have presented some of the problems in the analyses of the height, weight and
BMI measurements in the DNCHR. Correct standardization is important for the
interpretation of results and for avoiding introducing noise or bias into the
measurements while standardizing them. Further, using convenience data with a mix
of routine and extra measurements introduce potential challenges if individuals with
Figure 4: Mean z-scores with 95% conƱdence intervals for height, weight and BMI by years before and after IBD
diagnosis for pediatric IBD patients and their full siblings. The sibling population is plotted by date of diagnosis of their
IBD sibling.
12
high or low measurements have more observations. The height, weight and BMI
measurements in the DNCHR are a good example of these challenges: the skewed
distributions of weight and BMI need to be considered in the standardization, and
because of height and weight is monitored at specific ages during childhood, it is to
some extent possible to distinguish between routine and extra measurements.
As illustrated by the height in Figure 3, the crude standardization without
transformation can be sufficient in some cases, and if the skewness does not depend on
age it may also be sufficient to transform all measurements at once and then use crude
standardization. For weight and BMI and other skewed measurements it is however
necessary to use a more advanced method of standardization and the GAMLSS models
are then a good choice. They are flexible and easy to use through the implementation
of the lms function in the GAM package in R. However, there are some limitations.
Firstly, the lms function is only able to include one continuous covariate; this means
that the analyses did not take calendar year into account, though this will often be
necessary in registry studies. Another limitation of using the GAMLSS models is the
long computational time. While this is arguably in part a matter of sufficient
computational resources and patience, it may also be a question of using data better
and more efficiently. Cole 2021 provides a guide for designing studies of growth
reference centiles and many of the considerations could also be applied when creating
an internal reference.
In the construction of the internal reference for the standardization, we dealt with
informative number of measurements by only using one observation per individual.
Vogel 2017 discussed using resampling to deal with informative number of
observations by using 1000 repeated subsamples to estimate reference curves. We tried
to implement this approach in the current study, but again the size of the data was too
big to make it feasibly to rerun the GAMLSS model so many times. However, we ran
10 resamples and found that it did not change results. While this approach reduces the
impact of informative observation times, it is possible that problems with the fit for
weight and BMI may be due to the age intervals without planned routine
measurements. If children with observations in these intervals are likely to be children
with either high or low weight, it might have been better to exclude these age intervals
and base the model estimation on the age intervals with planned routine
measurements. Informative number of measurements and measurement times may also
play a role in the analysis of the IBD population. Since all children in the population
are ill, it is likely that many of the children will have extra measurements which may
be advantage for modelling trajectories. However, since more severely ill IBD patients
may lose more weight and therefore have more measurements, the informative
measuring times can still have an impact on results.
The discussion here has focused on height, weight and BMI in the DNCHR, but
similar considerations would apply to studies of trajectories of biological
measurements in the Register of Laboratory Results for Research. Many biomarkers
13
depend on age and sex, and using a GAMLSS model to create an internal reference
can potentially be an advantage over using an external data (Vogel 2017).
References:
Agrawal M, Christensen HS, Bøgsted M, Colombel J-F, Jess T, Allin KH. The rising
burden of inflammatory bowel disease in Denmark over two decades: a nationwide
cohort study. Gastroenterology. 2022.
Andersen MP, Wiingreen R, Eroglu TE, Christensen HC, Polcwiartek LB, Blomberg
SNF, et al. The Danish National Child Health Register. Clin Epidemiol. 2023;1087–94.
Bonfils L, Karachalia Sandri A, Poulsen GJ, Agrawal M, Ward DJ, Colombel JF, Jess
T, Allin KH. Medication-Wide Study: Exploring Medication Use 10 Years Before a
Diagnosis of Inflammatory Bowel Disease Am J Gastroenterol 2023;118:2220–2229.
Borghi E, de Onis M, Garza C, Van den Broeck J, Frongillo EA, GrummerဨStrawn L,
et al. Construction of the World Health Organization child growth standards: selection
of methods for attained growth curves. Stat Med. 2006;25(2):247–65.
Brusco De Freitas M, Poulsen GJ, Jess T. Anthropometric trajectories in children prior
to the development of inflammatory bowel disease. JAMA Network Open 2025 (in
press).
Cole TJ. Sample size and sample composition for constructing growth reference
centiles. Statistical Methods in Medical Research 2021, Vol. 30(2) 488–507.
Ishige T. Growth failure in pediatric onset inflammatory bowel disease: mechanisms,
epidemiology, and management. Transl Pediatr 2019;8(1):16-22
Stasinopoulos DM, Rigby RA. Generalized additive models for location scale and
shape (GAMLSS) in R. J Stat Softw. 2008;23:1–46.
Tinggaard J, Aksglaede L, Sørensen K, Mouritsen A, Wohlfahrt-Veje C, Hagen CP, et
al. The 2014 Danish references from birth to 20 years for height, weight and body
mass index. Acta Paediatrica, International Journal of Paediatrics. 2014;103(2).
Vestergaard MV, Allin KH, Poulsen GJ, Lee JC, Jess T. Characterizing the pre-clinical
phase of inflammatory bowel disease. Cell Rep Med. 2023;4(11).
Vogel M, Kirsten T, Kratzsch J, Engel C, Kiess W. A combined approach to generate
laboratory reference intervals using unbalanced longitudinal data. J Pediatr Endocrinol
Metab 2017; 30(7): 767–773.

14
GDPR and other issues in reporting multiple outcomes to a common exposure
By Klaus Rostgaard
Danish Cancer Institute, Danish Cancer Society, Copenhagen
klar@cancer.dk
Abstract
It is a common and non-trivial task to devise a sensible categorization of a battery of
disease outcomes to a common exposure. Obstacles/constraints include what can be
communicated exactly (sufficient numbers of outcomes), what makes subject matter
sense, what is relevant for the study, and changes in disease classification over the
study, to mention a few. Here, we devise a simple semi-automated algorithm to deal
with all mentioned obstacles.
Introduction – set-up and working example
The simplest and most common situation in which we report associations between
multiple outcomes and a common exposure is when we communicate standardized
incidence ratios (SIRs). A SIR Ri=Oi/Ei is the ratio between observed (Oi) and
expected (Ei) number of events (incidences of disease i) when following an exposed
cohort, the exposure being e.g. a specific occupation or a history of a specific disease.
The expectation Ei is usually calculated by summing products of sex-, age-, period-
and cohort-specific incidence rates for disease i assessed in the national/regional
cohort of people that the exposed cohort is nested within and correspondingly
characterized time at risk in the exposed cohort [1]. The statistical analysis of SIRs is
usually based on a Poisson model Oi~Pois(RiEi), where the null hypothesis is Ri=1 and
inference is about the parameter log(Ri) [1].
In practise the multiple outcomes we want to present typically represent a more or less
complete non-overlapping categorization of the spectrum of diseases or cancer forms.
Often we also want to present results for aggregated categorizations of outcomes, e.g.
disease chapters (International classification of diseases – ICD) and organ systems (for
cancers – ICDO) and finally for “any disease” and “any cancer”. Supplementary ad
hoc groupings, e.g. smoking-related cancers, are also common.
As our working example throughout, we will use a purely register-based study by
Andersen et al. [2] where we follow a cohort of 13,919 Danes with a hospital
diagnosis of the skin disease hidradenitis suppurativa (the exposure), for the
occurrence of a battery cancer forms (the outcomes), assessed in the Danish Cancer
Register.
15
Challenges in presenting and analysing SIRs with low event counts
Data stewards, such as Statistics Denmark and the Danish Health Data Authority
require that Oi=0 or >x, x typically 2 or 4, in order for them to be presented. When
combining outcomes into a group of outcomes G we have OGd¦iG Oiand EGd¦iG Ei
and de facto equalities when the numbers are small. Hence, we would very often have
the data for small residual groups revealed if we present numbers for both a main
group (an organ system) and all major cancers in that organ system. We also note, that
there is nothing “informative” or surprising in observing Oi=0, unless Ei is
substantially larger, which we could formalize in a criterion that Eishould be at least 3
or 5, symmetrical to the conditions for Oi. However, many applications of examining
many outcomes at a time would be aiming only at circumstances of “too much”, say in
recipients of blood transfusions [3]. In such cases, the occurrences of Oi=0 are of
limited interest. Furthermore, if Oi is just slightly less extreme we are not allowed to
report it exactly. So, in the following, we will concentrate only on outcomes for which
Oi is larger than some small integer x. For any(?) form of inference intended for an
ensemble of outcomes, say a correction for mass-significance, it is a problem that the
restrictions imposed by the data stewards are on the outcomes, the Ois, rather than
what we know a priori, the Eis.
Another set of choices and challenges comes before reaching this point. Tradition has
some classifications to offer, but changing classifications over a long time span of
follow-up may not be entirely consistent and satisfactory. Furthermore, what is lumped
together will often not be the same depending on whether the classification is geared
towards the presention of diseases or the genetic causes of it [3–8].
For documentation and sanity, it should be a given constraint that any grouping
employed should group together entities defined in other classifications.
One computationally good thing about this example (examining SIRs) is that you can
figure out what groupings to use, only studying persons with events of potential
interest. So, it can be made up of just tiny slivers of follow-up time around outcome
events in the exposed cohort.
If the number of groupings under consideration are modest, as in our example of
cancer forms, we can manually find out what groupings we prefer within the given
constraints, as we did in [2]. If the goal is wider, say scanning essentially the complete
spectrum of diseases [3], our approach preferably should be more algorithmic, for
reasons of logistics and documentation.
A semi-automated bottom-up algorithm for generating presentable output
The above to us suggests a simple algoritm for generating the grouping of outcomes to
be used that at all times stays compliant with revealing no Oi below some small
number x, while at the same time leaving a few choices open to the investigator, when
not all categories become large enough in the first two steps.
16
Algorithm
1) Generate Oi for all categories at the most detailed level, Oi<x are represented as
such.
2) Combine all categories within a main group for which Oi<x. Repeat 1) with
these substitutions for small categories.
3) For combined categories for which Oi<x decide to either 1) discard the
category, including from the definition of the main group or 2) combine it with
another category of your choice within the main group. Repeat step 2 with these
new categories.
4) Define main group categories based on the categories in 3). A main group is
dropped if the corresponding Oi<x.
5) Define the top level category (“Any cancer”) as you please.
6) Calculate everything according to the union of the categories in steps 4) to 6).
References
1. Rostgaard K. Methods for stratification of person-time and events - a
prerequisite for Poisson regression and SIR estimation. Epidemiol Perspect
Innov 2008; 5:16.
2. Andersen R, Rostgaard K, Pedersen O, Jemec GBE, Hjalgrim H. Increased
cancer incidence among patients with hidradenitis suppurativa - a Danish
nationwide register study 1977-2017. Acta Oncol 2024; 63:220–228.
3. Dahlén T, Zhao J, Busch MP, Edgren G. Using routine health-care data to search
for unknown transfusion-transmitted disease: a nationwide, agnostic
retrospective cohort study. Lancet Digit Heal 2024; 6:e105–e113.
4. Hebbring SJ. The challenges, advantages and future of phenome-wide
association studies. Immunology 2014; 141:157–165.
5. Wang L, Zhang X, Meng X, et al. Methodology in phenome-wide association
studies: a systematic review. J Med Genet 2021; 58:720–728.
6. Wu P, Gifford A, Meng X, et al. Mapping ICD-10 and ICD-10-CM Codes to
phecodes: Workflow development and initial evaluation. JMIR Med Informatics
2019; 7:1–13.
7. Pedersen MK, Eriksson R, Reguant R, et al. A unidirectional mapping of ICD-8
to ICD-10 codes, for harmonized longitudinal analysis of diseases. Eur J
Epidemiol 2023; 38:1043–1052.
8. Bastarache L. Using Phecodes for Research with the Electronic Health Record:
From PheWAS to PheRS. Annu Rev Biomed data Sci 2021; 4:1–19.
Imputering af manglende blodprøver i
laboratoriedatabasen
Frederik Lykke Petersen1&S¨oren M¨oller1,2
1Open Patient data Explorative Network, Odense Universitetshospital
2Klinisk Institut, Syddansk Universitet
1 Introduktion
Laboratoriedatabasens (lab-databasens) forskertabel best˚ar af mindst 1,9 milliarder prøvesvar
fra landets klinisk biokemiske og klinisk immunologiske laboratorier, indsamlet siden 2008.
Hovedparten best˚ar af blodprøver kodet som NPU-koder. Til berigelse af en population
kan lab-databasen leveres til eksempelvis Danmarks Statistiks forskermaskine. Hvis for-
skeren ønsker anvendelse af tabellen i Stata p˚a en stor population, kræves data-klargøring,
primært pga. datastørrelsen (især hvis den komplet p˚a hele befolkningen) og manglende
standardisering af variable. I dette bidrag gennemg˚as nogle kodningsmæssige uklarheder
i lab-databasen, og hvordan disse kan løses vha. SAS formater.
Som eksempel p˚a analyse af mønstret i manglende blodprøver i lab-databasen p˚aen
population, tager vi udgangspunkt i det igangværende AI-HEMO projekt som er forankret
p˚a Aalborg Universitet i samarbejde med bl.a. Hæmatologisk afdeling, OUH og OPEN,
OUH. I projektet analyseres sammenhængen mellem sjældne arvelige blodsygdomme og
let tilgængelige blodprøver, som i fremtiden skal anvendes til at danne en prædiktionsmo-
del i lavindkomstlande. I en del af projektet defineres udfaldet som binært - havende en
sjælden arvelig blodsygdom (N ca. 6000) eller ej, og disse matches med raske kontroller
p˚a alder og køn (N ca. 281.000), hvor indeksdato er casens dato for diagnosticering.
Prædiktorerne er otte forskellige prøver samt alder og køn. For hver relevant prøvetype
har vi indsamlet den senest registrerede blodprøve før indeksdato og kun beholdt denne til
analyse. I kohorten er symptomspecifikke blodprøvetyper mangelfulde p˚a den symptomfri
befolkning. Denne mangel er problematisk hvis variablene anvendes direkte som prædiktor
for udfaldet. Til h˚andtering af mangelfuldheden kan anvendes imputering, eksempelvis i
Stata.
En stærk antagelse i de følgende analyser er at mangelfuldheden er tilfældig (Eng: Mis-
sing at random). Hermed antages at mangelfuldheden er relateret til observerede variable,
men ikke til uobserverede variable. I blodprøver er dette desværre meget usandsynligt,
da prøvetagningsfrekvensen er højt korreleret til udfaldet, især for sjældnere symptom-
specifikke blodprøvetyper. Med andre ord; I mange tilfælde er det kun patienter som er
symptomatiske, som f˚ar specifikke prøvetyper taget, en form for konfundering ved indika-
tion for mekanismen bag de manglende data, n˚ar udfaldet udelades af modellen.
2 Kodningsmæssige uklarheder – SAS formater
Data leveres i SAS format, og konverteres dette direkte til Stata, bliver alle værdier
til tekstfelter som kræver megen diskplads. En optimeringsmulighed er at transformere
17

hver unik tekstbid en-til-en til et heltal og anvende SAS formater. For variable som har
f˚a unikke værdier er løsningen meget simpel. Eksempelvis findes variablen operator der
angiver om den rapporterede m˚aling er større eller mindre end de faktiske m˚alte værdi.
proc format ;
value operator label
1 = ”Storre end”
2 = ”Mindre end ”;
run ;
De bagvedliggende heltal svarende til operator dannes vha. if statements og formateres
med operator label i et data-step.
data lab ;
set ekstern . lab dm forsker (keep operator );
rename operator new = operator ;
if operaotor = ”stoerre end” then operator new = 1;
if operator = ”mindre end” then operator new = 2;
drop operator ;
format operator new operator label .;
run ;
Som supplement til prøverne leveres en oversigt over samtlige laboratoriekoder (lab dm labidcodes).
Disse kan oversættes til et format i et data-step.
data lab idcode label (rename=(idcode=label ));
set ekstern . lab dm labidcodes (keep=idcode );
start = n ;
fmtname = ’ idcodefmt ’ ;
type = ’N’ ;
run ;
For de resterende ikke-numeriske variable skal samtlige unikke værdier for variablene
findes, før et formatbibliotek kan dannes. Eksempelvis unit som indeholder prøvernes
m˚aleenhed. Dette gøres i et SQL-step som derefter anvendes i et data-step der danner
formatet som i ovenst˚aende.
proc sql ;
create table unique unit as
select distinct unit
from ekstern . lab dm forsker ;
quit ;
data unit label ;
...
run ;
proc format cntlin unit label ;
run ;
18

Data lab indeholder stadig unit tekstbidder, derfor skal de numeriske værdier kobles p˚ai
et SQL-step med select. Nedenfor en simplificeret udgave, kun p˚aunit. *Bemærk at dette
kan muligvis løses simplere.
proc sql ;
create table lab merged
as select A.∗, B. start as unit
from lab as A
left join unit label as B
on A. unit = B. label ;
quit ;
Iovenst˚aende skal * erstattes med samtlige variable der ønskes bibeholdt, bortset fra unit,
eks. A.var1,A.var2.HuskatB.start er heltalsvariablen i formatet unit label. Til sidst
eksporteres data til Stata. Filerne opdeles p˚a prøvekoder (DNK/NPU) vha. makroer.
Koden hertil er udeladt.
3 Imputering af blodprøvedata
Vores blodprøvedata har ikke-monoton arbitrær mangelfuldhed. Dette vil sige, at variab-
lene X1,X
2,...,X
pikke kan permuteres s˚aledes at den næstkommende variabel i rækken
har manglende værdier i samme observationer som foreg˚aende [1].
Flere muligheder til modellering af manglende værdier vha. imputation under ovenst˚aende
antagelse eksisterer, herunder prædiktiv middelværdimatchning (PMM) vha. K nærmeste
naboer (KNN) og Bayesiansk multivariat normal regression (MVN). Paradigmemæssigt er
disse to vidt forskellige. Et vigtigt m˚al for frekventister er ofte at kunne beskrive modeller
eksakt vha. deres parameterisering. Dette behov kan i høj grad stilles ved at anvende MVN
fremfor PMM da PMM modeller parameteriseres som en samling vektorer, dimensioneret
p˚a de uafhængige variable, og kræver relativt mere information end MVN, og modellens
størrelse (i b˚ade parametre og pladsforbrug) derfor vokser med antal observationer og ikke
blot med antal variable. MVN regressionsmodeller beskrives som p˚a modelformen af en
multivariat normalfordeling som
X∼MVN(μ, Σ),(1)
hvor X best˚ar af en observeret og uobserveret del. Dette tillader at alle uobserverede
Xi,i=1,...,n kan afhænge af observerede Xi,i=1,...,n.
Imputationerne dannes vha. en iterativ Markovkæde Monte Carlo (MCMC) model
indtil konvergens er opn˚aet. Detaljer herom er udeladt og kan læses i Stata dokumenta-
tionen [1]. I praksis udføres imputeringer i det følgende eksempel fra AI-HEMO projektet.
For overskuelighed dannes modeller p˚a samtlige variable nødvendigt, men kun variablene
for m˚alinger af hæmoglobin og RDW (Red Cell Distribution Width) analyseres i detaljer.
4 Imputering i Stata
4.1 Dataindhold
I Stata beskriver vi mangelfuldheden for m˚alinger af hæmoglobin og RDW p˚a individni-
veau vha Statas misstable.
19

. misstable sum hemoglobin rdw i f case = = 1
Variable |Obs=. Obs>.Obs<.
−−−−−−−−−−− +−−−−−−−−−−−−−−−−−−−−−−−−−−−
hemoglobin |1,122 4 ,768
rdw |4,591 1 ,299
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
. misstable sum hemoglobin rdw i f case = = 0
Variable |Obs=. Obs>.Obs<.
−−−−−−−−−−− +−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
hemoglobin |167,932 113 ,353
rdw |257,466 23 ,819
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Første kolonne (Obs=.) viser at RDW er langt mere mangelfuld end hæmoglobin b˚ade
for cases og kontroller.
4.2 Imputering
Vi udfører imputation af manglende variable vha. MVN. Variable som imputeres registre-
res som imputed og forklarende variable som regular:
. mi set wide
. mi register imputed hemoglobin rdw ( . . . )
. mi register regular case age koen
Der imputeres, og modelparametrene for hver MCMC iteration gemmes i ptrace.dta indtil
konvergens.
. mi impute mvn hemoglobin rdw ( . . . ) = i . koen age , ///
saveptrace(ptrace)
For hver iteration i MCMC opdateres parametrene, og disse gemmes som en ny række
iptrace. Parametrene vil kunne anvendes til at trække stikprøver fra den konvergerede
model, s˚a ny data kan imputeres p˚a den specificerede model. Stata har ikke en indbygget
funktion til dette. Bemærk, at udfaldet er udeladt fra imputationerne, da det i praksis
ikke vil være tilgængeligt, n˚ar der skal foretages prædiktioner p˚a nye data. Det kunne
være et interessant fremtidigt studie at sammenligne kvaliteten af imputationerne med og
uden inkludering af udfaldet.
Vi vurderer nøjagtigheden af imputationerne ved at analysere hæmoglobin- og RDW-
m˚alinger.
. foreach v in hemoglobin rdw{
misstable summarize ‘v ’ , gen ( mis ‘v’)
mi xeq 1: summarize ‘v ’ i f mis ‘ v ’ = = 0; ///
summarize ‘v ’ i f mis ‘v ’ = = 1; ///
summarize ‘v ’
}
20

For hæmoglobin:
m=1 d a t a :
//For ikke−manglende data
−>summarize hemoglobin if mis hemoglobin = = 0
Variable |Obs Mean Std . dev .
−−−−−−−−−−−−− +−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
hemoglobin |156,632 8.57 1.08
//For manglende data
−>summarize hemoglobin if mis hemoglobin = = 1
Variable |Obs Mean Std . dev .
−−−−−−−−−−−−− +−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
//For manglende og ikke−manglende kombineret
hemoglobin |224,761 8.67 1.09
−>summarize hemoglobin
Variable |Obs Mean Std . dev .
−−−−−−−−−−−−− +−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
hemoglobin |381,393 8.63 1.09
For RDW:
m=1 d a t a :
//For ikke−manglende data
−>summarize rdw i f mis rdw = = 0
Variable |Obs Mean Std . dev .
−−−−−−−−−−−−− +−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
rdw |33,248 .14 .40
//For manglende data
−>summarize rdw i f mis rdw = = 1
Variable |Obs Mean Std . dev .
−−−−−−−−−−−−− +−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
rdw |348,145 .14 .40
//For manglende og ikke−manglende kombineret
−>summarize rdw
Variable |Obs Mean Std . dev .
−−−−−−−−−−−−− +−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
rdw |381,393 .14 .40
Ovenst˚aende viser at middelværdier og standardafvigelser for imputationerne afviger ube-
tydeligt fra statistikkerne p˚a observeret data.
Figur 1 og 2 illustrerer fordelingen af de observerede m˚alinger, de imputerede m˚alinger
og de samlede m˚alinger, stratificeret efter case/kontrol.
P˚a figur 1 ses en god overensstemmelse mellem de faktiske og de imputerede værdier
for hæmoglobin. Dette er dog ikke tilfældet for RDW (figur 2), hvor de observerede værdier
for cases viser en meget smal fordeling, som imputationsmodellen ikke form˚ar at gengive
præcist. Denne snævre fordeling ville sandsynligvis blive bedre fanget, hvis udfaldet blev
inkluderet i modellen.
21

Figur 1. Tætheder af hæmoglobinm˚alinger. Bl˚a: Observeret, Rød: Imputeret, Grøn: Kom-
plet
Figur 2. Tætheder af RDW-m˚alinger. Bl˚a: Observeret, Rød: Imputeret, Grøn: Komplet
Dette resultat er overraskende i lyset af summarize-tabellen, hvor middelværdier og
standardafvigelser for de observerede og imputerede værdier var sammenlignelige. Det
tyder p˚a, at imputationerne form˚ar at efterligne middelværdi og standardafvigelse, men
ikke fanger højere momenter som skævhed og kurtosis, der kan være vigtige for at beskrive
fordelingerne nøjagtigt. Derudover har imputationerne ikke en begrænset udfaldsmængde
s˚a imputationerne kan ogs˚a være negative værdier, selvom disse ikke findes for RDW.
Derfor bør valget af imputationsmodel for RDW genovervejes, s˚a imputerede værdier
bedre afspejler observerede værdier, hvilket muligvis kan gøres vha. Statas mi impute
truncreg som tillader trunkering af udfaldsmængden. Det undersøges ikke nærmere om
truncreg bedre kan beskrive fordelingen af RDW.
Litteratur
1. StataCorp. Stata multiple-imputation reference manual release 18. pages 11–12, 2023.
22
:?A;DGIDA@C>C<:G 6; @DCP9:CH>CI:GK6AA:G
-DB C<HI:9
#CHI>IJI ;DG V@DCDB> 6G=JH .C>K:GH>I:I
J<A:H6C<H 6AA: 6G=JH /
B6>A I:C<HI:9:8DC6J9@
:8:B7:G
7HIG68I "0 ". 2"('"*!0 0 "0 '(//&/' '+*6!"*/&*0".2( "."$*"0 & "* $&2"* /0&',.<2"
'* $&2"/ #<($"*!" #+.0+('*&*$ "! /*!/5*(&$%"! (&$$". !"* /*!" ,.)"0".
2;.!& &*!"*#+. &*0".2(("0 ;."<$". *"#(". +#0" (0".*0&2" #+.)1(".&*$". 9 ( "!
'+*6!"*/ (&$$". !"* /*!" ,.)"0".2;.!& &*!"*#+. &*0".2(("0 "((". "!
/&''".%"! (&$$". !"* /*!" ,.)"0".2;.!& &*!"*#+. &*0".2(("0 2! #+./0:/ "$"*0(&$
2"! 7'+*6!"*/7 +$ 7/&''".%"!7 +$ %2+.2"! !/'&((". !" /&$ #. 7/*!/5*(&$%"!7 2! /'(
)* $<." %2&/ )* & "* $&2"* /0&',.<2" <*/'". 0 "."$*" "0 .&$0&$0 /*!/5*(&$%"!/&*0".2(
#+. "* ,.)"0".
%:NLDG9H +*6!"*/&*0".2( /*!/5*(&$%"!/&*0".2( #."'2"*0&/0&/' 2"./1/ 5"/&*/'
/*!/5*(&$%"!/+,#00"(/" ,+(&0&/' )"*&*$/):(&*$
:I @A6HH>H@: 9D77:AIH>9:I @DCP9:CH>CI:GK6A :G :I B:<:I 6CK:C9I G:9H@67 I>A >CI:GK6A:HI>
B6I>DC D< S B:G: <:C:G:AI S I>A 6C<>K:AH: 6; 9:C HI6I>HI>H@: JH>@@:G=:9 DB@G>C< :I EJC@I:H
I>B6I &YG:7[<:G ED>CI:G:G HDB G:<:A 6I 96 :C EDEJA6I>DCHE6G6B:I:G > @A6HH>H@ HI6I>HI>@
>@@: :G :C HID@6HI>H@ HI[GG:AH: @6C :I @DCP9:CH>CI:GK6A >@@: ;DGIDA@:H HDB 6I 9:I B:9
:C <>K:C H6C9HNCA><=:9 INE>H@ >C9:=DA9:G 9:C J@:C9I: EDEJA6I>DCHKYG9> :I :G
C:IDE 9:G;DG 9:I @6A9:H ;DG :I R@DCP9:CH>CI:GK6AR D< >@@: :I RH6C9HNCA><=:9H>CI:GK6AR ;
D< I>A 6CK:C9:H D<HX ;DGBJA:G>C<:C 6I >CI:GK6AA:I B:9 HX D< HX HIDG H>@@:G=:9 >C9:=DA9:G
9:C H6C9: KYG9>
23

&YG:7[<:GC: JC9A69:G 9D< HDB D;I:HI 6I ;DG@A6G: =K69 9:G =:AI EGY8>HI H@6A ;DGHIXH K:9
R@DCP9:CHR D< RH>@@:G=:9R D< =KDGK:9 9>HH: 7:I:<C:AH:G 69H@>AA:G H>< ;G6 RH6C9HNCA><=:9R
# :C <>K:C HI>@EG[K: 6C<>K:G :I @DCP9:CH>CI:GK6A 6I EDEJA6I>DCHE6G6B:I:G:C B:9
@DCP9:CH H>@@:G=:9 A><<:G >C9:C;DG >CI:GK6AA:I "K>H @DCP9:CH H>@@:G=:9 >@@: H@6A
;DGHIXH HDB H6C9HNCA><=:9 =KDG96C H@6A 9:I 96 ;DGHIXH )< =K69 H@6A B6C <[G: =K>H B6C
;6@I>H@ [CH@:G 6I 7:G:<C: :I G><I><I H6C9HNCA><=:9H>CI:GK6A ;DG 9:C J@:C9I: E6G6B:I:G
>HH: HE[G<HBXA 9>H@JI:G:H C:9:C;DG D< 9:G EGYH:CI:G:H :C >AAJHIG6I>DC B:9 J9<6C<HEJC@I
> :C EDA>I>H@ B:C>C<HBXA>C<
" !!! &!" $
# 9:I ;[A<:C9: I6<:H 9:G J9<6C<HEJC@I > :C CDGB6A;DG9:AI EDEJA6I>DC D< :C H>BE:A I>A;YA9><
HI>@EG[K: =KDG IGJ@@:I ;G6 9:CC: EDEJA6I>DC CI6< 6I K> :G
>CI:G:HH:G:I > EDEJA6I>DC:CH B>99:AKYG9> D< =6G :HI>B:G:I HI>@EG[K:<:CC:BHC>II:I
D< HI>@EG[K:K6G>6CH:C I @DCP9:CH>CI:GK6A ;DG ;XH 96 HDB
=KDG :G ;G6@I>A:C > 0;DG9:A>C<:C B:9 ;G>=:9H<G69:G ':9 I>AHIGY@@:A><
HIDG @6C0;G6@I>AKYG9>:C 6EEGD@H>B:G:H K:9 ;G6@I>AKYG9>:C > HI6C96G9 CDGB6A;DG9:A>C
<:C
DG :C <>K:C HI>@EG[K: @6C DK:CHIX:C9: @DCP9:CH>CI:GK6A &''" ;DGIDA@:H HDB 6I 9:I
B:9 H6C9HNCA><=:9 >C9:=DA9:G 9:C H6C9: KYG9> 6; UGH6<:C :G 6I > @A6HH>H@
;G:@K:CI>HI>H@ HI6I>HI>@ :G EDEJA6I>DCHE6G6B:IG: >@@: HID@6HI>H@: HI[GG:AH:G =KDGK:9 9:I
C6IJGA><K>H >@@: <>K:G B:C>C< 6I @DBB: B:9 H6C9HNCA><=:9HBYHH><: J9H6<C DB HX96CC:
E6G6B:IG: ,I>@EG[K::HI>B6I:G 6; EDEJA6I>DCHE6G6B:IG: 9:G>BD9 :G HID@6HI>H@: =KDGK:9
@DCP9:CH>CI:GK6AA:IH <GYCH:G 7A>K:G HID@6HI>H@: /:9 <:CI6<:C HI>@EG[K:J9I6<C>C< ."
,"0"! /),(&*$ ;XH 9:C HI6I>HI>H@: ;DG9:A>C< ;DG =KDG6C<>K:G HI6C96G96;K><:AH:C
>RH ;DG9:A>C<
:C @DGG:@I: ;DGIDA@C>C< 6; @DCP9:CH>CI:GK6AA:I 7A>K:G =:GB:9 6I =K>H B6C <:CI6<C:
<6C<: IGY@@:G CN: HI>@EG[K:G ;G6 EDEJA6I>DC:C D< 7:G:<C:G :I @DCP9:CH>CI:GK6A >
=K:G 6; 9>HH: K>A 6; 9>HH: >CI:GK6AA:G >C9:=DA9: 9:C H6C9: KYG9> 6; '6C H><:G D<HX
6I >CI:GK6AA:I =6G +2".$" ,.+&(&05
24
:I :G K><I><I 6I JC9:GHIG:<: 6I #+. !"* $&2*" /0&',.<2" ;DGIYAA:G @DCP9:CH>CI:G
K6AA:I >CI:I H6C9HNCA><=:9HBYHH><I DB E6G6B:I:G:C : ;DGIYAA:G CD<:I H6C9HNC
A><=:9HBYHH><I DB 9:C ,.+ "!1." 9:G 7:HIXG > 6I 7:G:<C: :I @DCP9:CH>CI:GK6A <:C
I6<C: <6C<: > #+./'"((&$" /0&',.<2". $:GON (:NB6C RDEPC9:G:CR 6; 9:I @A6HH>H@: @DC
P9:CH>CI:GK6A K6G B:<:I >CH>HI:G:C9: EX 9:C H@:AC:C # H>C 9>H@JHH>DC 6;=K69I=:
EG68I>86A HI6I>HI>8>6C @6C J9A:9: 6; :I @DCP9:CH>CI:GK6A 7:G:<C:I ;DG :C @DC@G:I
HI>@EG[K: H><:G =6C 6I CXG 9:CC: EG68I>86A HI6I>HI>8>6C J9A:9:G 6I EDEJA6I>DCHE6G6
B:I:G:C A><<:G >C9:C;DG >CI:GK6A<GYCH:GC: 96 <YA9:G 9:I 6I >C I=: ADC< GJC =: L>AA 7:
8DGG:8I >C 67DJI E:G8:CI D; 6AA 86H:H (:NB6C E # ;DGAYC<:AH: =:G6;
H><:G (:NB6C I=: EGD767>A>IN HI6I:B:CIH G:;:G ID I=: EGD7A:B D; :HI>B6I>DC L>I= L=>8=
I=: HI6I>HI>8>6C L>AA 7: 8DC8:GC:9 &* 0%" #101." DCH>9:G CDL I=: 86H: L=:C 6 H6BEA:
>H 6AG:69N 9G6LC 6C9 I=: 86A8JA6I>DCH =6K: <>K:C 3I=: 8DCP9:C8: >CI:GK6A46CL:H6N
I=6I &* 0%&/ ,.0& 1(. /" I=: EGD767>A>IN D; I=: IGJ: K6AJ: D; 3I=: E6G6B:I:G4 ;6AA>C<
7:IL::C 3I=: 8DCP9:C8: A>B>IH4 >H :FJ6A ID 3M4 -=: 6CHL:G >H D7K>DJHAN >C I=: C:<6I>K:
B>C @JGH>K:G>C< I @DCP9:CH>CI:GK6A 7:G:<C:I > :C @DC@G:I HI>@EG[K: :CI:C >C9:=DA9:G
:AA:G >C9:=DA9:G >@@: 9:C H6C9: KYG9> 6; E6G6B:I:G:C )K:CHIX:C9: @DGG:@I: ;DGIDA@C
>C< 6; :I @DCP9:CH>CI:GK6A :G C6IJGA><K>H 6Q:9I 6; 9:C HYGA><: H6C9HNCA><=:9HDE;6II:AH:
HDB @:C9:I:<C:G @A6HH>H@ ;G:@K:CI>HI>H@ HI6I>HI>@ (:NB6C =:CK>H:G Q:G: HI:9:G
I>A 6I RH6C9HNCA><=:9R H@6A ;DGHIXH HDB (+*$.1* ."(0&2" #."-1"* 5 > BD9HYIC>C< I>A 9:C
76N:H>6CH@: H6C9HNCA><=:9HDE;6II:AH: H: 6;HC>I
I 9:I @A6HH>H@: @DCP9:CH>CI:GK6A 6A:C: H><:G CD<:I H6C9HNCA><=:9HBYHH><I DB :C EGD
8:9JG:H :<:CH@67:G > .","0"! /),(&*$ >AAJHIG:G:G 9:AH 9: 6CK:C9:AH:HBYHH><: 7:<GYC
HC>C<:G K:9 :I HX96CI >CI:GK6A H6BI>9>< B:9 6I 9:I X7C:G ;DG 9>K:GH: ;:?A;DGIDA@C>C<:G >
@DC@G:I: 6CK:C9:AH:G
"
,DB 7:H@G:K:I DK:C;DG <>K:G :I @A6HH>H@ @DCP9:CH>CI:GK6A >C<:C H6C9HNCA><=:9HBYHH><
>C;DGB6I>DC DB 9:C J@:C9I: E6G6B:I:G 76H:G:I EX :C @DC@G:I HI>@EG[K: &YG:7[<:G
7:H@G>K:G D;I: :I M @DCP9:CH>CI:GK6A S 7:G:<C:I > :C @DC@G:I HI>@EG[K: S EX9:CBX9:
6I 9:I B:9 M '+*6!"*/ :AA:G /&''".%"! >C9:=DA9:G 9:C H6C9: E6G6B:I:GKYG9> ':C
AYG:7[<:GC: ;DG@A6G:G HDB G:<:A >@@: =K69 9:G =:AI EGY8>HI H@6A ;DGHIXH K:9 R@DCP9:CHR
:AA:G RH>@@:G=:9R ,DB K> =6G H:I :G 9>HH: 7:I:<C:AH:G >@@: 7ADI 6AI:GC6I>K:G I>A DG9:I
RH6C9HNCA><=:9R B:C =K69 :G 9: HX
25
(XG B6C S B:9 9: 96I6 9:G J9<[G :CH HI>@EG[K: S =6G 7:G:<C:I :I M @DCP9:CH>C
I:GK6A ;DG :C E6G6B:I:G A><<:G 9:I HCJ7A:C9: CYG 6I ;DGIDA@: ':9 M @DCP9:CH :AA:G
H>@@:G=:9 A><<:G 9:C H6C9: KYG9> 6; > >CI:GK6AA:I HDB HJ7HI6CI>:AI >9:CI>H@ B:9 ':9 M
H6C9HNCA><=:9 A><<:G 9:C H6C9: KYG9> 6; > >CI:GK6AA:I ':C 7GJ< 6; DG9:C: R@DCP9:CHR
:AA:G RH>@@:G=:9R > HI:9:I ;DG RH6C9HNCA><=:9R @6C >@@: H@?JA: 6I :I @A6HH>H@ @DCP9:CH>CI:G
K6A > :C <>K:C HI>@EG[K: G::AI >CI:I >C;:G:CHBYHH><I ;DGIYAA:G DB B:C 6A:C: ;DGIYAA:G
CD<:I DB :<:CH@67:GC: K:9 ,.+ "!1."* B:9 6I 7:G:<C: @DCP9:CH>CI:GK6AA:G > <:CI6<C:
HI>@EG[K:G IGJ@@:I ;G6 EDEJA6I>DC:C
# :C EG6@I>H@ :AA:G 6CK:C9:AHDG>:CI:G:I @DCI:@HI =KDGCXG :G :C HI6I>HI>H@ EGD8:9JG:H
H6C9HNCA><=:9HBYHH><: :<:CH@67:G > <:CI6<C: 6CK:C9:AH:G 96 >CI:G:HH6CI: I :@H:B
E:A =:GEX :G HI6I>HI>H@ @K6A>I:IH@DCIGDA > EGD9J@I>DCHK>G@HDB=:9:G C ;67G>@ EGD9J8:G:G
9>BH:9JII:G 9:G H@6A DK:G=DA9: 9>K:GH: @K6A>I:IHBXA "K:G 96< J9I6<:H :CHI>@EG[K:6;
9>BH:9JII:G ;G6 EGD9J@I>DC:C D< @K6A>I:I:C I:HI:H ":G :G 9:C :C@:AI: HI>@EG[K: >@@:
>CI:G:HH6CI > H>< H:AK :I >CI:G:HH6CI: :G > HI:9:I DB B6C > 9:C H6BA:9: EGD9J@I>DC
6; 9>BH:9JII:G EX A6C<I H><I H>@G:G H>< 6I 6C9:A:C 6; ;:?A7:=Y;I:9: 9>BH:9JII:G =DA9:H
EX EGYHE:8>P8:G:I C>K:6J : @A6HH>H@: HI6I>HI>H@: EGD8:9JG:G > ;DGB 6; @DCP9:CH>CI:G
K6AA:G D< (:NB6C*:6GHDC =NEDI:H:I:HI :G >9::AA: > HX96CC: H6BB:C=YC<: ->A <:C<YA9
;DG:@DBB:G 9:I EGD7A:B6I>H@ 6I 6CK:C9: 9>HH: EGD8:9JG:G CXG 96I6 ;DG:A><<:G HDB E6HH>KI
D7H:GK:G:9: >@@::@HE:G>B:CI:AA: *+*.","0(" RHI>@EG[K:GR =KDG ;DGBXA:I B:9 6C6AN
H:C :G 6I 9G6<: >C;:G:CH DB :C E6G6B:I:G :AA:G BD9:A 76H:G:I EX ZI @DC@G:I 96I6HYI
C<HI:9 6C9 ,8=C:>9:G 9>H@JI:G:G 9:CC: EGD7A:BHI>AA>C< B:G: 9:I6A?:G:I
I 9:I @A6HH>H@: @DCP9:CH>CI:GK6A 6A:C: H><:G CD<:I DB +2".$" ,.+&(&05 &* ."
,"0"! /),(&*$ >C9:7YG:G H6BI>9>< 6I B6C >CI:I @DCP9:CH :AA:G H>@@:G=:9HBYHH><I
:C9H><: H6C9HNCA><=:9HBYHH><I @6C H><: DB :C@:AIKYG9>:G :AA:G 9:A>CI:GK6AA:G >C9:C;DG
@DCP9:CH>CI:GK6AA:I #CIJ>I>KI K>A K> D;I: =6K: 9:C DE;6II:AH: 6I KYG9>:G DB@G>C< B>9I:C 6;
>CI:GK6AA:I :G B:G: RH6C9HNCA><:R RIGDKYG9><:R REA6JH>7A:R EX :C<:AH@ (&'"(5:C9KYG9>:G
IYI EX >CI:GK6A<GYCH:GC: ':C :C HX96C >CIJ>I>K DE;6II:AH: :G ;:?A6<I>< ,DB DM
E 7:BYG@:G I=: B:I=D9 D; 8DCP9:C8: >CI:GK6AH <>K:H DCAN DC: >CI:GK6A 6I
HDB: EG:H:A:8I:9 A:K:A D; EGD767>A>IN L=:C L: LG>I: 9DLC I=: 8DCP9:C8: >CI:GK6A
;DG 6 8DBEA:I:AN JC@CDLC CDGB6A B:6C I=:G: >H 8:GI6>CAN 6 H:CH: >C L=>8= I=:JC@CDLC
B:6C >H A>@:AN ID A>: C:6G I=: 8:CIG: D; I=: >CI:GK6A 6C9 G6I=:G JCA>@:AN ID A>: C:6G I=:
:C9H 6C9 >C L=>8= >C I=>H 86H: :K:C >; 9D:H A>: DJIH>9: I=: >CI:GK6A >I >H EGD767AN CDI
;6G DJIH>9: -=: JHJ6A I=:DGN D; 8DCP9:C8: >CI:GK6AH <>K:H CD 9>G:8I :MEG:HH>DC D; I=:H:
;68IH
"6G B6C :@H:BE:AK>H 7:G:<C:I ;[A<:C9: @DCP9:CH>CI:GK6A ;DG 3 4 D<
26

CJ <:GC: K>A K>9: B:9 =K>A@:C @DCP9:CH H>@@:G=:9 A><<:G > >CI:GK6AA:I 3 4
:G B6C EX ":GG:CH B6G@ 9:I @A6HH>H@: @DCP9:CH>CI:GK6A BJA><<[G >@@: 7:HK6G:AH: 6;
9:II: HE[G<HBXA 76N:H>6CH@: H6C9HNCA><=:9H>CI:GK6AA:G 9:G>BD9 :G 9>G:@I: 9:H><C:I I>A
7:HK6G:AH: 6; HX96CC: HE[G<HBXA H: 6;HC>I
:BYG@ 6I 96 >CI:GK6A<GYCH:GC: :G HID@6HI>H@: K6G>:G:G ;G6 HI>@EG[K: I>A HI>@EG[K:
:G =:AA:G >@@: ;[A<:C9: ;DGIDA@C>C< @DGG:@I ;DG DK:CHIX:C9: >CI:GK6A 3 4 "K>H
K> <:CI6<:G :@HE:G>B:CI:I B6C<: <6C<: EX CN: HI>@EG[K:G 96 K>A 9:C H6C9: KYG9> 6; >
6; I>A;YA9:C: A><<: > >CI:GK6AA:I 3 4
-=: 7DIIDB A>C: :G 6I :I @A6HH>H@ @DCP9:CH>CI:GK6A 7:G:<C:I > :C <>K:C HI>@EG[K:
>C<:C H6C9HNCA><=:9HBYHH>< :K>9:CH >C9:=DA9:G DB 9:C JC9:GA><<:C9: EDEJA6I>DCHE6
G6B:I:G )B @DCP9:CH>CI:GK6AA:I >C9:=DA9:G CD<:C ;DGB ;DG R:K>9:CHR DK:G=DK:9:I DB
E6G6B:I:G:C :G :I X7:CI HE[G<HBXA ?:< :G I>A7[?:A>< I>A 6I H><: C:?"K>H B6C :G
>CI:G:HH:G:I > H6C9HNCA><=:9HBYHH>< :K>9:CH DB :C E6G6B:I:G S :AA:G BD9:A S BX B6C
6CK:C9: 76N:H>6CH@: B:ID9:G H: CYHI: 6;HC>I
!%!" $
&69 DH CJ > HI:9:I DE;6II: EDEJA6I>DCHE6G6B:IG: HDB HID@6HI>H@: HI[GG:AH:G =K>A@:I :G
=K69 B6C <[G >C9:C;DG 76N:H>6CH@ HI6I>HI>@ :C H6C9: KYG9> 6; :C <>K:C E6G6B:I:G
:G J@:C9I D< KDG:H W EG>DG> JH>@@:G=:9 DB KYG9>:C 7:H@G>K:G K> K:9 :C H6C9HNCA><=:9H
:AA:G IYI=:9H;DG9:A>C< #C;DGB6I>DC:C > 96I6 DEHJBB:G:G K> <:CC:B A>@:A>=DD9
;JC@I>DC:C D< W EDHI:G>DG> ;DG9:A>C<:C ;DG ;XH 96 S B:9 6CK:C9:AH: 6; 6N:HR
;DGB:A S HDB
T EDHI:G>DG> ;DG9:A>C<:C J9IGN@@:G KDG:H JH>@@:G=:9 DB HDB :C @DB7>C6I>DC
6; KDG:H W EG>DG> JH>@@:G=:9 D< 9:C >C;DGB6I>DC DB HDB 96I6 <>K:G DH A HI6I>H
; D< I>A 6CK:C9:H :I @DCP9:CH>CI:GK6A HDB BXA ;DG 9:C EGY8>H>DC B:9 =K>A@:C :C E6G6B:I:G :H
I>B:G:H ':C D<HX 9:II: :G EGD7A:B6I>H@ H: 'DG:N :I 6A !:C:G:AI >C9:C;DG ;G:@K:CI>HI>H@
HI6I>HI>@ H@6A HI6I>HI>H@ JH>@@:G=:9 DE;6II:H HDB HI>@EG[K:JH>@@:G=:9 9:G BXA:H K:9 HEG:9C>C<:C > :C
HI6I>HI>@H HI>@EG[K:;DG9:A>C< :@H:BE:AK>H HDB:GRH HI6C96G96;K><:AH: ?; 6;HC>I $D B>C9G:
HI6C96G96;K><:AH: 9:HID B:G: EGY8>HI 7A>K:G E6G6B:I:G:C :HI>B:G:I 9:II: C6IJGA><K>H JC9:G 6CI6<:AH: 6;
6I .","0"! /),(&*$ 7:<G:7:I DK:G=DK:9:I <>K:G B:C>C< =K>A@:I > =[? <G69 @6C 9>H@JI:G:H CXG 9: JC9:G
A><<:C9: 96I6 :G E6HH>KI D7H:GK:G:9: >@@::@HE:G>B:CI:AA: H6B;JC9HK>9:CH@67:A><: 96I6 ?; C<HI:9 6C9
,8=C:>9:G (XG 9:CC: HI6C96G96;K><:AH: 9:GCYHI 6CK:C9:H I>A 7:G:<C>C< 6; :I M @DCP9:CH>CI:GK6A
;DG B:9 >C99G6<:AH: 6; RH HI>@EG[K:;DG9:A>C< DEHIXG 6AA: 9: ;DGIDA@C>C<HBYHH><: EGD7A:B:G 7:H@G:K:I
DK:C;DG
27

I>H@ >C;:G:CH DB H@:G B:9 J9<6C<HEJC@I > :@H:BE:AK>H 7:G:<C>C< 6; :I M
H6C9HNCA><=:9H>CI:GK6A ;DG E6G6B:I:G:C EX :C<:AH@ @6A9:I ."!&(" &*0".2(
#!" " "! !'
,DB >AAJHIG6I>DC 6; ;DGH@:AA:C B:AA:B :I @A6H>H@ @DCP9:CH>CI:GK6A D< :I 76N:H>6CH@ H6C9HNC
A><=:9H>CI:GK6A A69 DH H: EX 9:C 6C9:A 6; 7:;DA@C>C<:C 9:G K>A HI:BB: EX C=:9HA>HI:C
& =K>H 9:G K6G ;DA@:I>C<HK6A< CI6< 6I H:C:HI: B:C>C<HBXA>C< :G BXA>C<:C ;G6 ':<6
;DC 9:C H:EI:B7:G >;[A<: =K>A@:C & HIXG I>A 6I ;X 6; HI:BB:GC:76H:G:IEX
G:HEDC9:CI:G # BXA>C<:C DE<[G:H 9:C HI6I>HI>H@: JH>@@:G=:9 ;DG & I>A
9:G >Q ':<6;DC 6C<>K:G JH>@@:G=:9<GYCH:C ;DG =KDG B:<:I I6AA:C: > EGD8:CIED>CI @6C
HK>C<: I>A =K:G H>9: >C9:C;DG 9:C HI6I>HI>H@: JH>@@:G=:9 K:9 :I @DCP9:CH>CI:GK6A :I
K>A H><: 6I 9:C ;6@I>H@: EGD8:CI6C9:A B:9 B:<:I HIDG H>@@:G=:9 A><<:G >C9:C ;DG 9:I 6C
<>KC: >CI:GK6A:BYG@ 6CK:C9:AH:C 6; DG9:I RH>@@:G=:9R > HI:9:I ;DG RH6C9HNCA><=:9R
@DCP9:CH>CI:GK6AA:I ;DG & 7:G:<C:H @DC@G:I HDB B:9 6CI6<:AH:C DB :C 7>CD
B>6A;DG9:AI HI>@EG[K:
9KH B:9 @DCP9:CH :AA:G H>@@:G=:9 >@@: H6C9HNCA><=:9 A><<:G 9:C H6C9: 6C9:A 9:G
K>A HI:BB: EX & B:AA:B D< :C =:AI EGY8>H: HI6I>HI>H@: ;DGIDA@C>C< :G 6I
=K>H B6C A6K:G B6C<: HX96CC: B:C>C<HBXA>C<:G D< 7:G:<C:G :I @DCP9:CH>CI:GK6A >
=K:G 6; 9:B 96 K>A 6; >CI:GK6AA:GC: >C9:=DA9: 9:C H6C9: 6C9:A 9:G K>A HI:BB: EX
& 9:I '+*'."0" &*0".2( > 76H:G:I EX ZC BXA>C< :CI:C >C9:=DA9:G :AA:G >C9:=DA9:G
>@@: 9:C H6C9: 6C9:A D< >CI:GK6AA:I <>K:G >C<:C H6C9HNCA><=:9HBYHH>< >C;DGB6I>DC DB
6C9:A:C 6C9:I :C9 9:C IG>K>:AA: 6I H6C9HNCA><=:9:C :G :CI:C :AA:G # EG6@H>H J9
;[G:H 9:G A[7:C9: EDA>I>H@: BXA>C<:G 6; ;DGH@:AA><: B:C>C<HBXA>C<H>CHI>IJII:G D< EDA>I>H@:
@DBB:CI6IDG:G ;DGIDA@:G D;I: 9:C :C@:AI: BXA>C< > H6BB:C=YC< B:9 6C9G: I>AHK6G:C9:
BXA>C<:G KH .","0"! /),(&*$ 7:<G:7:I :G =:G >@@: =:AI K:9 H>9:C 6; =KDGK:9 9:I
@A6HH>H@: @DCP9:CH>CI:GK6A 7A>K:G :I B:C>C<H;JA9I G:9H@67
':C A69 DH CJ 7:G:<C: :I H6C9HNCA><=:9H>CI:GK6A ;DG 6C9:A:C 9:G K>A HI:BB:
EX & D< H6BB:CA><C: 9:I B:9 @DCP9:CH>CI:GK6AA:I > ':9 :C 7>CDB>6A;DG9:AI
=IIEHEDA>I>@:C9@96CB6G@EDA>I>@6GI,:9:CH:C:HI:':<6;DCH6BIGI>:GH
BA>C<:GD<K6A<G:HJAI6I:GHGHAI>9;B)DDMO7B2M+A0;(7C.M9MA"O0N/9=I5
&MN1@H?+<6
28

HI>@EG[K: ;XH A>@:A>=DD9;JC@I>DC:C HDB
=KDG
D< HK6G:C9: I>A :C HI:BB:6C9:A EX &69 DH HI6GI: B:9 6I
6CI6<: :C JC>;DGB W EG>DG> ;DG9:A>C< ;DG 9KH HX96C 6I :I
HK6G:G I>A 6I K> EX ;DG=XC9 >C<:CI>C< K:9 DB &RH H6C9HNCA><: HI:BB:6C9:A #C9HYII:H >
;XH =:GB:9
=K>A@:I HK6G:G I>A :C :I6 ;DG9:A>C< # 9:I @DC@G:I: I>A;YA9: 7A>K:G 9:I
:C :I6 ;DG9:A>C< H6C9HNCA><=:9H>CI:GK6AA:I 7A>K:G 3 4 76H:G:I
EX D< ;G6@I>AKYG9>:GC: > ;DG9:A>C<:C
:C JC>;DGB: W EG>DG> ;DG9:A>C< ;DG @6C ;DG:@DBB: JG:6A>HI>H@ 96 9:CH B>99:AKYG9>
:G D< K> ?D B:9 G:I HIDG H>@@:G=:9 K:9 6I & K>A ;X IYII:G: K:9 :C9
:@H:BE:AK>H 6; HI:BB:GC: =K>H 9:G K6G ;DA@:I>C<HK6A< &69 DH 9:G;DG6CI6<::C
B:G: G:6A>HI>H@ W EG>DG> ;DG9:A>C< /:9 H>9HI: K6A< > CDK:B7:G P@ & D< K:9
':<6;DCH B:C>C<HBXA>C< > 6J<JHI HID9 9: I>A KH J9HK>C< EX EAJHB>CJH
EGD8:CIED>CI :G >@@: JHY9K6CA>< /YA<:G K> 9:G;DG > HI:9:I :C :I6 W EG>DG>
;DG9:A>C< ;XH :I B:G: G:6A>HI>H@ 7>AA:9: 6; & '>99:AKYG9>:C > 9:CC: ;DG9:A>C< :G
D< D< ;G6@I>AKYG9>:GC: :G ==K D< T EDHI:G>DG> ;DG9:A>C<:C
7A>K:G :C :I6 ;DG9:A>C< 9:G =6G B>99:AKYG9> D< =KDG
H6C9HNCA><=:9H>CI:GK6AA:I ;DG 7A>K:G 3 4
:BYG@ =KDG CJB:G>H@ :CH 9: ID H6C9HNCA><=:9H>CI:GK6AA:G :G :BYG@ D<HX =KDG
CJB:G>H@ :CH 9>HH: >CI:GK6AA:G :G B:9 9:I @A6HH>H@: @DCP9:CH>CI:GK6A > :I :G :I
<:C:G6AI G:HJAI6I 6I CXG HI>@EG[K:HI[GG:AH:C :G G:A6I>K HIDG HDB =:G =KDG :G
H6C9HNCA><=:9H>CI:GK6AA:I >@@: HYGA>< ;[AHDB DK:G;DG 9:I EGY8>H: K6A< 6; W EG>DG> ;DG9:A>C<
D< > [KG><I CJB:G>H@ IYI EX 9:I @A6HH>H@: @DCP9:CH>CI:GK6A DG@A6G>C<:C :G 6I CXG
:G HIDG 9DB>C:G:G >C;DGB6I>DC:C > 96I6 A>@:A>=DD9;JC@I>DC:C W EG>DG> ;DG9:A>C<:C
+.0+('*&*$"* 6; 9: ID INE:G >CI:GK6AA:G :G 9D< KYH:CH;DGH@:AA>< ,6C9HNCA><=:9H>CI:GK6AA:I
3 4 =6G 9:C 9>G:@I: ;DGIDA@C>C< 6I 76H:G:I EX 9:C <>KC: HI>@EG[K: D< 9:C
6CI6<:9: W EG>DG> ;DG9:A>C< :G 9:G H6C9HNCA><=:9 ;DG 6I 9:C H6C9: 6C9:A 9:G K>A
!:C:G:AI =K>H W EG>DG> ;DG9:A>C<:C :G :I6 D< HI>@EG[K:C :G 7>CDB>6A;DG9:AI 7A>K:G W EDHI:G>DG>
;DG9:A>C<:C :I6
:II: HIXG > H@6GE @DCIG6HI I>A =NEDI:H:I:HI =KDG G:HJAI6I:I 6; ==K :I @A6HH>H@ I:HI D< :I 76N:H>6CH@
I:HI 6; 9:C H6BB: CJA=NEDI:H: 6;K><:G B:G: D< B:G: ;G6 =>C6C9:C CXG HI>@EG[K:HI[GG:AH:C KD@H:G 9:I
HX@6A9I: "8."5/&*!("5 ,.!+4
29

HI:BB: EX & A><<:G B:AA:B D< %DCP9:CH>CI:GK6AA:I > @6C >@@: <>K:H
:C I>AHK6G:C9: ;DGIDA@C>C< 9:II: >CI:GK6A :G 7ADI ZI J9 6; B6C<: =NEDI:I>H@: >CI:GK6AA:G
DB =K>A@: B6C K:9 6I 6; 9:B >C9:=DA9:G 9:C H6C9: 6C9:A
T EDHI:G>DG> ;DG9:A>C<:C I>AA69:G :C9K>9:G: 7:G:<C>C<:G HXHDB & ,6C9HNC
A><=:9:C ;DG 6I A><<:G B:AA:B ID K>A@XGA><: KYG9>:G :@H:BE:AK>H
6H:G:I EX :I6 ;DG9:A>C<:C @6C 9:CC: H6C9HNCA><=:9 7:G:<C:H I>A AA:G
H6C9HNCA><=:9:C ;DG 6I & ;XG B6M 6; HI:BB:GC: 9:G @6C 7:G:<C:H I>A &&
: H6C9HNCA><=:9HBYHH><: D99H ;DG 6I & ;XG M K:GHJH N 6; HI:BB:GC: M
N @
H:BE:AK>H :G D99H ;DG K:GHJH A>< B:9
7:G:<C:I J9;G6 :I6
;DG9:A>C<:C 9KH 9:I :G DK:G <6C<: B:G: H6C9HNCA><I 6I & ;XG 6; HI:BB:GC: :C9 6I
E6GI>:I ;XG 6; HI:BB:GC: :C HA6<H 7:G:<C>C<:G @6C >@@: A6K:H B:9 9:I IG69>I>DC:AA:
@DCP9:CH>CI:GK6A
!#"" "
,I6I>HI>H@ >C;:G:CH 76H:G:I EX 9:I @A6HH>H@: ;G:@K:CI>HI>H@: H:IJE > ;DGB 6; @DCP9:CH>CI:G
K6AA:G D< (:NB6C*:6GHDC (* =NEDI:H:I:HI 7N<<:G EX 9:C H6C9HNCA><=:9HDE;6II:AH: 6I
RH6C9HNCA><=:9R :G :C A6C<H><IH G:A6I>K ;G:@K:CH > %5,+0%"0& ( .","0"! /),(&*$-NE:#
D< -NE: ## ;:?AH6C9HNCA><=:9:GC: > :I (* I:HI :G J9IGN@ ;DG A6C<H><IH ;G:@K:CH:G > <:CI6<:I
6CK:C9:AH: 6; I:HI:I A><:HDB +2".$" ,.+&(&05 :G 9:I ;DG :I @DCP9:CH>CI:G
K6A # 9:C ;DGHI6C9 :G 9: @A6HH>H@: B:ID9:G ,."!0 EGD8:9JG:G :AA:G HDB $:GON (:NB6C
H6<9: I=: EGD767>A>IN HI6I:B:CIH G:;:G ID EGD7A:BH L>I= L=>8= I=: HI6I>HI>8>6C L>AA
7:8DC8:GC:9>CI=:;JIJG:
# BD9HYIC>C< =:GI>A :G 9:I 76N:H>6CH@: H:IJE =KDG RH6C9HNCA><=:9R :G J9IGN@ ;DG 6C
6ANI>@:G:CH !"$."" +# "(&"# DB :C E6G6B:I:G :AA:G BD9:A =:GJC9:G <G69:C 6; JH>@@:G=:9
DB E6G6B:I:G:CBD9:AA:C C6ANH:C :G ,+/0!0 > 9:C ;DGHI6C9 6I 9:C <>K:G H6C9HNC
A><=:9HBYHH><: J9H6<C DB E6G6B:I:G:CBD9:AA:C 76H:G:I EX 9: ;6@I>H@ D7H:GK:G:9: 96I6
"K>A@:C 6; 9: ID I>A<6C<: 9:G :G B:HI =:CH><IHBYHH>< 6;=YC<:G 6; EGD7A:BHI>AA>C<:C
:G :G >C<:C IK>KA DB 6I 9:I ;G:@K:CI>HI>H@: H:IJE :G K:A:<C:I I>A :@H:BE:AK>H HI6I>H
I>H@ @K6A>I:IH@DCIGDA > EGD9J@I>DCHK>G@HDB=:9:G =KDG 6CI6<:AH:GC: 76<.","0"! /),(&*$
H:IJER:I B:9 G>B:A><=:9 @6C H><:H 6I KYG: DE;NA9I: D< =KDG 9:C :C@:AI: HI>@EG[K: >@@: >
H>< H:AK :G >CI:G:HH6CI D< (:NB6CH ;G:@K:CI>HI>H@: B:ID9:G 7A:K 96 D<HX J9K>@A:I I>A 9:C
HA6<H EGD7A:BHI>AA>C<:G
30
:G>BD9 :G 9:I HKYGI 6I H: 6CK:C9:A><=:9:C 6; 9>HH: B:ID9:G CXG 96I6 ;DG:A><<:G HDB
>@@::@HE:G>B:CI:AA: D< *+*.","0(" =K>A@:I :G D;I: ;DG:@DBB:C9: >C9:C;DG H6B;JC9HK
>9:CH@67 ":G @6C 9: 76N:H>6CH@: B:ID9:G KYG: B:G: 6EE:AA:G:C9: 96 9: >@@:7N<<:G
EX :C HI6I>HI>@H HI>@EG[K:;DG9:A>C< > .","0"! /),(&*$ B:C > HI:9:I I6<:G J9<6C<HEJC@I
> 9: ;6@I>H@ D7H:GK:G:9: 96I6 D< =K69 9>HH: 96I6 >C;:G:CHBYHH><I @6C ;DGIYAA: DB EDEJ
A6I>DC:C
# 9: Q:HI: EG6@I>H@: 6CK:C9:AH:G :G 9:C HA6<H DK:GK:?:AH:G ;G6KYG:C9: : IG69>I>DC:AA:
B:ID9:G 6CK:C9:H B:G: :AA:G B>C9G: J@G>I>H@ J6CH:I =K>A@:C HA6<H 96I6 B6C6G7:?9:G
B:9 (XG 9:I 9G:?:G H>< DB >@@::@HE:G>B:CI:AA: 96I6 :G@AYG:G CYGKYG:C9:6GI>@:AH
;DG;6II:G H>< :C>< B:9 %696C: E 9:G DB 9: @A6HH>H@: ;G:@K:CI>HI>H@: B:ID9:G
H><:G -=:N 6G: 76H:9 DC I=: JH: D; 6 EGD8:9JG: >C 6 =NEDI=:I>86A >CPC>I: H:FJ:C8:H
D; JH:H JC9:G I=: H6B: 8>G8JBHI6C8:H -=JH 8A6HH>86A >C;:G:C8: G:A>:H DC I=: >9:6 I=6I 6
H>C<A: >CHI6C8: 86C 7: I6@:C 6H INE>86A D; 6 =NEDI=:I>86A >CPC>I: EDEJA6I>DC # A:6K: >I ID
I=DH: L=D PC9 I=>H 6C 6IIG68I>K: EGDEDH>I>DC ID :MEA6>C L=N
DM + ,DB: EGD7A:BH 8DCC:8I:9 L>I= HI6I>HI>86A >C;:G:C8: **(/ +# 0%
")0& ( 00&/0& /
C<HI:9 - 6C9 $0 ,8=C:>9:G (DC:ME:G>B:CI6A 96I6 =NEDI=:H>H I:HI>C<
6C9 I=: A>@:A>=DD9 EG>C8>EA: HD8>6A H8>:C8: E:GHE:8I>K: +1*!0&+*/ *! ."*!/ &*
+*+)"0.& /
%696C: $ DBB:CI DC 6GI>8A: 7N !:AB6C 5"/&* *(5/&/
'DG:N + + "D:@HIG6 $( +DJ9:G ' &:: 6C9 $ 06<:CB6@:GH -=:
;6AA68N D; EA68>C< 8DCP9:C8: >C 8DCP9:C8: >CI:GK6AH /5 %+*+)& 1(("0&* "2&"3
(:NB6C $ )JIA>C: D; 6 I=:DGN D; HI6I>HI>86A :HI>B6I>DC 76H:9 DC I=: 8A6HH>86A
I=:DGN D; EGD767>A>IN %&(+/+,%& ( .*/ 0&+*/ +# 0%" +5( + &"05 +# +*!+* ".&"/
0%")0& ( *! %5/& ( &"* "/
31

32
Measurement Error or Individual Variation
Associate Professor Emeritus, Department of Finance, Copenhagen Business School
Among other things, I will focus on some studies where preferences are measured at the individual
level. Since we cannot look into the head of an individual, we must use indirect measurements. We
therefore use a model. The model describes the assumed structure and enables a discussion of
estimation methods, as well as a discussion of what is estimated and, not least, allows the model to
discuss the interpretation of estimates. Whether estimates should be interpreted at the individual
level or at the population level, and the diƯerence will often reƲect the purpose of the analysis.
I will give some examples of how it is important in relation to the interpretation of an analysis how
estimates are interpreted.

33
Using higher dimensional space to Įnd soluƟons of problems
Jacob Hjelmborg, The Faculty of Health Sciences, Department of Public Health, Epidemiol-
ogy, BiostaƟsƟcs and Biodemography, SDU
The classic idea of embedding data into some higher dimensional space to Įnd soluƟons of
problems, e.g., separaƟon of features is key and has a modern aspect through extended ker-
nel-based methods. We focus on a recent proposal of a data analysis framework that involves
the theory of operator algebras. We will be reviewing embeddings of data into certain spaces
that have lots of potenƟally useful structure, that is, embeddings into Hilbert C*-modules
that have the reproducing kernel property. We intend to relate to aims of classical staƟsƟcal
noƟons as interacƟon, classiĮcaƟon and dimension reducƟon with applicaƟons in health sci-
ence.

Objektiv sensitivitetsanalyse for tidsvarierende konfundere
Andreas Kristian Pedersen1,2, Anna Mejldal2, Afsaneh M. Nejad3, and S¨oren M¨oller2,4
1Klinisk forskningsafdeling, Sygehus Sønderjylland, Danmark
2OPEN, Odense Universitet Hospital
3Institut for Matematik og Datologi, Syddansk Universitet, Odense
4Klinisk Institut, Syddansk Universitet, Odense
Resum´e
I kausal inferens kan tidens rolle ikke overvurderes, da rækkefølgen af ˚arsag og virkning er
afgørende for at etablere kausale sammenhænge. I det kontrafaktiske udfald setup har tidsva-
rierende konfunderens og eksponering blevet undersøgt i stor udstrækning. Dog er det seneste
gennembrud p˚a dette omr˚ade, E-værdien, ikke blevet udvidet til tidsvarierende konfunderens,
udfald eller eksponeringer. Vi foresl˚ar en udvidelse af E-værdien ved brug af den generelle op-
sætning af kontrafaktiske udfald, directed acyclic graphs, m˚alteori og stokastiske integraler, hvor
vi undervejs kun vil gøre minimale antagelser vedrørende fordelingen af konfunderen, i tr˚ad med
den oprindelige definition af E-værdien. Vi vil præsentere en stokastisk differentialligning for den
um˚alte konfunder, der kan forklare den kausale sammenhæng, og vise, hvordan denne ligning
kan løses numerisk under antagelsen om, at konfunderen er kontinuert over tid.
1 Introduktion
Konfundering er en af de mest problematiske størrelse indenfor biostatistik og epidemiologi hvor
en variable Cskaber en sammenhæng mellem to uafhængige variabler Xog Y, der ofte er kaldt
eksponeringen og udfaldet. Fænomenet ses ofte indenfor observationelle studier hvor man ikke
kan fastsl˚a om alt konfundering er taget højde for, og derfor ved man ikke hvorvidt den givne
sammenhæng er reel. En metode er sensitivitetsanalysen E-værdien, der siger hvor stærk en given
konfunder skal være associeret med eksponeringen og udfald p˚a en risiko skala til at forklare denne
sammenhæng man ser[DV16]. Problematikken er at E-værdien ikke er udvidet til longitudinelle
m˚alinger hverken i diskret eller i kontinuert tid, hvilket dette indlæg vil introducere.
For at kunne udvide E-værdien til kontinuert tid, skal den gennemsnitlige behandlingseffekt de-
fineres. Vi bruger her Robins kontrafaktiske setup[HR06], hvor behandlingseffekten er defineret som
forskellen mellem de to kontrafaktiske virkeligheder hvor alle var eksponeret eller ikke eksponeret,
som beskrevet i figur 2.
XY
C
E-værdi E-værdi
Figur 1: E-værdi fortolkning
34

Population
Yxt=1
tYxt=0
t
Population
Xt=1 Xt=0
EFobs
XtYt
EFtrue
XtYt
Figur 2: Definition of the effect sizes used in the derivation of the E-value process
Da eksponering ikke nødvendigvis er konstant over tid skal den gennemsnitlige behandlings
effekt op til tidspunkt ndefineres ved
1
n
n
k=1
YXk=1
k−YXk=0
k,
hvor YXk=i
ker det kontrafaktiske udfald til tid kfor i=0,1.
Derved ses der, under de klassiske antagelser indenfor kausal inferens, at vi kan estimere effekt-
størrelsen for den kausale og observerede sammenhæng i diskret tid p˚a følgende m˚ade[HR06]
EFtrue
XtYt=E[Yt|Xt=1,U
t=u]dFUt⊗Ut−1⊗···⊗U1(u)−E[Yt|Xt=0,U =u]dFUt⊗Ut−1⊗···⊗U1(u)
EFobs
XtYt=E[Yt|Xt=1,U
t=u]dF 1
Ut⊗Ut−1⊗···⊗U1(u)−E[Yt|Xt=0,U
t=u]dF 0
Ut⊗Ut−1⊗···⊗U1(u),
hvor Ut,Xtog Yter henholdsvis konfunderen, eksponeringen og udfaldet, FUt⊗Ut−1⊗···⊗U1(u)er
det marginale m˚al af Ut⊗Ut−1⊗···⊗U1,Fi
Ut⊗Ut−1⊗···⊗U1(u)erm˚alet der korresponderer til den
betingede fordeling af Ut⊗Ut−1⊗···⊗U1i gruppe i=0,1ogEFtrue
XtYtog EFobs
XtYter henholdsvis
effektstørrelsen for den ægte kausale sammenhæng og den observerede effektstørrelse.
Det ses nu at man kan definere b˚ade den ægte og observerede sammen mellem vores eksponerings
og udfald ved at fokusere p˚a funktioner af
f(t)=
n−1
i=1
ξi1ti,ti+1 (t),
hvor ξier Fti-adapterede stokastiske variabler hvor Ftier filteret genereret af vores konfunder
proces Uttil tid ti. Det bemærkes at disse funktion approksimerer vores givne integrale i kontinuer
tid, men ændrer sig i diskret tid. Derved f˚ar man følgende effektstørrelse i kontinuert tid n˚ar vores
eksponering er binær
EFtrue
XtYt=E[Yt|Xt=1,U
t,1]dUt,1−E[Yt|Xt=0,U
t,0]dUt,0,
hvor Ut,i er den betingede stokastiske proces af Utfor Xt=ifor i=0,1.
Det vil sige at hvis E-værdi processen defineres som forskellen mellem den kausale og observerede
effektstørrelse har vi at den m˚a opfylde følgende stokastiske differentialligning
dE(t)=EFUt,1Ytf(Ut,0)dUt,0+1
4EFUt,1Ytf(Ut,0)dUt,0,U
t,0,
35

hvor f(Ut,0) er associationen mellem konfunderen og eksponeringsvariablen, EFUt,1Yter associatio-
nen mellem konfunderen og vores udfald, f(Ut,0) er den afledte af associationen mellem konfun-
deren og eksponeringsvariablen og Ut,0,U
t,0er bracketfunktionen af Ut,0. Det bemærkes at b˚ade
f(Ut,0)ogEFUt,1Ythar klinisk simple fortolkninger, der er styrken af konfunderen p˚a henholdsvis
en relativ og absolut skala for eksponeringen of udfaldet.
2 Løsning af differentialligningen
N˚ar de givne størrelser er udfyldt i den stokastiske differentialligning ud fra den kliniske viden
bemærkes det, at det kun er bracketprocessen af konfunderen, der sjældent er kendt n˚ar man
arbejder med generelle semimartingaler.
Det viser sig dog at hvis en konfunder ændrer sig kontinuert over tid kan denne approksimeres
vha. Itˆo processer, hvorved bracketprocessen er givet ved
n−1
i=1
μ(ti,U
ti,0)d(ti+1 −ti),
der giver følgende stokastiske differentialligning for konfunderen i kontinuert tid
dE(t)=EFUt,1Ytf(Ut,0)dUt,0+1
4EFUt,1Ytf(Ut,0)
n−1
i=1
μ(ti,U
ti,0)d(ti+1 −ti).
Denne kan løses numerisk og derved kan den potentielle konfunder simuleres og følgende plot af
konfunderen kan konstrueres
í10
í5
0
5
10
0.5 1.0 1.5 2.0 2.5 3.0
t
Konfunderen
Figur 3: Utover tid
Litteratur
[HR06] M. A. Hernan og J. M. Robins. “Estimating causal effects from epidemiological data”. I:
J Epidemiol Community Health 60.7 (jul. 2006), s. 578–586.
36
[DV16] P. Ding og T. J. VanderWeele. “Sensitivity Analysis Without Assumptions”. I: Epidemio-
logy 27.3 (maj 2016), s. 368–377.
37

38
Violent aggression: Consequences of ostracism and violence against vulnerable
adolescents
Mogens Nygaard Christoffersen, VIVE, The Danish Center for Social Science Research,
mc@vive.dk
A
Abstract
Violent victimization and forms of ostracism of children and adolescents can have
important developmental and psychological implications. Ostracism activates the same
region of the brain as is activated by the experience of physical pain. Ostracism,
meaning exclusion from the social context or group, can threaten fundamental needs,
according to the need-threat model. An aggressive violence could be a response.
Method: Violent aggression by adolescents’ and young adults is studied in a large-
scale, prospective, longitudinal study of individuals born 1980-1985 followed in ages
15-27 years old (N=300,000) in linked records in Denmark. Violent aggression by
young people, identified from police records as a charge of a violent crime is analyzed
by a discrete-time log-odds model until an event occurs.
Violence against young people was identified in official records of parental violence
(or domestic violence), child maltreatment, or victimisation of a violent crime.
The experience of ostracism is approximated from records of being adopted, being in
care or being separated from family members. Not having graduated from high school,
no vocational training, living in a disadvantaged area, or non-Danish citizenship are
also taken as indicators of social exclusion.
Risk factors examined separately and jointly for their predictive power are:
victimization of violence, and indicators of ostracism. Gender is controlled either as
an intercept in a pooled model or by an interaction, splitting the sample into males and
females
Results: Prevalence of aggression in young people was 4.8 % (n=14,607) as first-time
charged up to age 27. Indicators of ostracism and violence in the family of the social
environment preceded an increased risk of violent aggression among young people,
both males and females.
It was not graduating from high school, or having no vocational training that most
markedly elevate the risk of being charged of a violent crime.
Further, some vulnerable children known to be exposed to ostracism and violence (e.g.
ADHD, brain injury or mental retardation) were found to be at higher risk of being
charged of a violent crime.

39
There is also a huge variation between males’ and females’ charges of a violent crime
for which we do not account. Generally, the model did not differ greatly between men
and women, apart from Danish citizenship which appeared protective for men, but not
for women.
Conclusion: Further study is needed of the mechanism where reaction to violence
bears resemblance to that from pain inflicted by repeated and persistent experiences of
ostracism from significant others in family, social groups, or local society, but also to
what extent structural disadvantages and segregation will feed into higher levels of
interpersonal violence. A need-threat model of ostracism provides a partial explanation
of these associations.
I
Introduction
Social exclusion comes in many shapes and forms. The political and economic
structures and opportunities from which stratification and inequality emerge can
produce social exclusion of the poor, undercut their pride and feeling of self-worth
(Crutchfield & Wadsworth, 2003). Structural disadvantages reduce the opportunity of
normal pathways to respect such as jobs, careers, and a capacity to be self-determining
(Anderson, 2019). Structural features such as segregation can exacerbate the effects of
poverty causing high levels of violent crime (Crutchfield & Wadsworth, 2003), and the
effects of extreme disadvantage are pronounced for violent crime (Short, 2003). Both
men and women living in a violent environment have a predisposition for violent
aggression (Shaw & Dubois, 1995).
Williams’ temporal need-threat model of ostracism
Why do we repeatedly find an association between previous violence in the family and
local community and later violent behavior in adolescents?
Fig. 1. Williams’ temporal need-threat model of ostracism (Williams, 2009; 2022).
Detection of
ostracism
Minimal signal:
Pain
Negative affect:
. Sadness
. Anger
Need-Threat:
. Belonging,
. Self-esteem,
. Control,
. Meaningful
existence/to be
recognized
Reflexive stage:
Coping stage:
Attend, appraise
and attribute:
.Motives,
.Meaning,
.Relevance
Need fortification:
Belonging/self-esteem
. Attempts to become
more socially attractive,
. Attend to social cues,
.
Compliance/conformity,
Control/recognition
.Gain attention
.Provoke,
.Control others,
.Retaliate,
.Lash out,
Resignation stage:
Depleted resources
:
.Alienation,
.Depression,
.Helplessness,
.Unworthiness
If ostracism
episodes persists
over extended time

40
Ostracism, meaning exclusion from the social context or group, can threaten four
fundamental needs: the need to belong, the need to maintain self-esteem, the need to
have control over one’s social environment, and the need to be meaningfully
recognized for existing. Williams’ temporal need-threat model of ostracism (Williams,
2009) can serve as a theoretical framework for the study of long-term consequences of
violence against children (Figure 1). The model proposes that reaction to ostracism
happens in three stages: a reflexive stage; a coping stage; and a long-term resignation
stage (Williams, 2009).
Ostracism is quickly detected and experienced as social painful and uncomfortable.
The reflexive stage is seen as an adaptive response to a – for an evolutionary
perspective – dangerous situation (Williams & Nida, 2022). Studies of ostracism in
laboratory have shown heightened levels of activation in the same region of the brain
that is activated by experience of the physical pain (Williams & Nida, 2022).
Not maintaining satisfactory levels of any of the four constructs (belonging, self-
esteem, control over environment and recognition) may result in psychological harm in
the coping stage. A child will engage in mental or behavioral activities to fortify the
needs (Williams, 2009). According to Williams’ model, the child will attempt to
become more socially attractive; the child will try harder to adapt to relevant norms
(Hutchison et al., 2007), or the child’s learned strategy could be to gain control,
provoke, retaliate or respond aggressively (lash out) in order to ensure adequate
protection of the child’s fundamental needs.
Under certain circumstances, retaliation, and generalized aggression can result from
ostracism or social exclusion (Twenge et al., 2001; Warburton et al., 2006). Ostracism
or social exclusion can be potential causes of aggressive behavior (Twenge et al.,
2001). This is substantiated by the observation that many perpetrators of violence feel
rejected by family members, peers, and society in general (Garbarino & Haslam, 2005;
Leary et al., 2003; Twenge et al., 2001).
Can Williams’ need-threat temporal model of ostracism also give us an explanation, if
we find an increased incidence of violent aggression after young person is exposed to
ostracism or violence?
Motivated by Williams’ need-threat model we will narrow our study to recorded
occurrence of ostracism or violence before first-time charges of violent crime, given
other potential risk factors as uniquely measured for the population in national linked
records. Can Williams’ needs-threat temporal model of ostracism give us an
explanation?

41
Social psychology in large scale studies
M
Method
The social psychologist focuses on individuals in face-to-face interactions (Tedeschi,
2003). The present study examines the implications for a child or young person of
being exposed to ostracism and violence prior to being charged with a violent crime.
The study is prospective and based on longitudinal data including the whole
population sample, which provides us with information about the chronological
sequence of potential causes before first-time registration of the events.
The total 6 birth cohorts (N=300,000) born between 1980 and 1985 are followed while
they were 15 to 27 years old (Figure 2). Most data extending back to 1980 was
available for both the cohort children and their parents. Hospitals records (diagnoses
CD-8) were applicable from 1980, and (diagnoses ICD-10) were applicable from
January 1994, while records concerning victims of sexual or violent assault were
confined to years after January 2001, sourced from police records.
Prospective data about participants and their families was collected each calendar year
from birth of the child. Risk factors represent developmental domains: inherited or
acquired vulnerabilities, family stressors, exposure to family violence, parent-child
relationship, indicators of ostracism, and disadvantaged living conditions, in general.
The events i.e. first-time charged of a violent crime against a person have been
analyzed by log-odds models (Allison, 1982). The regressors were entered jointly and
a procedure was carried out to select significant risk factors to give the best possible
prediction. Individual event history is broken up into a set of discrete time units (a
calendar year) in which an event either did or did not occur.
0
5
10
15
20
25
30
1975 1980 1985 1990 1995 2000 2005 2010 2015
Figure 2. Lexis diagram. Birth-cohort of January 1980 to
December 1985 being 15 to 27 years old in 2001-2012. Age by
calendar year.

42
Analyzing the event history of an individual can be characterized as a sequence of
events in order to answer the question: Why is it that some individuals get charged of a
violent crime while others do not? The model we seek should incorporate explanatory
variables that change in value over the observation period as well as variables that
remains constant.
The discrete-time proportional odds model proposed by Cox (Cox, 1970) have several
desirable features (Allison, 1982), but there are also problems in analyzing event
histories. In the proportional hazard model (Allison, 2010), we assume that the ratio of
the hazard for any two individuals is constant over time (age). Some age groups may
be more developmentally vulnerable than other age groups. A vector Įtis then added
to the model in order to incorporate the age factor. We are not imposing any further
restrictions on the set of constants (see Fig. 3).At age 18 years the highest numbers of
first-time events are observed, but half of young persons have their first-time charges
of violence after their 20th birthday.
The national rules determining the age of criminal responsibility is 15 years in
Denmark. Age 15 years is a natural starting point for our search. For each age group
(age=15, 16, ..., 27) a constant (dummy) is estimated. It turns out that none of the time
units has a frequency of 0. The smallest possible time unit is the calendar year for most
of the time-dependent covariates. Each individual’s event history is broken up into a
set of discrete time units in which an event either did or did not occur. Then the data
set consists of 3.8 million person-years.
All explanatory variables are treated as categorical dummy variables equal to one or
zero. When the model was created (Allison, 1982; Cox, 1970) it was difficult and
0
200
400
600
800
1000
1200
1400
1600
1800
2000
15 17 19 21 23 25 27 29
Figure 3. Number individuals charged with a violent crime
for the first time, by age. Individuals born between January
1980 and December 1985.
43
time-consuming to analyze large data sets, but modern computers make it less costly to
use the complete information. The proportional log-odds model allows in this way for
standardization relating to age. Maximum likelihood estimators for the regression
models are then calculated based on pooling of all the person years, and log-odds are
presented (Allison, 1982). The log-odd discrete time methods allow us to estimate
parameters in the model, treating each individual history as a set of independent
observations. We can benefit from earlier findings where it has been shown that
maximum likelihood estimators of parameters can be obtained by treating all the time
units for all individuals as though they were independent (Allison, 1982).
The logistic regression function is written:
Log[Pit/(1-Pit)] = Įt + ȕ’xit
Pit is the conditional probability that individual i has an event at age t, given that it has
not already occurred to that individual. Įt are estimated through dummy variables
being 1 when the individual reaches the age t, otherwise 0. Both the dependent and the
independent variables are dichotomized. Odds ratio is the ratio of the odds for x=1 to
the odds for x=0. It follows that log odds ratio is ȕ’. Estimates of odds ratio will have a
distribution that is skewed, in theory for large enough samples, the distribution will be
normal. Log odds ratio follow a normal distribution for much smaller sample sizes
(Hosmer & Lemeshow, 1989).
The model assumes that the ratios of the covariate’s hazards remain constant (Allison,
2010). The explanatory variables xit take on different value at different discrete age t (t
= 15, … ,27). The observation continues until age ti , at which point an event occurs or
the observation is censored (Allison, 1982). Censoring means that the individual is not
observed beyond the age ti.
The model allows that individuals can have changing covariates over time, but the
proportional hazards assumption means that the relative effect of each covariate is the
same at all points in time (age). The coefficient we estimate is a sort of average effect
over the range of ages in the data (Allison, 2010).
The time of observation of the explanatory variables may differ from actual time of the
event in linked administrative data. Events are divided into three types of time-
dependence. For example, the diagnoses of autism can be observed and diagnosed late
in adolescence, but from theory about autism, we know that it has been present all the
time. In Type I risk factors observed at time t also covers the years before and after t.
Some events will only influence the years when they are registered (Type II). In Type
II we assume that the influence from being long-term unemployed will vanish when
the redundant parent is back in employment. Type II describe a situation where the
individual is exposed to a risk factor at time t that will only cover t, and perhaps t+1.
44
While other events (Type III) are assumed to cover all the following years, as for
example a family separation.
S
Statistics
We wish to describe the environmental situation for the children the year before first-
time event was observed in comparison with their contemporaries. The multivariate
analyses included 23 risk variables (covariates) covering various aspects of the
temporal need-threat model (Supplementary). Risk factors were included in the final
model stepwise, if they contributed with new information, given all the others risk
factors. The stepwise procedure was carried out to select the most significant risk
factors to improve the prediction, and at the same time avoid redundancies. The
stepwise selection is an automatic selection method (Peduzzi et al., 1980).
In order to evaluate the risk factors’ contribution to the number of young persons
registered with a charge of a violent crime, attributable fractions (AF) are calculated
(Greenland, Sander, 1998). Attributable fractions express the reduction in incidence of
the event that would be achieved if the population had not been exposed at all,
compared with the current exposure pattern (Greenland, S. & Drescher, 1993). The
estimated AF of a certain risk factor depends on two parameters only. One parameter
is the strength of the risk factor measured by adjusted Odds Ratio (OR) or relative risk
(RR). The other parameter is the current exposure of the risk factor in the population.
The estimated AF is calculated solely on the basis on these two parameters (Levin,
1953; Woodward, 1999). Attributable fractions are only defined when OR and RR is
more than 1. AF are not applicable to gender, because the population will always be
exposed to both males and females.
The lifetime prevalence is estimated on the basis of the first-time incidence rate for the
ages t=15, 16, 17, …, 27. We imagine that for instance 300,000 individuals live
through the ages 15 to 27 years with the estimated age specific probabilities of first-
time events.
The pooled model builds on an assumption that for example men and women range the
seriousness of the experienced risk factors in the same order, at least. But what if for
example men’s response to risk factor A is an increased risk of violence, while
women’s response to the same risk factor is quite opposite. Analyzing men and women
together would erroneously estimate the association between risk factor A and the
following risk of being charged with a violent crime. We present separate analysis of
males and females in order to test the assumption of proportional hazards.

45
Figure 4. Forest plot of risk factors. Charged of violent crime, adjusted Odds Ratio (OR), [95% CI].
Note: the plot of Boys OR: 8.61 [8.16-9.08] is not included in Fig. 4.
M
Men’s and women’s violent crime
In the data we observe that, according to police records 13,119 men were charged with
a violent crime in comparison with only 1,488 women. The adjusted odds ratio for
being male is 8.6 [CI 8.2-9.1]. We test how far the huge gap might be a consequence
Parental violence
Child battered/neglected
Victim of violent crime
Victim of sexual crime
Child in (public) Care
Family separation
Not graduated f high school
No vocational training
Disadvantaged area
Non-Danish Citizenship
ADHD
Autism
Mental retardation
Brain injurie
Alcohol abuse
Drug abuse
Parental substance Abuse
Parental suicidal Behavior
Parental inpatient mental ill
Parental unempl. >21 w
Mother teenager
Gender (boys=1)
OR: 1,16 [1,11-1,2]
ns
OR: 2,49 [2,19-2,84]
ns
OR: 1,66 [1,57-1,76]
OR: 1,65 [1,59-1,72]
OR: 3,47 [3,28-3,67]
OR: 1,54 [1,49-1,6]
OR: 2,42 [2,25-2,61]
OR: 1,12 [1,07-1,18]
OR: 1,59 [1,5-1,7]
ns
OR: 1,24 [1,16-1,33]
OR: 1,79 [1,69-1,9]
OR: 1,67 [1,57-1,78]
OR: 1,13 [1,04-1,23]
OR: 1,32 [1,26-1,39]
OR: 1,15 [1,08-1,23]
ns
OR: 1,36 [1,29-1,44]
OR: 1,65 [1,55-1,75]
OR: 8,61 [8,16-9,08]
-0,75 0,25 1,25 2,25 3,25 4,25 5,25

46
of men and women experiencing different constraints and disadvantages and how far it
could be a consequence of different responses to violence, ostracism and other
disadvantages. From previous studies we know that more women react to violence and
social exclusion with PTSD, suicide attempts and to a lesser extend with violence
(Christoffersen, M. N. & Khan, 2024; Christoffersen, Mogens Nygaard & Thorup,
2024) .
Table 2.
Adjusted Odds Ratio estimates and Wald Confidence Intervals for men and women
subsequently charged with a violent crime by age 27.
Type
Men
% of
Men charged of
violent crime
Men
AF
Women
% of
Women charged of
Violent crime
Women
AF
Controls
OR
95% CI
%
Controls
OR
95% CI
%
Risk of violence
Parental (domestic) violence
(I)
14.0
1.1***
[1.1-1.2]
1.4
15.8
1.6***
[1.4-1.8]
8.7
Child battered or neglected
(III)
0.5
Ns
0.6
Ns
Victim of violent crime
(III)
0.5
2.4***
[2.1-2.7]
0.7
0.2
3.7***
[2.5-5.5]
0.5
Indicators of ostracism
Child adopted
(I)
1.2
Ns
[2.9-3.3]
1.2
Ns
Child in care
(III)
3.1
1.6***
[1.5-1.7]
1.8
2.8
2.1***
[1.8-2.4]
3.0
Family separation
(III)
33.5
1.6***
[1.6-1.7]
16.7
34.2
1.8***
[1.6-2.1]
21.5
Not graduated f high school
(I)
60.7
3.4***
[3.2-3.6]
59.3
50.1
3.6***
[3.0-4.3]
56.6
No vocational training
(I)
36.3
1.5***
[1.4-1.6]
15.4
28.9
2.0***
[1.8-2.2]
22.4
Disadvantaged area
(II)
1.7
2.5***
[2.3-2.7]
2.5
1.8
2.0***
[1.6-2.6]
1.8
Non-Danish Citizenship
(II)
7.8
1.2***
[1.1-1.3]
1.5
9.0
0.7***
[0.6-0.8]
NA
Selected disadvantages
ADHD
(I)
5.2
1.6***
1.5-1.7
3.0
7.5
1.5***
[1.3-1.8]
3.6
Autism
(I)
4.7
Ns
7.0
Ns
Mental retardation
(I)
3.6
1.2***
[1.2-1.3]
0.7
5.2
1.2*
[1.0-1.5]
1.0
Brain injury
(III)
4.6
1.9***
[1.7-2.0]
4.0
3.8
1.3*
[1.0-1.6]
1.1
Alcohol abuse
(III)
5.0
1.6***
[1.5-1.7]
2.9
6.7
2.2***
[1.8-2.6]
7.4
Drug abuse
(III)
2.2
Ns
3.6
1.3
[1.0-1.5]
1.1
Family risk factors
Parental substance abuse
(I)
11.9
1.3***
[1.3-1.4]
3.4
12.4
1.2*
[1.1-1.4]
2.4
Parental suicidal behavior
(I)
4.0
1.1**
[1.0-1.2]
0.4
4.3
1.3***
[1.1-1.6]
1.3
Parental inpatient mental ill
(I)
11.4
Ns
11.8
Ns
Parental unemployment>21 w
(II)
6.4
1.4***
[1.3-1.4]
2.5
6.4
1.4***
[1.2-1.7]
2.5
Mother teenager
(I)
2.9
1.7***
[1.6-1.8]
2.0
3.1
1.5***
[1.2-1.8]
1.5
Note: Numbers of men 13,119 numbers of women 1,488. Numbers of person-years in the study 1,898,626 and
1,932,175 for men and women, respectively. Ns means non-significant. AF means attributable fractions. NA
means that AF is Not Applicable for odds ratio below 1.0. Type of dependency. Type I: Risk factor observed at
time t also covers the years before and after t. Type II: Exposed to risk factor at time t are also present at t+1.
Type III: Exposed to risk factor at time t, then the risk factor is also present at all the following years.
In most cases there are no significant differences between men’s and women’s
exposure to known risk factors, or their response to them (Table 2). According to our
measures in administrative records, young men and young women had been exposed
to violence in the family to the same degree, but the women react more often

47
themselves with violent aggression, than women without such exposure. A relative
high fraction of the charged women (AF: 8.7%) can statistically be linked to their
exposure for parental violence (Table 2). The odds ratio was: 1.6; [1.4-1.8] for young
women who had been exposed to parental violence to become violent themselves.
Young men exposed to parental or domestic violence OR: 1.1; [1.1-1.2], also react
with violence more often than other boys, but to a lesser extent than girls. The
attributable fraction is only 1.4% among men.
We may conclude that estimating the strength (odds ratio) of being a member of a
minority group (non-Danish citizenship) must be done separately for men and women,
in order to get a non-biased result.
S
Strength and limitations
Prospective longitudinal studies following large population samples can help to avoid
retrospective bias in self-reported survey data, but following individuals in birth
cohorts have obvious methodological limitations. The temporal need-threat model
raises the question of risk factors which are only partly or insufficient represented in
the Danish Registry system.
We found that limited data exists on systematically registered violence against
adolescents. The assumption is that the hazard rate is completely determined by the
measured explanatory variables. In other words, we assume - naively you might say -
that the vector xit exhausts all the sources of individual variation in the hazard rate.
The interaction between individuals and their environment differ in many ways which
can possible capture all the variation among them (Allison, 2010).
Conclusion
Being a victim of violence and ostracism have important developmental and
psychological implications in adolescence. Social rejection (ostracism), and violence
against a child can increase the risk of later aggressive behavior as a response to get
control over others. Williams’ temporal need-threat model of ostracism provides a
partial explanation of these associations. Reaction to violence bears resemblance to
pain inflicted by repeated and persistent experiences of ostracism from significant
others in family or peer group.
Victims exposed to violence or ostracism are at higher risk of future violent behavior.
The number of adolescents charged of a violent crime were mainly associated with
prior violence in the family, and family separation and structural ostracism. The
included risk factors can only partly explain the occurrence of violent criminal
behavior. The selected risk factors have a robust strength i.e. odds ratios significantly
different from 1, but some of the risk factors are relatively rare in the Danish Registry
system and therefore, they do not explain much of the aggressive violence. After all,

48
the robust associations between violence and the outcome of interest gives useful
guidance for where to search for causal effects.
The results clearly indicate that victimization of violence and other forms of ostracism
seems to have important developmental and psychological implications including
violent aggression. The evidence that we can assemble for the need-threat model is
clearly insufficient to explain violent aggression. The results also tell us that violence,
ostracism, or loss of social support contribute to negative outcomes but only partly
explains them. We would suggest that future research and other forms of data
gathering also look for other risk factors and resilient factors in the environment.

49
FAIR data and Open Science: some insights from a work package
in the PIGWEB project
Leslie Foldager
Dept. of Animal and Veterinary Sciences, Aarhus University, Tjele, Denmark
Bioinformatics Research Centre (BiRC), Aarhus University, Aarhus, Denmark
Email: leslie@anivet.au.dk
Abstract
There is an increasing demand and awareness of making (public) scientific research transparent and
accessible both for other researchers but also to other levels of society, known as the Open Science
movement. Pillars of Open Science include sharing of data, code, workflows, and publications but also
transparency of peer reviewing. The PIGWEB project is a European project funded under the EU
Horizon 2020 programme that aims to strengthen the pig research community by providing and
facilitating transnational access to research infrastructures. One of the work packages focused on data
sharing according to the FAIR principles: Findable, Accessible, Interoperable and Reuseable. This
included getting an overview of facilities and awareness but also providing workshops on Open Science
and FAIR principles, and on tools needed for FAIR data management and practices. Aspects of sharing
via data papers and repositories were also presented and worth consideration.
Introduction
Sharing data and knowledge are elements of the Open Science movement as described
in the UNESCO Recommendation on Open Science (UNESCO, 2021). Pillars of Open
Science include sharing of data, code, workflows, and publications but also transparency
of peer reviewing, and there is an increasing demand and awareness of making (public)
scientific research transparent and accessible both for other researchers but also to other
levels of society (Figure 1). Institutions are developing in-house strategies to promote
data sharing and respect FAIR principles (Findable, Accessible, Interoperable and
Reusable; Wilkinson et al., 2016), e.g., Data INRAE (https://data.inrae.fr/), RADAR in
Germany (https://www.radar-service.eu/en) and Wageningen Data Competence Center
(https://www.wur.nl/en/Value-Creation-Cooperation/WDCC.htm). Aarhus University
also have instructions on the staff intranet as part of a policy endorsing the Danish Code
of Conduct for Research Integrity (UFM, 2014).
The present proceedings paper presents some insights on FAIR and Open Science from
work package 3 (WP3) of the EU Horizon 2020 project PIGWEB (An infrastructure for
experimental research for sustainable pig production; https://www.pigweb.eu/) with
partners from 10 European countries, including INRAE (National Research Institute for
Agriculture, Food and Environment, France), WUR (Wageningen University &
Research, The Netherlands), FBN (Research Institute of Farm Animal Biology,
Germany), Agroscope (the Swiss confederation's centre of excellence for agricultural
research), ILVO (Flanders Research Institute for Agriculture, Fisheries and Food,
Belgium), SLU (Swedish University of Agricultural Sciences), IRTA (Institute of

50
Agrifood Research and Technology, Spain) and AU (Aarhus University, Denmark). The
overall aim of the project is to strengthen the pig research community by providing and
facilitating transnational access to research infrastructures, reinforcing a culture of
cooperation between the research community and industrial and societal stakeholders,
and improving and integrating the services provided by the research infrastructures. The
project started in March 2021 and ends by February 2026.
In PIGWEB WP3, the focus is on FAIR sharing of data generated in the project. This
includes getting an overview of facilities and awareness, but also providing training
sessions on Open Science and FAIR principles, and on tools to support FAIR data
management and practices. WP3 have provided two sets of training sessions on open
science, data sharing and licensing, FAIR data management, metadata standards and
annotation with ontologies (Table 1). The use of shared ontologies and metadata
standards will improve reusability and machine-readability and allow faster and
standardised data processing and analytics. Aspects of sharing via data papers and
repositories are also worth consideration. Much of the contests in this proceedings paper
and the subsequent talk is either inspired or (more or less) directly copied from the
training session presentations – in a sense taking advantage of Open Science. The
researcher mentioned in Table 1 are hereby credited with extra acknowledgement to the
main organisers from WUR, Rob Lokers and Hendrik Boogaard.
Figure 1. Open science elements.
Redrawn slide
by Robbie Ian Morrison (
20 Feb 2021, CC BY 4.0 via Wikimedia
Commons
) based on presentation
by Ana Persic, Division of Science Policy and
Capacity
-Building (SC/PCB), UNESCO (France),
Open Science Conference 2021,
ZBW
– Leibniz Information Centre for Economics, Germany.
https://commons.wikimedia.org/wiki/File:Osc2021-unesco-open-science-no-gray.png

51
Table 1. Headlines from the PIGWEB WP3 training sessions on Open Science, data
sharing and FAIR principles.
Online seminar sessions (webinars), 29 Nov - 1 Dec 2022
Introduction to Open Science and FAIR principles (Rob Lokers, WUR)
Data management and the data life cycle (Hendrik Boogaard, WUR)
Data curation (Hendrik Boogaard, WUR)
Data publication (Rob Lokers, WUR)
Annotating data with Ontologies (Martin Toutant, INRAE)
Writing data management plans (Danny de Koning - van Nieuwamerongen, WUR)
PIGWEB data management plan (Catherine Larzul, INRAE)
On-site workshop, Wageningen, The Netherlands, 27-29 May 2024
Introduction and revisiting FAIR data practices and guidelines
(Rob Lokers & Hendrik Boogaard, WUR)
Introduction to using ontologies (Catherine Hurtaud, INRAE)
Animal Trait Ontology for Livestock (ATOL)1
Environment Ontology for Livestock (EOL)1
Animal Health Ontology for Livestock (AHOL)
1
Progress on ABCD2 metadata standard (Nina Melzer, FBN)
Understanding IPR3 and data licensing - good practices and consequences
(Rob Lokers, WUR)
Practical work on own data in small groups and discussions
1https://www.atol-ontology.com/en/atol-2/
2 Access to Biological Collections Data
3 Intellectual Property Rights
Open Science and FAIR principles
To cite the UNESCO Recommendation (UNESCO 2021), “Open science is a set of
principles and practices that aim to make scientific research from all fields accessible to
everyone for the benefit of scientists and society as a whole” and “Open science builds
on the following key pillars: open scientific knowledge, open science infrastructures,
science communication, open engagement of societal actors and open dialogue with
other knowledge systems”. This includes making publications, data, physical samples,
software, and dissemination accessible to all levels, amateur or professional
(wikipedia.org). Open science should encompass unhindered access to scientific articles,
access to data from public research, and collaborative research enabled by ICT
(Information and Communications Technology) tools and incentives (OECD, 2015).
The European Commission also actively supports the Open Science agenda and work
according to the FAIR principles, and for example provides the Interoperable Europe
Portal (https://interoperable-europe.ec.europa.eu/), to share knowledge on issues and

52
solutions. So, what is FAIR data sharing? Findable means that data should be
discoverable with metadata, identifiable and locatable by means of a standard
identification mechanism. Accessible means that the data should always be available
and obtainable; even if the data is restricted, metadata should be openly available.
Interoperable is perhaps the trickier part but means to be both syntactically parseable
(i.e. possible to transform from one format to another) and semantically understandable
so that data exchange and reuse is possible between researchers, institutions,
organisations, or countries. Reusable means that data should be sufficiently described
and shared with the least restrictive licences, thereby allowing the widest reuse possible
and the least cumbersome integration with other data sources.
FAIR – why and how?
Reasons why we should comply with the FAIR principles include that we want to make
use of the valuable work of peers, find and access their data and make sure they can find
and access our data, and thereby avoiding reinventing wheels so that research is more
efficient. By describing our data in a way that others understand and formatting it such
that it fits the needs of other researchers and tools, we also want to increase the chance
of getting credits for the work that we did to generate the data. Using FAIR data sharing
also helps to safeguard our scientific integrity by transparency and verifiability, prevents
loss of data, increases visibility, and drives innovation.
Sometimes we simply also must do it because funders require us to make the data
reusable, institutions have it as part of policies, and journals encourage or even request
data to go with the publication. As an example, the management at AU has adopted 3
strategic goals in relation the data sharing to be followed by all researchers at AU: 1)
relate to the FAIR principles (data as well as to other outputs), 2) integrate data
management into the research processes to ensure transparency and integrity in the
results and 3) contribute to good practice and clear standards for handling data as well
as metadata throughout the life cycle of the research. The last point includes data
collection, curation and storing both during and after the completion of projects,
including choosing licenses and using persistent indicators (PID), such as DOI (i.e.
Digital Object Identifier; https://www.doi.org/).
According to a report from the EC Expert Group on FAIR Data (EC, 2018), for data to
be FAIR, it needs to be represented in standard formats and accompanied by PIDs,
metadata and code (EC, 2018). Identifiers should also be applied to other related
concepts, e.g., identifying authors by ORCID (Open Researcher and Contributor ID;
https://orcid.org/). Data should be represented in common and ideally open file formats
and accompanied by the code used to process and analyse the data. It should also be
accompanied by sufficient metadata and documentations to understand how, why, when
and by whom the data were created, and have a clear accessible data usage license.

53
The FAIR principles may trigger some misunderstandings such as “I need to share all
my data”, “Others might misuse my data”, and “I do not benefit from data sharing”. The
use or reuse of the data can, however, be limited by specifying a suitable data licence
and the data can be kept (partly) closed. The main requirement is to make sure that
people know it exists and if or how they can get access. By providing good metadata the
risk of misuse can be reduced. It can never be guaranteed that no one misuses the data,
but the risk of at least unintended misuse can be reduced by describing the background
and provenance of the data, and by providing code for data processing if needed and
possible. Requiring attribution through a relevant licence increases the chance of being
credited and thus benefit from the sharing of data. Moreover, publication of data papers
in journals gives the opportunity to have the data sets published, peer reviewed and cited.
Data sharing
Sharing data is an important aspect of Open Science but is only useful if others can work
with it; find the data, get the data, understand what it is about, and easily process it.
There is however no requirement in Open Science for the data to be open. Data can also
be shared with restrictions but should be as open as possible and only as closed as
necessary. There may be reasons not to make data open; privacy (GDPR), contractual
obligations, the volume (transfer/archiving costs), or simply irrelevant for reuse.
Data can be categorised into three types: 1) open data, 2) shared data and 3) closed data.
Open data is data that anyone can access, use, and share. It must however be licensed to
make clear that anyone can use the data in any way they want, including transforming,
combining, and sharing it with others – and even for commercial purposes. Shared data
may also be widely accessible but under some conditions such as non-commercial reuse.
Not all shared data has to be available to anyone. At the other end, closed data could be
highly sensitive data such as personal data or commercially sensitive data, where it may
not be possible to share the data at all. Nevertheless, a metadata description of such
research data should be shared. Often, a relevant Creative Commons (CC) license is
applicable (https://creativecommons.org/share-your-work/cclicenses/).
Where to share or publish the data
When deciding where to share, deposit or publish the data it may be worth thinking
ahead and consider perhaps some of the following. Maybe there is a repository hosting
data from your research domain, which may then more likely also be used and searched
by fellow researched from this field. Perhaps searching a registry of repositories can be
helpful, such as re3data.org (https://www.re3data.org/). Check if the repository provides
the data with a DOI or another PID and, if needed, whether restricted access to data can
be provided. Some examples of repositories are figshare (https://figshare.com/), DRYAD
(https://datadryad.org/) and the EC funded Zenodo (https://zenodo.org). Institutions may
also offer repositories such as the AU facilities REDCap (https://redcap.au.dk/), a secure
web platform for building and managing online databases and surveys, ERDA

54
(Electronic Research Data Archive; https://erda.au.dk/) for storing, sharing, analysing
and archiving research data, and SIF (Sensitive Information Facility; https://sif.au.dk/)
for storing sensitive data.
To figure where to deposit data or publish data papers, references to data sets in
publications may also be consulted, journal websites and guides to authors, as well as
your peers, data stewards or institutional guidelines. In the interest of open research, the
Peer Community In (PCI) organisation (https://peercommunityin.org/) may also be an
option. PCI is a non-profit organisation of researchers offering transparent peer review,
citable recommendation, and publication of scientific articles in open access for free.
Currently there are seventeen thematic PCIs such as PCI Animal Science, PCI Health &
Movement Sciences, and PCI Mathematical & Computational Biology. Also many
established journals have open versions (with publication fees) like animal – open space,
which ”fully embraces Open Science and its philosophy is that all reproducible research,
the data linked to that research and the associated points of views of the authors will
contribute to knowledge gain” (c.f. https://animal-journal.eu/animal-open-space/).
Funding
The PIGWEB project has received funding from European Union’s Horizon 2020
research and innovation program under Grant Agreement No. 101004770. This
publication reflects the views only of the author, and the European Union cannot be held
responsible for any use which may be made of the information contained therein.
References
1. EC (2018). Turning FAIR into reality: final report and action plan from the
European Commission expert group on FAIR data. European Commission:
Directorate-General for Research and Innovation, Publications Office.
https://data.europa.eu/doi/10.2777/1524.
2. OECD (2015). Making Open Science a Reality. OECD Science, Technology and
Industry Policy Papers, No. 25, OECD Publishing, Paris.
http://dx.doi.org/10.1787/5jrs2f963zs1-en
3. UFM (2014). Danish Code of Conduct for Research Integrity. The Danish Ministry
of Higher Education and Science [UFM, Uddannelses- og Forskningsministeriet].
https://ufm.dk/en/publications/2014/files-2014-1/the-danish-code-of-conduct-for-
research-integrity.pdf
4. UNESCO (2021). Understanding open science. UNESCO open science toolkit.
https://doi.org/10.54677/UTCD9302
5. Wilkinson et al. (2016). The FAIR Guiding Principles for scientific data
management and stewardship. Scientific Data 3: 160018.
https://doi.org/10.1038/sdata.2016.18

55
Hvor liberale er Liberal Alliances vælgere?
Anders Milhøj
Anders.milhoj@econ.ku.dk
I efteråret 2023 blev der gennemført en lokal dansk udgave af European Social Survey
(ESS), som er en indsamling udført med stikprøver af befolkningerne i de fleste euro-
pæiske lande. Desværre indgår Danmark ikke i disse år i de fælleseuropæiske dataind-
samlinger, der foretages ca. hvert andet år.
Den lokale indsamling er finansieret af Økonomisk Institut, Københavns Universitet,
men den følger i det store hele den fælles spørgeramme. Undersøgelsen, der blev gen-
nemført af analysebureauet Wilke, havde ca. 1500 respondenter på 18 år og ældre,
dvs. at den er repræsentativ, hvad angår køn, alder og geografi, som andre danske me-
ningsmålinger.
Der spørges i den fælles ESS bl.a. om respondenten stemte ved sidste folketingsvalg
samt hvilket parti, respondenten i givet fald stemte på. Desuden spørges om, hvilket
parti respondenten føler sig tættest på. I den lokale stikprøve blev der yderligere stillet
enkelte aktuelle spørgsmål, bl.a. om alkohol- og tobaksvaner samt om holdninger til
aldersgrænserne for unges køb af alkohol- og tobaksprodukter.
Tilslutningen til Liberal Alliance
I stikprøven havde Liberal Alliance en tilslutning på 7.6% blandt de respondenter, der
stemte ved valget i november 2022, hvilket er stort set det samme som resultatet 7.9%
ved valget. I efteråret 2023, altså omkring et år efter valget, var tilslutningen lidt hø-
jere, 8.2%, hvilket er noget lavere end set i mange andre meningsmålinger fra efteråret
2023.
Blandt Liberal Alliances vælgere er der i denne undersøgelse en overvægt af unge,
mænd, byboere og personer med højere indkomster, hvilket mange andre undersøgel-
ser også har vist, se fx. Altinget Hvem stemmer på Liberal Alliance? Her er partiets ty-
piske vælger - Altinget - Alt om politik: altinget.dk.
Alkohol- og tobaksforbrug
Det er velkendt, at netop spørgsmål om drikke- og rygevaner kan være svære at opnå
pålidelige svar på, da mange respondenter forsøger at gøre besvarelsen mere ’korrekt’,
end den er i virkeligheden. I modsætning til tidligere ESS-undersøgelser, der var ind-
samlet ved face-to-face interviews, er denne ESS indsamlet via internettet, så måske er
trangen til at lyve sig bedre, end man er, ikke så stor.

56
Tabellen viser alkoholforbruget for Liberal Alliances vælgere sammenholdt med andre
partiers vælgere. Her er naturligvis kun brugt de respondenter, der stemte ved sidste
folketingsvalg, hvilket fx. 18-årige respondenter ikke havde mulighed for.
Drikker du alkohol?
Stemte på Andet
Stemte LA
Total
Slet ikke
221
16.57%
11
11.83%
232
En gang om m
å
neden
412
30.88%
34
36.56%
446
En gang om ugen
521
39.06%
39
41.94%
560
Dagligt
164
12.29%
9
9.68%
173
Ønsker ikke at oplyse
16
1.20%
0
0.00%
16
Total
1334
93
1427
Det er tydeligt, at LA vælgernes drikkevaner ligner vanerne hos de øvrige partiers
vælgere, da ingen forskelle er væsentlige. De små forskelle kan let forklares ved at
LA’s vælgere i hovedtræk er yngre end andre partiers vælgere.
Holdning til aldersgrænser for unges køb af alkohol
I de senere år har diskussionerne om aldersgrænserne for unges køb af alkohol og ni-
kotinprodukter spidset til, da flere og flere røster ønsker højere aldersgrænser og en
styrkelse af kontrollen med de indførte grænser. Derfor blev der i efteråret 2023 talt en
del om disse aldersgrænser, og der blev indgået politiske aftaler.
Midt i november 2023 blev der indgået en såkaldt ’forebyggelsesaftale’ mellem rege-
ringen, Alternativet, Danmarksdemokraterne, Konservative og SF. Aftalen indeholdt
skarpere aldersgrænser for salg af alkohol til unge, som blev vedtaget i juni 2024. Fra
1. juli 2024 må unge under 18 år kun købe alkohol med en styrke under 6%, svarende
til højst guldøl, men ikke stærkere øl, vin eller de meget populære shots med en pro-
cent under den tidligere grænse fra 2010 på 16.5% for unge over 16 år.

57
Aftalen omhandlede tillige tiltag for at mindske salget af nikotinprodukter målrettet
yngre, fx. forbud mod visse tilsætningsstoffer til e-cigaretter; dette mere komplekse
forslag er i høring frem til august 2024.
Tabellen viser holdningen til aldersgrænser for unges køb af alkohol blandt Liberal
Alliances vælgere sammenholdt med andre partiers vælgere. Der spørges altså til de
grænser, der gjaldt i efteråret 2023, dvs. før skærpelsen i sommeren 2024.
Er aldersgrænserne for unges køb af alkohol…
Stemte på Andet
Stemte på LA
Total
For lempelige / løse
451
33.81%
21
22.58%
472
Passende
863
64.69%
70
75.27%
933
For strenge
20
1.50%
2
2.15%
22
Total
1334
93
1427
Det vil sige, at 22.58% af LA vælgerne synes, at reglerne er for lempelige, mens hele
33.81% af de respondenter, der stemte på andre partier, synes grænserne er for lempe-
lige. Forskellen er synligt stor, men dog kun lige knapt signifikant, p = 8.1%. Hvis de
få, der synes, at reglerne er for strenge, slås sammen med den store gruppe, der svarer,
at reglerne er passende, bliver p = 2.2%, dvs. at forskellen er signifikant.
Det betyder, at LA’s vælgere er mere liberale, når det gælder mulighederne for unges
alkoholkøb end andre partiers vælgere. Men så er det også slut med velvilligheden, for
så godt som ingen, heller ikke blandt LA’s vælgere, ville slække på de daværende
grænser.
Rygning
I undersøgelsen er der, som for alkohol, ingen forskel på rygevanerne mellem LA væl-
gere og andre partiers vælgere. Men i modsætning til holdningen til unges alkoholkøb
er der heller ingen væsentlige forskelle på LA’s og andre partiers vælgere.
Den nuværende grænse har været ved 18 år siden 2008, og halvdelen af vælgerne og
endda også halvdelen af LA’s vælgere svarer, at den grænse er for løs. Der er altså
grænser for hvor liberale LA’s vælgere er.

58
Er aldersgrænserne for unges køb af tobak…
Stemte på Andet
Stemte på LA
Total
For lempelige / løse
702
52.62%
47
50.54%
749
Passende
608
45.58%
44
47.31%
652
For strenge
24
1.80%
2
2.15%
26
Total
1334
93
1427
Den nuværende grænse har været på 18 år siden 2008, og halvdelen af vælgerne og
endda også halvdelen af LA’s vælgere svarer, at den grænse er for løs. Der er altså
grænser for hvor liberale LA’s vælgere er.
Hvilke holdninger får vælgere til at stemme på Liberal Alliance
I ESS fra 2023 blev der stillet en række aktuelle holdningspørgsmål om hjemmear-
bejde, ukrainekrigen, covid, flygtninge, prisstigningerne og også de generelle ESS
spørgsmål om tillid til statens autoriteter og tilfredshed med livet. De generelle spørgs-
mål blev stillet til alle respondenter, men de aktuelle holdningsspørgsmål blev stillet i
batterier, hvoraf den enkelte respondent kun fik halvdelen af spørgsmålene i hvert bat-
teri.
I det følgende udføres først en screening på det originale datasæt med manglende vær-
dier af spørgsmålene for at finde hvilke spørgsmål, der kan bruges til at karakterisere
LA’s vælgere og dernæst udføres mere samlede analyser på et datasæt, hvor de mang-
lende værdier er imputeret.
Screening af enkeltvariable
Ved hjælp af en SAS-makro blev det undersøgt om de enkelte holdningsspørgsmåls
gennemsnit for LA’s vælgere var signifikant forskelligt fra gennemsnittet for vælgere,
der stemte på andre partier – bemærk at denne gruppe omfatter alle andre partier fra
venstre til højre, så den er meget inhomogen. Makroen kaldte blot Proc Ttest i SAS
med en class statement for hver af de mange holdningsspørgsmål. Det viste sig, at 35
spørgsmål gav signifikante forskelle med p-værdier mindre end 5%; de 10 mest signi-
fikante er vist i næste tabel.

59
Variabel
Obs
Differens
p
Jeg er bekymret for, at mange mennesker vil glemme de vig-
tige læreprocesser fra pandemien og vende tilbage til tidli-
gere vaner
691
1.93488
<.0001
Har/havde du mulighed for hjemmearbejdsdage på dit nu-
værende eller seneste arbejde?
1427
0.19435
0.0002
At agere bæredygtigt er en vigtig del af, hvem jeg er
718
1.37456
0.0002
Hvor stor tillid har du til politikere?
1421
0.87306
0.0006
Jeg føler, at min tillid til myndighederne er blevet påvirket
positivt af deres håndtering af pandemien
705
1.40931
0.0007
Jeg føler, at min tillid til myndighederne er blevet påvirket
negativt af deres håndtering af pandemien
684
í1.49623
0.0007
Jeg synes, at flygtninge bør have adgang til midlertidig el-
ler permanent opholdstilladelse i mit land
666
1.56321
0.0008
Jeg er bekymret for, at Ukrainekrigen kan eskalere til en
større international konflikt
677
1.34413
0.0010
Jeg mener, at individuelle handlinger ikke vil have en bety-
delig indvirkning p
å
klimaforandringerne, medmindre store
virksomheder også ændrer deres praksis
689
í1.35787
0.0015
Danmark bør være et foregangsland, hvad angår bæredyg-
tig udvikling
685
1.44162
0.0015
Desuden blev det undersøgt med anden SAS-makro om de enkelte holdningsspørgs-
mål kunne forklare, at en vælger havde stemt på LA i en logistisk regressionsmodel
for alle vælgere med LA som ’event’. Her blev resultaterne undersøgt ud fra AUC,
’Area Under the Curve’, dvs. arealet under ROC kurven. De 10 mest betydningsfulde
variable med højest AUC er vist i følgende to tabeller.

60
Variabel
Odds
Ratio
AUC
Jeg er bekymret for, at mange mennesker vil glemme de vigtige lære-
processer fra pandemien og vende tilbage til tidligere vaner
0.763
0.685
Jeg synes, at flygtninge bør have adgang til midlertidig eller perma-
nent
opholdstilladelse i mit land
0.842
0.650
Jeg mener, at individuelle handlinger ikke vil have en betydelig ind-
virkning p
å klimaforandringerne, medmindre store virksomheder
også ændrer deres praksis
1.231
0.649
Jeg er bekymret for, at Ukrainekrigen kan eskalere til en større inter-
national konflikt
0.814
0.648
At agere bæredygtigt er en vigtig del af, hvem jeg er
0.814
0.646
Jeg føler, at min tillid til myndighederne er blevet påvirket positivt af
deres håndtering af pandemien
0.844
0.641
Jeg føler, at min tillid til myndighederne er blevet påvirket negativt
af deres håndtering af pandemien
1.167
0.630
Danmark bør være et foregangsland, hvad angår bæredygtig udvik-
ling
0.835
0.630
Jeg mener, at det er vores moralske pligt at hjælpe flygtninge, uanset
omkostningerne
0.867
0.628
Jeg mener, at flygtninges ankomst kan være en byrde for landets øko-
nomi
1.215
0.627
En samlet model for holdninger hos Liberal Alliances vælgere
Når alle holdningsvariable inddrages på en gang i en logistisk regressionsanalyse, kan
modellen med alle variable naturligvis ikke estimeres, men der kan foretages en varia-
beludvælgelse.
I første omgang foretages en forward udvælgelse, hvor de mest betydningsfulde vari-
able successivt tilføjes modellen indtil ikke flere bidrager signifikant målt på signifi-
kans af parameteren. Der anvendes kun de variable, der i tabellerne over de variables
enkeltvise betydning er enten signifikante i en parvis sammenligning med Proc Ttest
på et 5% niveau eller har en AUC værdi over 0.6%

61
Da de fleste holdningsspørgsmål kun er besvaret af halvdelen af respondenterne, løber
denne metode hurtigt tør for komplette observationer af alle de brugte variable i mo-
dellen. Derfor anvendes et imputeret datasæt, se indlægget ved symposiet januar 2024,
der er komplet, men naturligvis præget af en vis usikkerhed. Især skal det vurderes ud
fra, at de manglende værdier er beregnet ud fra de observerede værdier af andre vari-
able, så der må forventes stærkere samvariation mellem variablene end der måske ville
være i et oprindeligt fuldstændigt datasæt; altså en øget risiko for multikollinearitet.
I den variabeludvælgelse bliver 6 variable signifikante i den afsluttende model, som
giver følgende estimater
Estimat
St
d
Err
Wald ȋ2
Pr
>
ChiSq
Label
0.3078
0.6528
0.2223
0.6373
Intercept
í0.1859
0.0483
14.8310
0.0001
Hvor stor tillid har
du til politikere?
í0.0792
0.0329
5.7950
0.0161
Danmark
bør
være et foregangsland, hvad
angår bæredygtig udvikling
í0.7048
0.2248
9.8303
0.0017
Har/havde du mulighed for hjemmearbejds-
dage på dit nuværende eller seneste ar-
bejde?
í0.0736
0.0330
4.9595
0.0259
Jeg er bekymret for, at Ukrainekrigen kan
eskalere til en større international konflikt
0.1198
0.0579
4.2866
0.0384
Jeg tror, at inflationen er midlertidig og vil af-
tage i de kommende år
í0.1074
0.0526
4.1757
0.0410
Jeg mener, at inflationen rammer lavind-
komstgrupper hårdere end
højindkomst-
grupper
De forklarende variable er alle angivet på en skala fra nul til ti, hvor nul er helt uenig
og ti er fuldstændig enig. Det betyder, at LA’s vælgere:
Ikke har tillid til politikere
Ikke har/havde mulighed for hjemmearbejde
Ikke prioriterer bæredygtighed
Ikke er bekymret for at ukrainekrigen udvikler sig
Tror at inflationen aftager snart
Ikke mener, at inflationen rammer de fattige hårdere end de rige

62
For at give et billede af, hvilke sandsynligheder, der er tale om, viser næste figur et ef-
fektplot, hvor effekten af variablen tillid til politikere varieres fra nul til ti, mens alle
de andre variable fastholdes til den mest ekstreme værdi (nul eller ti), der fører til hø-
jest sandsynlighed for at stemme LA.
0.0
0.2
0.4
0.6
0.8
1.0
Probability
0 - Slet ikke 2 4 6 8
10 - Fuld tillid
Hvor stor tillid har du til politikere?
Predicted Probabilities for la_sidste = LA
With 95% Confidence Limits
Fitcomputed atklima_1=0 hj1=0 ukrainekrigen_10=0 priser_4=10 priser_9=0

63
Modellen har en AUC på c = 0.708 beregnet ud fra ROC kurven
0.00
0.25
0.50
0.75
1.00
Sensitivity
0.00 0.25 0.50 0.75
1.00
1 - Specificity
ROC Curve for Model
Area Under the Curve = 0.7080

64
Kan BBR registeret bruges til retvisende ejendomsvurderinger?
Peter Linde, Peter@Brede.dk
Tidligere metodechef i Danmarks Statistik
Nævnsmedlem til vurderingsankenævnet 2023-2027
Bestyrelsen i Dansk Selskab for Surveyforskning og Symposium i Anvendt Statistik.
Censor på universiteterne i økonomi og statistik
Cand. scient. i matematisk statistik fra Københavns Universitet
Sammenfatning
I Skatteøkonomisk Redegørelsen 2021 står: Det hidtidige ejendomsvurderingssystem
har vist sig udfordret. Grund- og ejendomsvurderingerne har generelt været for upræ-
cise, uensartede og uigennemskuelige og er desuden blevet kritiseret af Rigsrevision.
Om de nye ejendomsvurderinger står der samtidig i redegørelsen: De nye vurderinger
af grund- og ejendomsværdier for ejerboliger er baseret på et bedre datagrundlag og en
bedre statistisk model end det gamle vurderingssystem. Det giver mere præcise, ensar-
tede og gennemskuelige vurderinger. Står der.
I ”Skatteøkonomisk Redegørelse 2021” står der alligevel på side 172: Der kan også
være udfordringer forbundet med kvaliteten af de data, som fremgår af Bygning- og
Boligregisteret (BBR). Denne afgørende forudsætning for retvise vurderinger er dog
ikke blevet undersøgt nærmere i redegørelsen.
De fleste gennembearbejde modeller til estimation af ejendomsvurderinger vil virke,
hvis data om boligerne er retvisende. Sikkert også den model, der er brugt til de forelø-
bige vurderinger. Som svar på et ønske om aktindsigt heri er der givet adgang til et notat:
Vurderingsmodel for ejerboliger 2019 (Se ”kilder” til sidst). Notatet indeholder en gen-
nemgang af modellen, men deler ikke centrale oplysninger om fx graden af forklaret
variation, signifikans af modellens forklarende faktorer eller alternative løsninger.
Udfordringen for vurderingerne er, at datakvaliteten i BBR ikke gør det muligt at lave
sikre retvisende estimater. En del af vurderingerne ligger inden for tolerancegrænsen i
lovgivningen på plus/minus 20%, dvs. et samlet spænd på 40%. Det betyder, at en ejen-
domsvurdering med en modelbaseret ejendomsvurdering på 5 millioner ikke ændres,
hvis den vurderingsfaglige vurdering er indenfor 1 million fra den modelbaserede. Også
selv om den er baseret på fejl i BBR. Indenfor tolerancegrænsen på plus/minus 20% vil
der ligge en del vurderinger, hvor estimatet påvirkes reelt af forkerte BBR oplysninger.
En vurdering af en ejendom afhænger ikke af historiske salgspriser for ejendommen,
men af de 15 nærmeste nabohandler. Selv om boligejeren har indberettet korrekt til BBR
vil ejendomsvurderingen også afhænge af, om naboerne har indberettet korrekt til BBR.
Udfordringerne med de nye ejendomsvurderinger er ikke primært et IT problem eller
den statistiske model - det er dataproblemet i selvrapporterede oplysninger til BBR, uden
egeninteresse i de er retvisende. Man har i hele processen overset den største udfordring
– at skabe et system til kvalitetsudvikling af BBR, selv om de røde lamper blinkede.
65
Indledning
De nye ejendomsvurderinger blev oprindeligt estimeret til at koste knap 100 millioner
kroner at udvikle. Her knap 10 år efter beslutningen om at udarbejde ejendomsvurderin-
ger baseret på BBR og statistiske modeller, er der søgt tillægsbevillinger i Finansudval-
get på over 4 milliarder kroner. Og vi har stadig ikke en løsning, der virker stabilt.
De historiske salgspriser, geodata samt Bygnings- og Boligregisteret (BBR) er de væ-
sentligste datakilder til statistiske regressionsmodel, der estimerer de nye og foreløbige
ejendoms- og grundvurderinger. BBR blev oprettet i 70-erne og det er boligejernes an-
svar, at alle oplysningerne om areal, opvarmning, tilbygninger mv. er retvisende. Udfor-
dringen for kvaliteten af BBR er, at boligejerne ikke har nogen egeninteresse i, der står
det rigtige i BBR. Hvis arealet er angivet for lille, tilbygninger eller forbedringer ikke
er oplyst, vil det give lavere ejendomsvurderinger.
Den afgørende forudsætning for alle statistiske modeller er at data er retvisende. Ellers
kan de ikke bruges til analyser og estimationer. Forudsætningen er også vigtig fordi i
komplekse statistiske modeller og ”kunstig intelligens” (Artificial Intelligence) kan IT
udfordringer, fagudtryk og matematiske formler skygge for det grundlæggende: Kan
data overhovedet bruges? Estimationen af ejendomsvurderingerne kan aldrig blive
bedre end kvaliteten af input data, men vil ofte blive markant dårligere. Det skyldes at
den statistiske model i sin optimering med forkerte data, kan give systematiske og vilde
outliers. Specielt hvis der bruges komplekse modeller og ikke robuste metoder. At en
statistisk model er kompleks og svær at forstå, er ikke i sig selv et kvalitetsstempel.
Ovenstående var baggrunden for jeg, som uddannet matematisk statistiker og tidligere
metodechef i Danmarks Statistik, med ansvaret for udarbejdelse af varedeklarationer for
blandet andet BBR, søgte om aktindsigt om:
1) De bagvedliggende statistiske regressionsanalyser (IA), der ligger bag modellen
til fastlæggelse af ejendoms- og grundvurderingen.
2) De bagvedliggende bilag til punkt 1
3) Den endelige model og notater/redegørelser, der beskriver denne. Herunder be-
tydningen sf generelle landsdækkende forhold/relationer, lokale og vægtningen
af nærmeste handler.
4) Hvordan ovenstående er formidlet til ledelsen i vurderingsankestyrelsen samt til
politikere/departementet og ministeren.
Ansvaret for BBR og retsgrundlaget
Det er kommunerne, der er registerfører for oplysninger i BBR og det er ejerne af boli-
gerne, der er forpligtiget til der står de rigtige oplysninger om boligen de ejer. For at
give kommunerne et retsgrundlag giver BBR loven grundlag for at give bøder på op til
5.000 kr. for urigtige oplysninger. Det er ikke lykkedes at finde et eneste tilfælde, hvor
denne bestemmelse har været anvendt i 50 år, og der findes ikke retningslinjer for, hvor-
dan kommunerne skal fastlægge bødestørrelsen mere konkret. BBR har løbende tilsyn
af kommunernes opgaver med BBR og på BBR’s hjemmeside findes 22 tilsyns-

66
rapporter1 fra 2021-2024. Ikke i en eneste tilsynsrapport er det oplyst, der er givet bøder.
Spørgsmålet behandlers ikke i opfølgningen eller konklusionen i tilsynsrapporterne.
Ved udbetalingen af støtte til gasopvarmning i 2022/2023 blev det synligt, at kvaliteten
af BBR ikke er godt nok til retvisende myndighedsafgørelser. I 2022 besluttede Folke-
tinget, at de omkring 405.000 husstande, der havde gasopvarmning ifølge BBR, skulle
have et skattefrit beløb afhængig af indkomst. I alt blev der udbetalt 2,4 milliarder kro-
ner. Mindst 147 millioner kroner blev udbetalt forkert. Det blev besluttet, at fejludbeta-
linger, baseret på der i BBR forkert stod, at ejendommen var gasopvarmet, ikke skulle
tilbagebetales. Ifølge loven om BBR er det ejerens ansvar, at oplysningerne er retvi-
sende, og mangler kan betyde en bøde på op til 5.000 kr. Med beslutningen om at fejl-
indberetninger til BBR ikke skulle tilbagebetaltes blev det modsatte retsprincip under-
støttet. Der blev ikke rejst bødekrav og fejludbetalingen kunne beholdes. Det udfordrer
hvilke krav, der fremadrettet kan rejses overfor forkerte BBR indberetning.
Kvaliteten af registre og BBR
Grundlæggende afhænger kvaliteten af et register om at alle dem, der indberetter, bruger
registeret eller er ansvarlige for registeret, har interesse i at oplysningerne er rigtige.
Samt af hvor krævende (byrden) det er at indberette korrekt. Interessen for at indberette
korrekt kan fx skyldes bødekrav eller økonomiske tilbagebetalinger. Godkendelse af
selvangivelsen for skat er ligesom indberetninger til BBR baseret på selv-angivelser.
BBR er primært en indberetning på eget initiativ, og skatteopgørelsen modsat en god-
kendelse af registrerede oplysninger og kontrol fra flere kilder. En lønmodtager og ar-
bejdsgiver kan fx have fælles interesse i at lønnen oplyses korrekt og kontrollerer på den
måde hinanden. Så denne oplysning er som udgangspunkt mere retvisende end fx op-
lysningen om arbejdstid og stilling, der også følger med arbejdsgiverens indberetning
om løn. Tilsvarende har skolerne en interesse i at indberette nye elever til elevbestanden,
fordi det giver øget støtte. Denne oplysning er som udgangspunkt af en bedre kvalitet,
end indberetninger om ophørte elever i studieforløbet. Det samme gælder indberetnin-
gen af diagnose og sygdom, der efterfølgende er behandlet eller viste sig ikke rigtige.
I BBR er udfordringen, at ejeren ikke har en økonomisk fordel af at indberette øgede
boligareal, nye toiletter eller udbygninger, da det øger ejendomsbeskatningen. Køber har
heller ikke en interesse i at sælger oplyser fx øget areal, da de så får øget ejendomsskat.
Hvis den nye ejer omvendt bagefter opdager, at arealet er for højt i BBR, er der højeste-
retsafgørelser, der understøtter, der kan rejses krav mod sælger og den nye ejer vil rette
det i BBR, da det betyder mindre beskatning. Så når arealet ikke er korrekt i BBR, er
det oftere for lavt end for højt.
1 Bornholm, Skive, Favrskov, Glostrup, Lolland, Frederikshavn, Faarborg-Midƞyn, Odsherred, Ikast-Brande, Jam-
merbugt, Ringkøbing-Skjern, Odense, Vordingborg, Frederikssund, Sønderborg, Slagelse, Nordfyn, Greve,
Stevns, Hjørring, Nyborg, Varde og Holstebro.

67
Om kvaliteten i BBR skriver BBR:
Det er et tilbagevendende spørgsmål, hvor god datakvaliteten i BBR faktisk er. Svaret er
tæt knyttet til spørgsmålene om, hvad det er man ønsker at registrere i BBR og hvad det
skal anvendes til. Da formålet med BBR er mangesidigt bliver kvalitetsspørgsmålet det
også. Derfor kan der ikke gives noget eksakt og generelt svar på, hvor god datakvaliteten
er, da det afhænger af den sammenhæng, BBR-data skal indgå i2.
BBR-myndigheden forsøger alligevel at finde metoder til at måle datakvalitet. Den se-
neste måling af datakvaliteten i BBR er foretaget af SAS Institute, som ifm. arbejdet i
regeringens ekspertudvalg om ejendomsvurderingen, gennemførte en omfattende ana-
lyse af BBR-data i 2014.
Man skal dog, som det fremgår af rapporten fra SAS Institute, være opmærksom på, at
den anvendte metode med såkaldte regelscanninger, udmærker sig ved at finde observa-
tioner, der enten er objektivt forkerte eller afviger fra normalen for de undersøgte grup-
per. Fejlbehæftede observationer, der ligger inden for et plausibelt interval, er langt
vanskeligere at opdage, og vil typisk ikke kunne identificeres ved regelscanninger af
denne karakter.3
Hvis sådanne fejl skal måles, er en grundig manuel stikprøvekontrol med besøg på ejen-
domme en mulighed for at af- eller bekræfte kvaliteten af data. Udfordringen ved en
sådan stikprøve er, at den skal afspejle den høje kompleksitet, som kendetegner den dan-
ske boligmasse, hvor der findes mange særtilfælde inden for hver boligtype. Et betyde-
ligt antal manuelle tjek ville derfor være en nødvendighed.4
Det er således ikke umiddelbart muligt hos BBR at finde oplysninger om BBR registeret
har en kvalitet, der understøtter, det er muligt at bruge til retvisende ejendomsvurderin-
ger. Det skal undersøges konkret da det ”afhænger af den sammenhæng BBR-data ind-
går i.” En sådan undersøgelse med manuelle tjek er ikke lavet i forbindelse med brugen
af BBR som primærkilden til de nye ejendomsvurderinger.
Danmarks Statistik bruger BBR registeret til statistik og skriver følgende i varedeklara-
tionen om statistikken:
Det er i høj grad op til boligejere selv at opdatere oplysninger i BBR, derfor kan man
tvivle på at ændringer fx i antal værelser, toilet-/badeforhold eller skift af opvarmning
altid bliver meddelt BBR.5
Hovedkilde til usikkerhed er, at der er mangler i rapporteringen. Manglerne skyldes
uvidenhed, forsømmelighed, glemsomhed eller andet. Det er for eksempel usikkert i hvor
stort omfang, borgeren melder ændrede antal værelser når der laves en ombygning eller
udskiftning af varmekilde.
2 ForfaƩers understregning. Her er det myndighedsafgørelser om beskatning.
3 ForfaƩers understregning
4 ForfaƩers understregning
5 ForfaƩers understregning

68
Danmarks Statistik tager på denne måde et væsentligt og generelt forbehold overfor sik-
kerheden af oplysningerne.
Når man søger i sager på internettet, bekræftes at BBR er udfordret på en lang række
punkter. DR har spurgt beskikkede landinspektører om de er enige i, at man kan regne
med oplysningerne i BBR-registeret er korrekte. 6% er enige i de er rigtige, mens 58%
er uenige eller meget uenige i de er rigtige. Til DR siger en landinspektør om BBR-
oplysningerne: Jeg bliver overrasket når det passer. LIFA, der arbejder med opmåling
af ejendomme, skriver fx: Det er alment kendt at en meget stor del af arealerne i BBR
er fejlbehæftede. LIFA vurderer, at der er fejl i op til 20% af de registrerede boligarealer.
Konkrete tjek hos LIFA har vist at 20-25% var forkerte.
Selv om der har været mange advarsler og kendskab til at BBR ikke havde en særlig høj
kvalitet er der ikke udviklet et egentligt driftssystem til at sikre den løbende kvalitet.
Mere brugervenlige indberetninger løser det ikke. Mange data er ikke det samme som
kvalitet. Egentligt kunne man stoppe artiklen her, for der er ikke grundlag for at antage,
at BBR registeret kan bruges til retvisende ejendomsvurderinger, uden betydeligt under-
støttende vurderingsfaglig sagsbehandling og et nyt driftssystem. For fuldstændighe-
dens er der alligevel et kort overblik over modellen nedenfor.
Estimationsmodellen
Den statistiske model er nærmere beskrevet i bilaget Vurderingsmodel for ejerboliger
2019, Implementeringscenteret for Ejendomsvurderinger, Udviklings- og Forenklings-
styrelsen, Modelkontoret, der findes på www.statistiksymposium.dk under Symposie-
bogen 2025.
Modellen for ejendomsværdien bygger på kvadratmeterprisen, som er handelsprisen
divideret med det sammenvejede boligareal, som det er kendt fra salgsopstillinger fra
ejendomsmæglere. Handelsprisen reguleres med tidsudviklingen, så de kan sammenlig-
nes. Kvadratmeterprisen, der er responsvariablen i den efterfølgende regressionsana-
lyse, er højreskæv. Det bruges i notatet som argument for at transformere

69
kvadratmeterprisen med logaritmen. Den logaritmiske fordeling af kvadratmeterpri-
serne er mere normalfordelt. Begrundelsen for transformationen er ifølge notatet, at det
er en forudsætning for middelrette estimater i en statistisk model. Transformationen har
samtidigt den konsekvens, at de forklarende variabler og faktorer påvirker kvadratme-
terprisen multiplikativt. Dvs. en resulterende faktor 1,1 for fx WC, påvirker kvadratme-
terprisen med 10%, frem for fx en addidativ virkning på fx 1.000 kr. for et WC, uanset
hvor høj kvadratmeterprisen er. Uanset om det er en multiplikativ eller adidativ virkning,
ganges kvadratmeterprisen til sidst med det sammenvejede boligareal for at for at esti-
mere ejendomsværdien, så WC-et i en stor ejendom tæller mere, uanset addidativ eller
multiplikativ virkning i modellen. Det giver god mening, da der normalt også er større
og bedre WC-er i store end i små ejendomme. Det ses generelt i modeller om ejendoms-
vurderinger, at en multiplikativ virkning giver en pæn ’grad af forklaret variation’ og
bedre modelfit. Men det behøver ikke at være tilfældet og er ikke beskrevet i notatet om
den konkrete analyse. Her begrundes den logaritmiske transformation med at ejendoms-
priserne hermed bliver normalfordelte. Normalt ville man statistikfagligt tage udgangs-
punkt i om afvigelserne (residualerne) er normaltfordelte. Dette er ikke undersøgt.
Det første trin er en naboprismodel, hvor handler i nærheden af den ejendom, der vur-
deres, får højst værdi, når de ligger tæt ved ejendommen og mindst, når de ligger længere
fra. Vægtene estimeres og bestemmes vha. en kernefunktion og summer til 100%. Det
samvejede gennemsnit beregnes som:
Gennemsnit af N observationer, der er responsvariablen i regressionen, er ifølge den
centrale grænseværdisætning i sig selv asymptotisk normalt fordelt. Uanset transforma-
tion af logaritmen.
I et vist eksempel i notatet med 15 nabohandler er den højeste vægt 15% og den mindst
1%. Det betyder de nærmeste 4 handler tæller for godt halvdelen. I hvilken grad det
giver større præcision eller mere variation for den enkelte vurdering er ikke beskrevet,
men vurderingen bliver i alle tilfælde mere afhængig af om BBR oplysningerne for de
allernærmeste handler er indberettet korrekt. Hvis moderniseringer eller det fulde areal
ikke er indberettet korrekt i de allernærmeste handler, har det stor og følsom betydning
for at kvadratmeterprisen stiger, selv om den ejendom, der vurderes, har indberettet kor-
rekt.

70
Vægtene rangordens efter afstand, og hvis der er 15 nabohandler, er det de samme låste
procenttal man bruger. De fx 15 handler findes ud fra en cirkel med centrum i den bolig,
der estimeres. I notatet begrundes dette med, at ”metoden svarer til det en ejendoms-
mægler ville gøre i en vurderingssituation. Metoden er således valgt ud fra et vurde-
ringsfagligt synspunkt.” I den ejendomsvurdering jeg selv har fået tilsendt, var en cirkel
dog ikke den vurderingsfaglige rigtige tilgang. Af de 15 handler var 5 (33%) i min ræk-
kehusbebyggelse på 188 rækkehuse, hvor der en 1. sal over en del af huset og lodrette
vægge. De andre 10 (67%) handler er fra et naboområde med en helt anden type række-
huse med kælder og 1. sal med skrå vægge. Her ville en lokal ejendomsmægler sam-
menligne med handler fra samme boligforening. Det er det der sker, når der ikke forud
for modelarbejdet er indhentet lokale oplysninger om fx sammenhængende bebyggelser
og ejerlaug for at kvalitetssikre vurderingen. Det betyder for en konkret ens bebyggelse
- at huse i midten af bebyggelsen, sammenlignes med andre huse i bebyggelsen, medens
huse i randen af bebyggelser i væsentlig grad sammenlignes med huse fra andre bebyg-
gelser. Oplysninger om ejerlaug er offentlig tilgængelige oplysninger, som kommunerne
kan hjælpe med. Min bebyggelse på 188 rækkehuse udgør 1% af kommunes indbyggere,
og kommunen 1% af landets indbyggere. Lokal fundering af modellen har ikke været
en del af udviklingsbudget på over 4 milliarder.
Den Hedoniske regressionsmodel for logaritmen af kvadratmeterprisen for bolig num-
mer ”i” opstilles som:
Parameteren ȕ beskriver de J procentvise tillæg til ejendommens kvadratmeterpris. I
notatet står der, at ”det giver letfortolkelige parametre, der kan anvendes til at kommu-
nikere værdifastsættelsen af ejendommen i forhold til ejendomsejer og vurderingsmed-
arbejdere”. I den ret omfattende skrivelse på op mod 50 sider man modtager, når man
får en ejendomsvurdering, er procenttillæggene dog ikke gengivet. Det betyder vurde-
ringen kan fremstå som en ”sort boks”.
Bias i modellen
For ejendomme med gennemførte handler er det muligt at estimere afvigelsen mellem
salgsprisen og den estimere salgspris. I notatet er redegjort for, hvordan dette residual
kan opdeles i tre komponenter:

71
Der er to kvalitetsmål i notatet - det ene er gengivet nedenfor. Det viser, der er størst
sikkerhed i større byer. Der må således forventes flest klager for områder med de lyse
farver i figuren nedenfor, hvor over halvdelen af vurderingerne ligger uden for interval-
let plus/minus 20% af salgsprisen.
Ejendomsværdiens opdeling i grund og bebyggelse
En særlig udfordring i ejendomsvurderingen (EV) er, at den skal opdeles i vurdering af
grunden (GV) og bebyggelsen (BV), fordi grundværdien beskattes separat med grund-
skylden til kommunen.

72
Når en ejendom handles, er det en samlet pris, der ikke deles op i to priser/komponenter
for bebyggelse og grund. Vurderingen af grundværdien søges løst ved at vurdere mar-
kedspriserne ved salg af ubebyggede grunde. Det siger selv, at datagrundlagt for vurde-
ring af grundværdien (GV) bliver med et anderledes datagrundlag og grunde, der ligger
længere væk, og dermed modelbaseret på en anden måde end ejendomsvurderingen. I
notatet er behandlet, hvordan dette søges løst bedst muligt med grundværdikurven. Det
fremgår af notatet, at grundværdierne kommer til at udgøre en større andel af ejendoms-
vurderingen. Det har også betydning for den usikkerhed, der opstår og har også givet en
del debat.
Opsamling
I indledningen til artiklen blev det fremhævet, at udfordringen ved ejendomsvurderin-
gerne ikke primært er et IT eller modelproblem, men et dataproblem ved pga. af kvali-
teten af BBR. Modellerne og IT løsningerne udfordres heraf, og bliver budbringeren for
at data ikke er retvisende. Men ikke årsagen.
Når der laves en konkret ejendomsvurdering, skal man huske, at det både er et spørgsmål
om alle forbedringer er indberettet til BBR og den statistiske afvigelse. De ejen-
domme, der ikke har oplyst alle forbedringer til BBR vil få mindre ejendomsvurderin-
ger, og de ejendomme, der har rigtige oplysninger højere vurderinger. Specielt hvis det
er tilfældet for de nærmeste ejendomme. Det betyder for disse ejendomme, at de bliver
pålagt højere ejendomsskatter ved salg. Den statistiske afvigelse, som er den der er be-
skrevet i figuren med danmarkskortet ovenfor, er et nul-sums spil. Det betyder, at der
generelt for hver ejendom med en for høj vurdering er en med en tilsvarende lavere. De
to komponenter – BBR fejlen og den statistiske fejl er de væsentligste man møder ved
vurderingerne.
Hvis man ville løse udfordringen med kvaliteten af BBR kræver det betydelige ressour-
cer i kommuner og på landsplan i driften samt at lovgivning om bøder efterleves. Men
det kræver nok også en ny lovgivning og retspraksis. Man kunne fx forestille sig føl-
gende:
1) Ejere får frit lejde for ændringer i BBR indtil en given skæringsdato, fx 1. januar
2026. Ændringer der ville resulterer i en anden (højere) vurdering, har ikke kon-
sekvenser og der gives ikke bøde.
2) Efter skæringsdatoen vil ændringer ikke kun blive beskattet fra skæringsdatoen,
men også pålagt et tillæg på fx 25%.

73
3) Når boligen sælges, skriver både sælger og køber under på at BBR oplysningen
er korrekt, som en forudsætning for tinglysning af handlen. Og køber overtager
sælges ansvar fra skæringsdatoen. Køber kan tegne en forsikring herfor eller
bruge konsulenthjælp hertil.
4) Hvis tillæg efter skæringsdatoen ikke kan indfris, indefryses det som gæld i ejen-
dommen med en løbende forrentning.
En ordning som ovenfor vil motivere både sælger og køber til at sikre korrekte oplys-
ninger i BBR. Den nødvendige kvalitet af BBR er en forudsætning for, der kan træffes
retvisende myndighedsafgørelser om ejendomsvurderinger på baggrund af BBR. Som
nævnt tidligere skal der i det hele taget sikres et system til løbende udvikling af BBR,
hvis det fremadrettet skal bruges til myndighedsopgaver, ligesom man gjorde med selv-
angivelserne af skat.
Som afslutning citatet fra Skatteministeriets Skatteøkonomisk Redegørelsen 2021: Der
kan også være udfordringer forbundet med kvaliteten af de data, som fremgår af Byg-
ning- og Boligregisteret (BBR). Ukendt var det ikke!
Ingen kæde er stærkere end sit svageste led.
Kilder
Spørgsmål 1-3 i ansøgningen om aktindsigt.
Vurderingsmodel for ejerboliger 2019, Implementeringscenteret for Ejendomsvurde-
ringer, Udviklings- og Forenklingsstyrelsen, Modelkontoret, der findes på www.stati-
stiksymposium.dk i Symposiebogen 2025 som bilag.
Spørgsmål 4 i ansøgningen om aktindsigt
Skatteøkonomisk redegørelse fra 2021 kapitel 5 (side 163-197) som findes på skatte-
ministeriets hjemmeside. https://skm.dk/aktuelt/publikationer/rapporter/skatteoekono-
misk-redegoerelse-2021

74
Arbejdsmarkedsreformer – øger de beskæftigelsen?1
Professor, dr. scient. adm. Jesper Jespersen
Roskilde Universitet
Indlæg på konference i Anvendt StaƟsƟk, den 27.-28. januar 2025, Odense
Abstrakt
Arbejdsmarkedsreformer har stået stærkt i den økonomiske politik fra slutningen af
1970erne. Men med helt forskellig prioritering i afvejning mellem udbud af og efterspørgsel
efter arbejdskraft. I perioden frem til midten af 1990erne lå fokus på en reduktion af
arbejdsudbuddet, bl.a. gennem en reduktion af den ugentlige arbejdstid, øget ferie og
(tvungen) afspadsering af overarbejde i kombination med en efterspørgselsorienteret
økonomisk politik.
Grundlaget for arbejdsmarkedspolitikken blev efterfølgende ændret radikalt gennem
Velfærdskommissionens (2003-06) redegørelser. Her anbefaledes det at øge
arbejdsudbuddet gennem mindskede sociale ydelser, reduceret indkomstskat samt øget
pensionsalder, hvilket ville ifølge den neoklassiske økonomisk teori føre til en tilsvarende
forøgelse af beskæftigelse.
Artiklen analyserer primært udviklingen på det danske arbejdsmarked igennem de seneste
15 år med fokus på den nyere og mere detaljerede statistik. Med dette afsæt sættes fokus på
det spørgsmål, om det er striben af udbudsreformer, der siden 2006 har kendetegnet den
økonomiske politik, eller om det er efterspørgslen efter arbejdskraft, der er den dominerende
faktor bag den markant U-formede udvikling i både arbejdsudbud og beskæftigelse igennem
periode?
Indledning
I perioden efter 2001 har arbejdsmarkeds- og socialreformer med sigte på at øge
arbejdsudbuddet og dermed – ifølge neoklassisk teori - beskæftigelsen nærmest stået i kø
som de skiftende regeringers højest prioriterede initiativer, uanset regeringens farve.
Reformerne synes stadig ingen ende at ville tage, hvilket i praksis har betydet bl.a. øget
1 DeƩe er en omarbejdet og opdateret arƟkel i forhold Ɵl Jespersen, J. (2023)

75
pensionsalder, mindskede (arbejdsmarkedsrelaterede) sociale ydelser og en reduktion af
progressionen i indkomstskatteskalaen.
Som det vil fremgå af denne artikel, har resultaterne af de mange reformer mildt sagt været
flertydige, idet både arbejdsudbud og beskæftigelse i lange perioder har ligget væsentligt
under det niveau, som kommissionsøkonomerne havde stillet politikerne i udsigt.
Helt tilbage til ’Velfærdskommissionens’ rapport i 20062var anbefalingen fra de deltagende
(overvejende neoklassiske) økonomer, at både en forøgelse af pensionsalderen, beskæring af
efterlønnen, reduktion af sociale ydelser og mindsket progression i indkomstskatteskalaen
ville udgøre vigtige instrumenter for at øge arbejdsudbud og dermed beskæftigelsen.
Men sådan gik det ikke umiddelbart. Ikke mindst viste der sig at være en afgørende forskel
på, om det var tilbagetrækningsalderen, der blev hævet, eller om det var dagpenge-,
kontanthjælpsniveauet og/eller indkomstskatten for de beskæftigede, der blev sænket.
Den helt afgørende forøgelse i beskæftigelsen indtrådte tilsyneladende først, da den
økonomiske politik blev lagt om i kølvandet på udbruddet af Covid19-epidemien. Her blev
Budgetloven suspenderet, og en efterspørgselsorienteret økonomiske politik gennemført
(ikke kun i Danmark, men i EU generelt). Det fik beskæftigelsen opgjort som antallet af
personer (og arbejdstimer) til at overstige niveauet fra 2008 og nåede sit foreløbige
højdepunkt i 2023. I hvilket omfang de mange arbejdsmarkedsreformer har bidraget til
denne gunstige udvikling, mangler endnu at blive endeligt klarlagt.
Denne artikel vil især fokusere på de teoretiske konklusioner, som striben af
arbejdsmarkedsfokuserede kommissioner er nået frem til igennem de seneste 20 år og
sammenholde dem med virkeligheden. En oplagt forklaring på disse markante afvigelser
synes at være, at anbefalingerne alle direkte eller indirekte lænede sig op af en teoretisk
ramme baseret på en generel ligevægtsmodel for dansk økonomi udviklet af
velfærdskommissionen under navnet DREAM (Danish Rational Expectation Annual
Model), Velfærdskommissionen (2004). Den er efterfølgende blevet benyttet af flere
ministerier ved kvantificering af arbejdsudbudsorienterede politiske forslag, se f.eks.
skatteministeriet, (2012). Den i finansministeriet benyttede regnemodel, ADAM udviklet af
Danmarks Statistik, blev efterfølgende tunet, så de langsigtede resultater – fuld (strukturel)
beskæftigelse - flugtede med DREAM-modellen. Dog med den forskel at det i ADAM-
modellen tager adskillige år fra en udbudsreform vedtages og efterfølgende implementeres
til den fulde beskæftigelseseffekt er opnået, Finansministeriet, 2024.
2Įle:///C:/Users/jesperj/Downloads/Velf%C3%A6rdskommissionen+%E2%80%93+form%C3%A5l,+resultater
+og+erfaringer.pdf

76
Arbejdsmarkedet: hvordan beskrives det staƟsƟsk?
Denne artikel må dog indledes med noget så kedeligt som en beskrivelse af de statistiske
udfordringer, som arbejdet med den talmæssige belysning af arbejdsmarkedet indebærer.
Uanset om vi taler om beskæftigelse, arbejdsstyrke eller ledighed, så er der varierende
statistiske definitioner og opgørelsesprincipper, der hver især leder til forskellige empiriske
resultater.
Et klassisk eksempel på en sådan forskel er den statistiske opgørelse af arbejdsløsheden, der
alene i Danmark kan variere med op til 100.000 personer på den samme population og
tidsperiode. Hertil burde der lægges et skøn over den (statistisk) skjulte arbejdsløshed, som
der ifølge sagens natur ikke er (præcise) tal for. De tre af Danmarks Statistik regelmæssigt
offentliggjort tal for arbejdsløsheden lød i 2022 på hhv. 70.000 personer, 90.000 personer
(begge registerbaserede) og 140.000 personer (Arbejdskraftundersøgelse (AKU) baseret på
interviews, der følger EuroStat’s anvisninger)3. Alt mens medierne (og delvis) politikerne
talte om udbredt mangel på arbejdskraft.
Hvordan hænger det sammen? – og kan alle have ret? Det korte svar er desværre et tøvende
’ja’, fordi der benyttes (og delvis argumenteres) ud fra ret så forskellige
opgørelsesprincipper og hensyn, alt efter hvilket spørgsmål, der skal belyses/besvares. De
registerbaserede tal er en opgørelse af det antal (omregnet til fuldtid) personer, der modtager
arbejdsmarkedsydelser fra offentlige myndigheder (Dagpenge, kontanthjælp,
beskæftigelsestilskud mm.). Formålet er her primært at belyse belastningen af de offentlige
budgetter. Da f.eks. dagpengeperioden blev reduceret fra 4 til 2 år, faldt den registrerede
arbejdsløshed – derimod stort set ikke den interviewbaserede arbejdsløshed. De mange
ændringer i de arbejdsmarkedsrelaterede ydelser og dermed den statistiske afgrænsning har
ændret opgørelsesprincipperne i den officielt (mest) benyttede arbejdsløshedsstatistik,
hvilket i sig selv er en udfordring, der delvis kunne afhjælpes ved brug af tal fra AKU-
statistikken, der er baseret på telefoninterview.
Tilsvarende problemer melder sig imidlertid også delvist ved brug af den interviewbaserede
statistik. Idet ændres spørgsmålene, så ændres svarene sig naturligvis også. Hvornår er man
arbejdsmarkedsparat? Oplever man sig selv som arbejdsmarkedsparat (en del af
arbejdsudbuddet), når man igennem 10 år har stået bagest i arbejdsløshedskøen? Her
nærmer vi os begrebet ’skjult arbejdsløshed’. Konstateres må det i hvert fald, at både i
perioden 2005-08 og nu igen 2021-23 er beskæftigelsen steget betydeligt mere, end det
skulle være muligt ud fra de statistiske oplysninger, der forelå om arbejdsudbuddets omfang
lige inden opsvinget tog fart - uanset hvilken af statistikkerne, der benyttes! Da
lavkonjunkturen i 2009 satte ind, faldt beskæftigelsen med ca. 200.000 personer; mens den
registerbaserede arbejdsløshed kun steg med godt 100.000 personer. Årsagen hertil er flere;
3 hƩps://www.dst.dk/da/StaƟsƟk/emner/arbejde-og-indkomst/befolkningens-
arbejdsmarkedsstatus/arbejdsmarkedsregnskab
77
men en væsentlig forklaring er, at adskillige personer ikke var berettiget til dagpenge- eller
kontanthjælp og derfor forsvandt ud af den officielle arbejdsmarkedsstatistik.
Det er således helt afgørende hvilket statistisk grundlag, der benyttes ved analysen af
ændringer i arbejdsløshed og dermed af det potentielle arbejdsudbud: om det skyldes
skiftende konjunkturer, ændringer i befolkningens størrelse, den aldersmæssige
sammensætning, arbejdsmarkedsreformer og/eller ændrede institutioner. Betydningen af
befolkningens størrelse kan delvis afhjælpes ved at benytte andele af den analyserede
befolkningsgruppe i stedet for de absolutte tal. Effekten af arbejdsmarkedsreformer bør
derfor primært måles på, om andelen af en betragtet befolkningsgruppes
arbejdsmarkedstilknytning (erhvervs- og beskæftigelsesfrekvens) har ændret sig.
Arbejdsmarkedsdata fra Danmarks Statistik (DS) er det mest omfattende statistiske
materiale, som står til rådighed. Men også her gælder det, at der er forskellige
opgørelsesprincipper. Hertil kommer såkaldte ’brud’ i de enkelte talserier, der i sig selv
vanskeliggør en sammenhængende statistisk analyse omfattende en længere periode. Den
’officielle’ arbejdsmarkedsstatistik blev senest omlagt fra 2008, hvilket giver en tidsserie på
knap 15 år, som jeg helt overvejende vil benytte mig af. Dette udgangsår er dog ikke ganske
uproblematisk, idet 2008 var et atypisk år med udpræget højkonjunktur. Noget tilsvarende
kan måske siges om slutåret 2023, hvilket på den anden side kan bidrage til at belyse
betydningen af efterspørgslen efter arbejdskraft for beskæftigelse og dermed arbejdsløshed.
Jeg vil afslutte dette indledende statistiske afsnit med at give et helt overordnet billede af
udviklingen på det danske arbejdsmarked fra 2008 til 2023 ved brug af tal fra AKU-
statistikken, der som nævnt (desværre) kun kan føres tilbage til 2008 på en konsistent basis.4
4 Se mere detaljerede oplysninger vedr. AKU-staƟsƟkken:
hƩps://www.dst.dk/da/StaƟsƟk/dokumentaƟon/staƟsƟkdokumentaƟon/arbejdskraŌundersoegelsen--aku-

78
Tabel 1. Arbejdsmarkedsforhold, 2008-2023
AKU-staƟsƟk
Aldersgrupper: 15-74 år
2008
2013
2018
2023
1000 personer
Beskæftigede
2809
2638
2833
3004
AKU-ledige
107
210
153
162
Uden for arbejdsstyrken
1177
1378
1369
1225
i alt
4093
4226
4355
4391
Procent
Beskæftigelsesfrekvens
68,6
62,4
65,1
68,4
Ledighed, pct.
3,67
7,37
5,12
5,11
Erhvervsfrekvens5
71,2
67,4
68,6
72,1
Ginikoefficient
27,9
27,9
29,6
30,6
Noter:
1. AKU-staƟsƟkken er baseret på interviews og omfaƩer i denne opgørelse personer i alderen 15-74 år.
2. Gini-koeĸcienten er et beregnet tal mellem 0 og 100, jo højere tal desto mere ulighed i disponibel indkomst
opgjort på husstand. (Det kan tolkes som et groŌ mål for, hvor stor en andel af den samlede disponible
husstandsindkomst, der skal ŇyƩes fra den halvdel af husstandene, der tjener mest Ɵl den halvdel, der tjener
mindst, for at gøre indkomsten imellem alle befolkningsgrupper helt lige. I 202 er det således godt 30 pct. af
den samlede disponible indkomst, der skulle omfordeles for at skabe en lige indkomsƞordeling.
Kilde: Danmarks StaƟsƟk, ArbejdsmarkedsstaƟsƟk: AKU110A og IFOR41
Det ses af tabellen, at antallet af beskæftigede personer er steget med ca. 200.000 personer
igennem de viste 15 år. Et tal der dog må vurderes i lyset af udviklingen i befolkningens
størrelse, hvilket hhv. beskæftigelses- og erhvervsfrekvenserne belyser. Her ses det, at for
perioden 2008-2023, hvor Danmarks Statistik angiver, at tallene er sammenlignelige, er
erhvervs- og beskæftigelsesfrekvensen i både 2013 og 2018 lavere end i 2008. Dette resultat
er mildt sagt overraskende, da det om noget har været skiftende regeringers erklærede mål
gennem striben af pensions-, arbejdsmarkeds-, social- og skattereformer at øge andelen af
befolkningens tilknytning til arbejdsmarkedet.
Som en konsekvens af arbejdsmarkeds- og skattepolitikken er der derimod igennem hele
perioden sket en stigning i indkomstuligheden, der har flyttet Danmark fra at være et af de
mest lige samfund i OECD til nu at tilhøre (den nedre del af) mellemgruppen af OECD-
lande.
5 Bemærk, at ’erhvervsfrekvensen’ beregnes som (summen af antal beskæŌigede + antal ledige) divideret med det
samlede antal personer i de omhandlede aldersgrupper, 15-74 år.

79
Det analytiske grundlag for arbejdsmarkedsreformerne: arbejdsudbud skaber
sin egen efterspørgsel - i DREAM-modellen
Når jeg indledningsvist ønskede at fremlægge de helt overordnede tal for udviklingen i
arbejdsudbud og beskæftigelse, skyldtes det, at udviklingen i hhv. beskæftigelses- og
erhvervsfrekvens for perioden 2008-2023 er overraskende – og efterlader umiddelbart det
ubesvarede spørgsmål: ’hvilken effekt har arbejdsmarkedsreformerne haft på beskæftigelsen
på trods af de omfattende reformer, der har ændret indkomstfordelingen markant?
Dette ubesvarede spørgsmål udfordrer således den simple regneregel, der benyttes i
Finansministeriet (FM) ved beregning af udbudspolitikkens konsekvenser dvs. ’råderummet
i dansk økonomi’. Ved beregningen af råderummet – opgjort som en hhv. positiv/negativ
saldo på den offentlige sektors budget - antages det a priori, at udbuddet af arbejdskraft
og dermed beskæftigelsen har en substitutionselasticitet på 0,1 med hensyn til forskellen
mellem real lønindkomst og arbejdsmarkedsrelaterede overførselsindkomster, begge opgjort
efter skat6. Denne hypotetiske elasticitet benyttes efterfølgende i finansministeriets
regnemodel til opgørelsen af ændringer i råderummet (dvs. den strukturelle budgetsaldo) for
den økonomiske politik.
Arbejdsmarkedet i finansministeriets regnemodel er (ligeledes a priori) konstrueret således,
at et øget udbud omsættes til øget beskæftigelse i forholdet 1:1. Det sker under henvisning
til moderne makroøkonomisk teori, der er helt dominerende blandt såkaldt mainstream
modeløkonomer Antagelsen er her, at i en velfungerende markedsøkonomi vil: udbud [på
arbejdsmarkedet] skabe sin egen efterspørgsel7. Den makromodel, der benyttes i
finansministeriet, har således denne postulerede egenskab, at udbud af arbejdskraft altid
efterfølgende omsættes til en tilsvarende stigning i beskæftigelsen.8
6 SubsƟtuƟonselasƟciteten og indkomsƞølsomheden forudsæƩes ens for alle beskæŌigede, det vil
sige uaĬængig af køn, arbejdsƟd og indkomstniveau.
Ministerierne anvender en subsƟtuƟonselasƟcitet på 0,1 og en indkomsƞølsomhed på
-0,05 på tværs af alle beskæŌigede, Finansministeriet, Regneprincipper, 2024, p.6
7Denne antagelse er kanoniseret blandt neoklassiske makroøkonomer, jfr. f.eks. tidligere overvismand Hans Jørgen
Whitta-Jacobsen udsagn i 2011 (midt under finanskrisen) gengivet nedenfor, og som jeg spurgte ham om for blot et år
siden, om han fortrød. Det gjorde han ikke.
8 Finansministeriets regnemodel er en tilpasset version af ADAM-modellen, oprindeligt udviklet i Danmarks
Statistik på initiativ af professor Ellen Andersen. Den blev overtaget og efterfølgende stærkt ændret af
finansministeriets økonomer, i en grad så Ellen Andersen havde svært ved at genkende den, idet hun udtalte i
2017: “Modellen siger det, der bliver puttet ind i den. Svaret er ikke noget, der kommer ud af den, det er noget, der
kommer ind i den. Og det er ikke inde i ADAM. Det kommer fra Finansministeriet.” (Professor Ellen Andersen, 27.
februar 2017 interview i anledning af 80 årsdagen med Kristine Dons Christensen, Zetland), Regnemodellernes moder
advarer mod at stole for meget på den model, hun selv har skabt (zetland.dk).
Men uƟlfredsheden i Įnansministeriet med ADAMs grundlæggende egenskaber tog Ɵl i et omfang, så det besluƩede at
opgive samarbejdet med Danmarks StaƟsƟk om modeludvikling. Der var sƟgende uenighed om ƟlpasningshasƟgheden
på arbejdsmarkedet, så det blev besluƩet at opbygge en helt ny regnemodel, MAKRO. Konsulenƞirmaet DREAM blev
engageret Ɵl at forstå deƩe arbejde under ledelse af en styregruppe bestående af repræsentanter fra oīentlige
insƟtuƟoner, herunder naturligvis Įnansministeriet og udvalgte modeløkonomer fra de højere læreanstalter, se bl.a.
DREAM, 2019 og Jespersen, 2017. Det i sƟgende grad blev vanskeligt at få de staƟsƟske esƟmaƟoner, som Danmarks

80
Men denne antagelse matcher ikke den faktiske udvikling, hverken totalt set som beskrevet
ovenfor i tabel 1 eller for arbejdsmarkedets kernegrupper (aldersmæssigt: 35-55 år) igennem
de seneste 15 år, jfr. tabel 2 nedenfor. Derimod synes reduktion af de
arbejdsmarkedsrelaterede sociale ydelser og mindsket progression i skatteskalaen at have
den tilsigtede – omend ikke 1:1 – effekt med hensyn til at øge indkomstuligheden, jfr.
Velfærdskommissionens redegørelse, kap. 4.
Et ændret udbud af arbejdskraft er ikke ensbetydende med en tilsvarende
ændring af beskæftigelse
Forskellen mellem arbejdsudbud og beskæftigelse udgøres af det ofte ganske betydelige og
varierende antal personer, der i kortere eller længere perioder – i ordets egentligste forstand
– er arbejdsløse. Et tal, der svinger både med konjunkturerne, med den økonomiske politik
og med demografien; men som helt åbenbart ikke forsvinder af sig selv.
Går vi tilbage til begyndelsen af 1990erne var der også forskel mellem den registerbaserede
og den AKU-opgjorte arbejdsløshed. Men dengang lå det registerbaserede tal højere en
AKU-statistikken, hvilket kunne tolkes som, at der må have været en del modtagere af
dagpenge og kontanthjælp, der ikke ifølge interviewundersøgelserne umiddelbart stod til
rådighed for arbejdsmarkedet. For så vidt ikke et overraskende resultat i og med at
arbejdsløsheden lå på ca. 10 pct. - svarende til ca. 300.000 personer, der reelt stod uden
arbejde. Det tal blev op gennem 1990erne reduceret ganske betydeligt gennem en målrettet
beskæftigelsespolitik (efterspørgsel) og en målrettet orlovs- og efteruddannelsespolitik
kombineret med en reduktion af ledighedsydelsernes størrelse og varighed, hvorved der
overgangsvist kom balance mellem den register- og den interviewbaserede
arbejdsløshedsstatistik. Efter regeringsskiftet i 2001 og med afsæt i Velfærdskommissionens
(2003-05) anbefalinger blev der som nævnt gennemført en stribe omfattende
arbejdsmarkedsreformer med det primære sigte at øge udbuddet af arbejdskraft. De
væsentligste instrumenter hertil var en forøgelse af pensionsalderen, kraftig beskæring af
efterlønnen, forøgelse af forskellen mellem og omfanget af ledighedsydelser i forhold til
den disponible indkomst, som også en stribe indkomstskattelettelser bidrog til.
StaƟsƟk stadig var hovedleverandør af Ɵl at matche de principper, som Įnansministeriet ønskede, at dets regnemodel
burde baseres på, bl.a. med hvilken hast arbejdsmarkedsreformer slog igennem på beskæŌigelsen og dermed
råderummet i den økonomiske poliƟk.

81
Hvad viser virkeligheden….
Benyttes AKU-statistikken er udviklingen igennem de seneste 15 år tankevækkende. Den
positive effekt på beskæftigelsen af den stribe af udbudsforøgende ’reformer’, som
kommissionsøkonomerne anbefalede, og som politikerne derfor fik ’lovning på’, hvis de
reducerede de sociale ydelser og mindskede progressionen i skatteskalaen, er svær at
genfinde i statistikken, navnlig for de 35-54 årige – der sædvanligvis betegnes som
arbejdsmarkedets ’kernetropper’, se tabel 2.
Jeg har på grund af de ovenfor beskrevne ændringer i statistikken valgt at benytte den
definitorisk sammenlignelige periode begyndelsen i 2008 til slutningen i 2022 (der begge
repræsenterer to konjunkturtoppe)9, jfr. tabel 2. Her kan det konstateres, at
beskæftigelsesfrekvensen set under ét ikke er steget – ja, den er faktisk ½ pct. point lavere i
2022 end i 2008. Denne udvikling dækker ydermere over en skævtrækning af udviklingen,
når den opdeles på aldersgrupper, idet arbejdsmarkedstilknytningen for alle grupper op til en
alder af 45 år er faldet. For aldersgruppen fra 45 til 54 år er tilknytningen – uanset de mange
reformer - stort set uændret. Det er først for grupperne 55 år og opefter at der ses en klar
beskæftigelses- og udbudseffekt, hvilket ikke er overraskende, når de betænkes, hvorledes
førtidspension er blevet markant forringet, og aldersgrænsen for at opnå folkepension er
blevet forøget med to år.
Hvad kan man slutte heraf? 1. udbuddet af arbejdskraft må (også) være bestemt af andre
forhold end størrelsen og varigheden af de sociale ydelser og progressionen i skatteskalaen
for personer i disse aldersgrupper, der som arbejdsmarkedsparat ikke har mulighed for at få
en anden social ydelse. Man kunne ligefrem få den kætterske tanke, at forringelserne for de
yngre aldersgrupper ligefrem har haft den modsatte effekt – at de har trukket personer ud af
arbejdsstyrken i takt med, at retten til en social ydelse ophørte, og jobmulighederne
begrænset. (Udfaldseffekten fra arbejdsstyrken var i hvert fald overraskende stor ca. 35.000
personer i 2013, da den reducerede dagpengeret fra 4 til 2 år var fuldt implementeret. En ret
der kun havde omfattet personer i dagpengesystemet, altså personer med en betydelig
tilknytning til arbejdsmarkedet, se Økonomi- og Indenrigsministeriet, 2019.
Ovenstående peger entydigt i retning af, at den hidtil i finansministeriet benyttede
tommelfingerregel, at der uanset aldersgruppe er en arbejdsudbudselasticitet på 0,1 knyttet
til forskellen mellem den disponible lønindkomst og arbejdsmarkedsydelser (efter skat)
trænger til et virkelighedstjek. Og det samme kunne beregningsmodellens a priori-antagelse,
at udbud af arbejdskraft skaber sin egen efterspørgsel efter arbejdskraft, også med fordel
underkastes, se finansministeriet, 2024
Men det ville være uretfærdigt at skære alle neoklassiske økonomer over en kam. Det er
således bemærkelsesværdigt, at Rockwool Fondens forskningsenhed - uanset at den
9 Uanset, at allerede i 2019 var der en udbredt opfaƩelse af, at ’Lige nu er der bragende højkonjunktur i Danmark’ Leif
Bech Fallesen skrev 3. okt. 2019 i Politiken.

82
tidligere har været en stærk fortaler for de gennemførte arbejdsmarkedsreformer – i en
efterfølgende evaluering har nuanceret sin tidligere konklusion, at nedskæring af de sociale
ydelser har haft en positiv beskæftigelseseffekt, se forskningsrapporten Hvordan udvikler
beskæftigelsen sig i Danmark?, juni 2019. Forskerne har her primært benyttet data fra
Styrelsen for Arbejdsmarked og Rekruttering. Efter at have gransket disse tal må forskerne
om end med en vis tøven konstatere, at netop for perioden fra 2008 til 2018 – altså fra en
konjunkturtop til den næste konjunkturopgang, hvor arbejdsmarkedsreformerne har haft
mulighed for at virke i op mod ti år - er antallet af (fuldtids)beskæftigede danskere i alderen
16-64 år faldet med ikke mindre end 150.000 personer. Rockwool Fonden formulerer
resultatet således: ’det er særligt de 25-54 årige (kernegrupperne), der har mistet terræn i
forhold til andre EU-lande’.10
Og hvordan er det gået for personer, der fik (top)skattelettelser? Her er der også
modsatrettede effekter i spil, hhv. en substitutionseffekt mellem arbejde og fritid og en
indkomsteffekt (jo større disponibel indkomst desto mindre incitament til at arbejde mere).
Jens Bonke og Schultz-Nielsens undersøgelse fra 2014 giver en indikation af, hvilken af
effekterne der dominerer. Her konstateres det, at der er en majoritet af danskere, der ønsker
at reducere det ugentlige antal arbejdstimer, men her stiller den overenskomstmæssigt aftalte
arbejdstid sig hindrende for reduktion af den ugentlige arbejdstid. Et resultat der flugter
med det overordnede billede af udviklingen i det gennemsnitlige antal årligt udførte
arbejdstimer pr. person, gengivet i tabel 1.
Derimod er udbud og beskæftigelse steget for de ældste aldersgrupper (55+), hvor
reformerne har været langt mere omfattende, idet den aldersbetingede ret til en permanent
indkomsterstattende ydelse bortfaldt for de aldersgrupper, der blev omfattet af forhøjelsen af
pensionsalderen, beskæring af efterløn og stærkt reduceret mulighed for at få tilkendt
permanent førtidspension. Disse reformer har samlet set indebåret en betydelig forøgelse af
pensionsalderen, hvilket i kombination med et generel løft i den aldersrelaterede
sundhedstilstand har øget både erhvervs- og beskæftigelsesfrekvenserne for aldersgrupper
over 55 år. Bemærkes bør det, at disse frekvenser rent faktisk begyndte at stige, før disse
reformer havde fuld effekt11. En udvikling der ligeledes må tolkes som, at adskillige andre
forhold spiller en væsentlig rolle for arbejdsmarkedsdeltagelsen også i de ældste
10 Her bør det også nævnes, at konsulentgruppen DREAM, der arbejder tæt sammen med finansministeriet, i et forsøg
på at bekræfte deres hidtil mekaniske brug af regnereglen omfattende en udbudselasticitet på 0,1 og fortsat klare
anbefaling af arbejdsmarkedsreformerne heller ikke kan påvise en positiv effekt for de nævnte kernegrupper på
arbejdsmarkedet. Og det på trods af, at forskerne gør sig ihærdige anstrengelser for at påvise en sådan positiv effekt:
idet 2018 sammenlignes med 2000 (der ikke var udpræget højkonjunktur), og der ydermere 1. justeres kraftigt for et
’databrud’ i 2003; 2. der korrigeres for øget antal studerende; i hvilket omfang det reducerer arbejdsudbuddet er ikke
klart belyst; 3. der korrigeres for en ændret befolkningssammensætning flere 1. og 2. generations indvandrere – også her
er det uklart om den tilsyneladende lavere beskæftigelsesfrekvens er et udslag af lavere udbud eller snarere udtryk for,
at disse grupper står bagest i arbejdsløshedskøen (efterspørgselseffekt).
Men på trods af disse tre ’korrektioner’, der alle har til formål at øge beskæftigelsesfrekvensen i 2018 – lykkes det
IKKE for DREAM-gruppen at påvise en forøget beskæftigelsesfrekvens for kernegrupperne, DREAM, 2019
11 Pensionsalderen blev hævet fra 65 år til 67 i perioden fra 2019 til 2022. Hvilket - blot nævnt som et kuriosum - også
var pensionsalderen for opnåelse af folkepension fra den blev indført i 1957 og frem til 2002.

83
aldersgrupper end blot de sociale ydelser. Disse forhold har også afspejlet sig i den
betydelige stigning fra 2020 i antallet tildelte senior- og Arne-pensioner. Førstnævnte er en
helbredsbetinget ydelse, der skal baseres på en lægelig vurdering, mens Arne-pensionen er
rettighedsbetinget (bestemt af antal år på arbejdsmarkedet). Det er dog klart den
helbredsbetingede pensionsret, der har været dominerende af de to
(førtids)pensionsmuligheder. Et forhold, der måske også kan forklares ved at ydelsen for
seniorpension er noget højere. Dette spørgsmål afventer en nærmere undersøgelse.12
Endelig bør udviklingen i de yngre aldersgrupper også vurderes i lyset af ovenstående. Det
forhold af de ældste aldersgrupper nærmest bliver tvunget til at blive længere på
arbejdsmarkedet i takt med, at pensionsalderen hæves, må indebære en risiko for, at der som
en konsekvens heraf vil være færre ledige stillinger, der kan besættes af de unge, der er klar
til at træde ind på arbejdsmarkedet. Dette omtales i dele af litteraturen, som en ’omvendt’
gøgeunge-effekt, hvor de ældre skubber de yngre årgange ud af arbejdsmarkedet. Det skal
dog også bemærkes, at den mindskede arbejdsmarkedstilknytning for de yngre årgange også
skyldes en øget tilgang til ungdoms- og videregående uddannelser.
Afslutning
Som det er fremgået af ovenstående gennemgang af udviklingen på det danske
arbejdsmarked igennem de seneste årtier, er den kendetegnet ved en stribe ganske
omfattende reformer, der over en bred kam kan karakteriseres som en mindskelse og
tidsmæssig afkortning af de arbejdsmarkedsrelaterede ydelser, en reduktion i progressionen
i indkomstskatten og en forhøjelse af pensionsalderen. Uanset disse ændringer kan der ikke i
den selvsamme periode påvises en signifikant stigning i arbejdsmarkedstilknytningen total
set; men derimod en markant stigning i indkomstuligheden målt ved Ginikoefficienten.
Ses der mere detaljeret på udviklingen i de enkelte (tiårs) aldersgrupper, fremtræder der dog
en afgørende forskel. Arbejdsmarkedets kernetropper i alderen fra 35-55 år har siden 2008
fortsat en høj, men reduceret(!) tilknytning til arbejdsmarkedet. Aldersgrupperne over 55 har
derimod opnået en markant forøget erhvervs- og beskæftigelsesfrekvens, der delvis kan
henføres til forøgelsen af pensionsalder, et (delvist) bortfald af efterløn og stærkt beskåret
adgang førtidspensionering. Et billede som muligheden for opnåelse af seniorpension og
Arne-pension ikke har ændret.
12 Efterfølgende har det også vist sig, at finansministeriet overvurderede det antal personer, der ville benytte sig af Arne-
pensionen – hvilket blot understreger betydningen af, at der er jobs til rådighed, som en væsentlig determinant ved
valget med arbejdsindkomst og arbejdsmarkedsydelse, selv af permanent karakter. https://fm.dk/media/18137/ny-ret-til-
tidlig-pension-vaerdig-tilbagetraekning-for-alle.pdf?fbclid=IwAR14WkDi0KrReUzIIezjtiiL6Xe9LJ-
SyyEEP4MtoFhRKSQAxBwNhLCN5FA

84
Ovenstående efterlader et flimrende billede af hvilke faktorer, der er dominerende med
hensyn til udviklingen på arbejdsmarkedet, herunder hvilken rolle de økonomiske
incitamenter egentlig spiller. Men konstateres kan det, at der ikke synes at være nogen
simpel sammenhæng, endsige tommelfingerregel, fra ændringer i social- og skattepolitikken
til udbuddet af arbejdskraft, eller fra udbuddet af arbejdskraft (registreret eller skjult) til
beskæftigelsen. Her spiller efterspørgslen efter arbejdskraft fortsat en betydelig rolle.
Litteratur:
Andersen, T.M. : Velfærdskommissionen – formål, resultater og erfaringer, Samfundsøkonomen, 2/2021,
s. 25-35
Bonke, J. og M.L. Schultz-Nielsen: Do Preferences Impact Behavior and Wellbeing? A Panel Study of
Preferred and Actual Working Time 2001-2008/09,IZA Discussion Paper No. 8356, 34
Pages Posted: 2 Aug 2014
Danmarks StaƟsƟk: Danmarks StaƟsƟks forskellige ledighedsbegreber, 2014,
hƩps://www.dst.dk/Site/Dst/SingleFiles/GetArchiveFile.aspx?Į=arbe&fo=ledighedsbegreber--
pdf&ext={2}
DREAM-gruppen: Ændringer i erhvervsdeltagelsen siden årtusindeskiŌet, arbejdspapir, 2019:4
DREAM-gruppen: Eīekterne af permanent øget arbejdsudbud, dec. 2023
hƩps://dreamgruppen.dk/Media/638448965067506331/arbejdsudbudsstoed.pdf
Finansministeriet, 2024 Regneprincipper personskaƩer,
hƩps://fm.dk/media/mumhodwc/regneprincipper-paa-personskaƩeomraadet.pdf
Greve, B. m.fl., Arbejdsmarkedet og arbejdsmarkedspolitik - en kritisk analyse, København:
Samfundsfagslitteratur, 1996
Grønnegaard Christensen, J. m.Ň.: De store Kommissioner – vise mænd, smagsdommere eller
nyƫge idioter? Syddansk Universitets Forlag, 2009
Jespersen, J.: Økonomien, journalisƟkken og den udeblevne kriƟk i R. Buch & M. Verner (red.),
Krisen i økonomi & JournalisƟk, Forlaget AJOUR, 2014
Jespersen, J.: Vækstøkonomi på Vildspor, Essaysamling, Forlaget Jensen&Dalgaard, 2019
Jespersen, J.: Arbejdsmarkedsreformer på godt og ondt, Særnummer: Velfærdsstatens
udfordringer, forandringer og konsekvenser, Samfundsøkonomen, 2023/4, s. 16-26
Regeringen: Ny ret ƟlƟdlig pension, august 2020
Rockwoolfonden: Hvordan udvikler beskæŌigelsen sig i Danmark?, juni 2019
SkaƩeministeriet: SkaƩereform, beskæŌigelse og velfærd, 2012

85
Velfærdskommissionen: FremƟdens velfærd kommer ikke af sig selv, Analyserapport, 2004
Velfærdskommissionen: FremƟdens Velfærd,slutrapport, 2006,
Įle:///C:/Users/jesperj/Downloads/Velf%C3%A6rdskommissionen+%E2%80%93+form%C3%A5l,+r
esultater+og+erfaringer.pdf
Økonomi- og Indenrigsministeriet: Dagpengereformen 2010: Hvordan gik det? Økonomisk Analyse,
25-02-2019
Tabel 2: Beskæftigelses- og erhvervsfrekvens og arbejdsløshed, 2008-2022
2008
2013
2017
2022
Beskæftigelsesfrekvens
Alder i alt
68,6
62,4
64,2
68,2
15-24 år
62,7
49,6
53,0
56,3
25-34 år
84,6
76,1
75,2
80,5
35-44 år
88,5
84,4
83,9
85,8
45-54 år
87,3
82,6
84,7
87,6
55-64 år
56
58,8
68,2
72,9
65-74 år
11,2
12,9
13,8
17,1
AKU-ledighedsprocent
Alder i alt
3,7
7,4
5,8
4,5
15-24 år
9,5
14,8
12,4
10,5
25-34 år
3,7
8,9
7,6
5,4
35-44 år
2,6
5,8
4,6
3,2
45-54 år
2
5,3
3,6
2,3
55-64 år
2,5
5,5
3,7
2,9
65-74 år
..
..
..
2,8
Erhvervsfrekvens
Alder i alt
71,3
67,4
68,2
71,4
15-24 år
69,2
58,2
60,4
63
25-34 år
87,8
83,6
81,4
85,1
35-44 år
90,8
89,6
87,9
88,6
45-54 år
89,1
87,3
87,8
89,7
55-64 år
57,5
62,2
70,8
75,1
65-74 år
11,3
12,9
13,9
17,6
Kilde: Danmarks Statistik, AKU111A
86
Økonomers køn og løn
En statistisk sammenligning af kvindelige og mandlige
cand. polit’ers lønfordelinger
Nadja Eifler, Rockwool Fondens Interventionsenhed
Henrik Hansen, Økonomisk Institut på Københavns Universitet
Resumé
Vi analyserer kønsforskelle i løn på tværs af hele lønfordelingen blandt nyuddannede
økonomer fra Københavns Universitet, som alle arbejder fuld tid. Vi finder, selv her,
betydelige lønforskelle. Forskellene kan ikke forklares af observerbare karakteristika,
så som karakterer, erhvervserfaring i studietiden, studietid, sektorvalg, ansættelse i
højtlønnede brancher, eller børn. I den offentlige sektor er den uforklarede lønforskel
mellem mænd og kvinder på næsten 7.000 kr. ved lønfordelingens 10. percentil, mens
den er 21.000 kr. ved lønfordelingens 90. percentil. Forskellene er dog kun marginalt
siknifikante. I den private sektor er den uforklarede lønforskel statistisk signifikant på
tværs af hele fordelingen, og på 17.000 kr. ved 10. percentil, mens den er 86.000 kr. ved
90. percentil. Forskelle i jobfunktioner eller familierelaterede forskelle kan muligvis
forklare en del af kønseffekten, men sådanne forskelle kan ikke forklare, hvorfor en
gruppe unge mænd og kvinder, der har taget de samme lange uddannelsesvalg, pludse-
lig begynder at divergere i deres valg umiddelbart efter de forlader deres studie.
1. Indledning
Mænd og kvinder i Danmark får forskellig løn. De politiske og videnskabelige debatter
fokuserer på, i hvilket omfang lønforskellene kan tilskrives de valg, mænd og kvinder
træffer i deres studieliv, familieliv og arbejdsliv. Hvis lønforskellene skyldes forskellige
valg, er der ikke et egentligt ligelønsproblem, da ligeløn principielt betyder lige løn for
lige arbejde. Lønforskelle, der derimod ikke er et resultat af frivillige valg, udgør et
problem, idet de repræsenterer en systematisk forskelsbehandling på arbejdsmarkedet,
som kan tilskrives individernes køn. Derfor opdeler økonomer traditionelt lønforskellen
i to; en forklaret og en uforklaret del (se Blau & Kahn, 2017; Kunze, 2017 eller Larsen
mfl., 2020). I denne artikel benævner vi de to dele hhv. ”karakteristika” og ”kønseffek-
ten”. Karakteristika henføres til forskelle i uddannelse, jobfunktioner, erhvervserfaring,
sektor- og branchevalg samt, i stigende omfang, familiens arbejdsdeling. Disse obser-
verbare forskelle, som kan påvirke individuelle lønninger, tager man højde for i økono-
metriske analyser. Den forskel der måtte være tilbage i gennemsnitslønningerne for
mænd og kvinder efter der er taget højde for de observerbare forskelle, kønseffekten,
har traditionelt været tolket som et udtryk for en systematisk forskelsbehandling på ar-
bejdsmarkedet.
87
Nyere danske studier af lønforskellen mellem mænd og kvinder bruger registerdata fra
Danmarks Statistik, og de baserer sig typisk på mange personer, fx 1.848.200 lønmod-
tagere i Larsen et al. (2020). I Eifler & Hansen (2024) går vi den modsatte vej, idet vi
alene ser på dimittender fra økonomiuddannelsen på Københavns Universitet (cand. po-
lit’er). Vi estimerer karakteristika og kønseffekter i gennemsnitslønningerne for
cand.polit’er, der dimitterede i perioden 1994-2013. Vi opdeler denne gruppe efter deres
ansættelse i enten den offentlige eller den private sektor, og vi tager via regressioner
højde for forskelle i deres evner og kundskaber i det omfang det afspejles i deres karak-
tergennemsnit på polit-uddannelsen, og deres opnåede erhvervserfaring i studietiden, og
vi medtager oplysninger om, hvorvidt de har børn. Vi sammenligner dermed lønninger
for en lille gruppe mænd og kvinder, som har meget ens karakteristika. Sammenlignin-
gen viser, at forskellen i gennemsnitslønningerne to år efter dimissionen, som kan hen-
vises til observerbare forskelle i evner og personlige valg, er lille. Broderparten i løn-
forskellene er således kønseffekten. Denne forskel er betydelig, både i den offentlige
sektor (ca. 16.000 kr. om året) og i den private sektor (ca. 40.000 kr. om året).
Nærværende artikel bygger videre på Eifler & Hansen (2024), idet vi udvider samplet,
og samtidig foretager en langt grundigere analyse, i det vi sammenligner lønfordelin-
gerne for kvinder og mænd. Analysen viser, at lønforskellene er markant stigende over
lønfordelingerne. For polit’er ansat i den offentlige sektor stiger lønforskellen fra godt
6.000 kr. i den lave ende af fordelingerne til ca. 30.000 i den høje ende. Der er dermed
tale om en stigende forskel i både absolut og relativ forstand. Samtidig kan vi ikke af-
vise, at hele lønforskellen i den offentlige sektor er en kønseffekt. I den private sektor
finder vi ligeledes stigende forskelle over lønfordelingerne, fra ca. 25.000 kr. i den nedre
ende til mere end 100.000 kr. i den høje del af fordelingen. Til forskel fra resultaterne i
Eifler & Hansen (2024) kan vi med det nye udvidede sample ikke længere afvise, at hele
lønforskellen i den private sektor er en kønseffekt, idet effekten af forskelle i karakteri-
stika kun er marginalt signifikant på et 10% signifikansniveau.
Artiklen er struktureret som følger. I næste afsnit viser vi, hvordan vi identificerer og
estimerer effekterne af forskelle i karakteristika samt kønseffekterne på tværs af lønfor-
delingerne. I afsnit 3 beskriver vi, hvordan vi har udvalgt vores sample af cand. polit’er
fra registrene i Danmarks Statistik. Vi har samlet alle empiriske resultater i afsnit 4, og
vi afslutter artiklen med et par kommentarer i afsnit 5.
2. Identifikation og estimation af kønseffekter
2.1. Lønfunktioner og lønfordelinger
Vi antager, at lønnen (Wi) for hver cand. polit er et resultat af observerbare og uobser-
verbare komponenter (Xi,İi), specificeret af lønfunktioner, gk(·,·), hvor indekset k, an-
giver personens køn med 0 for kvinder og 1 for mænd:

88
(,), 1, , 0,1.
H
,
ik k ik ik k
WgX i Nk
(1)
I langt de fleste analyser af individuelle lønninger, antages den betingede middelværdi
af lønfunktionen at være log-lineær, og de oftest inkluderede observerbare komponenter
er uddannelse og erfaring (se fx, Blau & Kahn, 2017, eller Larsen mfl., 2020). I denne
analyse vælger vi en lineær approksimation, idet vi har individer med samme uddannelse
og meget ens erfaring. Samtidig ser vi på hele lønfordelingen og ikke alene den betin-
gede middelværdi.
Den væsentlige antagelse for analysen er, at vi betragter løn (W), karakteristika (X) og
køn (K) som stokastiske variable med en simultan fordeling, hvorfra vi kan udlede mar-
ginale og betingede fordelinger. De tre centrale fordelinger er hhv. de to, hvor vi har
observationer: (i) Lønfordelingen for kvinder, F00 = F(W0|K= 0), (ii) lønfordelingen
for mænd, F11 = F(W1|K= 1), samt (iii) den uobserverbare kontrafaktiske lønfordeling,
vi ville have observeret for kvinder, hvis de observerede karakteristika havde været som
for mænd, F01 = F(W0|K= 1).
Den kontrafaktiske lønfordeling kan estimeres givet to antagelser. Den første betegnes
enten som ignorabilitet (Rosenbaum & Rubin, 1983), selektion på observerbare karak-
teristika (Heckman & Robb, 1985) eller betinget uafhængighed (Lechner, 1999). Grund-
læggende betyder antagelsen, at de uobserverede komponenter i lønfunktionerne (İ) gi-
vet de observerbare karakteristika (X) er uafhængige af køn (K). Den anden antagelse er
overlappende støtte, hvilket betyder at der ikke er nogen værdier af karakteristika (X),
som kun observeres for enten kvinder eller mænd. De to antagelser samles ofte i en
fælles antagelse om streng ignorabilitet (Rosenbaum & Rubin, 1983).
Antagelsen er tilstrækkelig for estimation af de tre fordelinger, F00, F11 og F01. Specifikt,
viser Firpo (2007), at vi kan bruge tre vægtfunktioner givet ved:
11(, ()) / ,kpx k p
Z
00
(, ()) (1 )/(1 ),kpx k p
Z
01
(, ()) (1 )/(1 ()) ()/ ,kpx k px px p
Z
u
hvor (p) er sandsynligheden for, at en person er en mand, mens (1 - p) er sandsynlighe-
den for, at vedkommende er en kvinde, og p(x) = P(K= 0 | X=x) er sandsynligheden
for, at personen kunne være en kvinde, givet de observerbare karakteristika (dvs. pro-
pensity scoren). De to første vægtfunktioner er velkendte, idet de bruges til at danne de
marginale lønfordelinger for hhv. mænd og kvinder, mens den tredje estimerer den kon-
trafaktiske fordeling under antagelsen om streng ignorabilitet. De tre fordelinger er givet
ved:
[]
() E[ (,()) ], , 0,1.
ab ab W w
Fw kpx ab
Z
d
1
(2)
I den empiriske analyse estimerer og sammenligner vi percentiler af de tre fordelinger.
Lad derfor forskellen i percentil 'Ȟ' mellem fordelingen for mænd og fordelingen for
kvinder være givet ved:

89
11 00
() ()
Q
QQ
' FF
(3)
Analogt til en Oaxaca-Blinder-dekomponering (Blinder, 1973; Oaxaca, 1973) af for-
skelle i gennemsnitslønningerne, opdeles forskellen i percentilerne i en kønseffekt og
karakteristika ved brug af den kontrafaktiske fordeling
11 01 01 00
[( ) ( )] [( ) ( )]
QQQ
QQ QQ
' ''
KX
FF FF
(4)
Firpo (2007) viser, at disse funktionaler af de tre fordelinger er identificeret givet streng
ignorabilitet og en antagelse om entydige percentiler. ǻȞXer forskellen i percentilerne,
som kan henføres til forskelle i de observerede karakteristika, mens kønseffekten (ǻȞK)
er forskellen i percentilerne, som skyldes forskellen i de to køns lønfordelinger. Dette
forbinder lønfunktionerne med opdelingen af percentilerne, fordi ens lønfunktioner for
de to køn medfører, at kønseffekten er nul.
2.2. Identifikation og estimation af kønseffekten med betydningsfunktioner
Firpo m.fl. (2009) foreslår en regressionsbaseret estimation af forskelle i visse funktio-
naler af fordelinger ved brug af re-centrerede betydningsfunktioner (engelsk: recentered
influence functions, RIF).1RIF’erne for percentiler kan gives som:
[()]
( , ) ( ) ( ) / ( ( )), , 0,1,
W
WWW W
d
ab
ab ab W q ab ab
HW q fq ab1
(5)
hvor qab(IJ) = inf{w | Fab(w)IJ} er den IJ-te percentil i fordelingen Fab, mens fab er tæt-
hedsfunktionen og 1[.] er indikatorfunktionen. For hver percentil er Hab(W,IJ) en stoka-
stisk variabel, og RIF-regressionerne er de betingede middelværdier givet ved:
E( ( , ) | ) ( , ), , 0,1
WW
{
ab ab
HW X x mx ab
(6)
RIF-regressionerne kan bruges til at estimere kønseffekterne i lønfordelingerne, fordi
betydningsfunktionerne i sig selv har middelværdi 0, så E[Hab(W, IJ)] = qab(IJ), og tårn-
egenskaben giver at:
11 01
E[ (,)| 1]E[ (,)| 1],
q
KmX K mX K
W
WW
'
01 00
E[ ( , ) | 1] E[ ( , ) | 0].
q
X
mX K mX K
W
WW
'
Hvis de betingede middelværdier approksimeres med lineære funktioner
(,) (), , 0,1,
WEW
c
ab ab
mx x ab
kan parametrene estimeres med almindelig regression:
1
00 0 0 0 00
()E[ |0]E[ (,)|0]
EW W
c
XX K XH W K
1 Betydningsfunktioner (Influence functions) defineres første gang i Hampel (1974). Funktionerne kvantificerer,
hvordan en given statistik ændres, når en lille mængde datamasse tilføjes til et bestemt punkt i fordelingen, den
givne statistik er baseret på. Man kan også tænke på betydningsfunktionen som en approksimation af betydningen
af en observation på en statistik beregnet ud fra et datasæt. Alle betydningsfunktioner har middelværdi nul. Re-
centreringen i Firpo m.fl. (2009) giver dermed betydningsfunktionen samme middelværdi som den oprindelige
statistik.
90
1
01 0 0 0 01
()E[ |1]E[ (,)|1]
EW W
c
XX K XH W K
1
11 1 1 1 11
()E[ |1]E[ (,)|1]
EW W
c
XX K XH W K
Som beskrevet i Firpo m.fl. (2018) leder dette til en opdeling af forskellen i percenti-
lerne, som er meget lig en Oaxaca-Blinder-dekomponering af forskellen i gennemsnit-
tene i en lineær regressionsmodel:
111011001
E[|1]'(() ())E[ |1]'()
W
EW EW EW
'
q
K
XK X XK
(7)
000000100
(E[ | 1] E[ | 0])' ( ) E[ | 1]'( ( ) ( ))
W
EW EW EW
'
q
X
XK XK XK
(8)
I (7) er det første led kønseffekten, mens det andet led er et fejlled, som skyldes den
potentielle forskel i de observerbare karakteristikas gennemsnit, når de vægtes med hen-
holdsvis Ȧ11 og Ȧ01. I (8) er første led effekten af forskelle i karakteristika, mens andet
led er en approksimationsfejl, der fremkommer, hvis der er forskelle i fordelingsfunkti-
onernes kurvatur.
Fordelen ved RIF-regressionsmetoden fremgår af (7) og (8). Med et givent løndatasæt
er ligningerne to Oaxaca-Blinder-dekomponeringer af funktioner af tre vægtede datasæt.
Kønseffekten i (7) er en sammenligning af de observerede lønninger for mænd med re-
vægtede løndata for kvinder, mens karakteristika-effekten i (8) er en sammenligning af
de re-vægtede lønninger med de observerede data for kvinderne.
3. Datagrundlag og -behandling
Danmarks Statistiks registerdata har oplysninger om 4.160 dimittender fra polit-studiet
i årene 1994-2017. Af disse medtager vi kun dimittender, som har både bachelor- og
kandidatuddannelsen fra polit-studiet, og vi udelader dimittender med meget korte og
meget lange indskrivninger, så alle dimittender har været på studiet i mindst 3 år og
højest 10 år. Blandt disse medtager vi alene dimittender, der er i fuldtidsbeskæftigelse i
det andet år efter deres dimission. Denne udvælgelse reducerer populationen til 2.915
dimittender, 2.003 mænd og 912 kvinder. Afgrænsningen afspejler at vi ønsker at be-
skrive de kønsmæssige lønforskelle blandt unge fuldtidsansatte dimittender, man almin-
deligvis vil karakterisere som typiske cand. polit’er.
Tabel 1 viser de gennemsnitlige årlige lønninger målt i faste 2015-priser, samt en række
karakteristika for de 2.915 dimittender fordelt på køn og sektor, hvor sektoren er givet
af dimittendernes ansættelsessted i deres andet år efter dimission. Lønindkomsten er
variablen LOENMV_13 fra Danmarks Statistiks register for personindkomst.
De velkendte lønforskelle mellem ansatte i den private og den offentlige sektor er mar-
kante. Samtidig ses betragtelige, og statistisk signifikante lønforskelle mellem mænd og
kvinder i begge sektorer. Da 65% af mændene er ansat i den private sektor i forhold til
42% af kvinderne, kan en del af den gennemsnitlige lønforskel mellem mandlige og
kvindelige dimittender på 59.000 kr. henføres til sektorvalg. Samtidig ses, at der inden

91
for sektorerne også er signifikante løngab: 18.000 kr. i den offentlige sektor og 53.000
kr. i den private sektor. I det følgende analyserer vi disse sektorspecifikke lønforskelle.
TABEL 1: KARAKTERISTIKA FOR CAND. POLIT’ER I FULDTIDSANSÆTTELSE ANDET
ÅR EFTER DIMISSION
Alle
Offentlig sektor
Privat sektor
Mænd
Kvinder
Mænd
Kvinder
Mænd
Kvinder
Lønindkomst (1.000 kr.)
491
432
416
398
532
479
Privatansatte
0,65
0,42
0,00
0,00
1,00
1,00
I finansiel sektor
0,29
0,18
0,06
0,05
0,42
0,37
I vidensservice
0,13
0,08
0,03
0,02
0,18
0,16
Karaktergennemsnit
8,11
7,86
7,91
7,81
8,21
7,74
Studiearbejde (årsværk)
2,44
2,15
2,25
2,13
2,54
2,18
Studietid (år)
7,07
6,98
7,33
7,09
6,94
6,83
Har børn
0,21
0,17
0,24
0,20
0,20
0,14
Forældre har LVU
0,28
0,26
0,26
0,26
0,30
0,26
Observationer
2.003
912
708
529
1.295
383
Note: Alle oplysninger er opgjort i andet år efter dimission. Lønindkomsten er opgjort i 2015-
priser.
Forældre har LVU er en indikator, som er lig 1,
hvis mindst én forældre har en lang
videregående uddannelse.
Kilde: Egne beregninger på baggrund af registerdata fra Danmarks Statistik.
Tabellen viser også, at mandlige og kvindelige dimittender ansat i den offentlige sektor
har meget ens karakteristika, i gennemsnit. Mændene har med et gennemsnit på 7,33 år
dog været på studiet lidt længere tid end kvinderne. Dette er den eneste statistisk signi-
fikante forskel i de to gruppers gennemsnitlige karakteristika—ud over lønforskellen.
I den private sektor er en større andel af mændene ansat i den finansielle sektor og kon-
sulentbranchen (vidensservice). Forskellene er dog ikke statistisk signifikante. Derimod
er mændenes karakterer signifikant højere end kvindernes, og de har haft betragteligt
mere erhvervsarbejde i studietiden. Endelig har en signifikant lavere andel af kvinderne
i den private sektor børn.
Tallene understreger, at selv når vi fokuserer på en meget specifik population, der meget
langt i deres livsforløb har foretaget de samme uddannelses- og sektorvalg, så er der
observerbare forskelle mellem mænd og kvinder, både i gennemsnitsløn og i visse ka-
rakteristika. I næste afsnit analyserer vi betydningen af disse observerbare forskelle for
de to gruppers lønfordelinger idet vi estimerer hhv. karakteristika og kønseffekter for de
centrale percentiler i fordelingerne.
4. Resultater
Tabel 2 viser parameterestimater for fire regressioner. De to første er for hhv. mænd og
kvinder ansat i den offentlige sektor mens de to sidste er for mænd og kvinder ansat i
den private sektor. Den afhængige variabel i alle fire regressioner er den årlige lønind-
komst, mens de forklarende variable er de karakteristika vi har vist i tabel 1 og

92
gennemgået ovenfor. De estimerede parametre er dermed ”afkastet” målt i kroner for
hver enhed af den angivne attribut. I regressionerne har vi udover de viste karakteristika
også inkluderet årsdummier for at tage højde for vækst- og konjunktureffekter i lønnin-
gerne. Vi har udeladt dummyen for 2015 og samtidig centreret karaktergennemsnittet
på 8, studiearbejdet på 2,5 årsværk, og studietiden på 5,5 år. Konstantleddet angiver
dermed lønindkomsten i 2015 for en polit med det angivne køn og sektor, som har været
på studiet i 5,5 år, arbejdet 2,5 årsværk i denne studietid og opnået et karaktergennemsnit
på 8. Denne dimittend er ikke ansat i hverken den finansielle sektor eller i vidensservice,
dimittenden har ingen børn, og er ikke selv barn af en akademiker.
Parameterestimaterne i Tabel 2 viser, at disse baseline polit’er tjener lidt over gennem-
snittet i den offentlige sektor, mens de tjener lidt under gennemsnittet i den private sek-
tor. Herudover ses det, at lønningerne i den finansielle sektor i det offentlige, som ventet
er markant og statistisk signifikant højere end i resten af den offentlige sektor, specielt
for de mandlige ansatte, mens ansatte i vidensservice i det offentlige ikke har højere
lønninger. I den private sektor er der i gennemsnit højere lønninger i både den finansielle
sektor og i vidensservice. Her er det de relativt få kvinder ansat inden for vidensservice,
som oppebærer høje lønninger, i gennemsnit.
TABEL 2: PARAMETERESTIMATER FOR LINEÆRE LØNFUNKTIONER OPDELT PÅ SEK-
TOR OG KØN
Offentlig sektor
Privat sektor
Mænd
Kvinder
Mænd
Kvinder
I finansiel sektor
82.445***
44.961***
42.546***
34.117**
(11.221)
(12.687)
(7.972)
(10.849)
I vidensservice
41.811
-19.013
36.242***
59.058**
(25.216)
(15.063)
(9.985)
(17.971)
Karaktergennemsnit
6.202***
7.805***
17.703***
11.641***
(1.727)
(1.590)
(2.011)
(3.081)
Studiearbejde (årsværk)
20.057***
14.808***
23.440***
29.316***
(2.485)
(2.608)
(3.220)
(4.762)
Studietid (år)
-7.910***
0.424
-5.095
-12.923*
(2.152)
(2.298)
(3.715)
(5.161)
Har børn
-8.521
-34.795***
-23.082*
-1.217
(6.664)
(6.310)
(9.052)
(12.340)
Forældre har LVU
-5.957
-5.938
4.099
7.730
(7.522)
(6.585)
(8.659)
(13.213)
Konstant
423.890***
404.678***
508.028***
471.732***
(13.637)
(10.871)
(17.590)
(20.806)
Årsdummier
Ja
Ja
Ja
Ja
Test af årsdummier
(0.005)
(0.001)
(0.042)
(0.101)
R2
0,276
0,279
0,165
0,269
Observationer
708
529
1.295
383
Note: Alle oplysninger er opgjort i andet år efter dimission. Lønindkomsten er opgjort i 2015-priser.
Karaktergennemsnittet er centreret ved 8,0; Studiearbejde er centeret ved 2,5 årsværk; studietiden er
centreret ved 5,5 år. Parameterestimater fra lineære regressioner. Robuste standardafvigelser i parentes.
*, **, *** angiver statistisk signifikans på hhv. 10%, 5% og 1%.
Kilde: Egne beregninger på baggrund af registerdata fra Danmarks Statistik.

93
For begge sektorer og begge køn er der positive afkast af karakterer og studiearbejde
mens studietiden og det at have børn ”straffes” i form af lavere lønninger, i gennemsnit.
Forholdet mellem karakterafkast og afkastet på studiearbejde varierer betragteligt på
tværs af sektor og køn. For mænd i den offentlige sektor kan ét karakterpoint substitue-
res med lige under fire måneders studiearbejde, mens substitutionsforholdet er godt ni
måneder i den private sektor. For kvinderne er der større ensartethed. Her er substituti-
onsforholdet lige under fem måneder i den private sektor og godt seks måneder i den
offentlige sektor.
Det er også interessant at se, at kvinder med børn i den offentlige sektor tjener ca. 35.000
kr. mindre om året i forhold til kvinder uden børn. Endelig ses det, at lønindkomsten for
dimittender, med akademikerforældre ikke er signifikant forskellig fra lønindkomsten
for dimittender med ikke-akademikerforældre. Vi udelader derfor denne attribut i de
følgende analyser.
Tabellerne 3 og 4 viser resultater af opdelingerne givet i ligning (7) og (8) for udvalgte
percentiler. Alle resultater er for pseudo-percentiler, genereret af vægtede gennemsnit.
Vægtningerne er foretaget for at sikre dimittendernes anonymitet. For percentil q(IJ) er
pseudo-percentilen beregnet ved
( ) 0.1 ( 0,02) 0.2 ( 0,01) 0.3 ( ) 0.2 ( 0,01) 0.1 ( 0,01)qq q qq q
WW W WW W
() 01
q
( ) 0.1
)
()
0.
1
01
01
0.1
Det er værd at bemærke, at der er betragtelige forskelle mellem top og bund i begge
lønfordelinger i begge sektorer. I relative termer er forskellene nogenlunde ens, idet løn-
ningerne omkring 90% percentilen er ca. 50% højere end lønningerne omkring 10%
percentilen for både mænd og kvinder i den offentlige sektor, samt for kvinderne i den
private sektor. For mændene i den private sektor er der en forskel på næsten 80% (godt
300.000 kr.) mellem top og bund. For den centrale IQR (0,25-0,75) varierer den relative
forskel mellem 23% (kvinder i den offentlige sektor) og 32% (mænd i den private sek-
tor).
Tabel 3 giver resultaterne for ansatte i den offentlige sektor. Lønforskellene mellem
mænd og kvinder er relativt beskedne og kun marginalt signifikante (10% niveau) i den
nedre ende af fordelingen. Forskellen er dog både markant—mere end 13.000 kr.—og
statistisk signifikant ved medianen. Herefter er den stigende til ca. 30.000 kr. i den øvre
ende af fordelingen. For alle percentiler finder vi, at effekten af forskelle i karakteristika
er små og insignifikante. Kønseffekten er således på 7.000 kr. ved 10. percentil, 21.000
kr. ved 90. percentil og 16.000 kr. ved gennemsnittet. Samtidig er de to fejlkilder, ba-
lancefejlen, givet i (7) og approksimationsfejlen i (8) små og insignifikante. Vi kan så-
ledes ikke afvise, at hele lønforskellen mellem mænd og kvinder i den offentlige sektor
kan tilskrives kønseffekten.
I den detaljerede opdeling af kønseffekten på delelementerne i den nederste del af tabel
3 ses det at mænd ”straffes” for lange studietider, mens kvinder har en ”børnestraf”, som
det også fremgår af regressionerne i tabel 2. En børnestraf på ca. 10.000 kr. ved medi-
anlønnen, dvs. ca. 2,5% af årslønnen, er betragtelig for ansatte i den offentlige sektor.

94
TABEL 3:OPDELING AF UDVALGTE PERCENTILER I LØNFORDELINGERNE FOR MÆND
OG KVINDER I DEN OFFENTLIGE SEKTOR
q(0,10)
q(0,25)
q(0,50)
q(0,75)
q(0,90)
Gns.
Løn, mænd
336.587
356.239
394.251
458.000
523.596
415.830
(2.213)
(2.566)
(3.562)
(5.302)
(7.258)
(3.063)
Løn, kvinder
330.122
346.895
381.010
428.382
492.937
397.825
(2.402)
(2.802)
(3.322)
(5.435)
(7.623)
(3.112)
Løn, kvinder, revægtet,
329.656
346.721
382.408
433.306
502.205
399.342
(2.654)
(3.050)
(3.602)
(6.209)
(8.557)
(3.196)
Lønforskel
6.465*
9.344*
13.241**
29.618***
30.659**
18.005***
(3.266)
(3.800)
(4.871)
(7.593)
(10.526)
(4.366)
Karakteristika
-0.128
0.128
1.106
2.503
7.093
1.464
(1.596)
(1.989)
(2.467)
(4.163)
(5.553)
(2.561)
Kønseffekt
6.795*
9.198*
11.545*
24.104***
21.412*
16.254***
(3.339)
(3.726)
(4.703)
(7.313)
(10.432)
(3.842)
Balancefejl
-0.338
-0.302
0.292
2.421
2.175
0.054
(3.466)
(3.919)
(4.519)
(7.386)
(11.107)
(3.774)
Approksimationsfejl
0.136
0.320
0.298
0.590
-0.022
0.234
(1.276)
(1.606)
(2.061)
(3.985)
(4.776)
(2.295)
Karakteristika:
I finansiel sektor
0.083
0.134
0.577
1.373
1.580
0.643
(0.111)
(0.174)
(0.576)
(1.382)
(1.753)
(0.649)
I vidensservice
-0.059
-0.107
-0.501
-0.255
-0.550
-0.255
(0.195)
(0.309)
(0.452)
(0.467)
(0.721)
(0.276)
Karaktergennemsnit
0.092
0.117
0.271
0.630
0.866
0.322
(0.259)
(0.324)
(0.740)
(1.725)
(2.362)
(0.876)
Studiearbejde (årsværk)
0.772
0.977
1.178
2.270
3.370
1.780
(0.567)
(0.702)
(0.836)
(1.595)
(2.383)
(1.221)
Studietid (år)
0.431
-0.247
0.342
0.495
2.607
0.158
(0.666)
(0.713)
(0.761)
(1.156)
(1.858)
(0.658)
Har børn
-0.908
-0.884
-1.396
-1.925
-1.709
-1.318
(0.676)
(0.662)
(0.975)
(1.349)
(1.282)
(0.914)
Kønseffekt:
I finansiel sektor
0.573
1.100
1.291
3.074
0.775
1.578
(0.395)
(0.564)
(0.736)
(1.900)
(4.528)
(0.956)
I vidensservice
0.866
0.399
1.301
1.590
4.981*
1.998
(0.730)
(0.906)
(1.010)
(1.354)
(2.190)
(1.051)
Karaktergennemsnit
0.032
0.011
-0.106
0.301
1.379
0.187
(0.194)
(0.195)
(0.268)
(0.504)
(1.317)
(0.263)
Studiearbejde (årsværk)
-0.094
-1.032
-1.281
-1.225
-3.008
-1.381
(0.659)
(0.806)
(0.953)
(1.452)
(2.485)
(0.909)
Studietid (år)
-7.212
-6.843
-17.155*
-26.074*
-46.621**
-14.579*
(5.683)
(6.216)
(7.228)
(10.465)
(15.068)
(5.673)
Har børn
5.536*
5.675*
9.383***
9.971**
4.637
6.267**
(2.189)
(2.379)
(2.742)
(3.827)
(5.602)
(2.229)
Konstant
-1.009
9.897
18.053
55.629
85.645
19.090
(16.092)
(18.465)
(21.345)
(31.655)
(49.747)
(17.320)
Mænd
708
708
708
708
708
708
Kvinder
529
529
529
529
529
529
Note: Alle oplysninger er opgjort i andet år efter dimission. Lønindkomsten er opgjort i 2015-priser.
Karaktergennemsnittet er centreret ved 8,0; Studiearbejde er centeret ved 2,5 årsværk; studietiden er
centreret ved 5,5 år. Robuste standardafvigelser i parentes. *, **, *** angiver statistisk signifikans på
hhv. 10%, 5% og 1%.
Kilde: Egne beregninger på baggrund af registerdata fra Danmarks Statistik.
95
TABEL 4:OPDELING AF UDVALGTE PERCENTILER I LØNFORDELINGERNE FOR MÆND
OG KVINDER I DEN PRIVATE SEKTOR
q(0,10)
q(0,25)
q(0,50)
q(0,75)
q(0,90)
Gns.
Løn, mænd
399.047
441.530
497.625
582.064
711.792
531.905
(3.239)
(3.031)
(3.521)
(6.026)
(13.067)
(3.959)
Løn, kvinder
374.103
412.835
458.505
517.007
591.334
479.196
(5.177)
(5.157)
(5.168)
(7.214)
(12.928)
(5.798)
Løn, kvinder, revægtet,
380.082
423.201
465.209
525.424
621.238
491.321
(5.372)
(5.286)
(5.773)
(8.004)
(23.469)
(6.830)
Lønforskel
24.945***
28.695***
39.119***
65.057***
120.459***
52.709***
(6.107)
(5.982)
(6.253)
(9.400)
(18.382)
(7.021)
Karakteristika
7.584*
9.712*
7.297
10.369
16.876
11.906*
(3.677)
(3.867)
(3.867)
(5.415)
(9.415)
(4.756)
Kønseffekt
17.642**
16.894**
31.291***
55.508***
85.877***
38.955***
(5.887)
(5.741)
(6.444)
(9.362)
(25.358)
(7.185)
Balancefejl
-1.605
0.655
-0.594
-1.953
13.028
0.218
(6.878)
(6.942)
(7.479)
(10.172)
(25.800)
(8.394)
Approksimationsfejl
1.324
1.435
1.125
1.132
4.677
1.630
(2.200)
(2.410)
(2.655)
(4.207)
(12.769)
(3.863)
Karakteristika:
I finansiel sektor
0.875
0.995
0.722
1.202
1.023
0.950
(1.147)
(1.293)
(0.962)
(1.569)
(1.475)
(1.236)
I vidensservice
0.671
0.827
1.000
1.431
2.565
1.349
(0.845)
(1.034)
(1.240)
(1.786)
(3.243)
(1.660)
Karaktergennemsnit
1.282
1.852
0.874
2.050
4.400
2.791
(1.031)
(1.321)
(0.841)
(1.562)
(3.151)
(1.902)
Studiearbejde (årsværk)
5.098*
6.545**
7.429**
11.491**
15.585*
9.860**
(2.041)
(2.326)
(2.500)
(3.827)
(6.341)
(3.298)
Studietid (år)
-0.885
-0.194
-0.854
-2.236
-3.365
-1.627
(0.896)
(0.559)
(0.855)
(1.825)
(2.961)
(1.365)
Har børn
-0.082
-0.234
-0.331
-0.896
2.067
-0.118
(1.223)
(1.174)
(1.078)
(1.151)
(2.283)
(0.850)
Kønseffekt:
I finansiel sektor
0.188
-5.585
-0.171
-4.137
24.143
2.753
(5.827)
(5.478)
(5.978)
(8.428)
(21.021)
(6.309)
I vidensservice
-3.794
-3.190
-3.277
-2.933
-19.595
-5.436
(2.693)
(2.793)
(3.187)
(4.923)
(13.784)
(3.772)
Karaktergennemsnit
1.061
0.672
2.172*
3.604*
1.246
1.187
(0.798)
(0.677)
(0.970)
(1.457)
(2.798)
(0.959)
Studiearbejde (årsværk)
0.168
0.214
0.007
-0.255
-2.080
-0.317
(0.274)
(0.285)
(0.194)
(0.402)
(2.692)
(0.421)
Studietid (år)
-5.060
-14.481
-2.083
19.658
76.022*
13.296
(8.713)
(7.479)
(8.525)
(12.272)
(32.764)
(10.152)
Har børn
-2.109
-0.066
-1.375
-3.127
-26.712*
-3.369
(3.771)
(3.975)
(3.860)
(4.362)
(12.971)
(3.536)
Konstant
54.286*
65.681*
51.201
-12.567
-41.856
38.637
(25.660)
(26.086)
(30.385)
(41.952)
(110.011)
(28.887)
Mænd
1295
1295
1295
1295
1295
1295
Kvinder
383
383
383
383
383
383
Note: Alle oplysninger er opgjort i andet år efter dimission. Lønindkomsten er opgjort i 2015-priser.
Karaktergennemsnittet er centreret ved 8,0; Studiearbejde er centeret ved 2,5 årsværk; studietiden er
centreret ved 5,5 år. Robuste standardafvigelser i parentes. *, **, *** angiver statistisk signifikans på
hhv. 10%, 5% og 1%.
Kilde: Egne beregninger på baggrund af registerdata fra Danmarks Statistik.

96
Lønforskellene i den private sektor er både markante og signifikante på tværs af percen-
tilerne, som det fremgår af tabel 4. Samlet set kan lønforskellen ikke henføres til for-
skelle i karakteristika, men det er værd at bemærke at den detaljerede opdeling af karak-
teristika viser, at mænd aflønnes for deres betydeligt længere studiearbejde, og forskel-
len er størst i de øvre percentiler. Kønseffekten er stor—ca. 17.000 kr. —i bunden af
fordelingen, og stigende til mere end 85.000 kr. i toppen af fordelingen. Den gennem-
snitlige kønsforskel er estimeret til ca. 40.000 kr. i overensstemmelse med resultatet i
Eifler & Hansen (2024). Til sammenligning med den offentlige sektor, kan vi ikke gen-
finde en børnestraf i den private sektor. Der er derimod tegn på en børnebelønning til
kvinderne. Gevinsten skal ses i lyset af at både kvinder og mænd i samplet arbejder fuld
tid.
Figur 1 viser den samlede lønforskel og de rene karakteristika og kønseffekter for alle
percentiler fra 5% til 95%. Figuren viser udglattede estimater (glidende gennemsnit) for
at sikre anonymitet. Den stigende lønforskel over lønfordelingerne, som fremgår af ta-
bellerne, er tydelig. Samtidig ses, at effekterne af forskelle i karakteristika overalt er
små, så kønseffekten er den dominerende forskel på tværs af fordelingerne i begge sek-
torer.
5. Afslutning
Økonomer har længe beskæftiget sig med ligeløn mellem mænd og kvinder, typisk ved
at opdele den observerede lønforskel i to; en forklaret og en uforklaret del. I teorien bør
den forklarede lønforskel fange resultatet af alle karakteristika og frivillige valg, mens
den resterende, og uforklarede lønforskel, fanger en systematisk forskelsbehandling på
arbejdsmarkedet, som kan tilskrives individernes køn. I praksis har det været vanskeli-
gere at opnå enighed om, hvorvidt den uforklarede lønforskel også rent faktisk skyldes
FIGUR 1: ESTIMEREDE LØNFORSKELLE SAMT RENE KARAKTERISTIKA OG KØNS-
EFFEKTER OVER
5-95 PERCENTILERNE
97
diskrimination. Et ofte hørt argument imod, at kalde den uforklarede lønforskel for dis-
krimination, er at der ikke er kontrolleret for alle forskelle i karakteristika. I vores ana-
lyse, kunne man for eksempel anføre, at forskelle i jobfunktioner eller familierelaterede
forskelle kan forklare mere af lønforskellen end vi gør her. Omvendt kan metoden også
kritiseres for at henføre for meget af den forklarede lønforskel til forskelle i valg, hvor
det her er underforstået at valg er frivillige. Hvis kvinder for eksempel fravælger den
private sektor fordi de antager, eller ved, at det vil være (for) svært at kombinere børn
og karriere, kan frivilligheden i dette valg formentligt føles begrænset for de berørte
kvinder og familier. Som økonomer vil vi sige, at kvinderne, og familierne, optimerer
under nogle bi-betingelser, og at dette er uproblematisk. Denne økonomfaglige tilgang
hjælper os dog ikke til at mindske hverken lønforskelle mellem mænd og kvinder, eller
den ulige konsekvens af at få børn, som kvinder rammes af.
I den offentlige debat er interessen for lønforskelle mellem mænd og kvinder, og deres
underliggende årsager, også stor. Det ses blandt andet ved, at en række danske fagfor-
eninger siden 2010 har ført en kampagne om ”Kvindernes Sidste Arbejdsdag”. Kam-
pagnen, som blandt andet støttes af økonomernes fagforening, DJØF, møder hvert år
kritik for at sprede myter og misinformation fordi den ikke i tilstrækkelig grad forklarer
og fortæller om, hvorfor mænd i gennemsnit tjener mere end kvinder på det danske ar-
bejdsmarked. Diskussionen handler grundlæggende om, i hvilken grad lønforskellene
kan henføres til mænd og kvinders forskellige valg i studielivet, familielivet og arbejds-
livet relativt til ”uforklarlige” forskelle i lønningerne.
I denne artikel har vi forsøgt at kortslutte nogle af de gængse kilder til argumentationer
omkring, at uforklarede lønforskelle må skyldes karakteristika der er iboende i hhv.
mænd og kvinder. Det har vi gjort ved at analysere lønforskellene for en lille gruppe
personer, som har foretaget mange ens valg i studie- og arbejdslivet. Vi har således en
god forståelse for, hvem de mænd og kvinder, som vi sammenligner, er. Disse personer
har for eksempel udvist samme interesse og evner for matematik i deres gymnasietid,
og de har oplevet den samme socialisering, som polit-uddannelsen på Københavns Uni-
versitet måtte udsætte sine studerende for. Vi betinger desuden vores analyse til, at alle
økonomerne er i fuldtidsarbejde kort tid efter deres dimission. Samtidig opdeler vi øko-
nomerne efter deres ansættelse i enten den offentlige eller den private sektor, og vi tager
via regressioner højde for forskelle i deres evner og kundskaber i det omfang det afspej-
les i deres karaktergennemsnit på polit-uddannelsen, og deres opnåede erhvervserfaring
i studietiden. Vi sammenligner dermed lønninger for en lille gruppe mænd og kvinder,
som har meget ens karakteristika, bort set fra deres køn.
For at dykke lidt dybere end de ofte sete gennemsnitlige lønforskelle, ser vi på lønfor-
skelle langs hele lønfordelingen for hhv. mænd og kvinder i hhv. den private og den
offentlige sektor. Analysen viser, at lønforskellene inden for hver sektor to år efter di-
mission, som kan henvises til observerbare forskelle i personlige valg og evner, er meget
lille—som forventet, idet vi analyserer en homogen gruppe. Størsteparten i lønforskel-
lene er således kønseffekten.
98
I den offentlige sektor er den uforklarede lønforskel mellem mænd og kvinder i gen-
nemsnit 16.000 kr. og statistisk signifikant. Ser vi på tværs af lønfordelingen, er den
uforklarede lønforskel ved lønfordelingens 10. percentil 7.000 kr., mens forskellen er
21.000 kr. ved lønfordelingens 90. percentil. Både i toppen og bunden af lønfordelingen
er forskellene kun marginalt signifikante. I den private sektor er den uforklarede lønfor-
skel statistisk signifikant på tværs af hele fordelingen. Den uforklarede lønforskel er her
39.000 kr. i gennemsnit. Ved lønfordelingens 10. percentil er forskellen 17.000 kr. i den
private sektor, mens den er 86.000 kr. ved lønfordelingens 90. percentil.
Forskellige i jobfunktioner eller familierelaterede forskelle kan, som nævnt, muligvis
forklare en del af kønseffekten. Men det efterlader spørgsmålet hvorfor mandlige og
kvindelige økonomer, som har foretaget så mange ens valg i deres formative år, begyn-
der at divergere i deres valg kort tid efter dimissionen?
Referencer
Blau, F. D., & Kahn, L. M. (2017). The Gender Wage Gap: Extent, Trends, and Expla-
nations. Journal of Economic Literature,55(3), 789–865.
Blinder, A. S. (1973). Wage Discrimination: Reduced Form and Structural Estimates.
The Journal of Human Resources,8(4), 436–455.
Eifler, N., & Hansen, H. (2024). Lige løn for lige uddannelse? Cand.polit’ers køn og
løn. Samfundsøkonomen,3, 14–23.
Firpo, S. (2007). Efficient semiparametric estimation of quantile treatment effects.
Econometrica,75(1), 259–276.
Firpo, S., Fortin, N., & Lemieux, T. (2018). Decomposing Wage Distributions Using
Recentered Influence Function Regressions. Econometrics,6(2), 28.
Firpo, S., Fortin, N. M., & Lemieux, T. (2009). Unconditional Quantile Regressions.
Econometrica,77(3), 953–973.
Hampel, F. R. (1974). The Influence Curve and Its Role in Robust Estimation. Journal
of the American Statistical Association,69(346), 383–393.
Heckman, J. J., & Robb, R. (1985). Alternative methods for evaluating the impact of
interventions: An overview. Journal of Econometrics,30(1), 239–267.
Kunze, A. (2017). The gender wage gap in developed countries. In The Oxford Hand-
book of Women and the Economy (pp. 369–394). Oxford University Press.
Larsen, M., Verner, M. & Mikkelsen, C.H. (2020). Den uforklarede del af forskellen
mellem kvinders og mænds timeløn. VIVE.
Lechner, M. (1999). Earnings and Employment Effects of Continuous Off-the-Job
Training in East Germany after Unification. Journal of Business & Economic
Statistics, 17(1), 74–90.
Oaxaca, R. (1973). Male-Female Wage Differentials in Urban Labor Markets. Interna-
tional Economic Review,14(3), 693–709.
Rosenbaum, P. R., & Rubin, D. B. (1983). The central role of the propensity score in
observational studies for causal effects. Biometrika,70(1), 41–55.

99
Definering af buskundepotentiale ved spatiel regression af
socioøkonomiske data og passagerforhold på Fyn
Thorbjørn Revsbech Sørensen1, Diana Andreea Vasile2, Patrycja Anna Zieba3, Flemming Albæk4 og
Seher Øzden5
1FynBus, Plan, ths@fynbus.dk, 2FynBus, Plan, dva@fynbus.dk, 3FynBus, Marked, paz@fynbus.dk,
4FynBus, Økonomi og Analyse, fal@fynbus.dk og 5FynBus, Økonomi og Analyse, soz@fynbus.dk
Baggrund
Siden 2015 har FynBus benyttet en model der beskriver potentielle kunder på Fyn. Modellen er
sammensat af socioøkonomiske data, og adfærdsdata som er definerede af forskellige registre og
omdannet til et datasæt som hedder ConZoomTM. Conzoom er et segmenteringsværktøj udviklet af
Geomatic som klassificerer befolkningen i Conzoom-grupper og Conzoom-typer, så de hver især udgør
så ensartede dele af den danske befolkning. Modellen kaldes i FynBus regi for Buskundepotentiale
(BKP).
I 2023 valgte Geomatic at opdatere grundlaget for ConZoomTM, og har i den forbindelse opdateret og
tilføjet grupper og typer, som ikke eksisterer i den nuværende model. Der er derfor behov for en
revidering af buskundepotentiale-modellen, især med henblik på de seneste opdateringer fra generation
5 til 6, som indeholder væsentlige ændringer, samt revurdering af passagerdata på baggrund af eksterne
påvirkninger som f.eks. Corona-krisen. Dette medfølger at FynBus skal redefinere buskundeværdi
(BKV) fra modellen fremadrettet med afsæt i generation 6 af ConZoomTM og FynBus’ passagerdata post
Covid-19.
BKP kortlægger potentielle buskunder med udgangspunkt i ConZoomTM, demografiske data og faglige
vurderinger. BKP definerer det samlede potentiale af buskunder, såfremt de ville have adgang til den
bedst mulige rejse til deres individuelle behov. Det er altså ikke en model som estimerer et passagertal,
men estimerer potentiale ud fra bedste forudsætninger for individets rejse.
Databeskrivelse
Conzoom data1, skabes af Geomatic og er et statistisk overblik over persontyper og grupper, som kan
benyttes ved analyse, der involverer adfærd, målgruppearbejde, analyser som involverer
socioøkonomiske elementer osv. Dataene skabes ud fra registre og sammensættes til typer og grupper.
Der er i alt 9 grupper og 39 typer fordelt på disse grupper, som giver indsigt i adfærden i et spatielt
afgrænset område. Conzoom datasættet repræsenterer, hvordan den danske befolkning så ud pr. 01-01-
2023 og placerer husstandene i 100x100 kvadratmeters celler.
Hver type og gruppe er associeret med mange variabler, som er aggregeret på decilniveau eller er af
typen boolean(sandt/falsk/dummy). Disse dækker eks. over boligtype, civilstand, bilejerskab,
familiestørrelse, økonomi, fritidsbeskæftigelser, uddannelsesniveau m.m. Der er indlagt et eksempel på
en gruppe og en type i Bilag 1. ellers kan oversigtens findes på ConZooms hjemmeside.
1 hƩps://www.conzoom.dk/da/danmark/segmenter

100
Det færdige datasæt projekteres på kort og ser ud som følgende:
De relevante variabler fra Conzoom datasættet er udvalgt og sammensat med data fra FynBus’
stoppesteder. Her benyttes Rejsekort data, hvor stoppestedernes geografiske koordinater er placeret

101
indenfor cellernes afgræsninger. For stoppesteder uden påstigere registreret via Rejsekort, er Conzoom-
data koblet med PTS-data (Passager Tælle System), som er baseret på realtidstællinger foretaget af
kameraer i busserne. Dette er for at dække evt. mangler som følge af rejsekortprodukter som ikke kræver
check-ind/ud og giver et mere repræsentativt datasæt. Det anvendte påstigningsdata er på stoppesteds-
og månedsniveau for 2023. Datasættet er ikke afgrænset til kun at indeholde busstoppesteder, men består
dermed af data for alle stoppesteder, dvs. letbane- og togstationer er også inkluderet, såfremt der har
været nogen registrerede påstigninger i 2023.
Formålet med dette datasæt er at anvende det i en regressionsanalyse for at generere nye BKV’er. Disse
værdier indgår i beregningsformlen for BKP og bruges til at kvantificere hver enkelt Conzoom-gruppe
behov for og/eller villighed til at benytte kollektiv trafik. Med andre ord estimerer BKV sandsynligheden
for, at hver Conzoom-gruppe rejser med kollektiv transport. For at opnå de mest præcise værdier er alle
relevante variabler, der forventes at påvirke brugen af kollektiv trafik, inkluderet i analysen.
Metode
BKP defineres ud fra følgende formel:
Buskundepotentiale = ܨݎܽܲݐ݁݊ݐ݈݅ܽ݁ + ݈ܶ݅ ܲݐ݁݊ݐ݈݅ܽ݁
(1)
Fra Potentiale = (ܰܽݐܾ݂݈݁݇݊݅݊݃௧௦)ή(ܤݑݏܸæݎ݀݅ ܨݕ݊ܤݑݏ) / 100
(2)
Til Potentiale = (ܦܾ݂݈ܽ݃݁݇݊݅݊݃௦௧ௗ ή0,2) + (ܦܾ݂݈ܽ݃݁݇݊݅݊݃ௗௗ௦ை௩ଵହ ή0,52)
(3)
Natbefolkning og dagbefolkning er defineret af Geomatic på baggrund af statistiske registre, og
busværdien er fastsat baseret på gruppen og typernes forbrugsadfærd, som er udarbejdet af Geomatic,
Movia og FynBus.
FynBus har valgt at benytte spatiel regression til at forsøge at definere en ny BKV, da teknologien tillader
muligheden for langt mere detaljerede passagertal i forhold til 2015. Dette skaber grundlaget for en
bedre og mere nøjagtig model.
Arbejdet med ConZoomTM data og stoppesteds-/passagerdata kræver at der tages højde for den spatielle
dimension. Passagertallene tager udgangspunkt i historiske data fra 2023, hvor der er benyttet data fra
rejsekortet, passagertælleudstyr i busserne og data fra FynBus egne salgskanaler Den tværfaglige
gruppe, bestående af repræsentanter fra Markeds-, Planlægnings- og Data-/Analyseafdelingerne, har
udvalgt ConZoom™-decilvariabler, der vurderes relevante for adfærd, som påvirker villigheden til at
benytte kollektiv trafik.
De udvalgte decilvariabler blev analyseret i en indledende undersøgelse, hvor korrelationerne mellem
variablerne blev afdækket til brug i den endelige model. Resultaterne blev samlet i en Spearman-
korrelationsmatrice for at identificere og ekskludere variabler med høj indbyrdes korrelation.
Der er ingen signifikante outliers, hvilket vil sige, at regressionsmodellerne er kørt på det komplette
datasæt. Dog er datasættet afgrænset til kun at bestå af de celler, hvor der har været påstigere/pts-
aktivitet, resten er sorteret fra. Resultatet er som følger:

102
Figur 1: Forkortelser i korrelationsmatricen. ald: aldersdecil, husi: husstandsindkomstdecil, bil:
bilrådighedsdecil, besk: beskæftigelsesdecil, ud: uddannelsesdecil, soc: socialklassedecil, fam: familietypedecil,
bol: boligtypefaktor, civ: civilstandsdecil, herk: herkomstfaktor, darb: dagbefolkning i arbejde, dgud:
dagbefolkning i uddannelse, uu15: uddannelse under 15, uo15: uddannelse over 15.
Ud fra ovenstående matrice er decilvariablerne alder, husstandsindkomst, bilrådighed, beskæftigelse,
uddannelse, socialklasse, familietype, boligtype, herkomst og civilstand anvendt i regressionsmodellen.
Efterfølgende har regressionskoefficienterne for familietypedecil, herkomst og boligtype vist sig ikke at
være signifikante, hvorfor de er blevet taget ud i den endelige model.
Derfor er der undersøgt følgende tre modeller til at udføre spatiel regression på BKV, da disse modeller
ofte ses benyttelse til lignede spatielle analyser.
Spatiel Lag Model (SLM), der også kendes som Spatial Autoregressiv Model er kendetegnet ved at den
afhængige variable er påvirket af nærliggende celler.
ݕ=ߩܹݕ+ܺߚ +ߝ
(4)
hvor y er den afhængige variabel, ߩ måler graden af spatiel afhængighed, W er den spatielle vægtmatrice,
X er de uafhængige variabler, ߚ er koefficienterne og ߝ er fejlledet.
Spatiel Error Model (SEM) er kendetegnet ved at der tages højde for korrelationer i fejlleddet, der kan
være til stede på grund af udeladte variabler.
ݕ=ܺߚ +ݑ, ߤ=ߣܹݑ +ߝ
(5)
hvor y er den afhængige variabel, X er den uafhængige variabel, , ߚ er koefficienterne, ߣ er det spatielle
fejlled, som repræsenterer graden af den spatielle korrelation i fejlledende, W er den spatielle
vægtmatrice med forholdet mellem cellerne og u er en vægtmatrice af uafhængige fejlled.
Spatiel Durbin Model (SDM) er en udvidet model af SLM, hvor både den afhængige og de
uafhængige variabler er påvirket af de nærliggende celler.
ݕ=ߩܹݕ+ܺߚ +ܹܺߠ +ߝ
(6)
hvor y er den afhængige variabel, X er den uafhængige variabel, ߚ er koefficienterne, ߠ er
koefficienterne for de spatielle lags af de uafhængige variabler, W er den spatielle vægtmatrice med
forholdet mellem cellerne og ߝ er fejlledet (Anselin, 1988).

103
For at udføre en spatiel regression skal der i modellen defineres afgrænsning i form a nabolag, der
spatielle regression modeller som udgangspunkt en af tre typer af nabolag. Disse, baseret på skakbrikker,
er kendt som ”Rook”, ”Bishop” og ”Queen”.
xRook: betragter kun naboer som er direkte horisontale eller vertikale ud fra cellens placering.
Rook nabolaget kan have op til 4 naboer.
xBishop: betragter kun naboer som ligger på de diagonale akser ud fra cellens placering. Bishop
nabolaget kan have op til 4 naboer.
xQueen: betragter naboer som ligger på både diagonale, vertikale og diagonale akser ud fra
cellens placering. Queen nabolaget kan have op til 8 naboer (Oyana, 2021).
Figur 2: Illustration af de tre forskellige nabotyper, der kan vælges mellem
Det vurderes at nabolaget Queen er bedst egnet til regression analysens formål, hvorfor der ikke laves
nogen modeller med Rook eller Bishop-nabolaget. Dog er der i ConZoomTM observationer som ikke har
nogen nabo, fx i kantområder eller isolerede områder. For at undgå at modellen ikke udelukker disse
celler er der i modellen specificeret at disse celler skal medtages. Dette giver et mere omfattende billede
af sammenhængen mellem påstigninger i bussen og socioøkonomiske faktorer i områder med få naboer.
Det besluttes at regressionsmodellen SEM benyttes, hvor nabolaget defineres som queen, idet der
vurderes det vil give de mest retvisende resultater, eftersom nabolaget queen inkluderer alle naboer
omkring en celle.
Den endelige model defineres derfor som følgende:
log(ܤݑݏܲåݏݐ݅݃݁ݎ݁)
=ߚ+ߚଵ݈ܽ݀݁ݎ+ߚଶܿ݅ݒ݈݅ݏݐܽ݊݀ +ߚଷܾ݈݅݃ݐݕ݁ +ߚସ݄ݑݏݏݐܽ݊݀ݏ݅݊݀݇݉ݏݐ
+ߚହܾ݈݅ݎå݄݀݅݃݁݀ +ߚܾ݁ݏ݇æ݂ݐ݈݅݃݁ݏ݁ +ߚݑ݈݀݀ܽ݊݁ݏ݁+ߚ଼ݏ݈݈ܿ݅ܽ݇ܽݏݏ݁
+ܥ݊ݖ݉݃ݎݑ݁ݎ +ߝ
(7)
Regressionskoefficienterne som skabes af denne model skal efterfølgende standardiseres til en værdi
der kan indgå i beregningen for BKP. Formlen for BKV er designet til at rumme værdier som er på hele
tal og på en skala fra 0 – 100. For at kunne indsætte vores nye værdier ind i den eksisterende formel, er
det besluttet at standardisere resultaterne så de tilpasses denne skala. Resultaterne fra
regressionsanalysen er derfor blevet omregnet til en vægt ved følgende formel:
ܸæ݃ݐ =݂݂݇݁݅ܿ݅݁݊ݐ െ݂݂݇݁ܿ݅݁݊ݐ
݂݂݇݁݅ܿ݅݁݊ݐ௫ െ݂݂݇݁ܿ݅݁݊ݐ ݂݂֞݇݁݅ܿ݅݁݊ݐ െ െ0,85
2,06 െെ0,85
(8)
Vægtene er efterfølgende ganget med 100 og afrundet til nærmeste hele tier, så de kan anvendes som
BKV i formlen ”Fra Potentiale”. I nedenstående tabel fremgår de beregnede BKV. Buskundeværdien
for Gruppe A. C og F er justeret på baggrund af tidligere model, og vurdering fra Markedsafdelingen.
Resultater
Analysen af den spatielle regression på buskundeværdi har resulteret i koefficienter som er vægtet for
at give os en heltalsværdi som der kan benyttes i den eksisterende formel for buskundepotentiale. Denne

104
nye værdi erstatter den forrige, hvor grundlaget for værdien er ukendt, hvilket fremgår af nedenstående
Tabel 1.
For at kunne sammenligne med den nye model som er dannet på baggrund af gruppeniveau med
buskundeværdierne fra den eksisterende model som er dannet på typeniveau fremgår middelværdien for
BKV for gruppen. Dette gøres for at vurderer om værdierne udskiller sig væsentligt fra den tidligere
model.
Gruppe kode
Gruppe navn
Koefficient
Vægt
Afrundet BKV
Middel af BKV i dag
A
Velfunderede husejere
-0,38
0,16
20
8
B
Komfort og hygge
0,24
0,38
40
16
C
Lever på landet
-0,85
0,00
5
5
D
Velhavere
0,08
0,32
30
10
E
Urban mangfoldighed
0,38
0,42
40
58
F
Vid og velstand
2,06
1,00
90
36
G
Seniorer
0,44
0,44
40
16
H
Unge på vej
0,38
0,42
40
80
I
Provinsliv
0,53
0,47
50
35
Tabel 1: Resultater for Spatiel Error Regression på ConZoomTM gruppeniveau. Kolonnen ”Middel af BKV i dag”
er den middelværdien af buskundeværdierne på gruppeniveau.
Da grundlaget er skiftet fra type til gruppe, er der selvfølgelig færre nuancer i buskundeværdien end der
var tidligere, hvilket middelværdien også giver udtryk for. Dog ved test af dataene er
Buskundepotentialet på det spatielle niveau tilsvarende til den eksisterende model. Derfor er det vurderet
at resultaterne er brugbare i det videre arbejde med buskundepotentiale hos FynBus.
Der vurderes undersøgt om rejsehjemmelfordelinger skal benyttes til at bestemme faktorerne der
anvendes i formlen Til-Potentiale (3). Der er dog opstillet fire scenarier der kan visualisere hvordan
disse faktorer påvirker det endelige buskundepotentiale. I disse scenarier indgår en følsomhedsanalyse
hvor vi har inddelt faktorerne. Et hvor de oprindelige faktorer er nedskaleret med henholdsvis 5 og 10
procentpoint. Samt et scenarie som kigger på andelen af beskæftigede, og folk under uddannelse, ud af
den samlede befolkning.
Scenarierne tager derfor udgangspunkt i den oprindelige models afgrænsninger hvor det er antaget at
20% af alle i beskæftigelse er potentielle kunder og 52% af uddannelsessøgende over 15 er potentielle
kunder
Scenarie 1: tager udgangspunkt i modellens tidligere værdier, hvor 20% af hele dagbefolkningen er
potentielle kunder og 52% af alle studiesøgende er potentielle kunder.
Scenarie 2: tager udgangspunkt i scenarie 1, men nedskriver begge værdier med 5 procentpoint.
Scenarie 3: tager udgangspunkt i scenarie 1, men nedskriver begge værdier med 10 procentpoint.
Scenarie 4: tager udgangspunkt i en optimistisk skalering som tager udgangspunkt i det totale potentiale
af hele Fyns befolkning, det er antaget denne model at alle beskæftigede og alle under uddannelse er
potentielle kunder. Dette indeholder værdierne 43% for dagbefolkningen og 12% af befolkning i
uddannelse over 15.

105
Nedenstående Tabel 2 viser umiddelbare resultater fra følsomhedsanalysen.
Scenari
eTil
potentiale
Dagbefolkning
i beskæftigelse
Dagbefolkning i
uddannelse over 15
år
BKP
Ændrin
g i %
1
20% og 52%
65.494
31.473
231.715
38%
2
15% og 47%
52.619
28.447
215.814
28%
3
10% og 42%
39.744
25.421
199.913
19%
4
43% og 12%
97.235
7.360
239.343
42%
Tabel 2: I ovenstående tabel fremgår resultaterne fra følsomhedsanalysen. BKP står for buskundepotentiale.
Scenarie 1, 2 og 3 vurderes at kunne arbejdes videre med som grundlag for den opdaterede
buskundemodel, alt efter interne målsætninger hos FynBus.
Diskussion og konklusion
Spatiel regressionsanalyse som metode til at definere buskundeværdien til brug i formlen for
buskundepotentiale, viser lovende resultater til videre udvikling. Differencen mellem de nye
buskundeværdier og buskundeværdierne defineret i den nuværende model for buskundepotentiale viser
sig for nogen grupper større end forventet. Derfor er det påtænkt at modellen bør testes på typer fremfor
grupper ved fremtidig udvikling inden modellen fuldt udrulles.
Resultaterne er som forventet højere end den nuværende model, netop grundet de mange variationer
som der fordeler sig på det mere detaljerede typeniveau for ConZoomTM data. Typenivauet er dog meget
ressourcekrævende at afdække, og har ikke været muligt under projektets udformning. Væksten i
buskundepotentialet er dog i tråd med stigende tilflytning som opleves på Fyn gennem de sidste 10 år,
hvori det er forventet at der tilsvarende er et stigende potentiale for buskunder.
Herudover, ønskes det afdækket hvorvidt faktorerne i Til-Potentiale (3) skal vurderes ud fra andre
metoder, herunder udnyttelse Transportvaneundersøgelsen, som udarbejdes af DTU, eller andre
statistiske modeller der kortlægger rejser på baggrund af transportmiddelfordeling.
Desuden, bør der vurderes hvorvidt decilindelingen hos ConZoomTM dataene er for brede i forhold til
formålet, her kan det overvejes at supplere med yderligere data fra Geomatic, eller Danmarks statistik
som indeholder variabler med kontinuerlige variabler eller andre tilsvarende variabler. Begge disse
muligheder kan potentielt forbedre modellen, dog er udnyttelse af realtidsdata for passagertællinger med
kameraer i busserne vurderet som meget brugbare som en afhængig variabel for denne type regression.
Konklusion
Modellen, der anvender spatial regressionsanalyse, viser lovende resultater. Det er dog nødvendigt at
undersøge modellens resultater på typeniveau for at sikre, at nuancerne i data er tilstrækkeligt belyst, og
at værdierne ikke overvurderes i forhold til den eksisterende model.
Derfor fortsættes arbejdet med fokus på at afdække disse usikkerheder, inden modellen implementeres
som et analyseværktøj hos FynBus.

106
Litteratur
Anselin L. 1988. Spatial Econometrics: Methods and Models. Kluwer Academics, Dordrecht
Oyana, T. J. 2021. Spatial analysis with R: Statistics, visualization, and computational methods (2nd
ed). CRC Press. https://doi.org/10.1201/9781003021643
Bilag 1: ConZoomTM data
De anvendte variabler er decilvariabler, der inddeler husstande på Fyn i ti lige store grupper2. Disse
variabler som er brugt i analysen, ser ud som følgende:
Decil
Alder
Husstan
dsindko
mst
Bilrådigh
ed
Beskæftigelse
Uddannelse
Socialklasse
Familietype
Boligtype
Civilstand
1
0-29 årige
Lav
Primært
husstande uden
bil
Primært
pensionerede
Primært
husstande med
grundskole
Meget stor
andel af
arbejderklasse
og underklasse
Primært
enlige uden
børn
Primært
enfamiliehus
og stuehus
Primært
enlige
2
30-49
årige
Primært
husstande uden
bil
Primært udenfor
arbejdsmarkedet
Primært
husstande med
erhvervsfaglig
og grundskole
Stor andel af
arbejderklasse
og underklasse
Primært
enlige uden
børn
Primært
enfamiliehus
Primært
enlige
3
30-49
årige
Primært
husstande uden
bil
Primært
Lønmodtagere på
lavt eller mellem
niveau
Primært
husstande med
erhvervsfaglig
og grundskole
Primært
middelklasse
og
arbejderklasse
Primært
enlige uden
børn
Primært
enfamiliehus
Primært
enlige
4
30-49
årige
Primært
husstande med
mindst en bil
Primært
Lønmodtagere på
lavt eller mellem
niveau
Primært
husstande med
erhvervsfaglig
uddannelse
Primært
middelklasse
og
arbejderklasse
Primært
enlige uden
børn
Primært
enfamiliehus
Primært
enlige
5
49-59
årige
Primært
husstande med
mindst en bil
Primært
Lønmodtagere på
lavt eller mellem
niveau
Primært
husstande med
erhvervsfaglig
uddannelse
Stor andel af
middelklase og
højere
middelklasse
Primært
enlige uden
børn
Primært
enfamiliehus
og
række/kæde
hus
Primært
enlige
6
Primært
personer
over 30 år
Primært
husstande med
mindst en bil
Primært
Selvstændig eller
Lønmodtagere på
højt niveau
Primært
husstande med
erhvervsfaglig
uddannelse
Stor andel af
middelklase og
højere
middelklasse
Primært med
børn
Primært
række/kæde
hus
Primært
par
7
Primært
personer
over 30 år
Primært
husstande med
mindst en bil
Primært
Selvstændig eller
Lønmodtagere på
højt niveau
Primært
husstande med
erhvervsfaglig
uddannelse
Primært
middelklasse
eller over
Primært med
børn
Primært
etagebolig
Primært
par
8
Primært
personer
over 65 år
Primært
husstande med
mindst en bil
Primært
Selvstændig eller
Lønmodtagere på
højt niveau
Primært
husstande med
erhvervsfaglig
uddannelse
Primært
middelklasse
eller over
Primært med
børn
Primært
etagebolig
Primært
par
9
Primært
personer
over 65 år
Primært
husstande med
mindst en bil
Primært
Selvstændig eller
Lønmodtagere på
højt niveau
Primært
husstande med
mellem og lang
videregående
uddannelse
Stor andel af
overklasse og
højere
middelklasse
Primært par
med børn
Primært
etagebolig
Primært
par
10
Primært
personer
over 65 år
Høj
Primært
husstande med
mindst en bil
Primært
Selvstændig eller
Lønmodtagere på
højt niveau
Primært
husstande med
lang
videregående
uddannelse og
forskere
Primært
overklasse
Primært par
med børn
Primært
etagebolig
Kun par
2 hƩps://apps.conzoom.eu/api/v1/meta/dk/variables

107
Aid for Trade and CO2 Emissions: The Case of Middle-Income Countries
Ayúe ArÕ, Department of Economics, Mersin University, Jørgen T. Lauridsen,
Department of Economics, University of Southern Denmark, and Elvan Küpeli,
Department of Economics, Mersin University. Correspondence: jtl@sam.sdu.dk.
Abstract
We investigate the impact of Aid for Trade (AfT) on the environment for 12 middle-
income countries during the period of 2003-2020 by employing the Augmented Mean
Group estimator and causality tests. While the direct effect of AfT on CO2 emissions is
significant and negative for the renewable as well as the total energy sector, the indirect
effect is not. We didn’t find evidence of an inverted-U-shaped effect of AfT on CO2
emissions. A causality relationship between AfT and CO2 emissions was found for the
total as well as the renewable energy sectors. Thus, AfT funds targeted to renewable or
total energy sectors in middle-income countries can reduce CO2 emission but not AfT
funds for other sectors.
Keywords: Sustainable development; Aid for Trade; CO2 Emissions; Trade;
Renewable Energy; Economic Development; Causality
1.Introduction
In the present study, we analyse the impact of AfT on the environment for middle
income countries. Detecting an improvement in environmental quality resulting from
AfT disbursements in these countries will indicate that in addition to the main purpose
of AfT, which is increased trade benefits, AfT is also beneficial for environment.
Another contribution of this study is to analyse the direct and indirect impact of AfT on
CO2 emissions. To this aim, we separate AfT into two groups depending on sectoral
basis: a) AfT funds transferred to the total energy sector to reflect the direct impact of
AfT, and b) AfT funds transferred to sectors other than the energy sector in order to
reveal the indirect effects of AfT. AfT inflows for sectors other than the energy sector
are mostly provided to the production sectors and infrastructure investments such as
communication, transportation and storage. In this study we search answers to the
following questions: Do AfT funds for production and infrastructure investments have
108
any effect on environmental quality through macroeconomic variables such as economic
growth and poverty and, if so, is this effect positive or negative, and do the AfT inflows
for the total energy sector or the renewable energy sector have any impact on
environmental quality? One finding revealing that AfT funds going to the energy sector
increase the environmental quality indicates that these funds were used mostly in the
renewable energy sector, not in the fossil fuel energy. As stated by Kablan and Chouard
(2022:5358), foreign aid for renewable energy is provided to support projects for
renewable energy resources and production. Therefore, AfT disbursements for the
renewable energy sector will be expected to improve environmental quality more than
other forms of AfT. In the present study, the validity of this thesis will be analysed.
Lastly, we investigated the existence of an inverted U-shaped relationship between total
AfT and environmental quality, as Boly (2018:18) states that the effect of foreign aid on
the environment quality depends on the monitoring power of donor countries and the
aim of authorities in recipient countries which is related to the magnitude of foreign aid.
This may also be valid for the relationship between AfT and CO2 emissions. In addition,
AfT may have effect on the environment through different channels such as economic
growth, poverty, income inequality etc. The effects of these macroeconomic variables
may realize in the opposite direction which can also change after a threshold value of
AfT. In the present study we aim to test the validity of U shaped or inverted U-shaped
AfT hypothesis between AfT-CO2 emissions.
Data from 12 middle income countries (Turkey, South Africa, Mexico, India, Morocco,
Bangladesh, Philippines, Vietnam, Egypt, Thailand, Indonesia, and China) are analysed
covering the years from 2003 to 2020. In the graph below the total AFT inflows in US$
are showed for the mentioned countries. According to the Figure 1, the highest AfT
funds go to India, Bangladesh, Vietnam, Philippines, Morocco, and Egypt. The lowest
AfT inflows belong to Türkiye, South Africa, Mexico and China. This makes sense since
Türkiye, South Africa, Mexico and China are relatively more developed than the other
countries in the study. It is also seen that the countries receiving most and least AfT
funds have almost not changed during the years 2003 to 2020. In addition, we can say
that total AfT has generally increased since 2003 and that the peak values were reached
in the years 2014 and 2017. Figures 1 and 2 also illustrate that there has been an

109
important increase in AfT funds, AfT for total energy and AfT for renewable energy
sectors during the years 2010 to 2019. Lastly, following a reduction in the years 2015
and 2019, these funds have started to increase again for most of the recipient countries
in the model.
Figure 1. Total AfT Funds
Figure 2. AfT disbursements for energy sector and renewable energy sector
In Figure 2, AfT inflows to the total energy sector and renewable energy sector (US $)
are displayed. We see that India, Bangladesh, Vietnam, Philippines and Egypt have the
highest AfT inflows to total energy sector. Türkiye, South Africa, Mexico and China
0
2000
4000
6000
8000
10000
12000
14000
16000
2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020
Total AfT
Türkiye South Africa mexico China
Indonesia Thailand Egypt Morocco
Philippines Vietnam Bangladesh India
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018
2019
2020
AfT for Energy
Türkiye South Africa mexico
China Indonesia Thailand
Egypt Morocco Philippines
Vietnam Bangladesh India
0
200
400
600
800
1000
1200
1400
1600
1800
2000
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018
2019
2020
AfT for renewable energy
Türkiye South Africa mexico
China Indonesia Thailand
Egypt Morocco Philippines
Vietnam Bangladesh India
110
have the lowest AfT inflows for energy sector which is parallel with the results of total
AfT.
When we look at the AfT funds for the renewable energy sector, Figure 2 shows that
India, Bangladesh, Vietnam, Philippines and Egypt have the highest funds. It is also
seen that the countries receiving the lowest AfT inflows for renewable energy sector
are again Türkiye, South Africa, Mexico and China as in the case of total energy
sector.
4. Model and Data
Model 1, which aims to determine the direct and indirect influence of AfT on the
environment, is written as (1) following the study of Nguyen et al. (2023):
Model 1: ܥܱ2௧ =ߚଵܣ݂ܶ,௧ +ߚଶܣ݂ܶ௧ଵ,௧ +ߚଷܩܦܲ௧ +ߚସݎ݁݊݁ݓ௧ +݁௧ (1)
In order to investigate the direct impact of AfT on the environment, we preferred AfT
inflows for the renewable energy sector (ܣ݂ܶ) as the second variable. For this
purpose, we created Model 2. Similar to Model 1, the ܣ݂ܶ௧ଶ covers the AfT funds
for all sectors except renewable energy sector:
Model 2: ܥܱ2௧ =ߚଵܣ݂ܶ,௧ +ߚଶܣ݂ܶ௧ଶ,௧ +ߚଷܩܦܲ௧ +ߚସݎ݁݊݁ݓ௧ +݁௧ (2)
Finally, in the study, the impact of total AfT on environment was also analysed for
developing countries. In this Model 3, the possibility of the impact of AfT on the
environment being U or inverted-U shaped was also considered:
Model 3: ܥܱ2௧ =ߚଵܣ݂ܶ௧ +ߚଶܣ݂ܶ௧
ଶ+ߚଷܩܦܲ௧ +ߚସݎ݁݊݁ݓ௧ +݁௧ (3)
To determine the relationship between environmental quality and AfT, the study include
12 developing countries (Turkey, South Africa, Mexico, India, Morocco, Bangladesh,
Philippines, Vietnam, Egypt, Thailand, Indonesia and China) that are in the middle-
income group according to the World Bank classification. Data covers the period 2003-
2020 in the analyses. While the data for AfT inflows were taken from the OECD site
(OECD, 2024), other data were obtained from the World Bank (WDI, 2023). The data
were used in logarithmic forms.

111
5.Empirical results
In this study, firstly, a cross-sectional dependency test was conducted. Determining
cross-sectional dependency provides guidance in selecting estimators and cointegration
and causality tests in order to produce consistent and reliable results. The LM test of
Breusch and Pagan (1980) and the LMadj test of Pesaran et al. (2008) were preferred
which can be used in the case of T>N. LMadj test is a stronger version of the LM test,
and Pesaran et al. (2008) developed it by including the mean and variance to the LM
test.
The null hypothesis indicates no cross-sectional dependence for LMadj test. According
to the test results summarized in Table 2, the probability values are less than 0.05, thus
revealing cross-sectional dependency.
Table 2. Cross-Sectional Dependency Test Results (p-values in parentheses)
LM
LMadj
CO2
634.079 (<0.001)
14.816 (<0.001)
AfTener
248.649 (<0.001)
9.292 (<0.001)
AfTother1
228.931 (<0.001)
14.566 (<0.001)
AfTren
241.254 (<0.001)
5.552 (<0.001)
AfTother2
237.222 (<0.001)
13.999 (<0.001)
AfT
262.655 (<0.001)
13.973 (<0.001)
AfT2
262.4683 (<0.001)
13.598 (<0.001)
renew
480.5656 (<0.001)
18.039 (<0.001)
gdp
973.2650 (<0.001)
11.697 (<0.001)
Whether the series contained unit roots was investigated with the Cross-sectionally
Augmented Dickey Fuller (CADF) test developed by Pesaran (2007). The CADF test is
one of the second-generation unit root tests that considers cross-section dependency.
Pesaran (2007) reached Cross-sectionally Augmented IPS (CIPS) statistics that give
results for the entire panel by taking the average of the CADF test statistics obtained for
each cross-section and adding the lags of the averages to the model. The CIPS test has
powerful size properties for small samples and can produce consistent results both in
the cases of N>T and T>N (Pesaran, 2007:266-267). Unit root test results are
summarized in Table 3 for the intercept model.

112
Table 3 indicates that while the variables ܥܱ2,ܣܨܶ௧ଶ,ܣ݂ܶ and ݎ݁݊݁ݓ are
difference stationary, ܣ݂ܶ,ܣ݂ܶ௧ଵ,ܣ݂ܶ,ܣ݂ܶଶand ܩܦܲ are level stationary.
The results of unit root tests indicate that the dependent variable is I(1) while some of
the independent variables are I(I) and the others are I(0).
Table 3. Results of Unit Root Test
Level
First diff.
Test stat.
Test stat.
CO2
-1.663
-3.161
AfTener
-2.901
-5.045
AfTother1
-2.271
-4.329
AfTren
-2.719
-3.995
AfTother2
-2.052
-4.613
AfT
-2.118
-4.475
AfT2
-2.692
-4.448
renew
-1.573
-3.316
gdp
-2.431
-3.529
Note: CIPS critical values for 10%, 5% and 1% significance levels are -2.14, -2.26 and
-2.47, respectively. Critical values are obtained from Pesaran (2007:280).
It is also useful to know whether our models are homogeneous or heterogeneous.
Determining whether the slope coefficients in the cointegration equation are the same
among the countries is also decisive in choosing appropriate cointegration tests,
coefficient estimators and causality tests. For this purpose, the homogeneity test of
Pesaran and Yamagata (2008) was applied. This test was conducted as a development
of the Swamy (1970) test statistic (ܵ
ሚ ), and can be used for samples where N<T as well
as samples with T>N. Two further tests from the study of Pesaran and Yamagata (2008)
are applied. Among the tests, the ο
෨ test produces consistent results for large samples.
The ο
෨݆ܽ݀ test is the bias-adjusted version and produces more consistent results for small
samples (Pesaran and Yamagata, 2008:57).
Homogeneity test results are presented in Table 4. According to Table 4, since the p-
values are less than 0.05, homogeneity is rejected.

113
Table 4. Pesaran and Yamagata (2008) homogeneity test results
Model 1
Model 2
Model 3
Test stat.
p-value
Test stat.
p-value
Test stat.
p-value
ο
෨
11.273
0.000
11.290
0.000
11.170
0.000
ο
෨݆ܽ݀
13.807
0.000
13.827
0.000
13.681
0.000
In order to investigate the existence of a long-run relationship between variables we
applied the Durbin Hausman technique of Westerlund (2008) which allows the
explanatory variables to be I(0) or I(1). Additionally, this test is used for samples with
cross-sectional dependence. Another advantage of the Durbin Hausman technique is that
it can produce results for both homogenous and heterogenous panels. Related to this
test, group statistics demonstrates results for heterogenous models while panel statistics
demonstrates results for homogenous models. (Westerlund, 2008). Table 5 below gives
the results of these tests for Model 1, Model 2 and Model 3. According to these results,
the p-values are greater than 0.05 which denote that the series are not cointegrated for
all 3 models.
Table 5. Cointegration Test Result
Mode1
Model 2
Model 3
Stat.
p-value
Stat.
p-value
Stat.
p-value
dh_g
-0.222
0.412
1.498
0.933
0.786
0.784
dh_p
0.009
0.503
-0.007
0.497
-0.064
0.475
Although the variables are not cointegrated we can search for coefficient estimates of
the regression models by employing the above-mentioned AMG method of Eberhardt
and Bond (2009). Thus, the direction and magnitude of the direct and indirect impact of
AfT on the environment can be determined. The AMG method allows cross-sectional
dependency and heterogeneity. Another advantage of the AMG method is that it is
demonstrated by Monte Carlo simulations that results are unbiased whether the variables
are cointegrated or not (Eberhardt, 2012:64). Similar to the Common Correlated Effects
(CCE) method, the AMG estimator will also be valid if there is unit root process in
regressors (Pesaran, 2007:969-75; Eberhardt and Bond, 2009; Eberhardt and Teal,

114
2010). In short, the AMG estimator also allows the integration of explanatory variables
at different degrees (Purcel, 2021:8-72).
Table 6. Results of AMG estimator results
Model 1
Model 2
Model 3
Coef.
p-value
Coef.
p-value
Coef.
p-value
AfTener
-.0157894
0.006
AfTother1
-.0097958
0.448
AfTren
-.0062864
0.003
AfTother2
-.0157805
0.282
AfT
-.2106083
0.674
AfT2
-.0144276
0.616
Gdp
.1106029
0.001
.1171257
0.001
.1002286
0.017
renew
-.5835462
0.000
-.5542236
0.001
-.5894321
0.000
C
-.3102884
0.432
-.3604896
0.454
-.899405
0.648
The results of AMG estimator are reported in Table 6 for Model 1, Model 2 and Model
3. According to the results of Model 1, the impact of AfT inflows on the energy sector
is statistically significant and negative. Thus, AfT has a direct effect on the
environmental quality and the increase in AfT inflows to the energy sector leads to
increase in environmental quality. This evidence for AfT for the energy sector is
supported by the results of Bhattacharyya et al. (2016) indicating that energy aids helped
to reduce CO2 emissions especially in Europe and Central Asian countries, while
differed from the findings of Mahalik et al. (2021) demonstrating that energy aids
increased CO2 emissions for India. On the other hand, AfT inflows for other sector have
no significant effect on CO2 emissions. Therefore, it can be concluded that AfT does
not have an indirect effect on CO2 emissions. Among the other explanatory variables,
renewable energy consumption reduces CO2 emissions while economic growth
increases them as expected from theory.
According to the results of Model 2, AfT for the renewable energy sector affects CO2
emissions negatively at a 1% significance level. The results obtained for AfT inflows to
the renewable energy sector are consistent with the results of Kablan and Chouard
(2022). However, the impact of AfT funds on CO2 emissions for other sectors is
insignificant which is in line with Model 1. Additionally, renewable energy
115
consumption and economic growth have negative and significantly positive effects on
CO2 emissions, respectively. In summary, the results of Model 1 and Model 2 reveal
that AfT has a direct effect but not indirect effect on the environment.
According to Model 3 the effect of total AfT on CO2 emissions is insignificant. This
result differs from the Nguyen et al. (2023) study, which covered 100 countries and
found that total AfT had a detrimental effect on environmental quality. The approach
that AfT may have an inverted U or U-shaped effect on the environment is not valid for
middle income countries. Renewable energy consumption reduces CO2 emissions while
economic growth increases CO2 emissions in accordance with theory.
Finally, the causal relationships between the variables were also questioned. For this
purpose, we employed the causality test developed by Emirmahmuto÷lu and Köse
(2011). This test can be used for cases where the series are cointegrated as well as not.
Another advantage is that it allows series to be integrated of order 0 as well as 1.
Moreover, this test considers heterogeneity (Emirmahmuto÷lu and Köse, 2011: 872). In
this test, the authors adopt the approach of the Toda and Yamamoto (1995) test and
produce Fisher statistics for the entire panel, based on the probabilities calculated for
each cross-section. The null hypothesis states that there are no causalities for all units,
while the alternative hypothesis denotes that there are causalities for some units
(Emirmahmuto÷lu and Köse, 2011).
According to the causality test results in Table 7, the null hypothesis that AfT for the
renewable sector is not a Granger cause of CO2 emission is rejected at the 5%
significance level. Similarly, CO2 is a Granger cause of AfT funds for the energy sector.
However, another finding is that there is no causality running from AfT for other sectors
to CO2 emissions, while it is seen that CO2 emissions is a Granger cause of AfT funds
for all sectors except the energy sectors. There is also a bidirectional causal relationship
between AfT funds transferred to the renewable energy sector and CO2 emissions, while
there is a unidirectional causality relationship between AfT funds for other sectors and
CO2 emissions running from AfT funds transferred to other sectors to CO2 emissions.
To summarize, there are causalities from variables reflecting the direct impact of AfT
to CO2 emissions only but not from variables reflecting indirect impact of AfT to CO2

116
emissions. These findings reveal that only AfT funds given to the energy and renewable
energy sectors may influence CO2 emissions and support the evidence obtained for
Model 1 and Model 2 in the AMG estimation results.
Table 7. Results of causality tests
Null Hypothesis
Fisher stat.
p-value
CO2 is not Granger cause of AfTener
66.80765
<0.001
AfT
ener
is not Granger cause of CO2
37.55394
0.038
CO2 is not Granger cause of AfT
other1
69.27143
<0.001
AfT
other1
, is not Granger cause of CO2
15.24730
0.913
CO2 is not Granger cause of AfTren
152.2413
<0.001
AfT
ren
is not Granger cause of CO2
120.2964
<0.001
CO2 is not Granger cause of AfTother2
37.30341
0.041
AfTother2 is not Granger cause of CO2
19.81088
0.707
CO2 is not Granger cause of AfT
41.57285
0.014
AfT is not Granger cause of CO2
27.25110
0.293
CO2 is not Granger cause of AfT2
40.37436
0.020
AfT2 is not Granger cause of CO2
26.89424
0.309
CO2 is not Granger cause of gdp
23.49229
0.490
gdp is not Granger cause of CO2
46.21355
0.004
CO2 is not Granger cause of renew
31.49969
0.140
renew is not Granger cause of CO2
38.55326
0.030
The causal relationship between CO2 emission and total AfT is unidirectional and runs
from CO2 emission to AfT. No causal relationship was found between CO2 and AfT2.
These findings are also consistent with the results of the AMG estimator for Model 3.
According to Table 7, economic growth and renewable energy consumption have
unidirectional relationships with CO2 emissions. The direction of the causality is from
economic growth to CO2 emissions and from renewable energy consumption to CO2
emissions, being in line with theory.
6. Conclusion
In this study, we investigated the effect of AfT on the environmental quality by focusing
on the components of AfT funds in terms of sectors. In this context, we made a
distinction between AfT funds for the energy sector and AfT funds for other sectors in
117
Model 1. By doing so, we aimed to investigate the direct and indirect effect of AfT on
CO2 emissions. Similarly, we also separated the AfT funds into 2 groups as AfT for
renewable energy sector and AfT for other sectors to search the direct and indirect
impact of AfT in Model 2. Additionally, we analysed the validity of inverted-U-shaped
effects between total AfT funds and CO2 emissions in Model 3.
In our study, a sample consisting of middle-income countries was analysed over the
period 2003-2020. We included renewable energy consumption and economic growth
variables to all models as control variables. For the coefficient estimates of the
regression models, we used the AMG method. According to the AMG results, the direct
impacts of AfT on CO2 emissions are negative and significant for both variables. In
contrast, the indirect effects of AfT funds on CO2 emissions are statistically
insignificant revealing that AfT funds for all sectors except energy and renewable
energy sectors have no influence on CO2 emissions.
The AMG results also demonstrate that the impact of total AfT on CO2 emissions is
insignificant (Model 3). Besides, the hypothesis that AfT may have an inverted-U-
shaped effect on CO2 emissions is not confirmed. On the other hand, as expected from
theory, renewable energy consumption affects CO2 emissions negatively, while
economic growth affects CO2 emissions positively in all 3 models.
Finally, we applied the causality test of Emirmahmuto÷lu and Köse (2011). According
to these results, AfT inflows to the renewable energy sector have bidirectional causal
relationships with CO2 emissions. Similarly, AfT funds to the total energy sector have
bidirectional causality relationships with CO2 emissions. No causalities are observed
from AfT funds for all other sectors to CO2 emissions. Moreover, no causality was
detected from total AfT to CO2 emissions. On the other hand, there is a unidirectional
causal relationship running from economic growth to CO2 emissions and from
renewable energy consumption to CO2 emissions. In sum, these findings are in line
with the regression model estimates.
To conclude, while AfT has a direct and negative impact on CO2 emissions, no indirect
effect has been observed in middle-income countries. In other words, when we examine
the impacts of the components of AfT on CO2 emissions, only Aft for total energy sector

118
or renewable energy sector contribute to the reduction of CO2 emissions. This reveals
that AfT funds for the total energy sector are mostly used in renewable energy sector
investments. On the other hand, we can conclude that since AfT for other sectors have
no effect on CO2 emissions, AfT has no impact on CO2 emissions through channels
such as economic growth, export diversification, poverty reduction etc. This may result
since the countries in the model have realized economic growth and building of
infrastructure at a a certain level. Besides, it may also take longer for the indirect effect
to realize as stated by Kim (2019:2718). On the other hand, the invalidity of the
hypothesis that AfT funds may have a U or inverted-U-shaped impact on the
environment may be due to the short period analysed.
In summary, the total AfT funds for developing countries to benefit more from foreign
trade do not affect environmental quality. However, when we analyse the components
of AfT funds on a sectoral basis, AfT funds transferred to renewable energy or to the
total energy sector may improve the environmental quality. The nonexistence of the
impact of total AfT on CO2 emissions may occur due to the low share of AfT given to
renewable energy or the total energy sector in total AfT. From a climate mitigation
policy perspective, AfT donor countries, which care about environmental quality,
should increase the proportion of AfT funds for renewable energy and total energy
sector. In addition, authorities should encourage renewable energy investments instead
of fossil resources to minimize the damage to the environment in middle countries where
economic growth is one of the main goals.
References
Arvin, M., Dabir-Alai, P. and Lew, B. (2006). Does foreign aid affect the environment in developing economies?
Journal of Economic Development, 63 (31). 31 (1): 63–87.
Bhattacharyya, S., M. Intartaglia, and A. McKay 2016. “Does Climate Aid Affect Emissions? Evidence from a
Global Dataset.” CSAE Working Paper Series 2016-09. Centre for the Study of African Economies, University of
Oxford.
Boly, M. 2018. “CO2 Mitigation in Developing Countries: The Role of Foreign Aid.” Working Papers 201208,
CERDI. http://cerdi.org/production/show/id/1915/type_production_id/1
Breusch, T.S & Pagan, A.R. (1980), The Lagrange Multiplier Test and Its Applications to Model Specification
Tests in Econometrics. Review of Economic Studies, 47, 239-53. https://doi.org/10.2307/2297111

119
Eberhardt, M. & Bond, S. (2009). Cross-section dependence in nonstationary panel models: A novel estimator.
MPRA Paper 17692, University Library of Munich, MPRA Paper, No. 17870. http://mpra.ub.uni-
muenchen.de/17692/1/MPRA paper 17692.pdf.
Eberhardt, M. (2012) Estimating panel time-series models with heterogeneous slopes, The Stata Journal (2012),
12, Number 1, pp. 61–71. https://doi.org/10.1177/1536867X1201200105
Eberhardt, M. & Teal, F. (2010) Productivity analysis in global manufacturing production. Discussion Paper 515,
Department of Economics, University of Oxford. http://www.economics.ox.ac.uk/research/WP/pdf/paper515.pdf.
Emirmahmuto÷lu, F., & Köse, N. (2011). Testing for granger causality in heterogeneous mixed panels. Economic
Modelling, 28, 870–876. https://doi.org/10.1016/j.econmod.2010.10.018
Kablan, S., & Chouard, V. (2022) Does climate aid matter for reducing CO2 emissions? The case of foreign aid
for renewable energy, Applied Economics, 54:46,5357-5372, https://doi.org/10.1080/00036846.2022.2044995.
Kim, Y. R.,(2019). Does aid for trade diversify the export structure of recipient countries? The World Economy,
42(9), 2684–2722. https://doi.org/10.1111/twec.12845.
Mahalik MK, Villanthenkodath MA, Mallick H, Gupta M (2021) Assessing the effectiveness of total foreign aid
and foreign energy aid inflows on environmental quality in India. Energy Policy, 149(112015), 1-19.
https://doi.org/10.1016/j.enpol.2020.112015.
Nguyen, T. P. T., Nguyen, V. A., & Ly-My, D. (2023). Does Aid for Trade affect the quality of the environment?
Evidence from Aid for Trade recipient countries. Journal of International Development, 1–20.
https://doi.org/10.1002/jid.3780.
OECD/WTO (2022), Aid for Trade at a Glance 2022: Empowering Connected, Sustainable Trade, OECD
Publishing, Paris, https://doi.org/10.1787/9ce2b7ba-en.
OECD (2024), OECD.Stat, Creditor Reporting System, https://stats.oecd.org/.
Pesaran, M. H. (2007), A Simple Panel Unit Root Test in the Presence of Cross Section Dependence, Journal of
Applied Econometrics, 22(2), pp. 265-312. https://doi.org/10.1002/jae.951
Pesaran, M. H., Yamagata, T. (2008) Testing slope homogeneity in large panels, Journal of Econometrics, 142(1),
pp. 50–93. https://doi.org/10.1016/j.jeconom.2007.05.010
Pesaran, M.H., Ullah, A. and Yamagata, T. (2008), “A Bias-Adjusted LM Test of Error Cross-Section
Independence”, Econometrics Journal, 11(1), 105-127. https://doi.org/10.1111/j.1368-423X.2007.00227.x
Toda, H.Y., Yamamoto, T., 1995. Statistical inference in vector autoregressions with possibly integrated processes.
Journal of Econometrics 66, 225–250. https://doi.org/10.1016/0304-4076(94)01616-8
Westerlund, J. (2008). Panel Cointegration Tests of the Fisher Effect. Journal of Applied Econometrics 23(2), 193-
223. https://doi.org/10.1002/jae.967
120
Fra prompt til praksis
Undervisning i anvendt statistik med generativ AI
Sara Armandi, Hans Bay, Anders Milhøj, Markus Roed Schøler og Nina Johanna Åberg-Jensen
Økonomisk Institut, Københavns Universitet
Disclaimer: Artikel er skrevet i en tid med hastig udvikling inden for generativ AI, og flere
oplysninger kan allerede ved udgivelsen være forældede. Dette understreger vigtigheden af
kontinuerlig opmærksomhed og forskning inden for området.
Abstract
Denne artikel undersøger integrationen af generativ AI, med særligt fokus på store
sprogmodeller som ChatGPT og Copilot, i undervisningen i anvendt statistik. Fokus er
rettet mod sprogmodellernes potentiale til at understøtte læring i kodning og dataanalyse,
særligt med henblik på programmet SAS. Gennem praktiske eksempler fremhæves både
styrker og begrænsninger ved brugen af modellerne, herunder vigtigheden af
velstruktureret promptning for at opnå de bedste resultater. Artiklen adresserer også
didaktiske overvejelser, der kan hjælpe undervisere og studerende med at udnytte
modellerne effektivt. Afslutningsvis præsenteres anbefalinger til, hvordan undervisnings-
og eksamensformer kan tilpasses for at fremme lige læringsvilkår og sikre en balanceret
anvendelse af AI i den akademiske kontekst.
1 Introduktion
Generativ AI (GenAI) er blevet en integreret del af vores hverdag, især gennem store
sprogmodeller (LLM'er, "Large Language Models") som OpenAI's ChatGPT og Microsofts
121
Copilot. Disse modeller kan både generere tekst og assistere med opgaver inden for
programmering og dataanalyse.
Pr. 2024 er der empirisk belæg for, at ChatGPT er den mest udbredte sprogmodel blandt
studerende på Økonomistudiet ved Københavns Universitet, der tager kurser i anvendt
statistik. Universitetet har desuden anskaffet en Enterprise-licens til Copilot, hvilket gør
dette værktøj frit tilgængeligt for både ansatte og studerende. Mange studerende er dog
usikre på, hvordan de korrekt og hensigtsmæssigt kan anvende disse værktøjer, hvilket
bekræftes af en større spørgeskemaundersøgelse fra de humanistiske og teologiske
fakulteter. I flere kurser frarådes studerende decideret at bruge GenAI-værktøjer, muligvis
fordi underviserne ikke har overblik over konsekvenserne ved anvendelsen.
Der er et presserende behov for undervisning i brugen af GenAI-værktøjer, da mange
undervisere oplever at modtage opgaver, der tydeligt viser sig at være delvist genereret af
LLM’er. Samtidig skaber forskelle i studerendes evner til at anvende modellerne en
uligevægt i forudsætningerne for læring og resultater, hvilket gør det afgørende at integrere
undervisning i LLM’er for at fremme lige vilkår for alle studerende.
Det er vigtigt at bemærke, at der ikke kun er behov for undervisning af studerende; mange
undervisere har også brug for en dybere forståelse af GenAI. Behovet for at dykke ned i
anvendelsen af GenAI understreges af følgende officielle udmelding fra Københavns
Universitet:
”Fra og med efteråret 2025 vil anvendelsen af generativ AI (GAI) ved alle
eksamensformer (inkl. hjemmeopgaver, BA-projekter og specialer) med "alle
hjælpemidler tilladt" derfor som standard være tilladt på KU.”
Udfordringen ligger i, at de nuværende undervisnings-, opgave- og eksamensformer ikke
nødvendigvis er designet til at håndtere GenAI, da det, jf. Figur 1, bl.a. er muligt for
studerende at opnå tilfredsstillende resultater ved blot at benytte generiske svar fra LLM'er
uden at engagere sig i den nødvendige læringsproces.

122
Figur 1: Eksempel på korrespondance med ChatGPT
Kilde: Eksempel fra ChatGPT.
Hvis der tages højde for de nævnte udfordringer, har GenAI-teknologier potentiale til at
revolutionere undervisningen, herunder inden for områder som programmering og anvendt
statistik. LLM’erne kan understøtte udviklingen af kode samt forbedre forståelsen og
fortolkningen af dataanalyse. Denne artikel undersøger, hvordan LLM'er kan integreres i
universitetsundervisningen med fokus på anvendt statistik, især i relation til
programmerings- og kodeopgaver til analyser. Der tages udgangspunkt i to specifikke
generative AI-værktøjer: ChatGPT og Copilot, som begge er blevet afprøvet i forbindelse
med opgaveløsning. Gennem praktiske erfaringer belyses, hvordan disse værktøjer kan
implementeres effektivt i undervisningen.
2 Hvordan virker LLM’erne?
GenAI er en gren af AI, der fokuserer på at skabe nyt indhold eller data ved at lære fra
eksisterende data, såsom tekst, kode, video og billeder. LLM'er er avancerede GenAI-

123
modeller, der er designet til at forstå og generere menneskelignende tekst baseret på enorme
mængder tekstdata, hvilket inkluderer information fra internettet, bøger, artikler og andre
kilder. En LLM er en kraftfuld machine learning model, som kan bearbejde og identificere
komplekse sammenhænge i tekster. Disse modeller bygger på teknikker som dybe neutrale
netværk, som er designet til at lære komplekse mønstre og relationer i data gennem
hierarkisk repræsentation. Alt dette resulterer i modeller med op til milliarder af parametre.
Modellerne fungerer ved at bearbejde tekst i segmenter snarere end ord for ord. Disse
segmenter behandles parallelt, hvilket gør det muligt for modellen at forstå komplekse
sammenhænge og mønstre i teksten. Ved at analysere flere segmenter samtidigt kan
modellen forudsige det næste ord eller sætning baseret på den givne kontekst.
Helt konkret indebærer det, at modellen, baseret på et bagvedliggende system af unikke
ordrepræsentationer, kan knytte ord til vektorer i et højdimensionalt rum. Dette muliggør
beregningen af sandsynligheder for disse repræsentationer og dermed sandsynligheden for
et givent ord. Selvom sandsynligheden for et bestemt ord kan være høj, er der altså stadig
en sandsynlighed for, at et andet ord vælges, jf. Figur 2. Denne egenskab ved modellerne
gør det muligt for dem at generere nyt og unikt indhold, herunder sammenhængende
sætninger og tekst.
Figur 2: Ordforudsigelser og sandsynligheder fra en LLM
Kilde: Eksempel fra ChatGPT Playground
124
Det er vigtigt at bemærke, at LLM’er som udgangspunkt ikke er matematiske modeller
designet til at udføre beregninger eller anvende formler, hvilket kan gøre dem upålidelige
til præcise numeriske opgaver og avanceret logik. Derudover kan de have svært ved at
forstå komplekse kontekster eller subtiliteter, hvilket kan føre til misforståelser eller
upræcise svar. Disse begrænsninger understreger, at LLM’er, på trods af deres evne til at
generere tekst og analysere sprog, bør bruges med omtanke – især i fag som anvendt
statistik, hvor nøjagtighed og præcision er afgørende for resultaterne.
2.1 Ikke længere kun en sprogmodel
Selvom LLM'er primært er baseret på sprog, har den hurtige udvikling ført til, at flere
modeller nu også kan håndtere matematiske og kodningsrelaterede opgaver. Dette opnås
gennem en kombination af avanceret mønstergenkendelse og evnen til at generere samt
eksekvere kode, hvilket gør dem særligt nyttige i undervisningssammenhænge inden for
anvendt statistik.
Når en LLM modtager en matematisk forespørgsel, analyserer den først strukturen og
kravene for at identificere relevante regler eller mønstre. Enkle problemer løses typisk ved
hjælp af mønstre fra LLM’ens træningsdata, mens mere komplekse opgaver kræver, at
modellen genererer kode, som derefter eksekveres for at sikre korrektheden. Denne proces
muliggøres gennem en kodefortolker, der omsætter tekstbaserede beskrivelser til faktiske
beregninger og kodning.
En kodefortolker, der ofte er integreret med Python, giver modellen mulighed for at
oversætte forespørgsler til funktionelle, kodebaserede løsninger, der kan udføres direkte.
Dette muliggør, at modellen kan håndtere alt fra præcise beregninger og avancerede
dataanalyser til generering af grafer og visualiseringer. Resultaterne præsenteres på en
overskuelig måde og suppleres ofte med forklaringer af fremgangsmåden. Eksempler på
denne funktionalitet gennemgås kort i Bilag 1.
125
3 Teknisk funktionalitet og begrænsninger af LLM’er
Moderne LLM’er som ChatGPT og Copilot tilbyder en bred vifte af anvendelser inden for
uddannelse, men de har også tekniske begrænsninger og særlige funktioner, der bør tages i
betragtning. En af de praktiske funktioner er muligheden for at arbejde med hukommelse
på tværs af samtaler. Dette kan være nyttigt ved større projekter, hvor modellen lærer
brugerens præferencer og arbejdsmetoder. Det betyder, at man kan angive detaljer om data
eller opgavekrav én gang og bruge denne kontekst i senere prompts. Ulempen er dog, at
denne hukommelse kræver vedligeholdelse; hvis man ikke opdaterer modellen om
ændringer i projektet, kan dens svar blive mindre relevante – det er som at arbejde med en
kollega, man glemmer at informere. Ved kortere opgaver eller isolerede projekter kan det
være en fordel at arbejde uden hukommelse på tværs af samtaler. Ved at starte en ny samtale
for hvert projekt sikrer man, at tidligere viden ikke påvirker modellens output.
3.1 Træningsdataenes betydning
LLM’er præsterer ofte bedst på engelsk, da de engelske modeller er trænet på større
datamængder og derfor har mere viden til rådighed. Dog kan der være situationer, hvor
modellen yder bedre på dansk, især når spørgsmålet drejer sig om lokale emner, der primært
er beskrevet i danske sammenhænge.
Inden for SAS-kodning er det tydeligt, at LLM'er er bedre trænet i PROC SQL end i SAS'
data steps. Dette skyldes, at SQL er et mere udbredt programmeringssprog, der anvendes
på tværs af forskellige databaser. Derfor genererer LLM'er oftere kode i PROC SQL
fremfor kode i SAS data steps, når en opgave kan løses ved begge metoder. Dette er en
konsekvens af begrænset træningsdata, hvilket også ses for specifikke SAS-procedurer.
3.2 Forskelle mellem gratis- og betalingsversioner af LLM’er
En væsentlig forskel mellem gratis- og betalingsversioner af LLM'er er deres evne til at
håndtere større datamængder. Generelt er både antallet og længden af prompts begrænset i
gratisversionerne. Tabel 1 viser forskellene i pris samt begrænsningerne for filupload for

126
Copilot Enterprise og de nuværende tre versioner af ChatGPT, som private brugere kan
anvende. Københavns Universitet har betalt for en Enterprise-licens til Copilot, så selvom
studerende og undervisere ikke selv betaler, er licensen ikke gratis. Tabellen giver derfor
et overblik over de udgifter, som studerende og undervisere ved Københavns Universitet
vil have i forbindelse med brugen af disse værktøjer.
Tabel 1: KU-brugerpris og filupload for hhv. Copilot Enterprise og ChatGPT
Copilot Enterprise
ChatGPT Gratis
ChatGPT Plus
ChatGPT Pro
Pris pr. måned
$0 USD/måned
$0 USD/måned
$20 USD/måned
$200 USD/måned
Muligheder ved upload af filer
Filstørrelse
- CSV
10 MB pr. fil
50 MB
50 MB
50 MB
-
Billeder
Håndterer ikke
billeder
20 MB
20 MB
20 MB
- Tekstfiler
10 MB pr. fil
20 MB
20 MB
20 MB
Tilladt antal
uploadede filer
Ubegrænset antal,
maks. 2 GB
3 filer dagligt,
maks. 10 GB
80 filer hver tredje
time, maks. 10 GB
80 filer hver tredje
time, maks. 10 GB
Kilde:
OpenAI Help Center, https://help.openai.com/en/articles/8555545-file-uploads-faq og
https://copilot.cloud.microsoft/, december 2024
Hvis en fil uploades i en samtale, og denne når sin længdegrænse, kan det blive vanskeligt
at fortsætte interaktionen. Dette kan resultere i tab af uploadet information og en følelse af
at skulle starte forfra.
Som det fremgår af Tabel 1 understøtter betalingsversioner mere data, og dermed mere
komplekse opgaver. For eksempel har ChatGPT's Plus-version vist sig at kunne løse
avancerede statistiske opgaver, som besvarelsen af en SAS-opgave i kurset Videregående
Statistik. Her genererede modellen komplette svar, inklusive kode og tabeller, uden at skulle
åbne SAS-editoren. En begrænsning opstod dog, idet datasættet i SAS-format skulle
konverteres til et format, som modellen kunne genkende, hvilket LLM’en dog kunne løse
ved at generere noget kode.
127
Når data og opgavebeskrivelser uploades, kan LLM'er generere komplette løsninger,
herunder figurer, statistiske modeller og fortolkninger af resultater. Det er dog vigtigt at
bemærke, at da modellerne anvender Python, kan der opstå små diskrepanser mellem
udregninger udført direkte i modellerne og dem udført i SAS. Desuden vil output fra
modellerne være formateret anderledes end for eksempel SAS-output.
Udviklingen af LLM’er går hurtigt, og hvad der i dag kræver en betalingsversion, kan snart
blive en del af den gratis udgave.
4 Prompt Engineering for studerende
En prompt er en tekstuel instruktion, der guider en LLM i, hvilken type output eller indhold
den skal generere. Promptudvikling er kunsten at formulere klare og præcise instruktioner,
der optimerer modellens ydeevne og hjælper brugerne med at maksimere deres interaktion
med LLM'er. Denne disciplin er i konstant udvikling, da metoderne til at skabe effektive
instruktioner hurtigt tilpasser sig nye behov og teknologiske fremskridt.
4.1 Prompt-opskrift
Der er mange forskellige måder at prompte på, og mange forskellige tilgange afhængig af
opgavetypen. Tabel 2 beskriver kort de vigtigste elementer, der bør overvejes i
opbygningen af en prompt, når der arbejdes med anvendt statistik – især i relation til kode
og fortolkninger af analytisk output.

128
Tabel 2: Elementer i prompt til effektiv anvendelse af LLM’er
Element
Beskrivelse
Eksempel
Valgfrit - - - - - - - - - - - - - - - - - - - - - - - - - -
Vigtigt
Opgave
Giv LLM’en en konkret opgave med tydeligt
mål
. Start med handlingsverber som:
“Gener
ér”, “Skriv”, “Analysér”
“Generér en
SAS
-
kode, der
[beskriv
opgaven]”
Kontekst
Inkluder relevante detaljer for at optimere
output. Tænk på hv
-
ord: ”Hvem”, ”Hvad”,
”Hvornår”, ”Hvor”, ”Hvorfor”
,
”Hvordan”.
Tidligere kørt kode kan være essentielt.
“Koden skal
anvendes til at
analysere [indsæt
datasæt]”
Eksempel
Brug eksempler for at forbedre kvalitet og
præcision af output. Det er ofte lettere at vise,
hvad man ønsker,
end at beskrive det.
”En tidligere
SAS
-
kode ser
således ud:
[indsæt kode]”
Persona
Beskriv specifik ekspertise eller baggrund for
at tilpasse
output-formatet. Brug ”Ager
som
[persona]”
.
”Du er
dataanalytiker
med erfaring i
SAS…”
Format
Angiv bestemt format for at gøre output
struktureret og forståeligt
. Formatér
inkluderer punktopstillinger, kodeblokke,
paragraffer eller tabeller.
”Formater koden
så den let
kopieres ind i en
SAS-editor”
Kilde
: Mange, men især https://www.syv.ai/prompting-guide.
Selvom en omfattende kontekst ofte forbedrer kvaliteten af output fra LLM'er, kan det i
enklere opgaver være en fordel at begrænse den givne kontekst. Stramme rammer kan
nemlig hæmme LLM'ernes evne til at generere det mest fordelagtige output, især når en
opgave kan løses på flere måder, og metoden er mindre vigtig. I tilfælde af simplere opgaver
kan det derfor være mere effektivt at undlade kodeeksempler og i stedet formulere en kort
og præcis prompt, der klart angiver det ønskede output. Dette gælder også, når man ønsker
at forstå specifik kode eller output. Overdreven forklaring af egne tanker kan begrænse
LLM'ernes muligheder og føre til suboptimale resultater.
129
Der findes flere interessante promptelementer og -teknikker, der kan være nyttige inden for
anvendt statistik. For eksempel kan man anmode om flere forslag til en opgave for at vælge
det mest optimale resultat. Desuden kan det være gavnligt at bede LLM’erne om at stille
spørgsmål til sin prompt, hvilket kan resultere i en mere præcis prompt og et mere nøjagtigt
output.
4.2 Simpel vs. avanceret promptning
Med udgangspunkt i eksamensopgaven i faget Programmering og Statistik med SAS fra
juni 2021 undersøges hvordan forskellige måder at prompte på kan have afgørende
indflydelse på det output, der opnås. Eksamensopgaven var en 3½-timers
hjemmearbejdeopgave udarbejdet af Anders Milhøj. Idet opgaven blev stillet før
udbredelsen af GenAI, tog den ikke højde for muligheden for at anvende GenAI til løsning
af opgaverne.
Gennem flere itereringer er det blevet undersøgt, hvordan forskellige prompts kan hjælpe
med besvarelsen af eksamensopgaven. I denne artikel præsenteres to yderpunkter, der
betegnes som henholdsvis simpel promptning og avanceret promptning. Studerende, der
anvender simpel promptning, er ofte dem, der ikke har fået uddannelse i brugen af LLM’er
eller dem, der er fagligt udfordret. På den anden side kendetegnes avanceret promptning
ofte ved, at den anvendes af fagligt dygtige og grundige studerende, der har en god
forståelse af pensum.
Tabel 3 viser fremgangsmåden samt de umiddelbare resultater for de to forskellige tilgange
til at besvare eksamensopgaven. Det er tydeligt, at mere avancerede promptteknikker
resulterer i langt mere brugbare og fornuftige resultater. Ved at anvende avancerede
prompts får LLM’en mulighed for at producere mere korrekt og relevant output, da flere
kontekstuelle elementer er inkluderet. Dette understreger behovet for didaktisk støtte i
promptkonstruktion, som kan guide mindre erfarne studerende.

130
Ud fra Tabel 3 ses også hvordan forskelle i promptstrategi påvirker kvaliteten af output og
den læringsmæssige værdi. Det fremgår, at manglende uddannelse i brugen af LLM’er i
undervisningen kan skabe ulighed blandt studerende. Derfor er det vigtigt at tilbyde
uddannelse i brugen af LLM’er for at hjælpe studerende, der ikke har kendskab til effektive
promptteknikker.
Tabel 3: Forskel på hhv. simpel- og avanceret promptning
Promptning
Simpel promptning
Avanceret promptning
Input til prompt
Tilgang
En simpel prompt uden detaljeret
kontekst
En omhyggeligt opbygget prompt
med detaljeret kontekst og
relevante prompt-elementer
Struktur
Indsætter opgaveteksten som
direkte prompt uden yderligere
detaljer
Starter med en generel prompt og
tilføjer (evt. trinvis) mere kontekst
og specifik viden
Eksempel
"Skriv kode til denne opgave i
SAS"
"Skriv SAS-kode til dataanalyse
med korrekt brug af libname og
stier, undgå dataoverskrivning"
Output fra prompt
Kvalitet
Ofte mangelfuldt output, der
kræver SAS-viden til fejlsøgning
Ofte præcist og korrekt output i
første forsøg
Fejl og
fejlsøgning
Overskriver ofte data uden
advarsel; kræver manuel tilpasning
Færre fejl i output; undgår typiske
fejl ved datahåndtering og SAS-
opsætning
Anvendelse af
output
Afhænger af erfaring med SAS og
manuel justering af fejl
Kan direkte anvende output uden
omfattende redigering
Læring og
refleksion
Begrænset læring; primært
afhængig af, at AI "løser" opgaven
Øget læring; promptdesignet
kræver forståelse af opgavens krav
og SAS-komponenter
Kilde: Egne observationer
For studerende med begrænset kendskab til pensum kan en praktisk tilgang være at indsætte
selve opgaveteksten i LLM’en uden yderligere prompt engineering for at se, hvilket output
der genereres. Dette kan føre til korrekte løsninger på mere simple opgaver, såsom visse
opgaver i Programmering og Statistik med SAS, som hidtil har været formuleret. Dog kan
studerende opnå markant bedre resultater, hvis de har en grundlæggende forståelse af,
131
hvordan LLM’erne fungerer, samt hvilke elementer der gør en prompt effektiv. Selv en
grundlæggende viden om disse aspekter kan hjælpe dem med at formulere bedre prompts,
hvilket i sidste ende kan føre til mere præcise og relevante output samt forbedrede
opgavebesvarelser.
4.3 Den gode prompt til generering af SAS-kode
Med udgangspunkt i en konkret opgave fra eksamenssættet i kurset Programmering og
Statistik med SAS fra juni 2021, undersøges, hvordan man kan opnå det bedst mulige output
ved at anvende forskellige prompts til at generere den nødvendige SAS-kode for at besvare
følgende eksamensopgave:
2a) Træk sognenummeret ud af variablen sogn i datasættet
sogne_udd_kirke.sas7bdat i en numerisk variabel kaldet sognenummer. Brug både
datasteps og SQL.
Når opgaverne indeholder mere tekst, er det ofte nødvendigt at forenkle dem væsentligt for
at hjælpe LLM’erne med at løse dem. Den konkrete opgave er kortfattet formuleret, hvilket
gør det klart, hvad der skal gøres, og dermed giver LLM’erne gode betingelser for at løse
opgaven.
Ved brug af gratisversionen af ChatGPT, Model 3.5/4 den 21. oktober 2024, startes med en
simpel prompt, hvor der udover opgaveteksten tilføjes:
”Jeg arbejder i dataprogrammet SAS. Generér en kode til følgende opgave:”
Den genererede kode, som ses i Tabel 4, formår at identificere sognenummeret korrekt. Der
opstår dog et problem idet det oprindelige datasæt overskrives, hvilket kan føre til
problemer for de studerende i efterfølgende opgaver. Derudover bliver der ikke dannet
noget udskrift, hvilket kan gør det vanskeligt for de studerende at vurdere, om opgaven er
løst korrekt.

132
For at sikre, at svarene fra LLM’en ikke påvirkes af tidligere stillede spørgsmål og
prompter, skrives de forskellige prompts i separate samtaler uden hukommelse mellem
dem. Dette betyder, at der ikke er nogen historik i samtalerne. Ved at anvende elementer
beskrevet i Tabel 2 fra Afsnit 4.1, udvides prompten til at inkludere flere relevante detaljer.
Forståelsen af eksamensopgaven og de mulige løsningsmetoder i SAS er en vigtig del af
promptdesignet, da de studerende selv skal kunne ræsonnere sig frem til, at der er behov
for at oprette et nyt datasæt.
Tabel 4: Kode genereret af ChatGPT ved hhv. simpel og endelig prompt
Simpel prompt
Endelig prompt
data sogne_udd_kirke;
set sogne_udd_kirke;
sognenummer =
input(substr(sogn, 1, 4), 8.);
/* Ekstraher de første 4 tegn
fra 'sogn' og konverter til
numerisk */
run;
libname sasprog 'path'; /* Ensure the library is defined */
data sognenummer_data; /* New dataset name */
set sasprog.sogne_udd_kirke; /* Use the original dataset */
/* Extract the first 4 characters as a numerical variable */
sognenummer = input(substr(sogn, 1, 4), 8.); /* Convert the
extracted substring to a number */
run;
/* Print the data to verify */
proc print data=sognenummer_data (obs=10); /* Print the first
10 observations */
title "First 10 Observations of the New Dataset
sognenummer_data";
run;
Kilde: Output fra ChatGPT, Model 3.5
/4, oktober 2024
Den endelige prompt formuleres på engelsk, da ChatGPT har vist sig at være mere effektiv
til at generere SAS-kode, når der prompts på engelsk. Den endelige prompt lyder således:
“I am an economics student working on an assignment in the computer program
SAS. [Kontekst] The data set I'm working with is called sogne_udd_kirke and
contains information regarding the population's educational level in different
counties in Denmark. [Opgave] Please generate a SAS code to solve the following:
Create a new data set where the county number is extracted from the variable sogn
and made into a numerical variable called sognenummer. [Eksempel] The county
133
number is the first 4 characters in the variable sogn, and the number and the name
of the county are separated by a blank. [Format] I would like the code to include
both data steps and SQL. Additionally, please include a print statement to check that
the code is correct.”
I ovenstående eksempel bidrager den første linje til formateringen ved at fremhæve et
vigtigt aspekt: at være opmærksom på modtageren af en prompt.
Samme forsøg udføres i Copilot Enterprise, som genererer tilsvarende resultater. Den
største forskel ligger i, at Copilot ikke kommer med alle de pædagogiske forklaringer, som
ChatGPT gør, uanset om man siger, at man er studerende eller ej. Desuden printer ChatGPT
ofte kodeforklaringer for hver linje, som kan stå i SAS. Svaret på hhv. den simple og den
endelige prompt ses i Tabel 4. I tabellen ses kun den del af svaret, der inkluderer koden til
datasteps eftersom SQL-koden er løst på tilsvarende vis.
4.4 Systemprompt
Der er forskel på output fra ChatGPT og Copilot, da der er forskel på systemprompten. En
systemprompt er en tekst eller instruktion, der gives til en LLM for helt overordnet, og på
tværs af samtaler, at guide dens svar eller adfærd. Den hjælper med at definere konteksten
og formålet med interaktionen, hvilket sikrer, at modellen leverer relevante og præcise
oplysninger.
Ved sammenligning af gratisversionen af ChatGPT og Copilot Enterprise, kan der ved
samme prompt, og uden ændring i lokale brugerindstillinger ses tydelig forskel i output,
idet ChatGPT for SAS-kodeeksempler generelt udviser bedre pædagogiske evner i form af
forklaringer og formatering end Copilot.
I ChatGPT er det muligt at tilpasse instruktionerne i sin lokale ChatGPT-version. Således
kan man påvirke systemprompten ved at tilføje svar til følgende to spørgsmål; ”What would
you like ChatGPT to know about you to provide better responses?” og ” How would you
like ChatGPT to respond?”. Tabel 5 viser et eksempel på tilpasning af systemprompten som
gemmes i de generelle indstillinger.

134
Tabel 5: Customisering af systemprompt i ChatGPT
Custom Instructions
What would you like ChatGPT to know about you to provide better responses?
I am an economics student training my skills in the computer program SAS. I have created a
library in SAS called SASPROG, meaning that I have already run the code “libname
SASPROG ‘path’;” with success.
How would you like ChatGPT to respond?
When explaining something, the answer should be short and in bullets. When I ask about a
new SAS procedure, I would like a brief explanation of the procedure, what it is used for and
with a basic code example. When I ask about code, I would like a short explanation for all the
code lines in the code, ready to paste into SAS. All the original datasets I am working with is
saved in the library SASPROG, meaning that when pulling data from an original dataset, you
should always write SASPROG. Before the name of the dataset. When you create code, I would
NOT like you to save the new dataset in the SASPROG library.
Kilde: System
-prompt i ChatGPT
Med den ovenstående systemprompt kan ChatGPT nu løse opgaver, som den tidligere
havde problemer med, fejlfrit. Selvom prompten er på engelsk, kan opgaverne løses både
på dansk og engelsk. De tidligere udfordringer med at trække data og overskrive datasæt er
blevet løst, da prompten klart angiver, hvilket bibliotek data skal hentes fra, og præciserer,
at nye datasæt ikke skal gemmes i dette bibliotek.
Selvom det ikke er muligt at oprette en systemprompt direkte i Copilot, kan den indsættes
manuelt i starten af en samtale. På den måde genereres kodeoutput af samme kvalitet som
hos ChatGPT. Ved længerevarende opgaveløsning af samme type skal man dog huske at
indsætte prompten hver gang og i alle samtaler for at opretholde outputkvaliteten.
135
5 Anvendelse af GenAI i undervisningen
I foråret 2025 introduceres det nye kursus SAS og AI i Praksis, som erstatter det tidligere
Programmering og Statistik med SAS. Dette kursus har til formål at integrere GenAI i
undervisningen, hvilket åbner op for en mere effektiv læringsmetode. Ved at anvende
LLM’er kan undervisningen accelereres, idet grundlæggende programmeringsfærdigheder
kan tilegnes på halvdelen af den tidligere tid. Fokus vil være på essentielle koncepter som
syntaks, libname, SAS-biblioteker og dataoverskrivning, samt de områder, hvor LLM’erne
kan have begrænsninger.
5.1 Styrker og Svagheder ved LLM’er i undervisningen
Styrker:
xEffektivt læringsværktøj
xForklaring af kode og grundlæggende procedurer
xHjælp til at lære nye muligheder i kald, f.eks. optioner i Proc Sgplot
xGenerering af eksempeldata til mere kedelige opgaver
xAutomatisering af manuelle processer
Svagheder:
xVanskeligheder med komplekse matematiske og avancerede logiske opgaver
xUdfordringer med makroer og nye procedurer
xBegrænset viden af meget specifik og konkret kode
xSammenblanding med andre programmeringssprog
xFejl i optioner/statements, der lyder plausible, men ikke eksisterer, som f.eks. PROC
PYTHON vs. PROC R.

136
5.2 Opgaver før og nu
LLM’er har vist sig at være særdeles effektive til at løse eksamensopgaver, forudsat at der
er forståelse for effektiv udarbejdelse af prompter. Dette rejser spørgsmålet om
nødvendigheden af at revurdere opgaveformuleringerne. Studerende opfordres til at angive,
hvilken LLM de har anvendt til at besvare opgaverne.
Traditionelle opgaver, som har bestået af at finde fejl i koder eller forklare samtlige
kodelinjer i et program, har mistet deres relevans, da LLM’erne kan give præcise svar. I
stedet bør der fokuseres på projektbaserede opgaver, der fremmer dybere forståelse. Et
eksempel kunne være at give studerende en kode, som de skal optimere eller anvende til at
løse et konkret problem, som vist i Tabel 6.
Tabel 6: Eksempel på traditionel vs. ny opgave indenfor programmering
Traditionel opgave
Ny opgave
Forklar følgende kode:
data d2;
retain studium;
set d1;
if anydigit(tekst)=0 and
index(tekst,'Adgangskvotient')=0
and
index(tekst,'Standby-
kvotient')=0 and
tekst ne 'Ansoegninger'
then studium=tekst;
run;
1. Hvad gør følgende kode?
proc sgplot data=sashelp.class;
vbox weight;
run;
2. Rotér boxsplottet, så det er horisontalt fremfor
vertikalt.
3. Lav et nyt boxplot ud fra koden i opg. 1, hvor
du opdeler populationen efter køn, dvs. at du
har to boxplots i samme graf.
4. Sæt danske navne på akserne til boxplottet
genereret i opgave 3.
5. Find et andet kald til at generere boxplot end
proc sgplot og find ud af forskellen mellem
procedurerne.
Kilde
: Egne observationer
Den traditionelle opgave i Tabel 6 kan uden videre løses af GenAI og sættes ind i en
opgavebesvarelse uden at studerende selv forstår hvad koden gør. I den nye opgavetype
lærer studerende forskellige muligheder når man genererer boxplot. Derudover bliver der
stillet krav til at studerende tester koderne, der eventuelt genereres sammen med GenAI.

137
Eftersom GenAI endnu ikke kan producere output, der visuelt ligner SAS-output, bør der
stilles krav om at vise specifikt output fra SAS-kørsel. LLM’er kan generere visuelle
repræsentationer af tabeller og grafer, men ikke endnu genskabe SAS-output i præcist
samme format. Studerende kan derfor anmodes om at indsende screenshots fra SAS for at
demonstrere deres evne til at producere det ønskede output.
Ved at integrere GenAI i undervisningen ønskes ikke blot at effektivisere læringsprocessen,
men også at opgaver og eksamener tilpasses til den moderne teknologiske virkelighed.
6 Diskussion og konklusion
Integrationen af GenAI, som ChatGPT og Copilot, revolutionerer måden, vi underviser.
Disse værktøjer tilbyder betydelige fordele ved at frigive tid fra rutineprægede opgaver,
men de medfører også risici for de studerendes grundlæggende forståelse af emnet. Det er
essentielt, at undervisere fokuserer på at styrke de studerendes kritiske tænkning ved at
fremhæve både fordele og begrænsninger ved brugen af LLM’erne.
Selvom AI-modeller kan være nyttige til at guide studerende og løse simple opgaver, er det
op til den enkelte studerende at forstå, hvordan man analyserer et problem og formulerer
relevante spørgsmål. Uden en solid forståelse vil der være en risiko for, at outputtet fra
modellerne bliver utilfredsstillende, et fænomen ofte beskrevet som "garbage in, garbage
out." Derfor er det afgørende, at studerende lærer at formulere velovervejede prompts,
snarere end at prompte hovedløst.
Desuden er det vigtigt at overveje forskellene mellem versioner og LLM’er, samt
omkostningerne ved betalings- versus gratisversioner. Studerende, der investerer i en
avanceret LLM, opnår kun en fordel, hvis de kan udnytte den korrekt. En grundig og
veluddannet studerende vil ofte opnå bedre resultater med en gratis model end en mindre
engageret studerende, der betaler for en bedre version. Med de i skrivende stund fordele
ved betalingsversionerne, har studerende dog givet udtryk for, at de i eksamensperioder vil
138
sikre sig adgang til en betalingsudgave af LLM’erne. Derfor er det vigtigt at sikre, at
LLM’erne ikke får for stor indflydelse på (eksamens-)opgaver.
En yderligere udfordring er den hastige udvikling inden for generativ AI, hvor nye
funktioner og opdateringer ofte sker uden tydelig kommunikation. Det kan være svært at
kvantificere forskellene mellem gamle og nye versioner af samme produkt, hvilket stiller
krav til både undervisere og studerende om at holde sig ajour med de nyeste ændringer.
Dette studie fremhæver således både mulighederne og udfordringerne ved at integrere
generativ AI i undervisningen i anvendt statistik. Selvom AI-værktøjerne åbner op for nye
metoder til at arbejde med kodning og dataanalyse, kræver det en tilpasning af
undervisningens opgave- og læringsmål for at sikre optimal læring. Fremtidig forskning vil
fokusere på at undersøge effekterne af integrationen af generativ AI i undervisningen i
anvendt statistik, hvilket kan bidrage til en dybere forståelse af, hvordan generativ AI kan
forbedre læringsprocesser.

139
Bilag
Bilag 1 Output fra ChatGPT’s kodefortolker
Et eksempel på ChatGPT’s kodefortolker fremgår af Figur B1, hvor et datasæt med en
industriel opdeling af 223 amerikanske virksomheder inden for materiale-sektoren blev
uploadet til OpenAI’s LLM, ChatGPT.
Figur B2: Eksempel på output genereret vha. ChatGPT’s kodefortolker
Kilde: Eksempel fra ChatGPT’s plus-version (tidligere pro), december 2024
Ved hjælp af kodefortolkeren visualiserede ChatGPT dataene ved at generere Python-
koden som vist i Figur B2. Hvis nødvendigt kan denne kode efterfølgende vha. LLM’en
omskrives til andre programmeringssprog som STATA, R eller SAS og dermed let
integreres i eksisterende arbejde.

140
Figur B2: Eksempel på Python-kode genereret af ChatGPT’s kodefortolker
Kilde: Eksempel fra ChatGPT.
Bilag 2 Eksempel med delopgave fra eksamensopgave
Tabel B1 viser flere af de prompter som ligger imellem den simple prompt og den
endelige prompt i Afsnit 3.3. Her skal bemærkes, at den tredje og den femte prompt
indeholder samme mængde af information og er bygget op på tilsvarende vis, med den
forskel at den ene prompt er på dansk og den anden på engelsk. Selvom de to prompter
indeholder den samme information, formår den engelske ChatGPT at oprette et nyt
datasæt på korrekt måde, og kommer derudover med en tabeltitel, hvilket ikke er tilfældet
med den danske prompt. I tabellen ses kun besvarelsen med datasteps, eftersom den del af
besvarelsen, som danner SQL-koden er tilsvarende.
Opgaveformulering: Træk sognenummeret ud af variablen sogn i datasættet
sogne_udd_kirke.sas7bdat i en numerisk variabel kaldet sognenummer. Brug både
datasteps og SQL

141
Tabel B1: Eksempel på ChatGPT’s kodesvar afhængigt af prompt
Prompt
Kodesvar
Jeg arbejder i dataprogrammet SAS. Generer kode
en kode til følgende opgave: Træk sognenummeret
ud af variablen sogn i datasættet
sogne_udd_kirke.sas7bdat i en numerisk variabel
kaldet sognenummer. Brug både datasteps og SQL.
data
sogne_udd_kirke;
set sogne_udd_kirke;
sognenummer = input(substr(sogn, 1, 4), 8.); /*
Ekstraher de første 4 tegn fra 'sogn' og konverter
til numerisk */
run;
Jeg er en økonomistuderende, som arbejder i
dataprogrammet SAS. Datasættet, jeg
arbejder i,
hedder sogne_udd_kirke og indeholder oplysninger
om befolkningens uddannelsesniveau og bopæl
fordelt i sogne. Jeg har lavet et libname, som
hedder sasprog. Generer en kode, som trækker
sognenummeret ud af variablen sogn i en numerisk
variabel kaldet sognenummer. Jeg vil have koden i
både datasteps og SQL og et udprint for at se om
koden virker
data sasprog.sogne_udd_kirke;
set sasprog.sogne_udd_kirke;
sognenummer = input(substr(sogn, 1, 4), 4.)
/* Ekstraher de første 4 tegn fra 'sogn' og
konverter til numerisk */
run;
proc print data=sasprog.sogne_udd_kirke
(obs=10); /* Udprint de første 10 observationer for
at kontrollere */
var sogn sognenummer;
run;
Jeg er en økonomistuderende, som arbejder i
dataprogrammet SAS. Datasættet, jeg arbejder i
hedder sogne_udd_kirke og indeholder oplysninger
om befolkningens uddannelsesniveau og bopæl
fordelt i sogne. Jeg har lavet et libname, som
hedder sasprog, dvs. at j
eg forinden har kørt
koden: libname sasprog'path'; Generer en kode til
følgende opgave: lav et nyt datasæt, hvor
sognenummeret trækkes ud af variablen sogn og
laves til en numerisk variabel kaldet sognenummer.
Jeg vil have koden i både datasteps og SQL samt et
udprint for at se om koden virker.
data sasprog.nyt_datasaet;
set sasprog.sogne_udd_kirke
/* Træk sognenummeret ud af 'sogn' variablen
*/
sognenummer = input(scan(sogn, 1, ' '), 8.);
run;
/* Udprint for at se om koden virker */
proc print data=sasprog.nyt_datasaet (obs=10);
run;
Jeg arbejder i
dataprogrammet SAS. Datasættet,
jeg arbejder i hedder sogne_udd_kirke og
indeholder oplysninger om befolkningens
uddannelsesniveau og bopæl fordelt i sogne. Jeg
har lavet et libname, som hedder sasprog, dvs. at
jeg forinden har kørt koden: libname sasprog'path';
Generer en kode til følgende opgave: lav et nyt
datasæt, hvor sognenummeret trækkes ud af
/* DATA step */
data sasprog.sogne_udd_kirke_ny;
set sasprog.sogne_udd_kirke;
/* Antager, at sognenummeret er de første cifre
i sogn variablen */
sognenummer = input(scan(sogn, 1, ' '), 8.); /*
Udtræk det første ord (antager det er nummeret) */

142
variablen sogn og laves til en numerisk variabel
kaldet sognenummer. Jeg vil have koden i både
datasteps og SQL samt et udprint for at se om
koden virker.
run;
/* Udprint for at tjekke, om det virker */
proc print data=sasprog.sogne_udd_kirke_ny
(obs=10);
var sogn sognenummer;
run;
I am an economics student working on an
assignment in the computer program SAS. The data
set I'm working with is called sogne_udd_kirke and
contains information regarding the population's
educational level in different counties in Denmark.
Please generate a SAS code to solve the following:
Create a new data set where the county number is
extracted from the variable sogn and made into a
numerical variable called sognenummer. The
county number is the first 4 characters in the
variable sogn, and the number and the name of the
county are separated by a blank. I would like the
code to include both data steps and SQL.
Additionally
, please include a print statement to
check that the code is correct.
libname sasprog '
path
'; /* Ensure the library is
defined */
data sognenummer_data; /* New dataset name */
set sasprog.sogne_udd_kirke; /* Use the
original dataset */
/* Extract the first 4 characters as a numerical
variable */
sognenummer = input(substr(sogn, 1, 4), 8.); /*
Convert the extracted substring to a number */
run;
/* Print the data to verify */
proc print data=sognenummer_data (obs=10); /*
Print the first 10
observations */
title "First 10 Observations of the New Dataset
sognenummer_data";
run;
Kilde:
Interaktion med ChatGPT’s gratisversion, oktober 2024

De spildte talenter.
Blandt de mange unge danske fodboldtalenter får nogle muligheden for at spille på
DBU’s udvalgte hold, - men er chancen lige stor for alle?
Steen Andersen
Emeritus, Institut for Økonomi, BSS, Aarhus Universitet, e-mail: sta@econ.au.dk
Abstract: Det kræver et uomtvisteligt talent at blive udvalgt – og talentet udvikler sig
over tid. Det betyder, at når man i DBU opererer med årgange, talenter U13-15 og
landshold U16-21, så har de, der er født først på året en fordel. I dette papir
anvendes data fra DBU’s landsholdsdatabase og fokus er på årgangene født mellem
1960 og 2005. Der skelnes ikke mellem hvilke landshold (U16-21) man har spillet på.
Der inddrages desuden det aspekt om man har spillet på herrer A-landsholdet.
Hvornår man er født året har, (1) større betydning for drenge end for piger, (2)
større betydning for årgang 2005 end for årgang 1960 og (3) heldigvis lidt mindre
betydning for om man får debut på et A-landshold.
Fødselsårgangene 1960-2005, fordelt på fødselsmåned.
Nedenstående grafiske illustration indikerer, at fordelingen af fødselsmåned, stort set
er uændret i perioden. I begyndelsen af perioden er fødsler i april og maj hyppigere
forekomne end i slutningen af perioden. (18,2% i 1960-1979 og 17,0% i 1990-2005).
Og begyndelsen af perioden er fødsler i juli og august mindre hyppigt forekomne end
i slutningen af perioden. (16,4% i 1960-1969 og 17,6% i 1990-2005).
Fordeling af fødte i perioden hen over året er ikke helt jævn, - der er færre fødte i de
kolde måneder.
143

DBU’s udvalgte blandt fødselsårgangene 1960-2005, fordelt på fødselsmåned.
Nedenstående illustrerer tydeligt, at DBU’s udvalgte på ingen måde afspejler
fordelingen af fødselsmåneder i baggrundsbefolkningen. En der er født i januar har i
forhold til en der er født i december 2,4 gange større chance for at være udvalgt
(304/248281)/(122/236627) til et at DBU’s ungdomslandshold.
Der er en markant lavere sandsynlighed for at være udvalgt jo senere på året man er
født, - dog afviger de som er født i august ved at have en relativ større chance for at
være udvalgt end de, der er født i juni og juli måned og nogenlunde samme chance
som de, der er født først på året.
Vækstkurver for drenge.
Det er ikke fødselsmåned i sig selv, men den fysiske og den mentale fremtoning, der
er nogle af mange afgørende parametre for om man er blandt DBU’s udvalgte.
Ud fra nedenstående kan man argumentere for, at den forventede højde for 15-årige
drenge er 172,0 cm med en standardafvigelse på 7,5 cm. Væksten per år omkring de
15 år er cirka 5 cm, dvs. den forventede højde for U15-drenge født i januar og
december er henholdsvis 174,3 cm og 169,7 cm.
144

Blandt januar-drengene har 72%, 46% og 22% henholdsvis en højde på over 170,
175, og 180 cm.
Blandt december-drengene har 48%, 24% og 8,5% henholdsvis en højde på over 170,
175 og 180 cm.
Hvilket betyder, at oddset for, at det er en januar-dreng er 1,5, 1,9 og 2,6 givet en
højde på henholdsvis 170, 175 og 180 cm – odds som kan sammenholdes med den
2,4 gange større chance nævnt ovenfor – og dermed indikere, at DBU’s
udvælgelsesprocedure svarer til kun at udvælge blandt spillere, der er 180 cm eller
højere!
145

DBU’s udvalgte fordelt på køn og årgang og den dag på året de er født.
Nedenstående tyder på, at de udvalgte år for år er født lidt tidligere på året end den
foregående årgang, mere udpræget for drenge end for piger.
En forklaring herpå kunne være, at der fra 1970 og frem afvikles flere og flere
U16/17 kampe, hvor favoriseringen kan antages at være større end ved U18+ kampe.
Antallet af kampe varierer meget fra år til grundet afvikling af slutrunder.
Denne sammenhæng kunne man ”koge” ned til at;
Dag på året man er født har signifikant betydning i denne sammenhæng - de udvalgte
herrer er i gennemsnit født 20 dage tidligere på året end de udvalgte kvinder og dette
rykker 1,4 dag per årgang, for både herrer og kvinder.
Gennemsnit for ”dag” på året er ved periodens begyndelse tæt på det forventede 183 (
(1+365)/2) og derefter signifikant faldende.
146

Hvis man sammenholder spillere med 1-9 og 10+ ungdomslandskampe ser man
- at de etablerede (10+) er født lidt tidligere på året (ikke signifikant), men
væsentligst, at der over tid for kvindernes vedkommende ikke sker et ryk for hver
årgang mens der for herrernes vedkommende er sket et ryk på -1,12-1,80·(1-0,69) = -
1,68 per årgang.
Dette er illustreret lidt mere nuanceret nedenfor:
En forklaring herpå kunne være, at scouts/trænere tilknyttet kvindelandsholdene er
bedre til at spotte og udvikle talenter, at der er langt færre piger end drenge*), der
spiller fodbold eller det faktum, at pigers vækstkurve flader ud tidligere end drenges.
*) I 2023 var 62% af DBU’s medlemmer under 19 år og 80 % af DBU’s medlemmer
var drenge/mænd.
147

DBU er opmærksom på problematikken og har initiativer, der understøtter såkaldte
”late developers”.
Har positionen på banen nogen betydning?
For herrer, vist nedenfor, har dag på året større betydning over tid jo tættere man er
på målet (p-værdi ved test er 0,027). Samlet set for herrer reduceres dag født på året
med 1,3. For målmænd er det med 2,3, for forsvarer 1,4, for midtbane 0,9 og for
angribere 0,6.
148

Hvem er det så, der får debut på A-landsholdet?
Fra DBU’s spillerdatabase uddrages de 838 spillere der til dato (december 2024) har
haft debut på herrer A-landsholdet.
Der er set bort fra de 17 spillere der udgjorde vikar-landsholdet samt 4 kvinder, der
fejlagtigt er blevet rubriceret under herrer A-landsholdet.
Fra første A-landskamp og frem til seneste (nr. 914) har i alt 838 spillere optrådt på
A-landsholdet.
For disse spillere ser man også, som for ungdomsspillerene, at de over tid er født
tidligere på året:
,
Det er dog ikke så markant som for herrer ungdomspillerne årgang 1960-2005. De
var i gennemsnit født dag 154 og faldet per år var 1,5 dag. For de samme årgange, der
A-debutere var tilsvarene tal dag 162 og med et insignifikant fald på 0,6 dag per år:
149

Det skal dog pointeres, at dag 162 er signifikant lavere end baggrunds populationens
dag 183:
Forskellen på 162 og 183 svarer til at man havde udvalgt helt ligeligt blandt talenter
født mellem 1. januar og 20. november og havde set helt bort fra dem, der var født
mellem 21. november og 31. december – det er omkring 10% af en årgang!
Opdelt på hvor etablere spillerne er (få, nogle eller mange A-landskampe) er der
ingen yderligere fund. Med hensyn til spillernes position på banen er der en tendens
(men ikke signifikant) til, at målmænd født tidligt på året favoriseres mere end de på
andre positioner.
Konklusion.
Det er primært for de yngste ungdomsherrer (og specielt målmand/forsvar) at de, der
er født tidligt på året, favoriseres. Når man bevæger sig fra U16 til U21-landshold
bliver den relative forskel i højde (vækst) på om man er født tidligt eller senere på
året mindre og mindre. De tidlige fravalg på udvalgte hold af talenter, der er født sent
på året, har konsekvens for det fremtidige karriereforløb.
For herrer A-landsholdsspillere svarer denne favorisering til, at man ser bort fra 10 %
af en årgang.
Talentet kan være dog være meget åbenlyst, spilleren kan være vedholdende og for
nogens vedkommende modnes/hærdes man måske af de udfordringer, man som ”late
developper” stilles overfor i teenageårene.
Som tidligere nævnt er fødselsdatoen ikke eneste indikator, for om man er ”late
developper”. Fokus her, har udelukkende været at se på spillere på udvalgte hold i
DBU-regi. Favoriseringen af ”tidligt fødte”, der spiller på lavere niveau, er ikke
berørt her. Man kunne forstille sig, at der hvor talentet ikke rækker eller der hvor
opmærksomheden fra træner-side ikke er til stede, - der løber de ”sent fødte” hurtigt
panden imod muren og lader på et tidspunkt støvlerne blive på hylden.
150
151
Hvem har gode matematikkundskaber trods matematikskræk
Anders Milhøj
Anders.milhoj@econ.ku.dk
I PISA undersøgelsen spørges til elevens egen holdning til matematikkundskaber med
spørgsmålet: ST268Q04JA = Agree/disagree: Mathematics is easy for me. Svarene gi-
ves på en skala fra 1 til 4:
1. Strongly disagree
2. Disagree
3. Agree
4. Strongly agree
Dette spørgsmål er ikke besvaret af 1071 elever.
Vi sammenholder svarene på dette spørgsmål med den gennemsnitlige matematik-
score, score_m, der er gennemsnittet af de 10 plausible values, pv1math - pv10math.
Alle er tildelt en matematikscore. Gennemsnittet af matematikscoren i Danmark er
478.8. Ud fra dette tal inddeles eleverne i to grupper, ‘høj’ og ‘lav’, alt efter om scoren
er over eller under dette gennemsnit. Bemærk, at data er indsamlet stratificeret efter
indvandrerbaggrund med overrepræsentation af skoler med mange ikke-etnisk danske
elever. Dette giver en vis overrepræsentation af bogligt svage elever, så gennemsnittet
478.8 er noget lavere end det sande gennemsnit af danske skoleelevers matematik-
score.
Tabellen viser fordelingen af svarene på dette spørgsmål sammenholdt med matema-
tikscoren kategoriseret i høj/lav. De nederste tal i cellerne er rækkeprocenter.
De fleste elever, der vurderer matematik som let (Agree eller Strongly agree), har en
høj matematikscore. Omvendt har en stor del af de elever, der finder matematik svært
(Disagree eller Strongly Disagree), en lav matematikscore, hvilket jo ikke kan for-
bavse. Dette indikerer en sammenhæng mellem elevernes selvopfattelse og deres fakti-
ske præstationer i matematik.
Der findes alligevel 166 atypiske elever, der har svaret ‘Strongly disagree’ på spørgs-
målet om egne matematikevner, men som alligevel har en matematikscore over gen-
nemsnittet, mens de 600 andre elever, der har svaret ‘Strongly disagree’, har den mere
forventede matematikscore under gennemsnittet. Disse 166 elever betegnes i det føl-
gende som ‘Atypiske’, mens de 600. for hvem matematikevnerne svarer bedre til deres
egen fornemmelse af lave matematikkundskaber, betegnes ‘Normale’.

152
Mathematics is easy for me.
Høj
Lav
Total
Strongly disagree
166
21.67
600
78.33
766
Disagree
658
38.37
1057
61.63
1715
Agree
1307
66.31
664
33.69
1971
Strongly agree
558
82.42
119
17.58
677
Total
2689
2440
5129
Frequency Missing = 1071
Blandt de 766 elever med matematikskræk er kønsfordelingen meget skæv med 68%
piger, men kønsfordelingen mellem atypiske elever og normale elever er helt ens, p =
0.95.
I det følgende sammenlignes de to gruppers svar på andre relevante spørgsmål i data-
sættet. Disse andre spørgsmål er først og fremmest udvalgt ved at screene for deres
evne til at adskille de to elevgrupper med resp. høj og lav matematikscore blandt de
elever, der har svaret ‘Strongly disagree’ på spørgsmålet om egne matematikevner, ved
hjælp af en SAS-makro. Listen over spørgsmål er dog på ingen måde komplet, fx er
der kun valgt et enkelt spørgsmål af mange stort set ensartede spørgsmål. I de viste re-
sultater er antal observationer forskellige, da der er forskelligt bortfald på de stillede
spørgsmål.
Socioøkonomiske forklaringer
I datasættet findes en indikator for hjemmets resurser, ESCS, som er sammensat af op-
lysninger om forældrenes uddannelse, indkomst samt elevens angivelser af akademi-
ske/kulturelle ting i hjemmet, fx. musikinstrumenter og bøger. Dette indeks er konstru-
eret som en standardiseret normalfordelt variabel. I en logistisk regressionsanalyse ses,
at denne variabel har stor betydning for sandsynligheden for at opnå atypisk høj mate-
matikscore trods skrækken for matematik.
Figuren viser at denne sandsynlighed vokser markant til ca. 50% for eleverne med hø-
jest værdi af ESCS. Forældre med overskud burde altså bruge noget af deres overskud
på at bearbejde deres børns matematikskræk.
Den anden figur illustrerer samme sammenhæng ud fra en anden tankegang. Selvom
en eventuel kausalitet nok ikke kan gå fra matematikscoren til matematikskræk, er det

153
interessant at se, hvordan ESCS er forskellig for de atypiske elever og de normale ele-
ver. Gennemsnittet af ESCS er 0.08 for normale elever og 0.48 for de atypiske elever –
og denne forskel er klart signifikant t = 5.6. Figuren sammenholder de to histogram-
mer for de atypiske hhv. normale elever.
0.0
0.2
0.4
0.6
0.8
1.0
Probability
-4 -3 -2 -1 0 1
2
Index of economic, social and cultural status
Predicted Probabilities for Type = Atypiske
With 95% Confidence Limits
Distribution of ESCS
Kernel
Normal
Normale
Atypiske
Type
0
5
10
15
20
25
Percent
0
5
10
15
20
25
Percent
Normale
0
10
20
30
Percent
0
10
20
30
Percent
Atypiske
-4 -2 0 2
Indexof economic,social and cultural status

15
Indvandrerbaggrund
Immigrant baggrunden er angivet på tre trin efter en OECD definition.
Immigrant background
Atypiske
Normale
Total
Native student
144
24.08
454
75.92
598
Second
-
Generation student
13
11.40
101
88.60
114
First
-
Generation student
7
17.50
33
82.50
40
Total
164
588
752
Frequency Missing = 14
De fleste atypiske elever er etnisk danske, mens normale elever har en højere andel af
første og anden generations elever. Denne tabel er relateret til den næste tabel om
sprog.
Det talte sprog i hjemmet
Language at home
Atypiske
Normale
Total
Language of the test
151
23.78
484
76.22
635
Other language
15
11.54
115
88.46
130
Total
166
599
765
Frequency Missing = 1
En dobbelt så stor andel af de elever, der trods matematikskræk, opnår en høj matema-
tikscore blandt de elever, der dansk i hjemmet, end blandt andre elever. I den forbin-
delse skal man huske, at et andet sprog jo godt kan være fx engelsk, så et andet sprog
ikke nødvendigvist er et tegn på et ikke-akademisk hjem. Tallene kunne dog godt tyde
på, at en del af matematikopgaverne er så verbalt formulerede, at elever, der ikke er så
gode til dansk, har et handicap i matematikopgaverne.

155
Pjæk
I skipped a whole school day the last two weeks
Atypiske
Normale
Total
Never
134
25.43
393
74.57
527
One or two times
26
16.56
131
83.44
157
Three or four times
2
6.45
29
93.55
31
Five or more times
4
10.26
35
89.74
39
Total
166
588
754
Frequency Missing = 12
Atypiske elever pjækker mindre end normale elever. Nu er det måske en overfortolk-
ning at opfatte dette spørgsmål, som et spørgsmål om pjæk, for fravær kunne vist efter
spørgsmålets formulering også være sygdom. Men det er dog påfaldende, at elever helt
uden fravær har en højere sandsynlighed for et godt matematikresultat end elever med
fravær.
Elevens mening om lærerens arbejde
My teachers are interested in my wellbeing
Atypiske
Normale
Total
Strongly disagree
1
2.86
34
97.14
35
Disagree
13
14.29
78
85.71
91
Agree
57
22.35
198
77.65
255
Strongly agree
25
33.33
50
66.67
75
Total
96
360
456
Frequency Missing = 310

156
Atypiske elever føler i højere grad, at deres lærere er interesserede i deres velbefin-
dende sammenlignet med normale elever. Det har altså en positiv indflydelse på deres
resultater, at de føler, at læreren oprigtigt interesserer sig for deres velbefindende. Det
er også glædeligt, at det ikke er så mange, der føler, at lærerne ikke interesserer sig for
deres velbefindende.
Udenadslæren er en god ting!
Memorize mathematical rules
Atypiske
Normale
Total
Never or almost never
12
21.82
43
78.18
55
Less than half of the
lessons
12
16.67
60
83.33
72
About half of the lessons
21
19.63
86
80.37
107
More than half of the lessons
24
24.00
76
76.00
100
Every lesson or almost every lesson
26
35.62
47
64.38
73
Total
95
312
407
Frequency Missing = 359
Hvis der indgår elementer af ’klassisk’ udenadslæren i matematikundervisningen, kla-
rer eleverne sig bedre. Hvad der menes med mathematical rules i niende klasse, er
selvfølgelig uklart, for det kan vel være alt fra den lille tabel til formlen for en cirkels
areal, så det skal vel fortolkes som, at et fast ståsted øger mulighederne for at løse op-
gaver.
Løse ligninger og andre aspekter af matematikundervisningen
Ligningen i spørgsmålet, 2(x+3)=(x+3)(x-3), er i øvrigt lidt drilsk, så det er ret oplagt
at løse den forkert ved at overse løsningen x = í3. Men det er oplagt, at hvis undervis-
ningen udfordrer eleverne, løftes niveauet. Det sker heldigvis i mere end halvdelen af
skolerne, hvis man skal bedømme det efter elevernes svar, hvad der dog kan være
tvivlsomt

157
Solving an equation like 2(x+3)=(x+3)(x-3)
Atypiske
Normale
Total
Frequently
53
25.48
155
74.52
208
Sometimes
28
21.05
105
78.95
133
Rarely
5
17.24
24
82.76
29
Never
1
4.35
22
95.65
23
Total
87
306
393
Frequency Missing = 373
Et overordnet spørgsmål om Quality of mathematics instruction, hvor der svares på en
skala fra et til ti, giver en signifikant sammenhæng med en odds ratio på 1.119. Sam-
menhængen illustreres ved følgende effectplot, der viser, at hvis eleverne synes mate-
matikundervisningen er best possible er sandsynligheden for at få en høj matematik-
scoren i PISA undersøgelsen ca 30%, mens den kun er knapt 20% for elever, der me-
ner undervisningen er ringe.
0.0
0.2
0.4
0.6
0.8
1.0
Probability
2 6
Best mathematics instruction possible10
ST272Q01JA
Predicted Probabilities for Type = Atypiske
With 95% Confidence Limits

158
Computer i matematiktimer
How often using computer mathematics systems in school
Atypiske
Normale
Total
Frequently
56
32.00
119
68.00
175
Sometimes
24
16.55
121
83.45
145
Rarely
8
20.51
31
79.49
39
Never
2
9.52
19
90.48
21
Total
90
290
380
Frequency Missing = 386
Eleverne motiveres åbenbart af brug af IT-baserede værktøjer i matematikundervisnin-
gen, så heldigvis sker det på de fleste skoler i datasættet. Det er også påfaldende, at
elever, der ofte bruger computer til matematik, klarer sig bedre, end elever, der ikke
gør det, så de fordele ved udenadslæren, der blev beskrevet tidligere, bliver ikke hæm-
met ved brug af IT-værktøjer.
Men svarene på andre spørgsmål viser, at brug af mobiltelefoner til at følge med på so-
ciale medier i timerne er skadeligt. Det er altså ikke godt at være ’på’ i mere end halv-
delen af timerne, for det mindsker sandsynligheden for at opnå en god matematikscore.
De atypiske elever er mere enige i, at der skal sættes regler for privat brug af mobilte-
lefoner i timerne, end de normale elever med matematikskræk.
En anden ramme for spørgsmål viser, at elever, der anvender IT-værktøjer ved lektie-
læsning hjemme, klarer sig bedre end elever, der sjældent gør det. Svarene på en
række spørgsmål viser også, at elever der mere end to timer dagligt, er på sociale me-
dier eller bruger skærme til underholdning, fx spil eller film, klarer sig dårligere. Men
dette resultat er bestemt ikke entydigt, hvad følgende tabel viser.

159
Facebook®, Instagram®,
Twitter®, emails, chat
Atypiske
Normale
Total
No time at all
11
25.58
32
74.42
43
Less than 1 hour a day
24
21.43
88
78.57
112
Between 1 and 3 hours a day
56
37.09
95
62.91
151
More than 3 hours and up to 5 hours a day
36
21.05
135
78.95
171
More than 5 hours and up to 7 hours a day
17
15.04
96
84.96
113
More than 7 hours a day
7
12.96
47
87.04
54
Total
151
493
644
Frequency Missing = 122
Ihærdighed og glæde ved skolen
I stop when work becomes too difficult
Høj_disagree
Normal
Total
Strongly disagree
6
35.29
11
64.71
17
Disagree
33
42.86
44
57.14
77
Neither agree nor disagree
29
20.14
115
79.86
144
Agree
17
15.32
94
84.68
111
Strongly agree
3
11.11
24
88.89
27
Total
88
288
376
Frequency Missing = 390
160
De ret få elever, der hurtigt giver op, klarer sig dårligt, og et yderligere spørgsmål om
at fuldføre opgaver, der viser sig komplicerede, viser samme klare tendens. Glæden
ved at lykkes med noget er altså væsentlig for lysten til at lære mere og bedre, mens
gentagne fiaskoer giver eleverne lyst til at opgive det hele. Et yderligere spørgsmål vi-
ser, at elever, der har lysten til at lære noget nyt, lærer sig bedre, hvilket nok kan til-
skrives samme tendens, at faglig mistrivsel ødelægger indlæringen.
Konklusion
VIVE udgav i november 2024 en rapport, Jóelsdóttir, L.B. & Østergaard, K.:
PISA 2022 – Delrapport matematik. Danske 15-åriges oplevelse af deres matematik-
undervisning – og deres motivation, selvsikkerhed, matematikangst og mindset. Den
omhandler lignende emner og sammenligner bla. med andre OECD lande med tilsva-
rende konklusioner ved brug af gennemsnit og andele blandt hele populationen af alle
elever.
I dette symposieindlæg er der udelukkende fokus på elever, der trods matematikskræk
alligevel klarer sig godt i PISAs matematiske spørgsmål. Mange af de viste sammen-
hænge er oplagte, og de er som oftest netop sammenhænge og ikke kausaliteter. Da de
gode matematikevner hos en elev med matematikskræk kan være et tegn på, at eleven
trods alt er en god, ihærdig og dygtig elev, der bare fejlagtigt føler ikke helt at kunne
slå til i matematik. Overvægten af piger i gruppen med matematikskræk kunne tyde
på, at det kunne være tilfældet, så det ville være en god idé at undersøge om effekterne
i de mange tabeller vekselvirker med kønnet.
161
Aktivitetsdeltagelse, dødelighed og hospitalsindlæggelser: Et dansk kohortestudie
Linda Juel Ahrenfeldt1, Tobias Anker Stripp1,2,3, Jens Søndergaard1, og Sören Möller4,5
1) Forskningsenheden for Almen Praksis, Institut for Sundhedstjenesteforskning,
Syddansk Universitet, Esbjerg-Odense, Danmark
2) The Human Flourishing Program, Quantitative Institute for Social Sciences,
Harvard Universitet, Cambridge, MA, USA
3) Center for Videnskab og Tro, Københavns Universitet, København, Danmark
4) Open Patient data Explorative Network, Odense Universitetshospital, Odense,
Danmark
5) The OPEN Research Unit, Klinisk Institut, Syddansk Universitet, Odense,
Danmark
Baseret på artiklen Impact of activity participation on the risk of mortality and
hospitalisations in Danish men and women: Insights from REGLINK-SHAREDK 1
accepteret i Epidemiology i oktober 2024.
Introduction
Med længere levetid og en voksende ældrebefolkning er det vigtigt at fokusere på at
forbedre sundheden blandt de ældre. Banebrydende studier af Berkman og Syme i 1979
2 og House et al. i 1988 3 viste den beskyttende effekt af sociale relationer på
dødelighedsrisikoen. Efterfølgende epidemiologiske undersøgelser, herunder
systematiske oversigtsartikler og meta-analyser, har konsekvent bekræftet
sammenhængen mellem social tilknytning, sundhed og dødelighed 4-6.
Mens social tilknytning omfatter forskellige former for engagement i det sociale
miljø, har en specifik forskningsgren undersøgt formel social deltagelse, som
kendetegnes ved aktiv involvering i etablerede organisationer 7. Det har dog vist sig, at
formel social deltagelse har forskellige sundhedseffekter afhængigt af typen af aktivitet.
For eksempel er frivilligt arbejde forbundet med lavere dødelighed 8. Omvendt er
omsorg eller pleje af familiemedlemmer ofte stressende og kan påvirke både fysisk og
mental sundhed negativt 9, og nogle studier tyder på at omsorg og pleje hænger sammen
162
med højere dødelighed 10. Forskning, der undersøger sammenhængen mellem
aktivitetsdeltagelse og brug af sundhedsydelser, såsom indlæggelser, er stadig
begrænset.
For nyligt undersøgte vi sammenhængen mellem deltagelse i en religiøs
organisation samt dødelighed og indlæggelser blandt 2987 danskere på 40 år og derover,
som blev interviewet fra 2004-2007 og fulgt i de danske registre frem til 2018 11. Vi
observerede, at personer, der havde deltaget i religiøse organisationer inden for den
seneste måned, havde en 30 % lavere dødelighed, med en mere markant sammenhæng
blandt kvinder (44 %), men ingen signifikant sammenhæng blandt mænd. Omvendt
havde mænd, der deltog i en religiøs organisation, 33 % færre indlæggelser per år, mens
en lignende sammenhæng ikke blev observeret blandt kvinder 11. Selvom undersøgelsen
bidrog til den begrænsede forskning om de potentielle sundhedsmæssige fordele ved
deltagelse i religiøse organisationer, står ét spørgsmål tilbage: Skyldes disse
sundhedseffekter det at være religiøst aktiv, eller kan vi finde lignende sammenhænge
for andre aktiviteter?
I dette studie undersøger vi sammenhængen mellem aktivitetsdeltagelse og
dødelighed og hospitalsindlæggelser blandt midaldrende og ældre danskere. Vores
hypotese er, at formel social deltagelse er forbundet med lavere dødelighed og færre
indlæggelser, med de stærkeste sammenhænge for dødelighed blandt kvinder og
indlæggelser blandt mænd.
Metoder
Datakilde og studiepopulation The Survey of Health, Ageing and Retirement in
Europe (SHARE) er en omfattende survey-undersøgelse, der indsamler information om
den aldrende befolkning i Europa gennem personlige interviews 12. SHARE indsamler
bl.a. data om sundhed, økonomisk status og sociale faktorer for personer på 50 år og
derover samt deres ægtefæller eller partnere uanset alder. Undersøgelsen startede i 2004-
2005 og er siden da gennemført hvert andet år 12. I REGLINK-SHAREDK-projektet er
danske SHARE-data blevet koblet med danske registerdata på Danmarks Statistik,
hvilket skaber et unikt datasæt, der kombinerer subjektive interviewdata med objektive
registerdata 13.
163
I denne longitudinelle undersøgelse inkluderede vi danske mænd og kvinder på 40 år
eller ældre, som havde deltaget i mindst én SHARE-interviewrunde i enten 2004-2005
eller 2006-2007. Vi ekskluderede 2 personer under 40 år, 54 personer uden svar på
spørgsmål om aktiviteter, 29 personer hvis survey-data ikke kunne kobles til de danske
registre, samt én person uden interviewdato, hvilket resulterede i en studiepopulation på
2987 personer, identisk med studiepopulationen i vores tidligere artikel 11.
Dødelighed og indlæggelser De danske SHARE-data blev koblet til nationale
sundhedsregistre ved hjælp af CPR-numre. Vi anvendte tre registre: CPR-registret,
Dødsårsagsregisteret og Landspatientregisteret.
Aktivitetsdeltagelse Data om aktivitetsdeltagelse kom fra SHARE-interviews, hvor
deltagerne blev spurgt om deres deltagelse i syv forskellige aktiviteter indenfor den
sidste måned. Deltagerne blev også spurgt om hyppigheden af disse aktiviteter og deres
årsager til deltagelse.
Statistiske analyser Vi anvendte generaliserede lineære modeller med pseudo-
observationsbaserede estimater til at evaluere dødelighedsforskelle ved 90 års alderen
for personer der havde deltaget i aktiviteter indenfor den seneste måned ift. dem der ikke
havde 14,15. Denne metode anvender en cloglog-regressions-model sammen med
Kaplan-Meier-estimatoren ܵ(ݐ)på valgte tidspunkter ݐ(i vores tilfælde ݐଵ=90 år) til
at estimere relative forskelle:
݈݈ܿ݃݃൫ܵ(ݐ)൯=log
൫െ݈݃൫ܵ(ݐ)൯൯ =ߚ்ܼ
og en logistisk regressionsmodel sammen med Aalen-Johansen estimatoren ܳ(ݐ) på
tidspunktet ݐ:
݈݃݅ݐ൫ܳ(ݐ)൯=ߚ்ܼ
til at estimere absolutte forskelle, baseret på de modellerede sandsynligheder.
Baseret på disse modeller estimerede vi relative risici (RR) og risikodifferencer (RD)
med 95% konfidensintervaller (CI). Hospitaliseringsmålet omfattede alle
heldøgnsindlæggelser registreret i løbet af den 14-årige opfølgningsperiode. På grund af
overdispersion i Poisson-regressionsmodellen anvendte vi negativ binomial regression

16
til at beregne incidensrate-ratioer (IRR) for indlæggelser. Studieperioden begyndte på
interviewdatoen og sluttede enten den 31. december 2018 eller ved deltagernes død,
afhængigt af hvad der indtraf først.
Vi estimerede to modeller. Model 1 justerede for alder, køn og interviewbølge.
Model 2 justerede også for uddannelse, civilstand, formue, medicinsk historie, rygning,
alkoholforbrug, BMI, depressive symptomer og begrænsninger i dagligdags aktiviteter
(ADL). I alle analyser vurderede vi effekterne separat for hvert køn ved at inkludere en
interaktionsterm mellem aktivitetsdeltagelse og køn.
For at vurdere robustheden af resultaterne lavede vi fire sensitivitetsanalyser
baseret på model 2.
1) Beregning af E-værdier ift. resultaterne fra hovedanalyserne. Denne analyse blev
udført ved brug af formlen
ܧ െݒ݈ܽݑ݁ =ܪܴ +ඥܪܴ ή(ܪܴ െ 1)
Baseret på den oprindelige artikel af VanderWeele og Ding 16 ved hjælp af Stata-pakken
”evalue” 17.
2) Ekskludering af deltagere der havde deltaget i en religiøs organisation.
3) Ekskludering af deltagere med ADL-begrænsninger ved baseline.
4) Hospitaliseringsmålet udvides til også at omfatte dagpatienter, ambulante patienter
og skadestuebesøg.
Alle analyser blev udført ved hjælp af Stata version 17.0.
Resultater
Studiepopulationen bestod af 1.348 mænd (45,1%) og 1.639 kvinder (54,9%) med en
gennemsnitsalder på 62,6 år. I alt deltog 36,4% i en sports- eller socialklub, 30,8% hjalp
familie og venner, 19,4% udførte frivilligt arbejde, 10,6% deltog i et uddannelses- eller
træningskursus, 5,9% deltog i en religiøs organisation, 5,8% passede en syg eller
handicappet person, og 4,9% var involveret i en politisk eller samfundsrelateret
organisation (Tabel 1).
Tabel 1 - Baselinekarakteristika for studiepopulationen.
Total
Mænd
Kvinder
Antal (%)
2.987
1.348 (45,1)
1.639 (54,9)

165
Alder (år), gennemsnit (yngst-ældst)
62,6 (40-98)
62,5 (43-94)
62,8 (40-98)
Døde
848 (28,4)
407 (30,2)
441 (26,9)
Deltagelse i aktiviteter
Frivilligt/velgørende arbejde
578 (19,4)
285 (21,1)
293 (17,9)
Passet syg/handicappet
172 (5,8)
63 (4,7)
109 (6,7)
Hjulpet familie/venner
919 (30,8)
454 (33,7)
465 (28,4)
Uddannelses/træningskursus
315 (10,6)
121 (9,0)
194 (11,8)
Sports/socialklub
1,083 (36,4)
486 (36,1)
597 (36,4)
Politisk/samfundsrelateret organisation
147 (4,9)
87 (6,5)
60 (3,7)
Religiøs organisation
176 (5,9)
68 (5,0)
108 (6,6)
Samlet aktivitetsscore
0 aktiviteter
1014 (34,0)
441 (32,7)
573 (35,0)
1 aktivitet
1042 (34,9)
472 (35,0)
570 (34,8)
2 aktiviteter
587 (19,7)
275 (20,4)
312 (19,0)
3+ aktiviteter
344 (11,5)
160 (11,9)
184 (11,2)
Tabel 2 skitserer de vigtigste motivationsfaktorer for de forskellige aktiviteter. Den
vigtigste grund til at deltage i frivilligt arbejde var at yde noget nyttigt (72,7%). Den
primære motivation for at passe en syg eller hjælpe familie og venner var at føle sig
nødvendig (henholdsvis 87,8% og 83,2%). Uddannelses- eller træningsaktiviteter var
drevet af ønsket om at bruge færdigheder eller holde sig i form (60,0%). Ift. sports- eller
sociale klubber var fornøjelse (78,8%) og at holde sig i form (75,4%) de vigtigste
drivkræfter. Politisk engagement var primært drevet af ønsket om at bidrage (64,0%),
mens deltagelse i religiøse organisationer hovedsageligt var for personlig fornøjelse
(65,9%) (Tabel 2).
Tabel 2 - Årsager til aktivitetsdeltagelse angivet i procent.
Frivil-
ligt
arbejde
Passet
syg/
handi-
cappet
Hjulpet
familie/
venner
Uddan-
danses/
trænings
kursus
Sports/
social
klub
Politisk
organi-
sation
Religiøs
organi-
sation
For at møde folk
50,5
2,9
11,3
19,4
55,8
44,2
46,9
For at yde noget nyttigt
72,7
32,0
40,0
15,9
9,8
64,0
28,0
For at opnå noget
personligt
23,7
4,4
5,3
50,6
26,8
20,5
49,4
Fordi der er brug for mig
63,7
87,8
83,2
15,2
9,7
37,4
27,4
For at tjene penge
1,6
5,2
0,3
9,2
0,4
2,0
-
Fordi jeg nyder det
68,3
22,0
46,6
34,5
78,8
50,6
65,9
For at bruge mine evner
eller holde mig i form
41,7
7,6
15,8
60,0
75,4
29,3
16,6
Fordi jeg føler, jeg er
tvunget til at gøre det
5,0
14,3
5,0
18,4
3,0
9,6
-
-Tallene kunne ikke estimeres pga. mindre end fem personer i grupperne.
Blandt de 848 registrerede dødsfald viste model 2 lavere dødelighed for personer, der
deltog i 1, 2 eller 3+ aktiviteter sammenlignet med dem, der ikke deltog. Laveste

166
dødelighed var indikeret blandt dem, der deltog i 3+ aktiviteter (RR 0,78; 95% CI 0,67–
0,89; RD -0.19; 95% CI -0.28 to -0.11). Specifikke aktiviteter, der var associeret med
lavere dødelighed, inkluderede frivilligt arbejde (RR 0,85; 95% CI 0,76–0,95; RD -0.11;
95% CI -0.18 to -0.04), hjælp til familie og venner (RR 0,88; 95% CI 0,82–0,95; RD -
0.09; 95% CI -0.14 to -0.04) og deltagelse i sports- eller socialklubber (RR 0,89; 95%
CI 0,81–0,98; RD -0.09; 95% CI -0.15 to -0.03). Disse sammenhænge var stærkere
blandt kvinder end blandt mænd (Figur 1).
Ift. indlæggelser blev der ikke fundet signifikante forskelle, bortset fra at mænd, der
deltog i 3+ aktiviteter (IRR 0,75; 95% CI 0,57–1,00) og mænd der deltog i en religiøs
organisation (IRR 0,67; 95% CI 0,46–0,98) havde færre indlæggelser (Figur 2).

167
Ift. indlæggelser blev der ikke fundet signifikante forskelle, bortset fra at mænd, der
deltog i 3+ aktiviteter (IRR 0,75; 95% CI 0,57–1,00), og mænd, der deltog i en religiøs
organisation (IRR 0,67; 95% CI 0,46–0,98), havde færre indlæggelser (Figur 2).
Dosis-respons-analyserne viste overordnet et konsistent mønster for personer, der
udførte aktiviteterne mindre end én gang om ugen ift. dem der udførte aktiviteterne
mindst én gang om ugen. Dog var sammenhængene mellem frivilligt arbejde og lavere
dødelighed, samt det at passe en syg eller handicappet og færre indlæggelser, kun til
stede for dem, der deltog i aktiviteterne mindre end én gang om ugen. Den modsatte
sammenhæng i form af flere indlæggelser var indikeret for personer der passede en syg
eller handicappet mere end én gang om ugen 1.
Sensitivitetsanalyserne viste overordnet robuste resultater. Flere E-værdier viste
moderat robusthed. For eksempel blev der fundet en E-værdi på 1,63 for frivilligt
arbejde, hvilket betyder, at en umålt confounder, der er associeret 1,63 gange med både
eksponeringen og udfaldet, efter at have taget højde for de målte confoundere, vil kunne
forklare effekten. Svagere confoundere kan ikke. Den mest robuste E-værdi var for
kvinder, der deltog i en religiøs organisation (E-værdi = 3,04, E-værdi nedre CI-grænse
= 1,29) 1.
168
Når deltagere involveret i religiøse organisationer samt dem med ADL-begrænsninger
blev ekskluderet, forblev de overordnede resultater konsistente 1.
Generelt blev sammenhængene svækket, når alle typer indlæggelser blev inkluderet, og
kun sammenhængene i model 1 forblev signifikante 1.
Diskussion
Denne danske undersøgelse viste, at personer der deltog i mindst én aktivitet, havde
lavere dødelighed sammenlignet med personer der ikke deltog i aktiviteter. Specifikt
fandt vi, at frivilligt arbejde, det at yde hjælp til familie eller venner samt deltagelse i
sports- eller socialklubber var associeret med lavere dødelighed, især blandt kvinder.
Mænd, der deltog i mindst tre aktiviteter eller deltog i religiøse organisationer, havde
færre indlæggelser. Bemærkelsesværdigt var det, at styrken af sammenhængen for nogle
aktiviteter varierede afhængigt af aktivitetsfrekvensen. For mænd var frivilligt arbejde
forbundet med en lavere risiko for dødelighed, mens det at passe en syg eller
handicappet var forbundet med færre indlæggelser, men kun når aktiviteten blev udført
mindre end en gang om ugen. Dette antyder, at overdreven involvering i visse aktiviteter
kan ændre sammenhængen fra at være beskyttende til potentielt at have negative
sundhedskonsekvenser, i tråd med litteraturen om omsorgsrelateret stress 9.
Vores resultater stemmer overens med tidligere forskning 8,18-22 som viser, at
aktivitetsdeltagelse er associeret med lavere dødelighedsrater. Det interessante er dog,
at vores studie indikerer, at deltagelse i sports- eller sociale klubber har en lignende
effekt som andre former for socialt engagement, såsom frivilligt arbejde. Dette antyder,
at den specifikke type aktivitet muligvis ikke er den primære drivkraft bag de
observerede sundhedsfordele. I stedet kan fordelene snarere stamme fra social
tilknytning, som kan reducere ensomhed og fungere som en buffer mod stress 23.
Derudover kan deltagelse i sociale aktiviteter give en følelse af mening eller formål med
livet 24, hvilket er forbundet med bedre sundhedseffekter 25.
Mens kvinder generelt lever længere end mænd på tværs af alle lande 26, rapporterer de
også oftere dårligere selvvurderet helbred, oplever flere depressive symptomer, har en
169
højere forekomst af samtidige sygdomme, klarer sig dårligere i fysiske tests og er
generelt mere skrøbelige end mænd 27-31. I overensstemmelse med dette fænomen, kendt
som ”the male-female health survival paradox” 32, fandt vi, at kvinder drager større
fordel af sociale aktiviteter, når det kommer til overlevelse, hvorimod resultaterne
indikerer, at selvom den samme sammenhæng ikke findes hos mænd ift. de specifikke
aktiviteter, så er det muligt, at aktivitetsdeltagelse kan resultere i færre alvorlige
sygdomme og dermed beskytte mænd mod indlæggelser.
Vores tidligere forskning viste, at deltagelse i en religiøs organisation var forbundet med
lavere dødelighed for kvinder og færre indlæggelser blandt mænd 11. Denne
undersøgelse fandt lignende sammenhænge for overlevelse, dog lidt mindre udtalte, men
ift. indlæggelser, fandt vi ingen lignende sammenhænge for andre aktiviteter. Dette
tyder på, at der kan være særlige sundhedsmæssige fordele ved religiøse aktiviteter, især
for mænd.
En anden mulig forklaring på vores fund kan være omvendt kausalitet. Deltagelse i
sociale aktiviteter kræver både fysisk og mental energi, hvilket betyder, at de, der
deltager, muligvis har et bedre helbred end dem, der ikke deltager. Selvom vi justerede
for en bred række af potentielle confoundere, herunder medicinsk historie,
begrænsninger i dagligdags aktiviteter (ADL) og mental sundhed, som også dækker
tidlige tegn på sygdom, såsom mangel på energi og søvnproblemer, kan der stadig være
potentielle confoundere, vi ikke har taget højde for f.eks. genetik. Dog reducerer vores
longitudinelle studiedesign, hvor aktivitetsdeltagelse blev målt før udfaldet, og hvor der
blev taget højde for socioøkonomiske og helbredsmæssige faktorer ved baseline,
sandsynligheden for omvendt kausalitet. Derudover viste sensitivitetsanalysen, hvor
personer med ADL-begrænsninger ved baseline blev ekskluderet, ingen væsentlige
ændringer i resultaterne.
Styrkerne ved dette studie inkluderer et omfattende datasæt, der kombinerer forskellige
former for aktivitetsdeltagelse fra interviews med danske registerdata, hvilket giver
detaljeret information om dødelighed og indlæggelser over 14 år. Vi undersøgte også
dosis-respons-sammenhænge og anvende både relative og absolutte mål for dødelighed.

170
Begrænsningerne omfatter en relativt lille studiepopulation på knap 3.000 deltagere,
hvilket skaber usikkerhed omkring estimaterne. Aktivitetsdeltagelse blev kun målt på ét
tidspunkt, hvilket ikke tager højde for ændringer over tid. Forskellige aktiviteter kan
have forskellige mekanismer, der påvirker dødelighed, og disse blev ikke fuldt ud
undersøgt. En potentiel begrænsning ved SHARE er de lave svarprocenter i nogle lande
og interviewbølger, hvilket kan føre til selektionsbias. I Danmark var svarprocenterne
67,1 % i bølge 1 og 65,2 % i bølge 2 33.
Konklusion
Undersøgelsen viste, at deltagelse i mindst én aktivitet var forbundet med lavere
dødelighed. Ift. de specifikke aktiviteter var frivilligt arbejde, det at yde hjælp til familie
eller venner samt deltagelse i sports- eller socialklubber forbundet med lavere
dødelighed, med resultater, der var sammenlignelige med dem for deltagelse i en religiøs
organisation. Den stærke sammenhæng med færre indlæggelser blandt mænd, der deltog
i en religiøs organisation, blev dog ikke fundet for andre aktiviteter. Fremtidige studier
bør undersøge de underliggende mekanismer bag disse sammenhænge.
Referencer
1
Accepted in Epidemiology, October 14, 2024
2
American journal of epidemiology 109
186 20 1979 10 1093 11267
3 Science (New
York, N.Y.) 241 5 0 5 5 1988 10 1126 3399889
Appl Psychol Health Well Being 5 28 78 2013
10 1111 12000
5
PLoS medicine 7 1000316 2010
10 1371 1000316
6
Psychosomatic medicine 72 229 238 2010
10 1097 0 013 3181 01611
7 et al.

171
Social science & medicine
(1982)251 112906 2020 10 1016 2020 112906
8
Campbell Syst Rev 16 112
2020 10 1002 2 112
9
Psychological bulletin 129 9 6 972 2003
10 1037 0033 2909 129 6 9 6
10
Jama 282 2215 2219 1999 10 1001 282 23 2215
11
European journal of
epidemiology 38 281 289 2023 10 1007 1065 023 0096
12 et al.
International journal of epidemiology 42 992 1001
2013 10 1093 088
13 REGLINK-SHARE - Survey on Health, Ageing and
Retirement in Europe 202
1
- -Biometrika90 15 27
2003 10 1093 90 1 15
15
10 1177 1536867 1501500313
15 3 809 821 2015
16
Annals of internal medicine 167 268 27 2017
10 7326 16 2607
17
The Stata Journal 20 162 175 2020 10 1177 1536867 20909696
18 1
Bmj 367 6377 2019 10 1136 6377
19
Health Promot Int 21 5 12 2006
10 1093 027
20
European journal of epidemiology 22
589 597 2007 10 1007 1065 007 9153
21 et al.
Journal of epidemiology and
community health 70 583 588 2016 10 1136 2015 206305
22 et al.
Preventive medicine 49 1 2 1 7 2009
10 1016 2009 06 026
23
Journal of health and social behavior 52 1 5 161 2011
10 1177 00221 6510395592

172
2 International Encyclopedia of the Social & Behavioral Sciences
(Second Edition) 365 370 2015
25
Health Psychology Review 11 387 18
2017 10 1080 17 37199 2017 1327325
26
BMJ 332 808 2006 332 75 5 808
10 1136 332 75 5 808
27
European journal of ageing 17 69 79 2020 10 1007 10 33 019 0052
28 et al.
European journal of public health 29
667 67 2019 10 1093 266
29
Int J Public Health 64 1025 1036
2019 10 1007 00038 019 01270 9
30
Aging & mental health 1 8 2021
10 1080 13607863 2021 2013 3
31
Eur. J. Public Health 21 81 91 2011
10 1093 022
32
Aging clinical and experimental research
20 91 102 2008
33
17
700 2019

173
Triangulation of contradictory evidence from three randomized trials
of an early 2-dose measles schedule in Guinea-Bissau from 2003-2019
Sebastian Nielsen1, Sören Möller2.1Bandim Health Project, Department of Clinical
Research, University of Southern Denmark, 2Open Patient data Explorative Network
(OPEN), Department of Clinical Research, University of Southern Denmark
Note: this is work in progress. Suggestions and comments are very welcome! Both
before, during and after the symposium, e-mail: senielsen@health.sdu.dk.
Introduction
This study investigates the non-specific effects (NSEs) of childhood vaccines on all-
cause child mortality in Guinea-Bissau. Nature has recently included the discovery of
NSEs of vaccines as their major milestone 13 in the history of vaccine research [1]. In
short, vaccines have been shown to alter susceptibility to other disease than the
targeted disease, an effect that has been termed NSEs. However, contrary to the
specific effects of vaccines, the NSEs are very context dependent. Contextual factors
of the NSEs of vaccines include but are not limited to host factors (e.g. sex), sequence
and combinations of vaccinations as well as maternal factors [2, 3]. Identification of
contextual factors for the NSEs of vaccines is a novel field within the epidemiological
investigations of the NSEs of vaccines. Identification of contextual factors often
require multiple datasets and triangulation of the available evidence [2, 4].
In this study we propose a method to identify contextual factors, by defining three
conditions that needs to be satisfied to identify a contextual factor.
We will use the definition in an explorative investigation with the aim of identifying
contextual factors to provide insight on the contradictory results reported from three
randomized trials (RCTs) conducted in Guinea-Bissau between 2003 and 2019 [5-7].
RCT I showed a beneficial HR of 0.70 (95% CI: 0.52-0.90) while RCT II produced a
HR of 1.38 (0.92-1.90) and RCT III a HR of 1.17 (0.72-1.90) (p-value for
homogeneity of HRs = 0.018) (Table 1).

17
Table 1. Main results and primary characteristics of the three RCTs of 2-dose vs 1-
dose measles vaccine (MV) schedules conducted in Guinea-Bissau.
Methods
Early 2-dose measles vaccine RCTs
The trial design was almost identical for the three RCTs (Figure 1). Children were
enrolled from 4 weeks after receiving the third dose of Penta vaccine given from 14
weeks of age. All children received measles vaccine (MV) at 9 months of age as is the
World Health Organization (WHO) policy for low-income countries. The RCTs
compared the effects on all-cause child mortality of a 2-dose MV schedule given from
4 months and 9 months (2-dose MV group) to the standard one dose of MV at 9
months of age (1-dose MV group).
Figure 1. Trial design of the 2-dose MV RCTs.
RCT I
RCT II
RCT III
Hazard ratio
(2
-dose/1-dose)
0.70 (0.52
-
0.90)
1.38 (0.92
-
1.90)
1.17 (0.72
-
1.90)
Area
Urban
Urban
Rural
Years
2003-2009
2011-2019
2012-2015
Number of participants
6,417
6,598
3,709
Randomization ratio
1:2
2:1
1:1
Number of deaths
217
123
69

175
Interactions with oral polio vaccination campaigns
The investigators of the RCTs have previously documented a potential interaction
affecting the 2-dose/1-dose MV hazard ratio (HR, unless otherwise stated the HR will
always refer to the comparison the 2-dose vs. 1-dose MV group) with oral polio
vaccination campaigns (C-OPV). Children who had received C-OPV-before-
enrolment, did not have a beneficial effect of 2-dose MV, compared to the children
who did not receive C-OPV-before-enrolment [8, 9]. An overview of enrolment
periods, follow-up period and OPV campaigns conducted can be seen in Figure 2.
Figure 2. Inclusion and follow-up period for the three 2-dose MV RCTs in Guinea-
Bissau. Vertical lines represent national OPV campaigns conducted.
Contextual factors
We identified the following potential contextual factors. Non-binary factors were
transformed to binary factors as defined below.
Sequence and combination of vaccines and other health interventions: C-OPV-before-
enrolment (yes / no), C-OPV-after-enrolment (yes / no), age of first routine OPV (14
days / >14 days), time interval between DTP3 and enrolment (<5 weeks / 5 weeks)

176
and Vitamin A supplementation given at birth (yes / no, OBS: only possible for
children in RCT I).
Host factors: sex (male / female), age at enrolment (<22 weeks / 22 weeks) and
exclusive breastfeeding at time of enrolment (yes / no). Maternal antibody (MatAb)
measurements (NB: measles MatAb only available for subgroups of RCT I (6.8%) and
III (13.4%) and most of RCT II (94.6%). Other MatAb only available in RCT II):
detectable measles MatAb (>28.7 mIU/mL / 28.7 mIU/mL), rubella (upper quartile /
three lower quartiles), varicella (upper quartile / three lower quartiles) and Mumps
(upper quartile / three lower quartiles).
Triangulation
In the following we propose a triangulation framework to identify contextual factor(s),
which may explain the contradictory results 2-dose MV RCTs. This was done in the
combined analysis of all three RCTs for all children and separately by sex since many
studies have shown that the NSEs are differential by sex [10].
The triangulation framework consists of three conditions that need to be satisfied:
1) Existence
Contextual factor for the HR exists if either A) the factor independently has a direct
significant impact (either positively or negatively) on the HR or B) the factor has a
significant impact on the HR combined with sufficiently many two-way interactions
with other potential contextual factors (excluding those with factors that are
independently impacting the HR as defined in part A). Sufficiently many tests,
meaning that the probability of observing the number of significant two-way
interactions is less than 5% when adjusted for multiple testing (defined further below)
and where the effects of the different two-way-interactions on the HR are all in the
same direction.
2) Consistency
The effect of the contextual factor is consistent across RCTs if there is no significant
heterogeneity in the impact of the contextual factor on the HR across RCTs.
3) Coherence
177
The contextual factor is coherent, if the variation in distribution of the contextual
factor between RCTs contributes to explaining the differences in HR across RCTs.
If one or more contextual factor(s) can be shown to satisfy these three conditions, by
triangulation it is likely that the contextual factor(s) can help explain the observed
heterogeneity in the HRs across the RCTs.
Beneficial, detrimental or neutral exposure to contextual factors
It is possible to identify participants who are exposed to multiple contextual factors
that affects the HR both beneficially and detrimentally. Participants can spend follow-
up time as “only exposed to beneficial contextual factors” (beneficial group), “only
exposed to detrimental contextual factors” (detrimental group) or either “exposed to no
contextual factors” or “exposed to both beneficial and detrimental contextual factors”
(neutral group).
Statistical analysis
We conducted an individual-level combined analysis of the three RCTs, based on the
original data sets. For mortality, we present HR and Wald 95% CIs estimated from a
Cox proportional hazards model with age as the underlying time and stratified by sex
and RCT.
Adjusted p-value in multiple testing
For the existence of a contextual factor by interactions with other factors (two-way
interactions, part B in the existence criterion), it is required that the adjusted p-value is
less than 5%. We use the cumulative distribution function for the binomial distribution
defined as:
ܨ(݇,݊,)=ܲ(ܺ<݇)=ቀ݊
݅ቁ(1 െ)ି
ିଵ
ୀ
where k is number successes out of n repeated observations of a Bernoulli distributed
random variable X with probability p for each success. The formula for the adjusted p-
value is then calculated as:
(1 െܨ(݇,݊,))·ܨ(0,݊െ݇,)·2
178
The adjusted p-value is the probability to observe k or more successes, i.e. observe at
least k significant interactions for a potential contextual factor, but with the
requirement that none of the remaining n-k interactions are significant in the opposite
direction. Finally, we multiply by two since the direction of the first interaction can be
either beneficial or detrimental.
For identifying existence of contextual factors in this study (with p=0.025) it translates
to a requirement of three (k=3) or more significant interactions for both evaluating the
contextual factors for all children (12 factors, n=22 tests) and by sex (11 factors, n=20
tests), the corresponding adjusted p-values are 2.1% and 1.7%.
Results
Existence
Among all children the potential beneficial contextual factor “not yet received C-OPV-
after-enrolment” was directly impacting the HR. “Not received C-OPV-before-
enrolment” was identified as contextual factor with three two-way interactions, namely
with: “received OPV at birth by 14 days of age”, “not exclusively breastfeeding” and
“female sex”. For the detrimental impact of factors on the HR, no factors were
identified to independently significantly impact the HR. With the two-way
interactions, three factors were identified as negatively impacting the HR. The first,
“received C-OPV-before-enrolment” with four two-way interactions with: “short
DTP3 interval”, “detectable measles MatAb”, “received C-OPV-after-enrolment” and
”exclusive breastfeeding”. The second, “Received C-OPV-after-enrolment” was
impacting negatively in three two-way interactions with: “received C-OPV-before-
enrolment”, “male sex” and “high Rubella MatAb levels”. And the third, “Short DTP3
interval” in three two-way interactions with: “received C-OPV-before-enrolment”, “no
detectable measles MatAb” and “low varicella MatAb levels”.
Contextual factors identified by sex found among males “not yet received C-OPV-
after-enrolment” was an independently beneficial contextual factor. There was no
detrimental factor for males. For the females “not received C-OPV-before-enrolment”

179
was a beneficial factor and “received C-OPV-before-enrolment” was a detrimental
contextual factor directly on the HR.
Consistency
When comparing the effects of the potential identified contextual factors, we found for
all children that the effects among children with beneficial contextual factors were for
RCT I-III: 0.76 (0.31-1.83), 0.81 (0.24-2.78) and 1.20 (0.43-3.32) (p for homogeneity
= 0.79). For the detrimental factors the HRs were: 2.90 (0.82-10.3), 4.71 (1.43-15.5)
and 1.66 (0.68-4.03) (p=0.38). For the contextual factors identified separately by sex
both the beneficial and detrimental effects did also not differ significantly across RCTs
(p=0.38 and p=0.27).
Coherence
In Figure 3 we see that the proportion of follow-up time and the associated mortality
rates for the children exposed to beneficial, detrimental or neutral contextual factors as
identified for all children by RCT and randomization group. Figure 4 is the same as in
Figure 3 but for contextual factors identified separately by sex.
Figure 3. Proportion and mortality rates by RCT, contextual factor exposure and
randomization group for contextual factors identified among all children.

180
Figure 4. Proportion and mortality rates by RCT, contextual factor exposure and
randomization group for contextual factors separately by sex.
Since some of the contextual factors are time-varying the comparison of MRs is only
valid between randomization groups (red vs. blue) within contextual exposure groups.
From Figure 3 and 4 we see that the contextual factors identified separately by sex
identify a larger proportion of the follow-up time as either beneficial or detrimental,
while the contextual factors identified among all children categorizes most follow-up
as neutral in all three RCTs.
Combined HRs by exposure to contextual factors
The HR based on contextual factors identified among all children exposed to
beneficial contextual factors was 0.89 (0.51-1.56) while it was 2.64 (1.47-4.73) among
children exposed to detrimental contextual factors (p for same effect = 0.008). The
effect was also beneficial in the neutral group, i.e. among children exposed to no
contextual factors or exposed to both beneficial and detrimental contextual factors,
0.78 (0.61-0.98). For the contextual factors identified separately by sex the beneficial
HR was 0.65 (0.49-0.85) while the detrimental was 1.66 (0.99-2.78) (p for same effect
= 0.002) and in the neutral group the effect tended also to be negative, 1.41 (0.97-
2.05).
181
Discussion
Using the proposed definition to identify contextual factors, we corroborated that C-
OPV administered both before-enrolment and during follow-up (after-enrolment)
impacted the HR (2-dose/1-dose MV) in the three RCTs. For all children two
beneficial and three detrimental contextual factors were identified, only some of these
were identified separately by sex, mainly those related to C-OPVs. No additional
contextual factors were identified by sex. We found that the contextual factors
identified separately by sex provided a more coherent explanation of the observed
differences in the HR.
Strengths and limitations
We used individual-level data from three RCTs with few differences in trial design and
data collection [5-7]. Two RCTs were conducted in the same study area during
different time periods (Figure 2). Though RCTs were similar, and data was collected in
almost identical manners there may still be differences due to different fieldworkers or
procedures in the RCTs. Another limitation is the availability of potential contextual
factors in the datasets, e.g. MatAb were only available for some of the participants,
while other factors may not be available at all, or we may not be aware that they exist
and therefore no information has been collected on these factors. For those factors that
are available only some have been chosen to be included in the present triangulation.
Notably, we have not (yet) considered whether children “received campaigns with
OPV together with vitamin A supplementation” or “campaign Vitamin A
supplementation alone”. We did also not distinguish between the comparison of the
HR before and after the standard 9-month MV. Before 9-months MV the HR is
comparing 1-dose vs no dose of MV and from 9-months MV it is a comparison of 2-
dose MV vs. 1-dose MV. There are also several other possible approaches to defining
the beneficial and detrimental groups in the RCT cohorts; one approach could be to
define a score with beneficial interactions counting positively and detrimental factors
negatively. Another aspect would be if all contextual factors are equal, or should they
be weighed according to e.g. their level of significance. The cut-off at p=0.05 to
identify as potential a contextual factor is arbitrary and could be questioned. Allowing
182
the inclusion of contextual factors with both beneficial and detrimental effects of the
HR, could also be possible with alternative definitions of the framework.
Other studies
We recently investigated the impact of C-OPVs on the HR and found that C-OPVs
may have had an impact on the HR and therefore do explain the contradictory results
of the three RCTs to some extent [8, 9]. This is however the first study that attempts to
define a more rigorous framework for identifying contextual factors for the NSEs of
vaccines. Few studies have focused on this very important area of the NSEs.
Perspectives
During the COVID-19 pandemic the Bacillus Calmette–Guérin (BCG) was used in
RCTs in both healthcare workers and senior populations as a potential stop-gap
vaccine. While BCG vs. placebo reduced all-cause mortality by 39% (3-62%) [11], no
RCTs had power to include mortality as a primary outcome, and results on the
predefined primary outcomes, e.g. different morbidity outcomes, were mixed.
Understanding these effects of BCG and the associated contextual factors would be
very important. The framework defined here should be re-tested in other settings and
datasets to either confirm, debunk or identify potential new contextual factors
associated with not only the comparison of a 2-dose vs. 1-dose MV vaccination
schedule, but could also be applied in other areas of epidemiological research.
Conclusion
We defined a triangulation framework and used it to identify the contextual factors to
provide insight on the contradictory results of three RCTs of an early 2-dose MV
schedule. The findings corroborated previous findings that not having received C-
OPV-before-enrolment and C-OPV-after-enrolment affected the HR (2-dose/1-dose)
beneficially, while having received C-OPV-before-enrolment, C-OPV-after-enrolment
and short DTP3 interval had a detrimental impact on the HR. Despite identified
contextual factors varied among all children and separately by sex, and factors
identified by sex were more coherent, overall conclusions were similar for both
approaches.

183
References
1
Another layer of protection
2020 20 202
2859 020 00018 3
2
How to evaluate potential non-speci
Ʊ
c e
Ư
ects of vaccines the uest
for randomi ed trials or time for triangulation
2018 17 5 11
20
3
accinology time to change the paradigm
2020 20 10 27 283
Triangulation in aetiological epidemiology.
2016 45 6 1866 1886
5
Non-speci
Ʊ
c e
Ư
ects of standard measles vaccine at 4. and 9 months of
age on childhood mortality randomised controlled trial.
2010 341 695
6
E
Ư
ect of early two-dose measles vaccination on childhood mortality
and modi
Ʊ
cation by maternal measles antibody in Guinea-Bissau, West Africa A single-
centre open-label randomised controlled trial.
2022 49 101 67
7
A Two-Center Randomi ed Trial of an Additional Early ose of Measles
accine E
Ư
ects on Mortality and Measles Antibody Levels.
2018 66 10
1573 1580
8
oes oral polio vaccine have non-speci
Ʊ
c e
Ư
ects on all-cause mortality
Natural experiments within a randomised controlled trial of early measles vaccine.
2016 612 013335
9
Contradictory mortality results in early 2-dose measles vaccine trials
interactions with oral polio vaccine may explain di
Ư
erences.
202 148
10722
10
The non-speci
Ʊ
c and sex-di
Ư
erential e
Ư
ects of vaccines.
2020 20 8 6 70
11
BCG to Protect against Covid-19 in Health Care
Workers.
2023 389 2 191 192
Abbreviations (in alphabetical order):
C-OPV = campaign oral polio vaccine; BCG vaccine = Bacillus Calmette–Guérin
vaccine; DTP vaccine = diphtheria-tetanus-pertussis vaccine; HR = hazard ratio;
MatAb = maternal antibody; mIU/mL = milli-international units per milliliter; MV =
measles vaccine; NSE = non-specific effect; OPV = oral polio vaccine; OPV0 = oral
polio vaccine recommended at birth; Penta = pentavalent, in addition to DTP including
hepatitis B vaccine and Haemophilus influenzae type b vaccine; RCT = randomized
controlled trial; YF vaccine = yellow fever vaccine; WHO = World Health
Organization

Estimating Healthcare Transitions: Integrating Logistic Regression and
Markov Models to Predict Mortality from Continuity and Discontinuity of Care
Troels Kristensen, DaCHE, Department of Public Health, University of Southern
Denmark
This is a work in progress. Please contact the author for permission before citing or
sharing
Abstract:
Background: Continuity of care (COC) in general practice has been linked to improved
health outcomes. However, maintaining COC becomes increasingly challenging over time
due to varying levels of discontinuity. This study conceptualizes COC as a "medical health
system technology" with differing degrees of discontinuity (DCOC) across areas, clinics,
and subpopulations. The idea is to model the impact of varying effectiveness of this
technology on patient mortality.
Aim: To model likely transitions from COC to increasing levels of DCOC and related
death in patients aged 55 and older in general practice. The intension is to estimate degrees
of DCOC over time and enable future applications in resource allocation, care disparities,
inequality, and health economics analyses.
Method: A Markov model with five states (Continuity, Mild Discontinuity, Moderate
Discontinuity, Severe Discontinuity, Death) was used to simulate progression in continuity
and cumulative time spent in each discontinuity state towards death. A 12-year cohort of
4,571,041 listed patients above 12 years who stayed alive were applied to measure long run
degrees of (D)COC. Annual transition probabilities between states and the absorbing state
death were estimated using transition rates, logistic regression analysis and margins
analysis at the end of the analysis period. The plan is to use sensitivity analyses assessed
the robustness of findings.
Results: The model shows transitions across care states based on the estimated annual
transition probabilities. This allows for capturing gradual transition and years in continuity
of care, mild discontinuity, moderate discontinuity, severe discontinuity and death. The
model permits long run cohort simulation for elderly patients. Finally, the model can be
used to simulate interventions targeting care coordination reduced transitions to degrees of
discontinuity.
Conclusion: This type of model offers long run insights into care transitions, enabling
evidence-based policy decisions to optimize resource allocation, improve care continuity,
and enhance patient outcomes.
184
1. Introduction
Continuity of care (COC) may be conceptualized as a "medical technology" (MedTech)
that in most cases positively impacts patient outcomes. While MedTech is typically
associated with tangible innovations like drugs, devices, diagnostics, or software - COC or
mild levels of discontinuity of care (DCOC) could also be seen as a health system
technology. For instance, in general practice. This technology perspective suggests that
COC technology shares core characteristics with MedTech. A characteristic is that it relies
on structured processes to enable consistent and personalized interactions between patients
and providers, delivering measurable benefits such as improved chronic disease
management, reduced mortality and cost savings. A well implemented “relation”-
technology in terms of COC is widely regarded as a hallmark of an optimal healthcare
system, whereas increasing care discontinuity signals systemic dysfunction (i.e., exhibit
signs of 'sickness' in health systems). The later deterioration is expected to result in adverse
outcomes, including higher mortality rates(1–3).
Using Markov modeling this study intends to actually model the effects of discontinuity in
patient care in Danish general practice over time. This means a model where a patient
transitions through different states based on their level of COC, subsequent DCOC and
outcomes. By doing so, a Markov model can quantitatively assess how COC or degrees of
COC impacts progression to outcomes such as death. Potentially also resource use, and
quality of life. Given the temporal nature of COC and DCOC, Markov modeling offers a
potential logical approach to studying the impact of changes in this "health system
technology." Markov models capture transitions between defined states, making them ideal
for modeling patient transitions through varying levels of COC, DCOC and their associated
health outcomes such as death over time. By simulating transitions to adverse outcomes
like mortality, Markov models can estimate cumulative time spent in each state. Next, the
impact of interventions to reduce DCOC, and potential gains in patient outcomes could also
be analyzed. This study hypothesizes that COC and DCOC can be modelled. The aim of
this study is to model likely transitions from COC to increasing levels of discontinuity and
related death in patients aged 55 and older in general practice. The intension is to estimate
degrees of DCOC over time and enable future applications in resource allocation, care
disparities, inequality, and health economics analyses.
185
2. Methods
A Markov model with five states (Continuity, Mild Discontinuity, Moderate Discontinuity,
Severe Discontinuity, Death) was used to simulate progression of (dis)continuity (potential
desease in health system relations) and cumulative time spent in each state (4). The COC
and DCOC states were created based on a combination of statistical and clinical expert
opinion. Continuity was defined as zero shifts, mild discontinuity of care was defined as 1-
4 shifts. moderate discontinuity was 5-8 shifts, and Severe discontinuity was defined as 9
or more shifts. The empirical measurements of states of progression of discontinuity to
death were based on the patients` registered provider shifts over a 12 years analysis period
from 2007 to ultimo 2018 (5). The death state was the absorbing state. A cycle length of
one 1 year was adopted to allow for gradual transition between states. In principle patients
could move between the 5 states in 5 * 5 = 25 different ways. The transition matrix (P)
specifies all possible probabilities of moving from one state to another. This means the
matrix in my Markov model with five states (Continuity(C), Mild Discontinuity(M),
Moderate Discontinuity(Mod), Severe Discontinuity(S), Death(D), looks like this:
P =
ۏ
ێ
ێ
ێ
ۍ
ܲܥܥ ܲܥܯ ܲܥܯ݀ ܲܥܵ ܲܥܦ
ܲܯܥ ܲܯܯ ܲܯܯ݀ ܲܯܵ ܲܯܦ
ܲܯ݀ܥ ܲܯ݀ܯ ܲܯ݀ܯ݀ ܲܯ݀ܵ ܲܯ݀ܦ
ܲܵܥ ܲܵܯ ܲܵܯ݀ ܲܵܵ ܲܵܦ
00 0 01
ے
ۑ
ۑ
ۑ
ې
(1)
In the transition matrix P in (1), pij represents the probability of transitioning from state i =
C,M,Mod,S,D to state j = C,M,Mod,S,D. The bottom row reflects that death is an absorbing
state. The adapted model did not allow for reverse transitions probabilities. This means 10
reverse transition probabilities (PMC, PModC, PSC, 0, PModM, PSM, 0, PSMod, 0, 0)
reflecting the zeros below the diagonal in (2) was ruled out. For instance, transition from
severe discontinuity back to moderate discontinuity during the analysis period. This was
due to the experienced based definition of discontinuity. This means 15 transition
probabilities are remaining. They are illustrated in Figure 1 using an illustrative set of
transition probabilities.
186

Figure 1: Illustration of Makrov (dis)continuity states excluding reverse transitions
Figure 1 shows an illustrative example of the adapted Markov model without reverse
transitions probabilities. They are ruled out sine the applied experienced based long run
definition of discontinuity does not allow patients to reverse from at state of discontinuity
to continuity or lower levels of discontinuity.
Besides the illustrated reduced model, this study anticipates that it is meaningful and
reasonable to only model gradual transition (e.g., from continuity to mild, then moderate,
and then severe) in one year. This means it is not possible to transition to discontinuity in a
way that trespasses the next gradual level. Accordingly, the 3 non-gradual transition
187
probabilities (PCMod, PCS and PMS) were set to zero. The resultant “reduced transition
matrix” P` is shown below:
P` =
ۏ
ێ
ێ
ێ
ۍ
ܲܥܥ ܲܥܯ 00ܲܥܦ
0ܲܯܯ ܲܯܯ݀ 0ܲܯܦ
00ܲܯ݀ܯ݀ ܲܯ݀ܵ ܲܯ݀ܦ
00 0 ܲܵܵ ܲܵܦ
00 0 0 1
ے
ۑ
ۑ
ۑ
ې
(2)
In total, the transition matrix P` in (2) required 11 non-trivial transition probabilities since
the zeros and 1 in (2) are given. The 4 diagonal probabilities PCC, PMM, PModMod, PSS
of the 11 were calculated as residuals since the probability of staying in the states per
definition is the residual up to 1. This means 7 transitions probabilities was required
estimated for the model.
The all-cause mortality transition probabilities from the 3 different continuity states (PCD,
PMD, PModD) to death, could be assumed to be the same and age dependent based on
Danish register data. In contrast, PSD both include the likelihood of Dying from severe
continuity plus all-cause mortality.
The implication was that we needed to estimate 3 annual transition probabilities PCM,
PMMod, PModS and the later 4 stated “all-cause mortality” probabilities). The resulting
Markov states are illustrated in Figure 1. Different from the remaining all-cause mortality
probabilities, the transition probability PSD both includes the likelihood of dying from
severe discontinuity of care and the likelihood of dying from all-cause mortality.
2.1 Transition probabilities
All patients are at risk of gradual transitioning from continuity to mild DCOC, moderate
DCOC, severe DOCOC at the beginning of analysis period. They also have a risk of all-
cause mortality and death from each state. This study used patient-specific register data to
estimate transitions probabilities for movements from one state to another within a given
time period(cycle) of one year. The applied data originates from a previous and forthcoming
188

paper(ref). More precisely, the yearly transition probabilities between states in our Markov
model was estimated using two main approaches:
Rate-to-probability:
The first approach converts transition rates between states into probabilities. The transition
rates were calculated based on empirical data.
Formula:
If the transition rate from state i to state j is rij, the probability of transitioning during a
cycle of length t (e.g., one year) is given by:
Pij = 1െ݁ିೕ௧ (3)
To determine Transition Rates rij for (3) data was gathered on the number of observed
transitions between states (iĺj) and the total time at risk for the population. More precisely,
we used data on the Danish population above 12 years listed in Danish general practice to
analyze how they switched to the different states during a 12 year analysis period. We
Computed the transition rate for the 12 years for (3) as follows:
rij =୳୫ୠୣ୰୭ ୰ୟ୬ୱ୧୲୧୭୬ୱ ୰୭୫ ୧՜୨
ୣ୰ୱ୭୬ିଢ଼ୣୟ୰ୱ ୟ୲ ୖ୧ୱ୩ ୧୬ ୗ୲ୟ୲ୣ ୧ כଵଶ (4)
Next, we applied the rate-to-probability formula (4) above to convert the transition rate
into a probability for 12 years. (ݐ = 1 year).
2.2 Logistic regression
These annual transition probabilities to death (PCD, PMD, PModD,PSD) were estimated
using logistic regression based on a 12-year cohort of patients aged 50+ and margin
analysis.
The dependent variable was a dummy for death in a 3-year follow-up period and the
dichotomous explanatory variables was Mild Discontinuity, Moderate Discontinuity,
Severe Discontinuity. Logistic regression was used to estimate the probability of an event
189

(e.g., transitioning from state i to j) as a function of predictors (demographic makers,
regional markers, municipality markers, socio economic markers and morbidity markers)
at the end of the cohort period ultimo 2018 in the following way:
logit (Pij) = log ( ೕ
ଵିೕ) = ߚ+ߚଵܺଵ+ߚଶܺଶ+ڮ..+ ߚܺ (5)
where Pij is the transition probabilities and X1, X2, …, Xk are the patient characteristic
predictors influencing the transition.
Convert Coefficients to Probabilities:
For each state the transitioning probabilities were predicted based on the following formula
based on the regression in (5):
Pij = ഁబశഁభభశഁమమశڮ..శഁೖೖ
ଵା ഁబశഁభభశഁమమశڮ..శഁೖೖ
More specifically, margins analysis in Stata was used to estimate the required conditional
probabilities for the transition matrix. For categorical variables Stata calculates the adjusted
probabilities by taking a weighted average of the predicted probabilities across all levels of
the categorial variables, using the observed distribution of the variables in the data set. This
is usually more realistic than holding variables at their means.
3. Results
The results of the logistic regression analysis of the association between follow-up
mortality and patient characteristics will be presented at the symposium. This is also the
care for the margins analysis of transition probabilities. Below an illustrative example of
the model have been included.
3.1 Transition probabilities for the Markov model
The illustrative model parameters in Table 1 were used to populate the Markov model:
190

Table 1: Gradual transition matrix for Markov model with 5 stages
Continuity
Mild
discontinuity
Moderate
Discontinuity
Severe
Discontinuity
Death
Continuity
1-0.05
0.05
0
0
0.01
Mild discontinuity
0
1-0.1
0.1
0
0.02
Moderate
Discontinuity
0
0
1-0.1-0.05
0.1
0.05
Severe Discontinuity
0
0
0
1-0.15
0.15
Death
0
0
0
0
1
Next in Table 2 the Cohort simulation for the model of COC, degrees of DCOC and death
was calculated based on transition probabilities in Table 1 (only the first 10 years for
illustration).
Table 2: Cohort simulation for the model of (dis)continuity transition
Cycle
Age
Continuity
Mild
discontinuity
Moderate
Discontinuity
Severe
Discontinuity
Death
0
50
75.0
20
3.8
1.3
0.0
1
51
71.9
17.4
6.7
2.4
1.5
2
52
69.0
16.2
8.3
3.2
3.3
3
53
66.3
15.5
9.1
3.8
5.2
4
54
63.9
15.2
9.6
4.1
7.2
5
55
61.7
14.9
9.8
4.3
9.2
6
56
59.7
14.7
9.9
4.4
11.3
7
57
57.9
14.4
9.8
4.5
13.3
8
58
56.2
14.2
9.8
4.4
15.4
9
59
54.6
14.0
9.6
4.4
17.4
10
60
53.1
13.7
9.5
4.4
19.3
191

Figure 1: Cohort simulation for elderly patients above 50 years
4. Discussion:
This study deals with simulation of gradual transition from COC through likely DCOC to
death. It also estimates how much time individuals spend in various states to understand
COC and the overall burden of DCOC.
0
10
20
30
40
50
60
70
80
50 60 70 80 90 100
110
Continuity Mild discontinuity Moderate Discontinuity
Severe Discontinuity Death
192

The estimated model or modified versions can be applied to a range of different tasks. One
task is healthcare resource planning and workforce allocation. Time in each health state can
be used to model the need for healthcare resources, such as improved infrastructure.
Another optional task is to adopt the model to assess disparities in care continuity across
different populations. In this way, the model can be used simulate the impact of social
determinants of health (e.g., income, location) in terms of related transition probabilities on
care discontinuity. Furthermore, the model can potentially be used to quantify how
interventions targeting underserved populations could reduce transitions to severe
discontinuity.
Another potential application is demand forecasting. This means modelling the demand for
healthcare services in each state over time, allowing for proactive resource allocation and
budgeting. Furthermore, the model can be used assess future Quality of life and conduct
health economics analysis. For instance, the model framework can be used to assign health
utility scores (e.g., quality-adjusted life years, QALYs) to each state to quantify the impact
on patient quality of life over time. It is also an option to attach cost values to each state to
calculate the total economic burden of care COC and DCOC over time. Severe
discontinuity is expected to have higher associated costs due to likely related hospitalization
and lost productivity. Furthermore, attached cost and QALY values to states could allow
for cost-effectiveness analysis to determine whether interventions that reduce time in
higher-cost states are worth implementing. Our model could also be used to quantify the
benefits of policies designed to reduce transitions to higher discontinuity states or assess
the impact of specific programs (e.g., care coordination or telemedicine) by modelling and
comparing time spent in different states before and after implementation.
Limitations:
Logistic Regression vs. Cox Proportional Hazards Model
The choice between logistic regression and Cox proportional hazards models depends on
the study design and objectives. In this study, logistic regression is used to estimate the
probability of mortality during a three-year period following a 12-year cohort period, with
predictors based on characteristics measured at the end of the cohort. This design leverages
193
the cumulative effects of COC and other factors during the cohort period to predict the
likelihood of death in the subsequent follow-up period.
Logistic regression is well-suited to this setup because it estimates the probability of death
over a fixed follow up period (three years) using predictors that summarize exposures and
conditions observed at the end of the cohort period. By focusing on end-of-cohort
characteristics, the model simplifies the analysis by avoiding complexities related to time-
to-event data or censoring. This approach is particularly effective when the predictors of
interest are stable or reflect cumulative effects, such as COC over the preceding 12 years.
However, this approach has some limitations. By using predictors measured at the end of
the cohort period, the model does not account for dynamic changes in health status, care
patterns, or other critical factors that occurred during the cohort period. These changes may
have influenced the predictors or mortality risk in ways that are not explicitly modeled.
Furthermore, logistic regression does not capture the timing of deaths within the three-year
follow-up period, which could obscure temporal patterns. The Cox proportional hazards
model, in contrast, explicitly accounts for time-to-event dynamics, modeling the hazard of
death over the follow-up period. It allows for the inclusion of time-varying covariates and
captures the timing of deaths, offering a more granular view of mortality risk. However, the
Cox model is more complex to implement and may not align as naturally with the discrete
transition probabilities required for Markov modeling.
Overall, logistic regression is seen as a pragmatic and effective choice for this study, given
the reliance on fixed end-of-cohort characteristics and the clearly defined three-year follow-
up period. While it provides probabilities that are readily interpretable and suitable for
Markov modeling, complementary analyses using Cox proportional hazards or other
survival models could validate these findings and offer additional insights into temporal
dynamics and the influence of cumulative and dynamic factors on mortality.
Defining the applied degrees of discontinuity
In the Danish GP context where there are no specific evidence-based guidelines, defining
degrees of discontinuity such as mild, moderate, and severe discontinuity of care. This can
be done in several ways. Here we used a combined statistical and conceptual methods. The
statistical approach was used to categorize provider shifts based on empirical data
distribution. This can ensure objectivity and balanced group sizes. However, statistical
thresholds may lack clinical meaning. I also used a more conceptual approach, grounded in
194
expert consensus among GPs and literature. The later may have aligned the definition with
expert knowledge and implications for care quality and patient outcomes such as mortality.
But a strict conceptual approach may overlook nuances in population variability or create
imbalanced categories. Accordingly, I have attempted to combine these approaches—using
both statistical patterns to inform thresholds and refining them with clinical reasoning.
Consequently, I hope I have defined discontinuity levels that are both scientifically valid
and clinically meaningful.
References
1. Sandvik H, Hetlevik Ø, Blinkenberg J, Hunskaar S. Continuity in general practice
as predictor of mortality, acute hospitalisation, and use of out-of-hours care: a registry-
based observational study in Norway. Br J Gen Pract. 2022 Feb;72(715):e84–90.
2. Baker R, Freeman GK, Haggerty JL, Bankart MJ, Nockels KH. Primary medical
care continuity and patient mortality: a systematic review. Br J Gen Pract. 2020
Sep;70(698):e600–11.
3. Pereira Gray DJ, Sidaway-Lee K, White E, Thorne A, Evans PH. Continuity of
care with doctors-a matter of life and death? A systematic review of continuity of care
and mortality. BMJ Open. 2018 Jun 28;8(6):e021161.
4. Briggs A, Sculpher M. An introduction to Markov modelling for economic
evaluation. Pharmacoeconomics. 1998 Apr;13(4):397–409.
5. Olsen J, Kristensen T. Continuity and discontinuity of care among older patients in
Danish general practice. BJGP Open [Internet]. 2023 Jun 17 [cited 2023 Jul 9]; Available
from: https://bjgpopen.org/content/early/2023/06/19/BJGPO.2023.0081
195
196
Network meta-analysis of diagnostic test accuracy trials
Oke Gerke1,2, Werner Vach3,4
1Department of Nuclear Medicine, Odense University Hospital, Denmark;
2Department of Clinical Research, University of Southern Denmark, Denmark; 3Basel
Academy for Quality and Research in Medicine, Switzerland; 4Department of Sports
Science and Clinical Biomechanics, University of Southern Denmark, Denmark
Background
An important step before clinical intervention selection is the diagnosis of the
condition of a patient. Diagnostic tests are commonly used to confirm or exclude a
target condition (e.g. a disease). To this end, sensitivity (the proportion of positive
test results in those with the target condition) and specificity (the proportion of
negative test results in those without the target condition) of a diagnostic test are
assessed simultaneously. Decision-making rarely relies on a single diagnostic test
accuracy study; instead, evidence from multiple diagnostic test accuracy studies
addressing the same question is used.
Diagnostic test accuracy meta-analysis focuses on evaluating individual tests across
separate studies. However, multiple index tests may be available for a target
condition, making their comparative accuracy important for decision-making.
Network meta-analysis allows for a more integrated and comprehensive evaluation
of several diagnostic tests simultaneously in a single model.
While network meta-analyses are well-established and widely used in outcome
studies targeting patient-related benefit like overall survival (1), network meta-
analysis in diagnostic accuracy trials differ in terms of simultaneously targeting
sensitivity and specificity of a test (2). Several network meta-analysis models have
been developed recently to evaluate the comparative accuracy of multiple diagnostic
tests, dealing differently with issues like handling of imperfect reference standards,
modelling multiple thresholds, or number of diagnostic tests that can be investigated
(two vs. more than two) (3).
197
Purpose
We performed a systematic review and network meta-analysis on the detection of
bone metastases in breast cancer and compared five imaging modalities (4). We
applied two meta-analytical approaches: firstly, we applied classical bivariate
random-effects modelling (5), thereby making use of all information available from
single- and multi-modality studies. Secondly, we focused on the subgroup of paired
studies and network meta-analyzed differences in sensitivity and specificity (6). Do
single-modality studies provide appropriate added benefit to multi-modality studies?
Case study
We followed the Preferred Reporting Items for Systematic Review and Meta-Analysis
of Diagnostic Test Accuracy studies (PRISMA-DTA) guidelines (7) and conducted a
comprehensive search in MEDLINE/PubMed, Scopus, and Embase. We searched for
original research papers in English on humans on 17 March 2023 and updated the
search on 25 February 2024. The research question was
“Does FDG-PET/CT and/or NaF-PET/CT outperform MRI, contrasted enhanced (CE)-CT,
and bone scintigraphy in diagnosing bone metastases in breast cancer patients in
terms of diagnostic accuracy?”
We defined PICO(TS) as follows:
xP – Population: high-stage (III or IV) or known primary breast cancer with
suspicion of recurrence (staging or re-staging)
xI – Index test(s): imaging with FDG/NaF-PET/CT, MRI, CE-CT, and bone
scintigraphy
xC – Comparator: biopsy or clinical / imaging follow-up (composite reference)
xO – Outcome: summary sensitivity & summary specificity (patient-based)
xT – Timing: no limit on date of publication (but inherently limited for PET/CT)
xS – Study type: original clinical studies
All studies included in the meta-analysis needed to have information on both
sensitivity and specificity on a per-patient basis. Studies with missing information on

198
either target parameter were excluded and missing information was not imputed. We
conducted all analyses with the package metadta and the network suite in STATA/BE
18.0 (StataCorp, College Station, Texas 77845 USA).
Results
Study selection
We identified 913 records through database search and assessed 48 full-text articles
for eligibility. Forty studies contributed with data to the systematic review (Figure 1),
of which 29 studies contributed to our meta-analyses. Reasons for exclusion from
meta-analysis were missing information on specificity, missing information on
prevalence of bone metastases, lesion-based analysis only, and half of the patients (5
out of 9) receiving chemotherapy prior to imaging.
Figure 1. Regional distribution of 40 studies (on 4,247 patients) published between
2001 and 2023
Study characteristics
Half of the studies were retrospective (20 out of 40, 50%), 17 were prospective
(42.5%), and three were unclear (7.5%). Number of patients (bone metastases)
ranged from 9–884 (0–95), with a median and interquartile range of 85 and 51–119

199
(27 and 12–42), respectively. Of the 29 studies that contributed to our quantitative
synthesis of results investigated 13 studies (45%) a single modality (7 times FDG-
PET/CT, 5 times NaF-PET/CT, and once CE-CT) and 16 studies (55%) assessed at least
two modalities simultaneously (Figure 2, from left to right):
xonce FDG-PET/CT, MRI, CE-CT, and bone scintigraphy.
xonce FDG-PET/CT, NaF-PET/CT, and bone scintigraphy,
xonce FDG-PET/CT, CE-CT, and bone scintigraphy,
xonce FDG-PET/CT and NaF-PET/CT,
xonce FDG-PET/CT and CE-CT,
x8 times FDG-PET/CT and bone scintigraphy,
xonce MRI and CE-CT, and, finally,
xtwice MRI and bone scintigraphy.
Figure 2. Pattern of which imaging modalities were compared in the included studies
[reproduced from (4) with permission].

200
Figure 3 shows the respective network map, emphasizing that FDG-PET/CT and bone
scintigraphy were the most frequently compared modalities, followed by FDG-PET/CT
and CE-CT as well as MRI and bone scintigraphy.
Figure 3. Network map [reproduced from (4) with permission]
Bivariate random-effects modelling
Figure 4 comprises Summary Receiver-Operating-Characteristics (SROC) curves
derived from bivariate random effects models by modality. The generalized I-square
statistic for between-study heterogeneity assessment was 35.64%, 0.03%, 0.01%, 0%,
and 45.13% for FDG-PET/CT, NaF-PET/CT, MRI, CE-CT, and bone scintigraphy,
respectively. So, notable between-study heterogeneity was observed for both FDG-
PET/CT and bone scintigraphy.

201
Figure 4. SROC curves for FDG-PET/CT (top left), NaF-PET/CT (top center), MRI (top
right), CE-CT (bottom left), bone scintigraphy (bottom right) [reproduced from (4)]
Network meta-analysis
Figure 5 visualizes the estimated differences in sensitivity and specificity for all
estimable comparisons between modalities (as shown in Figure 3). It is apparent that
the two studies that compared FDG-PET/CT and NaF-PET/CT directly were diametrical
in terms of superiority in sensitivity or specificity, suggesting differing thresholds for
PET positivity. Comparing FDG-PET/CT and bone scintigraphy, estimates for the
difference in sensitivity varied a lot. Those for the difference in specificity were
consistently zero for 6 out of 11 studies, but advantageous for FDG-PET/CT for the
remaining studies. The difference in specificity between MRI and CE-CT was quite
precisely estimated in two studies whereas the summary estimate became
comparably imprecise (in terms of a comparably wide 95% confidence interval).

202
Figure 5. Estimated differences in sensitivity (top) and specificity (bottom) for all
estimable pairwise comparisons of modalities. Positive values indicate an advantage
for the modality named first in the comparison. [Reproduced from (4) with
permission]

203
Differences between estimates from direct comparisons and indirect comparisons
exceeded 20% for differences in both sensitivity and specificity for several head-to-
head comparisons (e.g. FDG-PET/CT vs. NaF-PET/CT; NaF-PET/CT vs. bone
scintigraphy), see Table 1. This suggests an inconsistency issue for some pairwise
comparisons of modalities.
Table 1: Sidesplits in network meta-analyses for differences in sensitivity (A) and
specificity (B) [reproduced from (4) with permission]
(A) Sensitivity
Side
Direct comparison
Indirect comparison
Difference
Coefficient
Std. Err.
Coefficient
Std. Err.
Coefficient
Std. Err.
P-value
FDG-PET/CT
vs. NaF
-
PET/CT
-0.05
0.11
-0.29
0.29
0.24
0.30
0.42
FDG-PET/CT
vs. MRI
0
0.18
0.01
0.11
-0.01
0.21
0.95
FDG-PET/CT
vs. CE-CT
-0.29
0.10
0
0.17
-0.29
0.19
0.13
FDG-PET/CT
vs. BS
-0.12
0.05
0.11
0.20
-0.23
0.21
0.27
NaF-PET/CT
vs. BS
0.16
0.15
-0.19
0.14
0.35
0.20
0.086
MRI vs. CE-CT
-0.20
0.13
-0.27
0.17
0.07
0.21
0.74
MRI vs. BS
-0.20
0.10
0.10
0.18
-0.30
0.21
0.16
CE-CT vs BS
-0.04
0.16
0.18
0.12
-0.22
0.20
0.27
(B) Specificity
Side
Direct comparison
Indirect comparison
Difference
Coefficient
Std. Err.
Coefficient
Std. Err.
Coefficient
Std. Err.
P-value
FDG-PET/CT
vs. NaF
-
PET/CT
0.05
0.11
0.34
0.28
-0.29
0.31
0.35
FDG-PET/CT
vs. MRI
0
0.13
-0.03
0.09
0.03
0.15
0.87
FDG-PET/CT
vs. CE-CT
0.03
0.07
-0.07
0.13
0.09
0.15
0.53
FDG-PET/CT
vs. BS
-0.07
0.04
-0.13
0.18
0.06
0.18
0.72
NaF-PET/CT
vs. BS
-0.37
0.13
0.05
0.14
-0.42
0.20
0.037
MRI vs. CE-CT
-0.01
0.09
0.11
0.14
-0.13
0.16
0.43
MRI vs. BS
-0.02
0.08
-0.16
0.13
0.14
0.15
0.36
CE-CT vs. BS
-0.05
0.09
-0.11
0.10
0.06
0.13
0.67

204
Table 2 shows estimates and 95% confidence intervals of sensitivity and specificity for
each modality, derived from both single- and multi-modality studies. With a
sensitivity of around 0.94-0.95 and a specificity between 0.93 and 1, FDG-PET/CT,
MRI, and NaF-PET/CT outperformed CE-CT and bone scintigraphy. The network meta-
analysis of multi-modality studies supported the comparable performance of FDG-
PET/CT and MRI in the assessment of bone metastases whereas the contrary
estimated differences in sensitivity and specificity between FDG-PET/CT and NaF-
PET/CT (-8% vs. +10%) are inconsistent with the respective point estimates of the two
modalities. For FDG-PET/CT, MRI, CE-CT, and bone scintigraphy, the estimates of
sensitivity and specificity from bivariate random effects modelling and the estimated
differences in sensitivity and specificity between modalities from the network meta-
analysis are consistent.
Table 2 Summary of meta-analyses. Estimates (and respective 95% confidence
intervals) of sensitivity and specificity derived from bivariate random effects models
and network meta-analyzed differences in sensitivity and specificity
Modality
Bivariate random effects models
Network meta-analysis of multi-
modality studies (N=16); comparator
minus reference
Number of
studies
Sensitivity
Specificity
Sensitivity
Specificity
FDG-PET/CT
20
0.94
(0.89
–0.97)
0.98
(0.96
–
0.99)
Reference
Reference
MRI
7
0.94
(0.82
–
0.98)
0.93
(0.87
–0.96)
0.01
(
-0.16 – 0.18)
p=0.91
-0.02
(
-0.15 – 0.12)
p=0.82
NaF-PET/CT
4
0.95
(0.85
–0.98)
1
(0.93
–1)
-0.08
(
-0.28 – 0.12)
p=0.44
0.10
(
-0.10 – 0.29)
p=0.34
CE-CT
5
0.70
(0.62
–0.77)
0.98
(0.97
–0.99)
-0.22
(
-0.40 – -0.04)
p=0.017
0.01
(
-0.11 – 0.13)
p=0.92
Bone
scintigraphy
13
0.83
(0.75
–
0.88)
0.96
(0.87
–0.99)
-0.11 (-0.20 – -0.02)
p=0.017
-0.07
(
-0.15 –
0.001)
p=0.053

205
Conclusions
Our twofold analysis strategy indicated clearly consistent as well as inconsistent
pairwise comparisons between the five modalities. Both FDG-PET/CT and MRI
accurately assessed bone metastases in breast cancer in terms of sensitivity and
specificity, and they outperformed CE-CT and bone scintigraphy regarding sensitivity.
On the opposite, the potential role of NaF-PET/CT here is still unclear. Earlier critiques
advised against performing single diagnostic test evaluation at all (8). Using single-
modality studies in network meta-analyses of diagnostic test accuracy trials should be
done with caution (if at all), and further research and exploration into caveats are
warranted.
References
(1) Cochrane Handbook for Systematic Reviews of Interventions. Chapter 11: network meta-
analyses. https://training.cochrane.org/handbook
(2) Cochrane Handbook for Systematic Reviews of Diagnostic Test Accuracy.
https://training.cochrane.org/handbook-diagnostic-test-accuracy
(3) Veroniki AA, Tsokani S, Agarwal R, Pagkalidou E, Rücker G, Mavridis D, Takwoingi Y. Diagnostic
test accuracy network meta-analysis methods: A scoping review and empirical assessment. J Clin
Epidemiol. 2022; 146: 86-96. https://doi.org/10.1016/j.jclinepi.2022.02.001
(4) Gerke O, Naghavi-Behzad M, Nygaard ST, Sigaroudi VR, Vogsen M, Vach W, Hildebrandt MG.
Diagnosing Bone Metastases in Breast Cancer: A Systematic Review and Network Meta-Analysis
on Diagnostic Test Accuracy Studies of 2-[18F]FDG-PET/CT, 18F-NaF-PET/CT, MRI, Contrast-
Enhanced CT, and Bone Scintigraphy. Semin Nucl Med. 2025 Jan;55(1):137-151.
https://doi.org/10.1053/j.semnuclmed.2024.10.008
(5) Nyaga VN, Arbyn M. Metadta: a Stata command for meta-analysis and meta-regression of
diagnostic test accuracy data - a tutorial. Arch Public Health. 2022; 80(1): 95.
https://doi.org/10.1186/s13690-021-00747-5
(6) White IR. Network meta-analysis. Stata Journal. 2015; 15(4): 951-985.
https://doi.org/10.1177/1536867X1501500403
(7) McInnes MDF, Moher D, Thombs BD, McGrath TA, Bossuyt PM; and the PRISMA-DTA Group;
Clifford T, Cohen JF, Deeks JJ, Gatsonis C, Hooft L, Hunt HA, Hyde CJ, Korevaar DA, Leeflang
MMG, Macaskill P, Reitsma JB, Rodin R, Rutjes AWS, Salameh JP, Stevens A, Takwoingi Y, Tonelli
M, Weeks L, Whiting P, Willis BH. Preferred Reporting Items for a Systematic Review and Meta-
analysis of Diagnostic Test Accuracy Studies: The PRISMA-DTA Statement. JAMA. 2018 Jan
23;319(4):388-396. https://doi.org/10.1001/jama.2017.19163
(8) Moons KG, van Es GA, Michel BC, Büller HR, Habbema JD, Grobbee DE. Redundancy of single
diagnostic test evaluation. Epidemiology. 1999; 10(3): 276-281.

206

207

208

209

210

211

212

213

214

215

216

217

218

219

220

221

222

223

224

225

226

227

228

229

230

231

232

233

234

235

236

237

238

239

240

241

22
Studying the First Modern Economy with the Sound Toll Accounts
By Lisbeth la Cour and Battista Severgnini, CBS
Abstract: The first part of the title above describes the final analysis we want to
perform in this study. Here we will mainly present a more initial discussion about our
data sources and in particular the data from the Sound Toll Accounts as digitalized by
researchers in the Netherlands and made online available for researchers for free.
These data are very rich and complete in that they in principle offer information about
each ship that sailed through Øresund in the time span of the Sound Toll (1429 – 1857).
Originally in la Cour & Feilberg (2000), we presented a study based on the Sound Toll
accounts but with a different focus. Back then, we used the summary tables of Bang and
Korst (1922-1930) based on the original books of the accounts. In the present study we
want to change our main source to the digitalized version mentioned above. At the
present stage we are still preparing, cleaning and comparing the online data with our
old Bang and Korst data. Hence our paper here is mainly on our opportunities and
challenges in this data preparatory phase, although we also want to sketch the ideas we
have for further research.
1. Introduction.
For economic historians and economists it has been of interest for many years to look
at economic growth and its potential drivers over centuries from different perspectives.
On the one hand, using historical data to test development theories, especially when
going back several centuries, can be challenging since the amount, scope, and quality
of historical data must be gathered from various sources and might be affected by
sample selection and measurement errors. On the other hand, such data, when used for
empirical and quantitative analysis, can offer unique perspectives across different
dimensions. First, it may cover a long span of time, enabling long-term time series
analysis. Second, the extensive nature of these datasets allows for a detailed
examination of specific shocks, helping to disentangle potential long-run effects from
short-term ones. Finally, the historical case may capture specific shocks that could be
difficult to identify using contemporaneous data.
An interesting example of a historical case that exhibits these characteristics is the
Sound Toll Accounts. This administrative archive has been introduced due to a taxation
(in Danish Sundtoldforvaltningen) decided by Eric of Pomerania in 1417 (Scheltjens,
2017). The record contains highly detailed quantitative information on trade, providing
entries for each ship that carried goods through Øresund from 1429 to 1857.
These accounts are the data of interest in this article. This dataset covers a crucial period
from an economic history perspective. Beginning in the 15th century, the Netherlands—

23
followed by other countries—experienced the first significant episodes of positive
economic growth, driven by a predominant role of technological change. This period
also marked the early decline of Malthusian mechanisms. Trade has been recognized as
a key factor in explaining the success of this industrious nation (De Vries and Van Der
Voude, 1997). Furthermore, economist and economic historians found a strong positive
relationship between commercial exchanges and the political power of mercantilism
(Heckescher, 1935) and natural resources of a country (Viner, 1948) Given the detailed
information it provides, covering both micro-level data and long time series, the Sound
Toll Accounts are an excellent candidate for potential econometric analysis.
Furthermore, access to this source is not without problems. In Rigsarkivet you will find
micro-films of each page in the hand-written registrations of these accounts.
Alternatively, the digitized version provided by the Sound Toll Registers Online (STR
henceforth, https://www.soundtoll.nl) is not without its problems, as we will describe
later. From there to actual econometric analysis is a big step.
The aim of this paper is to explain where we are in the process of accessing these
accounts/registers and to present and discuss the challenges we have met in order to
perform an econometric analysis. As in la Cour and Feilberg (2000) we will focus on
the trade of rye from the Polish city of GdaĔsk to the harbour of Amsterdam during the
period covered by data. The route, often referred as the ‘mother of all trades’for being
the cornerstone of the Dutch economy (Van Tielhof, 2002) is illustrated in Figure 1.
2. The data source.
Historians agree that the Sound Toll Accounts is a rich source of important information
when it comes to trade and transportation of goods through Øresund during the time
period of the effect of the Sound Toll (see, among others, Scheltjens (2018)). As for any
historical source, there are certain caveats to be aware of.: First, during the early
centuries of the toll, the accounts are not complete and information for several years
between 1427 and 1497 is missing and thus potentially affected by self-selection
Second, there were other competing routes from Western Europe to the Baltic Sea area,
including the ones through the Little Belt and the Great Belt, the overland route, the
route to Russia via North Cape and, from 1784 on, the Schleswig-Holstein Canal.
Finally, the next concern about the STR’s reliability involves fraud. i.e. false
declarations and a fourth reason why the STR must be handled with care, is the fact that
sometimes parties were exempted from the toll. For example, Danish ships paid less
during a certain time period).
The data collection process is a crucial aspect of this analysis. On the one hand,
basically, a researcher could go directly to the micro-films mentioned above. On the
other hand, this procedure would not be an easy task. Until about 15 years ago easier
access could be obtained by using the set of summary tables provided in Bang & Korst
(many year – see reference list) or by applying the digitalized version of Johansen

2
Figure 1: The route the ships followed when rye was traded between Danzig and
Amsterdam.
Source: Graph created by the authors using the GIS map provided by
(1983) for a selected span of years. An earlier study by la Cour and Feilberg (2000)
used these sources. More recently a free, digitalized, online version of the Sound Toll
Accounts – now Registers (STR) has been released, all made available through a large,
Dutch, ‘citizen-science’ project (i.e., not ordinary citizens but citizens with ability to
read the old hand-written pages and with some historical knowledge too). Despite the
easier access to the micro-sources, there are still issues to be analyzed, which we address
later.
In this paper we will download, clean and make the STR online data ready for use in
econometric studies for a key time period just up to industrialization. We start out by
looking at data from 1650 until 1857 but will quickly reduce our focus on 1675 – 1794
a time period where rye was the most important source of grain for food in Western
Europe (De Vries and Van Der Voude, 1997 and Van Tielhof, 2002).
2.1 The content of STR.
The STR online is a very rich database. It contains one (before 1633) or several (after
1633) records for each passage through the Sound for several centuries. Initially data
for some years are missing but the quality of the source increases with time and Friis
(1925) says that after 1618 the quality seems quite good due to increased control by the
government administration.

25
Table 1: The stepwise reduction in observations during cleaning and selection.
Type of reduction
Loss of
observations
Number of
observations
Comments
The full data set as
downloaded and merged.
-
4,836,702
Before 1633 one passage
may have several records.
After 1633 one passage
has only one record.
We drop observations
where ‘to’, ‘from’ and
‘type of goods’ are either
empty or contain a star.
7,859
4,828,843
We drop observations
where our indicator for
Amsterdam equals zero.
4,434970
393,873
Destination: We mark and
delete versions of
Amsterdam provided by
STR online. We add three
more variations to the list.
We drop observations
where our indicator for
Danzig equals zero.
304,598
89,275
Departure: We mark and
delete versions of Danzig
provided by STR online.
We drop observations
where our indicator for
rye
equals zero.
73,327
15,948
Type of goods: we delete
goods that are not rye. We
select rye from the STR
online list and add a few
more variants ourselves.
We do not include
Rogken, Ruh and ‘R.’.
Indicators for several
types of goods
0
15,948
We do not delete these
observations at the
moment. We construct
indicators and we can
easily drop them for
robustness.
A few obs. with missing
values for number or units
or measurement
17
15,931
This sample is valid when
we use data for the
amount of rye.
The entire STR contain data on 1.8 million passages through the Sound. The clerks of
the tollhouse at the Danish city of Elsinore recorded in principle the following data of
each passage (STR Online, Home):
- the date of the passage
- the name of the shipmaster

26
- the place of residence of the shipmaster
- the port of departure
- the port of destination (from the mid-1660s)
- the composition of the cargo
- the toll paid.
In addition to these overall types of information, there is a passage indicator. There is
not always – but in most cases – a one-to-one match between passages and records in
the database. If a ship carried more than one type of goods then the passage of this
ship receives a unique identifier but a record for each type of goods.
We perform some initial data cleaning before we start reporting of descriptives and in
Table 1 we report how this cleaning and selection reduces the number of observations
for the final analysis.
For our purposes, we notice that the largest drop in number of observations is seen
when we narrow down to the destination port being Amsterdam. The order in which
we narrow down has a say here. In the end we are left with a little less than 16,000
observations which still reflects the high degree of detail in the STR online. In the end
we want to analyze the data at an annual level so we have to perform temporal
aggregation.
3. The units of measurement
Before we can aggregate the amounts of rye to an annual level, we need units of
measurement to convert the content of the amount of a good to the same volume
measure (grain was most often measured as a volume). As the aantal variable (the
number of goods in a specific measurement unint) is a string variable we first need to
convert it to a numeric variable. However, as non-integer numbers are recorded as, e.g.,
“8 ¼”, we first need to split these values into the integer part and the fraction. After that,
we can convert each part to a numeric variable and add them up to reach the amount.
We use ‘Lasts’ as our common measure. In the Middle ages the measurements were a
‘mess’ and there was no real standardization of the units. In the STR online, there has
been no attempt of converting measurement units and therefore the conversion in this
article is suggested by the authors which of course makes it up for further discussion1.
From 1683 and on-wards a standardization was introduced in Denmark by law. We will
mainly use that conversion for now as it contains most of the years of our sample period.
We are however aware that it was well known that despite this law it took some time to
achieve a full implementation. We work with ‘Lasts’ (in Danish: Læst or Læster, think
1 STR online do provide a csv file that categorizes different spellings of the most ‘common’
measurement units.

27
of the volume of the ship), ‘Tønder’ (think of barrel), ‘Skæpper’ (think of a type of bowl
smaller than a barrel)2 and a few weight measures: Skippund, Lispund and Centner. We
delete a few observations with either missing units of measurement or units that does
not really make sense.
We have lent support for our conversions from Thestrup (1991), Hægstad (1983). Also
we have had an eye to the file that categorizes measurement units in maten.csv.zip from
the sub menu called ‘Download’ in STR Online.
First, we categorize words to the ‘official’ versions of a sub measure. Second, we
convert the ‘official’ sub measures to ‘Lasts’. For step one a list on our subjective
categorizations are available upon requests. For step two we apply the conversions of
the 1683 law:
1 Last equal 24 ‘Tønder’
1 ‘Tønde’ equal 8 ‘Skæpper’
Conversions for the few weight measures are from Thestrup (1991).
Parallel to the discussion above, there is the issue of the language used to define the
goods shipped. To address this, we proceed in two ways. First, we utilize the
crosswalks provided by STR to translate the goods, available at the following link:
https://www.soundtoll.nl/data/pdf/products.pdf. Additionally, we clean the data using a
code provided by Professor Arne Solli from the University of Bergen, Norway.
4. Descriptive statistics and graphs.
In this section we will show some descriptive statistics and graphs from the STR online
and compare them with our old data from the old article, la Cour & Feilberg (2000).
Our first challenge or worry is that for some years we simply get zero values for this
specific trade. That does not match with the numbers we have used previously as we
did not observe as many years with zero trade of rye as we do now.
Our strategy to solve this puzzle: we have tried to get help from Rigsarkivet to find out
if the original Bang & Korst tables contain some kind of introduction with information
on how they actually converted the measures before performing their aggregations.
Answer: that does not seem to be the case. But Rigsarkivet told us, that originally the
STR online project had intensions of making information available for conversion of
units of measurement but that they had to give up due to the challenges with measures
changing over time and geographically differences. Of course, our problem is somewhat
2 In Folkeskolen. Blog (2024) it is stated that the German word Sheffel refers to ‘Skæppe’. We
categorize versions of ‘Scheffel’ to ‘Scheffel’. After that, we convert versions of Scheffel in the same
way as we convert Skæppe.

28
simpler than the corresponding problem for the entire database due to our selected focus
on the trade with rye.
Figure 2: Number of ships with rye from Figure 3: Lasts of rye from Danzig to
Danzig to Amsterdam 1639 – 1857 Amsterdam 1639 - 1857
Next,in Figure 2, we will display graphically the quantity of rye transported from
Danzig to Amsterdam between 1639 and 1857. As explained above we have to convert
the quantities to a common unit of measurement and for that we use Lasts.
Apart from the year around 1650 and a few more before 1794 we seem to have an
almost unbroken time series of lasts of rye transported through the Sound from Danzig
to Amsterdam. Therefore, we select a sample running from 1675 to 1794 as basis for
the econometric analysis.
Our next check of the data consists of a comparison of the numbers from Figure 3
with the numbers we apply in la Cour & Feilberg (2000) based on Bang&Korst and
the Johansen digitalization. We illustrate how these numbers correlate in Figure 4.
Figure 4: Quantity of rye from STR online Figure 5: Quantity of rye from STR online
and our 2000 data. 1675 – 1794 against our 2000 data. 1675 - 1794
Finally, Figures 6 and 7 illustrate the prices of rye in Amsterdam and Danzig (in gold)
and the quantity of rye transported through the Sound from Danzig (1600–1795),
respectively.

29
Figure 6: Price of rye in Amsterdam Figure 5: Quantity of rye in Amsterdam
and Danzig (in gold) and Danzig (1600–1795)
5. An initial suggestion for an econometric analysis
A preliminar attempt for investigating our time series is to consider the following error
correction model:
ǻZt=ȆZt-1 +ī1ǻZt-1 +īk-1 ǻZt-k+1 + + ijDt + İt
where Ɋ is a constant and Z is a vector containing the price in Amsterdam, the price in
Danzig, the exchange rate and at some point also the quantity of rye. Especially when
adding the quantity measures and also other growth related measures like population
later on, we also expect to be able to run a more micro-econometrics inspired analysis.
6. Conclusions
This study represents an exploration in analysing and in understanding the dataset of
the Sound Toll (1429–1857), an important source for understanding of European trade
patterns and economic history. By analysing similarities and differences from the
traditional Bang and Korst summary tables to the comprehensive digitalized dataset
provided by Dutch researchers, we attempt new opportunities for analysis.
The data offers a complete account of ships passing through Øresund, enabling deeper
explorations of trade dynamics, regional economic interactions, and long-term
historical trends. However, the complexity of harmonizing these datasets rquires more
meticulous data preparation.
Our research aims to harness these digitalized resources to perform more detailed
analyses of trade flows, market integration, and price mechanisms across Europe. This
paper has started the groundwork for future inquiries, emphasizing the transformative
potential of these data while addressing the methodological considerations required to
discover their full value.

250
7. References
Bang, N. and Korst, K. (1906, 1922, 1930, 1933, 1939, 1945, 1953): ”Tabeller over
Skibsfart og Varetransport gennem Øresund 1497-1660, 1661-1783 og gennem
Storebælt 1701-1748.”
De Vries, Jan, and Ad Van der Woude. The first modern economy: Success, failure,
and perseverance of the Dutch economy, 1500–1815. Cambridge University Press,
1997.
Heckscher, Eli F. Mercantilism. Routledge, 1935.
la Cour, L. and Feilberg, M. (2000): “An empirical investigation of the grain trade
from Poland to Amsterdam (1670 – 1795) – is the import relation of th Amsterdam
market stable even when the turbulent period after 1760 is included in the sample?”,
in Symposium i Anvendt Statistik, Aalborg Universitet, pp 177-201.
Folkeskolen, Blog (2024) through the link: https://blog.folkeskolen.dk/blog-dansk-
danskundervisning/at-saette-sit-lys-under-en-skaeppe/219622 (Accessed 16 December
2024).
Friis, A. (1925): “Bemærkninger til Vurdering af Øresundstoldregnskaberne og
Principerne for deres Udgivelse.”, Historisk Tidsskrift, Bind 9. række, 4, pp 109-182.
Hægstad, A. (1983): ”Mål og Vægt i Danmark 1283-1983. Den legale metrologi
gennem 700 år.” Dantest & Danmarks tekniske Museum.
Johansen, H.C. (1983): “Shipping and Trade between the Baltic Area and Western
Europe 1784-95.” Odense University Press.
STR Online. https://www.soundtoll.nl/#home.
Scheltjens, Werner. "The Sound Toll at Elsinore. Politics, shipping and the collection
of duties 1429–1857: edited by Ole Degn, Copenhagen, Museum Tusculanum Press,
2017, 623 pp., $85.00 (hardback), ISBN: 9788763544702." (2019): 333-335.
Thestrup, P. (1991): ”Pund og Alen. Danske mål- og vægtenheder fra 1683-reformen
til i dag.” Arkivernes Informationsserie. Rigsarkivet. GEC Gad.
Van Tielhof, Milja. The'mother of all trades': the Baltic grain trade in Amsterdam
from the late 16th to the early 19th century. Vol. 3. Brill, 2002.
Viner, J., 1948. Power versus plenty as objectives of foreign policy in the seventeenth
and eighteenth centuries. World Politics,1(1), pp.1-29
251
Appendix. List of variable names in the original STR file after merge of the parts
for different types of information.
Var. name Explanation
id_doorvart id of passage
regel rule
van from
naar to
maat measurement unit
aantal number
soort first type
muntsoort1 first currency
bedrag1 first amount
muntsoort2 second currency
bedrag2 second amount
muntsoort3 third currency
bedrag3 third amount
maat_alt other measurement unit
maat_alt other number
hulp help
year year
v17

252
SAS and Open Source – A Legendary Alliance in Data Analytics
Sara Armandi
1 Introduction
For decades, SAS has been the superhero of analytics – strong, powerful, and trusted to
deliver results when it matters most. SAS has been the go-to choice for statisticians, data
analysts, and business intelligence professionals for decades. But no hero operates in
isolation forever. As the data landscape has evolved, new heroes have emerged: Python,
the agile problem-solver who always has the right tool for the job, and R, the statistical
genius capable of unlocking insights from even the messiest data. These open source
champions have captured the hearts of analysts and researchers everywhere, building large,
enthusiastic communities along the way. Faced with this changing environment, SAS has
chosen not to stand alone but to team up, as illustrated in Figure 1, creating an analytics
team that is more capable than ever.
Figure 1: The Analytics Team, SAS, Python and R
Source:
Generated using DALL-E 3, by OpenAI, based on the prompt: “
Please create an image of three
cool superheroes in a dynamic formation. At the center
, a strong and mature superhero. To the left,
show a younger
superhero holding a python snake and with a lot of gear
. To the right, depict an artistic
superhero and statistical genius with a calculator. Highlight their unique personalities and teamwork”.
253
Please note that in Figure 1 above, it appears that SAS and Python have switched places.
In the generated image, SAS is positioned on the left, Python is in the center, and R is on
the right.
SAS’s history of collaboration isn’t new. Long before Python and R became the data
world’s favorite new heroes, SAS showed its collaborative side with SQL. By creating the
SQL procedure, SAS proved it could be flexible, allowing users to mix SQL with its own
tools. That was just the beginning. Now, with Python and R in the spotlight, SAS is making
it clear: it’s not here to compete – it’s here to assemble the ultimate analytics team.
But why bring in Python and R? In today’s data universe, versatility is key. Python is like
the superhero with a gadget for everything – it can clean data, analyze it, and even build
machine learning models with ease. R, on the other hand, is the statistics wizard, delivering
complex calculations and stunning visualizations like magic. SAS, with its battle-tested
reliability, scalability and speed, adds the muscle to this team. Together, these tools form a
powerful combination, allowing users to solve problems in ways that weren’t possible
before.
Throughout this article, the focus is on how SAS has embraced integration with Python and
R, highlighting practical ways these tools can work together to save the analytics day.
Examples from superhero datasets illustrate how SAS, Python, and R combine their
strengths to analyze heroes and villains, uncover their powers. This collaboration
showcases how analytics workflows can become more flexible and effective, proving that
no challenge is too big for this dream team of tools.
2 Motivation for Integration
The integration of SAS with Python and R is driven by the changing demands of the modern
analytics landscape. Organizations and individuals increasingly seek tools that allow
flexibility, scalability, and collaboration. While SAS has long been a trusted powerhouse

254
in analytics, Python and R have risen to prominence as open source champions, celebrated
for their innovation and accessibility. SAS’s decision to integrate with these tools is not
merely about staying relevant; it’s about leveraging the strengths of each to create a more
versatile and efficient analytics ecosystem.
2.1 Comparing the Tools
Table 1 below highlights the comparative strengths and focus areas of SAS, Python, and R
Table 1: Comparing SAS, Python and R
Feature
/
Force
SAS Python R
Ease of Use
User
-
friendly, with
GUI options and
coding support
Versatile, but requires
coding
skills
Intuitive for users with
a statistical background
Statistical
Analysis
Strong in traditional
analytics and modeling
Good for machine
learning and data
manipulation
Excellent for statistical
analysis and data
visualization
Integration
Integrates well with
databases and
enterprise tools
Extensive library and
API integration
Integrates well with
data science tools and
packages
Community
Support
Established support but
limited community
Large and active open
source community
Strong academic and
research
-focused
community
Visualization
Good with built
-in
capabilities
Extensive libraries
(e.g., Matplotlib,
Seaborn)
Superior capabilities
(e.g.,
ggplot2)
Cost
Requires licensing
Free and open source
Free and open source
As can be seen from Table 1, SAS, Python, and R each bring unique strengths to the
analytics table. Analysts often face scenarios where combining these tools leads to optimal
results. For example, Python might be used to preprocess and clean superhero data, R to
create stunning visualizations of hero attributes, and SAS to handle complex data
255
management and ensure enterprise scalability. The integration ensures that users don’t need
to compromise on their choice of tools, empowering them to select the best one for the job
at hand.
2.2 Open Source Meets Enterprise
However, the growing focus on open source tools has presented challenges for SAS. Many
educational institutions have shifted toward teaching Python and R, resulting in fewer
graduates familiar with SAS’s syntax and capabilities. Recognizing this, SAS has
strategically embraced integration tools like SASPy and SWAT that make it easier for
Python and R users to access SAS’s powerful analytics engine. This approach bridges the
gap between open source enthusiasts and enterprise needs, ensuring that SAS remains a
valuable player in data workflows.
While Python and R offer remarkable flexibility and community-driven innovation, they
can struggle with scaling to manage large datasets or meeting enterprise-grade
requirements. SAS, in contrast, is built to excel in these areas, offering robust data
management and scalability for the most demanding applications. Integrating SAS’s
strengths with the flexibility of Python and R creates a constructive collaboration where
users can perform end-to-end analytics without hitting roadblocks.
SAS’s embrace of integration tools is a forward-looking move that reshapes the way
analytics workflows operate. Tools like SASPy and SWAT enable users to interact with
SAS’s engine directly from Python and R, allowing them to work in familiar environments
while tapping into SAS’s reliability and scalability. This strategy ensures that analysts no
longer need to choose between innovation and enterprise-grade power—they get both.
By blending open-source agility with SAS’s enterprise robustness, this integration positions
SAS as a key player in the hybrid analytics ecosystem. It is not just about keeping up with
trends but about leading them, fostering collaboration, and maximizing the value of data.
256
3 SAS Viya
Introduced in 2016, SAS Viya is a cutting-edge platform designed for artificial intelligence,
analytics, and data management. Built with a modern, cloud-native architecture, SAS Viya
optimizes the use of public cloud infrastructure, making it highly scalable and efficient for
today’s data-intensive workflows (SAS Institute, 2024).
At the core of SAS Viya is the Cloud Analytics Service (CAS), an engine that processes
data in-memory. This approach drastically reduces the time required for data access and
computation compared to traditional disk-based methods. Its distributed architecture allows
CAS to scale horizontally across multiple nodes, making it capable of handling large
datasets and supporting multiple users simultaneously.
One of Viya’s most compelling features is its open and flexible integration with multiple
programming languages, including SAS, Python, and R. This multilingual support ensures
that users can incorporate SAS Viya seamlessly into their existing workflows, leveraging
the strengths of different tools while benefiting from Viya’s robust capabilities.
Since its rollout, SAS has made Viya the centerpiece of its innovation strategy. New
features and enhancements are developed with Viya in mind, reflecting a strong
commitment to this cloud-native platform. Its open source integrations have further
solidified its relevance, providing users with a powerful, scalable, and flexible environment
for tackling modern analytics challenges.
3.1. GitHub in SAS Viya
GitHub is a widely used platform for version control and collaboration among developers,
particularly in open source projects. It enables multiple contributors to work on code
simultaneously, track changes, and share their work effectively, fostering collaboration and
enhancing code quality.
257
In SAS Studio within SAS Viya for Learners, the integration with GitHub facilitates the
cloning of repositories, management of code versions, and collaborative project work. This
integration streamlines the process of sharing and collaborating, providing a rich
development environment for learners to refine their coding skills. By utilizing GitHub, it
becomes possible to push changes back to the repository, ensuring that work remains
accessible to others1. The steps for achieving this integration are well described in the SAS
community article "GitHub + SAS Studio Integration in SAS Viya for Learners 4”.
4 SAS in Python
Python’s popularity can be attributed to its versatility. It offers libraries for everything from
basic data manipulation to cutting-edge machine learning, making it a favorite for solving
diverse analytical problems. Recognizing Python's strengths, SAS has developed multiple
ways to integrate Python into the SAS environment and to embed SAS functionality within
Python workflows.
4.1 SASPy
SASPy is a powerful Python interface module designed to bridge Python and SAS, enabling
the creation of mixed Python-SAS workflows that leverage the strengths of both platforms.
With SASPy, Python developers can tap into SAS’s powerful analytics engine while
working in their familiar Python environment (SASPy GitHub,2024). SASPy
fundamentally establishes a SAS session, executes code, and returns outputs (logs and other
outputs) to the Python script. Additionally, it generates SAS code, providing methods,
objects, and syntax that can be used directly in Python, which it then automatically
translates into the corresponding SAS language statements for execution. Typically, SAS
procedures or steps align directly with Python methods, offering a straightforward one-to-
one mapping2.

258
The SASPy project, is available through the SASPy GitHub Repository, and can connect
to both SAS 9.4 and SAS Viya environments, connecting users to the SAS programming
interface, enabling them to submit SAS code8.
4.1.1 SAS OnDemand for Academics with SASPy
For academic users and those new to SASPy, SAS OnDemand for Academics offers a free,
cloud-based platform to explore its capabilities. SAS OnDemand for Academics is a cloud-
based service which allows users to run SAS directly through a web browser without
requiring local software installation. To use SASPy with SAS OnDemand for Academics,
a SAS profile must be created and registered. Additionally, SASPy version 3.3.4 or higher
is required to establish the connection7.
In addition to an active SAS OnDemand account, a Python environment is needed, such as
a Conda environment, and optionally a code editor like Visual Studio Code. Detailed
instructions for setting up these tools are provided in Appendix A1. The subsequent
appendix, Appendix A2 outline the configuration and usage of SASPy to connect Python
with SAS OnDemand for Academics.
4.1.2 Connect to SAS OnDemand for Academics
Once configured, test the connection to the SAS server by executing the following
commands in the Python environment:
import saspy # import SASPy module into the Python session
sas = saspy.SASsession() # start a new SAS session named ‘sas’
print(sas) # prints the session object
Expected output:
Using SAS Config named: oda
SAS Connection established. Subprocess id is XXXXX
The connection object “sas” now serves at the interface to the SAS session.

259
4.1.3 Executing SAS Code in Python with SASPy
SASPy offers a robust mixed Python-SAS workflow, enabling analysts to execute SAS
code directly in Python while leveraging Python’s extensive libraries. This integration is
invaluable for users seeking to harness SAS’s analytics capabilities alongside Python's
flexibility for data manipulation and visualization.
The SASsession object is the cornerstone of SASPy, providing access to all functionalities.
Key configurations for SASsession are typically set in the sascfg_personal.py file, and
further details can be found in the SASPy Configuration Documentation6.
For users unfamiliar with SASPy or seeking guidance on its capabilities, the “help(sas)”
function can provide comprehensive documentation directly within the Python
environment:
help(sas) # Displays the help documentation for the SAS session object
Additionally, SASPy offers a teaching mode via the teach_me_SAS method. When
activated, this mode displays the SAS code generated by SASPy without executing it. This
feature is particularly useful for debugging and learning SAS syntax:
sas.teach_me_SAS(True) # Enable teaching mode
4.1.4 Superheroes and SASPy
To demonstrate SASPy’s capabilities, a dataset from Kaggle containing information about
superheroes is utilized. To accees the data in the Python session, the Python Kaggle API is
utilized:
import Kaggle # import kaggle module into the Python session
kaggle.api.dataset_download_files('claudiodavi/superhero-set',
path='Super Heroes Data', unzip=True)
The code creates two datasets in the home directory; heroes_information.csv and
super_hero_powers.csv. For this example, the focus is on heroes_information.csv. The
dataset contains attributes such as name, gender, eye color, race, and alignment.

260
import pandas as pd
# Load the dataset into a Pandas data frame
superheroes = pd.read_csv('Super Heroes Data/heroes_information.csv')
# Display the first few rows
print(superheroes.head())
Using the Pandas library, the dataset is loaded into a data frame and displayed:
name Gender Eye color Race ... Alignment
0 A-Bomb Male yellow Human ... good
1 Abe Sapien Male blue Icthyo Sapien ... good
2 Abin Sur Male blue Ungaran ... good
3 Abomination Male green Human / Radiation ... bad
4 Abraxas Male blue Cosmic Entity ... bad
To utilize the SAS programming interface and SASPy in Python, the data frame is uploaded
to the SAS session using the “df2sd” (an alias for “dataframe2sasdata”) method. When the
data is available in the SAS session, other methods, like “submitLST” can be used. This
method is a conversion rapper, which executes the SAS code and returns the result:
# Upload the dataset to SAS
sas.df2sd(superheroes, table='superheroes_sas', libref='work')
# Submit SAS code to analyze the dataset
results = sas.submitLST('''
proc freq data=work.superheroes;
tables Gender Alignment;
run;
''')
The generated output displays the frequency tables in SAS format:

261
The "download" method downloads a remote file from the SAS server's file system and
thus, requires the remote file's location as input. This location corresponds to the work path,
which can be obtained by printing the session object using “print(sas)”, as demonstrated in
Section 4.1.3:
sas.download(localfile=r'C:\...\superheroes.sas7bdat',
remotefile='/saswork/path/superheroes_sas.sas7bdat', overwrite=True)
SASPy also simplifies the conversion of SAS datasets back into Pandas data frames,
enabling further analysis using Python libraries:
# Retrieve data from SAS into a Pandas data frame
sas_df = sas.sasdata2dataframe(table='superheroes', libref='work')
# Analyze data in Python
print(sas_df[['name', 'Gender', 'Alignment']].head())
The above code provides the following Python output:
name Gender Alignment
0 A-Bomb Male good
1 Abe Sapien Male good
2 Abin Sur Male good
3 Abomination Male bad
4 Abraxas Male bad
This simple example illustrates how SASPy provides a flexible and efficient approach to
combining the best of Python and SAS, enabling a wide range of analytics applications
across diverse domains.
4.2 Python SWAT
The Scripting Wrapper for Analytics Transfer (SWAT) package is a powerful Python
library developed by SAS for connecting to and leveraging the Cloud Analytic Services
(CAS) engine in SAS Viya. Unlike SASPy, which can connect to both SAS 9 and SAS
Viya, SWAT is specifically designed for SAS Viya environments. This focus allows SWAT
to take full advantage of CAS’s distributed, in-memory processing capabilities, making it
ideal for handling large-scale analytics and big data tasks. As described in Section 3, the
CAS server is the heart of SAS Viya, designed for high-performance, distributed analytics.
By connecting Python to CAS using SWAT it becomes possible to perform complex

262
computations on massive datasets without being constrained by local machine limitations.
Further, a wide array of built-in CAS actions for data manipulation, machine learning, and
statistical analysis becomes available.
4.2.1 Setting Up a CAS Connection
To begin using SWAT in Python, access to a running CAS server is needed. Establishing a
connection requires the CAS host address, port, username, and password. The basic
connection syntax is5:
import swat # import swat module into the Python session
conn = swat.CAS('cas-server-address', port=5570, username='username',
password='password')) # connect to CAS server
Once connected, the “conn” object serves as the interface to the CAS server.
4.2.2 CAS Actions
CAS actions are the building blocks of analytics in CAS. They are predefined, optimized
operations for tasks such as loading data, transforming datasets, and training machine
learning models. The availability of actions depends on the installed SAS Viya products
and licenses. The “help” action will display a list of available actions in the CAS
installation. Using Python’s “help” function will display both the help for the CAS action
as well as information about the Python object driving the action:
conn = help(); # list available actions in CAS installation
help(conn.tableinfo) # displays help for the tableinfo action
SWAT also supports the submission of raw SAS code using the “runCode” action. This
functionality is especially useful for users transitioning from SAS to Python or for
leveraging existing SAS code within a Python workflow. For example:
conn.runCode(code="""
data superheroes_cas;
set superheroes;
super_power = “Yes”;
run;
""")

263
The SWAT package bridges the gap between Python and SAS Viya, empowering data
scientists to leverage the power of CAS within their Python workflows.
4.3 SASPy vs. SWAT
While both SASPy and SWAT enable Python integration with SAS, as shown in Table 2,
they serve each their purposes and cater to different SAS environments.
Table 2: Comparing SASPy and SWAT in Python
Feature
SASPy
SWAT
Connection
Type
Connects to SAS 9 and SAS
Viya
Connects exclusively to
SAS Viya (CAS)
Processing
Location
Executes code in the SAS
programming runtime
Utilizes CAS for distributed,
in
-memory processing
Primary
Use Case
Traditional SAS tasks (data
manipulation, statistical
analysis)
Big data analytics and high-
performance computing
Python
Integration
Submits SAS code or uses
Pythonic methods
Pythonic interface for CAS
actions and analytics
SASPy is ideal for traditional SAS environments or users extending SAS workflows with
Python. SWAT is designed for leveraging SAS Viya's modern, distributed architecture
directly within Python.
5. Python in SAS
SAS has embraced the growing demand for Python by enabling seamless integration of
Python code within the SAS environment, creating a dynamic superhero team-up. This
capability allows analysts and data scientists to leverage Python’s extensive libraries and
programming flexibility while benefiting from SAS’s powerful analytics and data
management capabilities.
264
5.1 PROC PYTHON
In the 1990s, SAS 6 introduced the SQL procedure, allowing users to use SQL syntax
alongside the DATA step, enhancing data manipulation in SAS. Similarly, the PYTHON
procedure introduced in SAS Viya in October 2021, integrates Python's libraries and tools
into SAS workflows, extending this flexibility. With PROC PYTHON, SAS provides the
ability to execute Python code within SAS programs. The procedure embeds Python code
directly within a SAS program.
The PYTHON procedure creates a Python subprocess from a SAS Compute Server process,
allowing for the execution of Python code within SAS. It automatically imports SAS data,
enabling interaction between SAS and the Python environment. The procedure facilitates
variable sharing between Python and SAS, data movement between SAS datasets and
Pandas data frames, and the invocation of SAS functions. Additionally, it allows for the
submission of SAS code within Python statements, creating a workflow that integrates both
programming languages3. Python code will be executed by the Python installation in the
SAS Viya environment, rather than the local client. In the SAS Viya for Learners
environment used for demonstrations, a wide range of packages are pre-installed; however,
not all packages may be available.
5.1.2 Superheroes and PROC PYTHON
Along with the PYTHON procedure, the Python Code Editor in SAS Studio was
introduced. This interface automatically invokes the PYTHON procedure and embeds the
Python code within a submit/endsubmit block when executed. Conversely, when using the
traditional SAS Studio Editor, users must explicitly invoke the PROC PYTHON procedure
along with the submit/endsubmit block.
The code example below demonstrates how to run the PYTHON procedure using the
submit/endsubmit block in the regular SAS Studio editor. The superheroes dataset,
previously mentioned in Section 4.1.5, is utilized again and can be retrieved in SAS Studio

265
on SAS Viya for Learners through GitHub integration by accessing the repository at
github.com/saraarmandi/superhero, as detailed in Section 3.1. This repository contains
various resources, including the SAS dataset superheroes.sas7bdat. In the Python code, the
superheroes dataset is loaded using Python’s Pandas library, which is capable of reading
SAS files directly.
proc python; # Start the Python procedure
submit; # Start the Python code block
import pandas as pd # Import Pandas module into the Python session
# Load the SAS dataset into a Pandas data frame
data_path = '/path/git /superheroes.sas7bdat'
df = pd.read_sas(data_path) # Load SAS dataset into Pandas data frame
print(df.head()) # Display the first few rows of the data frame
endsubmit; # End the Python code block
run; # End the Python procedure
Any output generated, such as the “print(df.head())” statement above, will be displayed in
the SAS log or results window. To continue the work on the superheroes dataset, the BMI
is calculated for all superheroes and plotted using the Python matplotlib library:
proc python;
submit;
# Import plotting library and calculate BMI
import matplotlib.pyplot as plt
df['BMI'] = df['Weight'] / (df['Height'] / 100) ** 2
# Visualize the BMI distribution
plt.hist(df['BMI'], bins=20, color='skyblue', edgecolor='black')
plt.title('Distribution of BMI Among Superheroes', fontsize=14)
SAS.pyplot(plt) # Show the plot (can’t use Python’s plt.show())
endsubmit;
run;
The chart specifications can be built out using Python syntax. However, as the execution
environment for Python in SAS Viya is integrated with SAS’s own processing and output
systems, the “plt.show()” function is not applicable. This function is designed to display
plots in a standard interactive Python environment, where a GUI backend can manage the
display. However, in SAS Viya, there is no direct GUI for displaying plots like in traditional
Python environments. Instead, SAS manages graphics output using
the SAS.pyplot(plt) which render the plot within the SAS environment. This function sends

266
the Matplotlib figure to SAS for display, allowing correct visualization of the plot in the
SAS interface.
As a result, the output effectively illustrates the distribution of BMI among superheroes,
providing valuable insights into the dataset. This integration between SAS and Python
empowers users to combine SAS's analytical strength with Python's versatility, enhancing
data analysis capabilities.
6 SAS and R
Integrating SAS with R empowers users to leverage the statistical prowess and visualization
capabilities of R alongside SAS's robust data management features. Key tools like
SAS/IML and R SWAT facilitate seamless collaboration between the two environments.
6.1 SAS/IML
One of the most versatile options for integrating SAS with R is SAS/IML. Interactive matrix
language (IML) is a programming language for statistical computations, focusing on

267
algorithms using matrices and vectors. SAS/IML allows for seamless integration of R code
within the SAS environment, enabling users to leverage the statistical power and advanced
analytics of R alongside the robust data management and processing capabilities of SAS.
SAS/IML allows direct calls to R functions and seamless data transfer between SAS and R.
This enables sophisticated analyses using specialized R libraries and techniques not
available in SAS. To invoke R from within SAS/IML the SUBMIT statement is used, which
passes data into the R environment and executes R code directly from the SAS session.
proc iml;
call ExportDataSetToR("sasdataset", "R-frame" );
submit / R; /* Start submitting statements to R */
# R CODE
endsubmit; /* Stop submitting statements to R */
call ImportDataSetFromR("sasdataset", "R-frame");
In the code, "call" statements invoke specific procedures in the SAS IML environment. The
first "call" exports a SAS dataset to an R data frame, facilitating further analysis in R. The
second statement imports results or modified data from R back into the SAS environment.
6.1.1 The RLANG Option
The RLANG option in SAS/IML allows SAS to execute R code directly within the PROC
IML procedure. This integration enables SAS users to access R's extensive statistical
capabilities and packages while maintaining the powerful data management features of
SAS. To use R in SAS/IML, the RLANG option must be configured to specify the location
of the R installation.
R integration through SAS/IML is available in both SAS Viya and SAS 9.4 environments.
In SAS Viya, R support is preconfigured, making it easy to execute R code without
additional setup. In SAS 9.4, R must be installed separately, and the RLANG option must
be set up to connect SAS to the R environment.

268
6.1.2 Superheroes and R with SAS/IML
Superheroes, whether good or evil, often have distinctive physical traits. To analyze the
differences in Body Mass Index (BMI) between good and bad superheroes, an analysis
using the Oaxaca-Blinder decomposition (OBD) method is conducted. This approach
separates observed differences into components attributable to measurable factors and those
due to unexplained influences. While OBD isn't integrated into a SAS procedure yet, the
IML procedure comes to the rescue:
proc iml;
call ExportDataSetToR("work.superheroes", "superheroes_r" );
submit / R;
library(boot) # Import necessary library
library(stats) # Import necessary library
library(GeneralOaxaca) # Import necessary library
# Oaxaca-Blinder decomposition
BO_A <- GeneralOaxaca(BMI ~ male, data=superheroes_r,
groupInd=superheroes_r$good,B=100)
BO_A$twofold
endsubmit;
The SAS dataset "work.superheroes" is exported to the R data frame "superheroes_r." The
R package "GeneralOaxaca" is imported along with two other functional packages for
decomposition. The model analyzes BMI differences between "good" superheroes (coded
as good=1) and "bad" superheroes, factoring in gender (with male superheroes coded as
male=1).
value prop (%) s.e z value P(>|z|) CI_l CI_u
char -1.3385 34.520 0.39901 -3.3545 0.0004 -2.1149 -0.55080
coeff -2.5390 65.480 1.41670 -1.7918 0.0366 -5.2844 0.27008
diff tot -3.8774 100.000 1.4091p -2.7515 0.0030 -6.6020 -1.07807
The results show that the average BMI of good superheroes is about 3.88 units lower than
that of bad superheroes, with 34.52% of this difference explained by gender distribution.
Male superheroes, who generally have higher BMIs, are more common in the "bad" group.
The remaining 65.48% of the BMI gap is unexplained, indicating other factors at play, such
as character portrayal—villains often appear larger and more muscular, while heroes are
depicted as slimmer and more athletic.
269
This integration between SAS and R empowers users to harness SAS's scalability and data-
handling strengths alongside R's specialized statistical capabilities. By seamlessly
combining these tools, workflows become more powerful and versatile, enabling advanced
analyses such as the Oaxaca-Blinder decomposition for exploring complex relationships
like the BMI gap between superhero alignments.
6.2 R SWAT
R SWAT facilitates the integration of R with SAS Viya by enabling users to manipulate
CAS tables and perform in-memory computations. This tool enhances workflow efficiency
by allowing seamless data exchanges between R and SAS environments, as previously
discussed in Section 4.2.
7 The Latest SAS Offshoot – SAS Viya Workbench
In April 2024, SAS announced a significant advancement in its integration with open
source technologies: the SAS Viya Workbench. As a self-service, on-demand
development environment, SAS Viya Workbench enables users to build AI models and
conduct data analysis seamlessly. It supports multiple programming languages, offering
robust capabilities for SAS, Python and R.
A standout feature of SAS Viya Workbench is its no-installation requirement, allowing
users to access the platform immediately as SAS manages the infrastructure. This
simplifies setup and enables developers to focus on their projects. Additionally, it offers
scalable compute resources, letting users adjust processing power based on project needs
to optimize performance and cost. By combining traditional SAS capabilities with open-
source flexibility, SAS Viya Workbench enhances productivity and fosters collaboration
among data scientists and developers9.

270
8 Conclusion
Just as superheroes unite to face challenges, integrating Python and R into SAS forms a
powerful analytics team that can tackle complex data issues. SASPy and SWAT facilitate
Python integration, while SWAT also supports R, providing versatile options for executing
code within SAS. Additionally, PROC PYTHON offers distinct approaches for Python
integration, and SAS/IML enriches the experience by enabling advanced statistical analyses
with R. Table 3 provides an overview of the tools and their capabilities.
Both Python and R struggle with scaling for enterprise needs and handling large datasets –
areas where SAS excels. This integration bridges those gaps, allowing organizations to
select the right tool for each task without compromising performance or reliability.
Table 3: SAS Integration with Python and R
Tool
Environment
Advantage
Use Case
SASPy
Connects to SAS 9 and
SAS Viya
Extends SAS
workflows with Python
Traditional data
manipulation and
analysis
PROC
PYTHON
Native Python
execution in SAS Viya
Seamless data
exchange with built-in
functions
Advanced Python
applications within
SAS
SWAT
Connects exclusively
to SAS Viya
Leverages CAS for big
data analytics
High
-performance
computing and
analytics
SAS/IML
Connects to SAS 9 and
SAS Viya
Direct execution of R
functions
in SAS
Complex statistical
analyses
requiring
R
libraries
By understanding and leveraging these tools, users can choose the right hero for their
specific data adventures, ensuring they emerge victorious in their analytical quests.
271
References
1
LGroves (2024, June 6). GitHub + SAS Studio Integration in SAS Viya for Learners
4 (VFL4). SAS Communities Library. Retrieved December 31, 2024, from
https://communities.sas.com/t5/SAS
-Communities-Library/GitHub-SAS-Studio-
Integration
-in-SAS-Viya-for-Learners-4-VFL4/ta-p/933185
2
Philips, J. (2019). A Complete Introduction to SASPy and Jupyter Notebooks. The
University of Alabama. Retrieved December 31, 2024, from
https://support.sas.com/resources/papers/proceedings19/3238
-2019.pdf
3
Profi, M. (2021, November 8). SAS opens its code editor interface to Python users.
SAS Blogs. Retrieved December 31, 2024, from
https://blogs.sas.com/content/subconsciousmusings/2021/11/08/sas
-studio-
python-
editor/
4
SAS Insitute. (2024, June 7). Learning the SAS Viya Platform. SAS® Help Center.
Retrieved December 31, 2024, from
https://documentation.sas.com/doc/en/pgmsascdc/v_058/pgmsasgswlcm/home.htm
5
SAS Institute. (2016, September 14). Getting Started with SWAT. GitHub. Retrieved
December 31, 2024, from
https://github.com/sassoftware/sas-viya-
programming/blob/master/python/hands
-on-workshop/Part%202%20-
%20Getting%20Started%20with%20SWAT.ipynb
6
SAS Institute. (2018). GitHub - sassoftware/saspy: Configuration. GitHub.
Retrieved December 31, 2024, from
https://sassoftware.github.io/saspy/configuration.html
7
SAS Institute. (2020, July 21). Create files to configure Python to access SAS
OnDemand for Academics
. Retrieved December 31, 2024, from
https://support.sas.com/ondemand/saspy.html
8
SAS Institute. (2024). GitHub - sassoftware/saspy: A Python interface module to the
SAS System. It works with Linux, Windows, and Mainframe SAS as well as with SAS
in Viya.
GitHub. Retrieved December 31, 2024, from
https://github.com/sassoftware/saspy
9
SAS Institute. (2024, April 17). SAS announces general availability of SAS Viya
Workbench developer environment for building AI models
. SAS. Retrieved
December 31, 2024,
from https://www.sas.com/en_us/news/press-
releases/2024/april/general
-availability-viya-workbench-developer-
environment.html?trk=article-ssr-frontend-pulse_little-text-block

272
Appendix
A1 Installing Python
An easy way to get Python (and additional modules) up and running on different
platforms (Windows, Linux, Mac) is using the Anaconda Python distribution. It also has
the advantage that it does not interfere with any existing Python installations exist on a
system/computer. Using the "miniconda" variant much less space is taken up than a full
installation. The installation procedure is as explained below:
1. Download the miniconda installer
from https://docs.conda.io/en/latest/miniconda.html.
2. Choose the installer for your platform of choice. It is important to choose the 3.-
something version of Python (not the 2.7 version). You can find the installation
instructions for your platform here: https://conda.io/projects/conda/en/latest/user-
guide/install/index.htmlLinks to an external site. (Under Regular Installation). On
Mac, the easiest solution is to just download the .pkg file. Unless you choose a
specific location yourself, miniconda will install somewhere under your home
directory (something like /Users/user-name/miniconda3 on Mac, /home/user-
name/miniconda3 on linux, C:\Users\user-name\AppData\Local\miniconda3\ on
windows. To minimize the chances of something unexpected happening, it’s
recommend using the default settings when installing.
3. Once Python is installed through Anaconda, you can install an editor. On widely
used editor is Visual Studio Code (VS Code). Downloaded it
here: https://code.visualstudio.comLinks to an external site.. This page contains
some installation instructions: https://code.visualstudio.com/docs/setup/setup-
overviewLinks to an external site.. Again, it’s recommend just using the default
options when installing.
273
4. After installing VS Code, install a few extensions to make it work optimally for
Python code. Under the View menu, select Extensions. Search for python, and
install this extension (if it is not already installed). Also install the extension
called jupyter.
5. Now, tell VS Code to use the miniconda python installation. To do this, click on
the search bar at the top of the window, and choose Show and Run commands (or
alternatively, just press Ctrl-Shift-P (windows) or Option-x (Mac)). Then
type Python: Select Interpreter, and press enter. A list of python installations
should show up. Find the one corresponding to your miniconda3 installation - it
should be called something like ('base').
6. Now, create a directory/folder where you want to put your Python, and then click
on Open Folder... under the File menu. After that, you can now click File->New
File... to create a new Python file (e.g. hello.py).
7. In the lower-right corner of the window, VS Code will show you which installation
of Python you are using. This should say something like 3.12.4 ('base': conda).
A2 Connecting SAS to Python Using SAS OnDemand for Academics with SASPy
More details on configuring Python to access SAS OnDemand for academic are available
in the official SASPy documentation7. To connect SASPy with SAS OnDemand for
Academics, follow these steps, which only needs to be done once:
1. Prerequisites
Ensure the following are available:
xActive SAS profile registered for SAS OnDemand for Academics
xJava (version 1.8.0_162 or higher): Required for SASPy to communicate with
SAS servers.

274
2. Create Configuration Files
To configure SASPy, create a configuration file named “sascfg_personal.py”. This
file defines how SASPy connects to SAS servers. Example content:
SAS_config_names=['oda']
oda = {'java': 'C:\\Program Files (x86)\\Common
Files\\Oracle\\Java\\javapath\\java.exe',
# European Home Region 1
iomhost': ['odaws01-euw1.oda.sas.com', 'odaws02-
euw1.oda.sas.com'],
'iomport': 8591,
'authkey': 'oda',
'encoding': 'utf-8'
}
xAdjust the Java path to match the system’s configuration.
xTo identify where to save the “sascfg_personal.py” file, run the following
command in Python:
import saspy, os
print(saspy.__file__.replace('__init__.py', 'sascfg_personal.py'))
3. Create Authentication File
An authentication file “_authinfo” (or “.authinfo” if using Linux/Mac) is needed to
storeSAS OnDemand credentials securely. Example content:
oda user ODA_EMAIL or ODA_USERNAME password ODA_PASSWORD
xReplace “ODA_EMAIL”, “ODA_USERNAME”, and
“ODA_PASSWORD” with the actual SAS OnDemand credentials.
xSave this file in the home directory (e.g., C:\Users\USERNAME on
Windows)
4. Install SASPy
Install SASPy using Python’s package manager:
pip install saspy # or conda install saspy

Empower Learning with SAS!
Discover a free, on-demand compute environment designed for educators
and students to enhance programming skills and accelerate project
completion.
•Build Skills: Develop expertise in AI and machine learning.
•Flexible Learning: Supports both SAS and Python to suit your needs.
Start your journey today:
www.sas.com/viya-workbench-for-learners